Bruk tekst-til-tale-API-et
På samme måte som sine tale-til-tekst-API-er , tilbyr Azure Speech i Foundry Tools et tekst-til-tale-API for talesyntese:
Som med talegjenkjenning er de fleste interaktive taleaktiverte applikasjoner i praksis bygget med Azure Speech SDK.
Mønsteret for implementering av talesyntese ligner på talegjenkjenning:
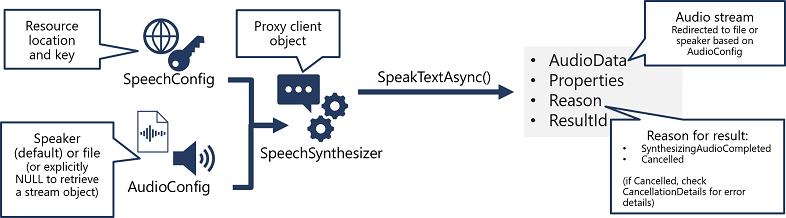
- Bruk et SpeechConfig-objekt for å kapsle inn informasjonen som kreves for å koble til Azure Speech-ressursen din. Spesielt plasseringen og nøkkelen.
- Du kan også bruke en AudioConfig til å definere utdataenheten for talen som skal syntetiseres. Som standard er dette standard systemhøyttaler, men du kan også angi en lydfil, eller ved eksplisitt å angi denne verdien til en nullverdi, kan du behandle lydstrømsobjektet som returneres direkte.
- Bruk SpeechConfig og AudioConfig til å opprette et SpeechSynthesizer-objekt . Dette objektet er en proxy-klient for tekst-til-tale-API-en .
- Bruk metodene for SpeechSynthesizer-objektet til å kalle opp de underliggende API-funksjonene. For eksempel bruker SpeakTextAsync() -metoden Azure Speech-tjenesten for å konvertere tekst til muntlig lyd.
- Bearbeid svaret fra Azure Speech-tjenesten. Når det gjelder SpeakTextAsync-metoden , er resultatet et SpeechSynthesisResult-objekt som inneholder følgende egenskaper:
- AudioData
- Egenskaper
- Grunn
- ResultId
Når tale er syntetisert, er Reason-egenskapen satt til opplistingen SynthesizingAudioCompleted , og AudioData-egenskapen inneholder lydstrømmen (som, avhengig av AudioConfig , kan ha blitt sendt til en høyttaler eller fil automatisk).
Eksempel – syntetisering av tekst som tale
Følgende Python-eksempel bruker Azure Speech i Foundry Tools for å generere muntlig utdata fra tekst.
import azure.cognitiveservices.speech as speechsdk
# Speech config encapsulates the connection to the resource
speech_config = speechsdk.SpeechConfig(subscription=KEY, endpoint=ENDPOINT)
# Audio output config determines where to send the audio stream (defaults to speaker)
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
# Use speech synthesizer to synthesize text as speech
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config,
audio_config=audio_config)
text = "My voice is my password!"
speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
# Did it succeeed?
if speech_synthesis_result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
# Yes!
print("Speech synthesized for text [{}]".format(text))
elif speech_synthesis_result.reason == speechsdk.ResultReason.Canceled:
# No - Ty to find out why not
cancellation_details = speech_synthesis_result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))