Bruk en visjonskompatibel modell i Microsoft Foundry-portalen
Tips
Se fanen Tekst og bilder for mer informasjon!
Hvis du vil håndtere ledetekster som inneholder bilder, må du distribuere en multimodal generativ AI-modell – med andre ord en modell som ikke bare støtter tekstbaserte inndata, men også bildebaserte (og i noen tilfeller lydbaserte) inndata. Multimodale modeller tilgjengelig i Microsoft Foundry inkluderer (blant andre):
- Microsoft Phi-4-multimodal-instruct
- OpenAI gpt-4.1
- OpenAI gpt-4.1-mini
Tips
For å lære mer om tilgjengelige modeller i Microsoft Foundry, se oversiktsartikkelen om Microsoft Foundry Models i Microsoft Foundry-dokumentasjonen.
Teste flermodale modeller med bildebaserte ledetekster
Etter å ha distribuert en multimodal modell, kan du teste den i chat-lekeplassen i Microsoft Foundry-portalen.
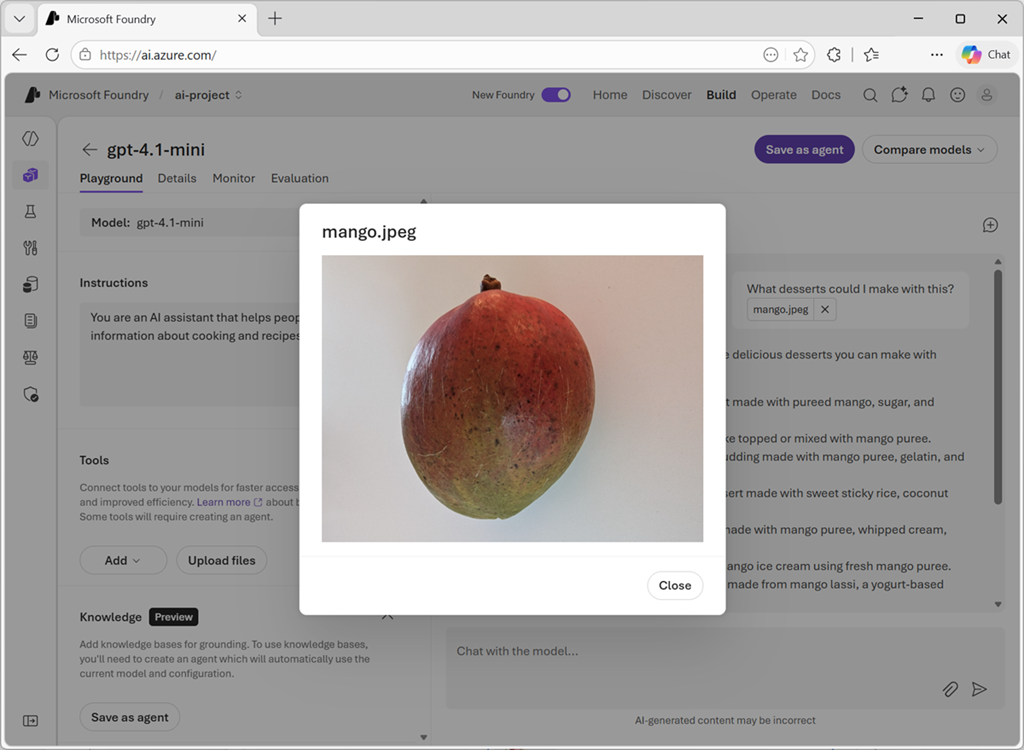
På chatlekeplassen kan du laste opp et bilde fra en lokal fil og legge til tekst i meldingen for å få svar fra en flermodal modell.