Trekk ut informasjon fra dokumenter
Tips
Se fanen Tekst og bilder for mer informasjon!
Dagens forretningsprosesser er sterkt avhengige av data som finnes i dokumenter som skjemaer, kvitteringer og fakturaer. Manuell behandling kan føre til forsinkelser og feil, noe som gjør automatisering av datautvinning viktigere enn noen gang.
Hvordan Azure Content Understanding fungerer
Azure Content Understanding følger en modelldrevet ekstraksjonsarbeidsflyt der ustrukturert innhold innleses, analyseres og returneres som strukturert data.
Importer innhold: Du sender inn innhold til Azure Content Understanding.
AI-drevet analyse: Tjenesten bruker en kombinasjon av: Optisk tegngjenkjenning (OCR), talegjenkjenning, naturlig språkforståelse og multimodale AI-modeller for å analysere innholdet.
Strukturert output: Tjenesten returnerer strukturerte resultater (for eksempel i JSON) som matcher modellen din—noe som gjør dataene enkle å lagre, søke i eller integrere i nedstrømssystemer.
Bemerkning
JSON (JavaScript Object Notation) er et tekstbasert dataformat som brukes til å lagre og utveksle strukturerte data mellom systemer. Det er lett for mennesker å lese og skrive, og lett for maskiner å tolke og generere.
Forstå skjemaer
OCR (optisk tegngjenkjenning) gjør det mulig for en datamaskin å 'lese' tekst fra bilder, som skannede dokumenter, bilder av kvitteringer eller bilder av trykte sider, og gjøre denne teksten om til redigerbar og søkbar digital tekst. Grunnleggende OCR hjelper med å gjenkjenne trykt tekst, fokuserer på tekstuttrekking, og forstår ikke mening, kontekst eller sammenhenger mellom ord.
Azure Content Understandings dokumentanalyse-muligheter går utover enkel OCR-basert tekstutvinning og inkluderer også skjemabasert uttrekking av felt og deres verdier. Den skjemabaserte tilnærmingen er det som skiller Azure Content Understanding fra grunnleggende OCR- eller transkripsjonstjenester.
Et skjema beskriver hvilken informasjon du ønsker å hente ut og hvordan denne informasjonen skal struktureres. Når du definerer et skjema, spesifiserer du felt som skal trekkes ut. Et skjema lister opp de spesifikke feltene eller entitetene du bryr deg om.
Anta for eksempel at du definerer et skjema som inkluderer fellesfeltene som vanligvis finnes i en faktura, for eksempel:
- Leverandørnavn
- Fakturanummer
- Fakturadato
- Kundenavn
- Egendefinert adresse
- Elementer - varene som er bestilt, som hver inkluderer:
- Varebeskrivelse
- Enhetspris
- Bestilt antall
- Linjevaresum
- Fakturadelsum
- Avgifter
- Fraktkostnad
- Fakturatotal
La oss si at du må trekke ut denne informasjonen fra følgende faktura:
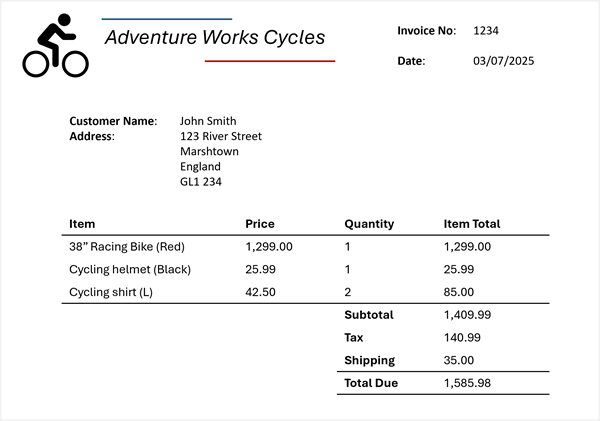
Azure Content Understanding kan bruke fakturaskjemaet på fakturaen din og identifisere de tilsvarende feltene, selv om de er merket med forskjellige navn (eller ikke merket i det hele tatt). Den resulterende analysen gir et resultat som dette:

Skjemaet definerer også feltstrukturen. Skjemaer støtter strukturerte og nestede felt, ikke bare flat tekst. Eksempel:
-
Itemser en samling - Hvert element har
description,unit price,quantity, ogline total
Å identifisere strukturerte felt gjør at Azure Content Understanding kan forstå sammenhenger mellom verdier, noe OCR alene ikke kan gjøre.
I fakturaeksempelet kan du for hvert oppdaget felt hente ut nestede verdier:
- Leverandørnavn: Adventure Works Cycles
- Fakturanummer: 1234
- Fakturadato: 07.03.2025
- Kundenavn: John Smith
- Egendefinert adresse: 123 Street, Marshtown, England, GL1 234
-
Elementer:
- Element 1:
- Elementbeskrivelse: 38"Racersykkel (rød)
- Enhetspris: 1299,00
- Antall bestilt: 1
- Linjeelement totalt: 1299,00
- Element 2:
- Elementbeskrivelse: Sykkelhjelm (svart)
- Enhetspris: 25.99
- Antall bestilt: 1
- Linjeelement totalt: 25.99
- Element 3:
- Elementbeskrivelse: Sykkelskjorte (L)
- Enhetspris: 42.50
- Antall bestilt: 2
- Linjeelement totalt: 85.00
- Element 1:
- Fakturadelsum: 1409,99
- Skatt: 140,99
- Fraktkostnad: 35.00
- Faktura totalt: 1585,98
Azure Content Understanding trekker ut forventet mening, ikke bare etiketter. Skjemaer anvendes semantisk, det vil si:
- Felt kan trekkes ut selv om etiketter er forskjellige
- Felt kan hentes ut selv om etiketter mangler
For eksempel kan faktura nr., faktura # eller et umerket nummer alle mappes til InvoiceNumber hvis analysatoren fastslår at de representerer det samme konseptet.
Forstå analysatorer
En analysator er en enhet i Azure Content Understanding som tar imot input, anvender AI-analyse og produserer strukturerte resultater. Analysatorer anvender konsekvent samme ekstraksjonslogikk på alt innkommende innhold. Når det er konfigurert, sørger en analysator for at et skjema gjenbrukes konsekvent for hver analyseforespørsel. Analysatorer produserer også forutsigbare JSON-resultater. De strukturerte resultatene gjør nedstrøms prosessering (lagring, søk, automatisering) enklere.
Azure Content Understanding tilbyr ferdigbygde analysatorer for vanlige scenarier og støtter skreddersydde analysatorer tilpasset dine behov. På et høyt nivå:
- Du velger eller lager en analysator.
- Analysatoren inkluderer et skjema som definerer felt og struktur.
- Du sender inn innhold for analyse
- Tjenesten anvender skjemaet
- Du mottar strukturerte JSON-resultater som matcher skjemaet
Bruk av Azure Content Understanding i Foundry-portalen
Bemerkning
Foundry-portalen har et klassisk brukergrensesnitt (UI) og et nytt brukergrensesnitt.
Etter at du har opprettet en Microsoft Foundry-ressurs, kan du bruke new Foundry-portalgrensesnittet for å teste Azure Content Understanding. Foundry-portalen gir innholdseksempler og lar deg laste opp eget materiale for analyse.
Du kan bruke det visuelle grensesnittet til å velge et kildedokument og hente ut standardfeltene med informasjon. For eksempel, når du prøver Azure Content Understanding på et bilde av et dokument, returnerer tjenesten dokumentteksten og tekstlayoutinformasjonen.

Azure Content Understandings analysatorer identifiserer tekstverdier i dokumenter og mapper dem til spesifikke felt. For eksempel, gitt en faktura, returnerer tjenesten feltene (som leverandøradresse) og dataene i feltene (for eksempel 123 456th Street).

I Foundry-portalen kan du også se JSON-resultatene av prosesseringen.

Å bygge en klientapplikasjon med Azure Content Understanding
Du kan bruke Content Understanding API til å bygge en lettvekts klientapplikasjon som henter ut data programmatisk.
Bemerkning
En klientapplikasjon er et programvareprogram som kjører på en brukers enhet og ber om tjenester eller data fra et annet system, vanligvis en server, over et nettverk. Klienten er den delen av en applikasjon som brukerne interagerer med, mens serveren gjør det tunge arbeidet bak kulissene. Applikasjoner kan be om data eller handlinger fra en tjeneste og motta et strukturert svar ved hjelp av et API.
Når du bruker Content Understanding API, kan du velge en ferdigbygd analysator eller lage en egendefinert analysator. Ferdigbygde analysatorer inkluderer: prebuilt-invoice, prebuilt-imageSearch, prebuilt-audioSearch, og prebuilt-videoSearch. Når du sender inn innhold for analyse til analysatoren, er analysen asynkron, noe som betyr at du får resultatet senere når det er klart. Fordi analysen er asynkron, må du polle den Operation-Location URL-en (eller analyzerResults) til jobben lykkes.
Bruk av Azure Content Understanding Python SDK
La oss se på prosessen med å bruke Python SDK for å analysere en faktura fra en URL.
- Installer Azure Content Understanding Python SDK.
python -m pip install azure-ai-contentunderstanding
Identifiser ditt Foundry-ressursendepunkt og API-nøkkel eller Microsoft Entra-ID. Endepunktet ditt ser vanligvis slik ut:
https://<your-resource-name>.services.ai.azure.com/Lag og kjør klientapplikasjonskoden. Her er
analzyer_idID-en til den forhåndsbygde analysatoren. Du kan finne en liste over forhåndsbygde analysator-ID-verdier her.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
Den resulterende utdataen er JSON som viser den uttrukne markdownen, feltene, dataene i feltene og konfidensscore. Eksempel:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
Lær deretter hvordan du bruker Azure Content Understanding-analysatorer for å hente ut strukturerte data fra lyd og video.