Utforsk hyperskalafunksjoner
Hyperscale-tjenestenivået i Azure SQL Database er et tjenestenivå i den vCore-baserte innkjøpsmodellen som er ideell for forretningsarbeidsbelastninger. Det er et svært skalerbart ytelsesnivå for lagring og databehandling som bruker Azure til å skalere ut lagrings- og databehandlingsressursene for en Azure SQL-database vesentlig utover grensene som er tilgjengelige for tjenestenivåene Generell formål og Forretningskritisk . Den kobler fra spørringsbehandlingsmotoren fra langsiktige lagringskomponenter, noe som gir sømløs skalering av databehandlings- og lagringsressurser.
Hyperscale forenkler infrastruktur og programutforming, slik at utviklere kan fokusere på forretningsbehov i stedet for å administrere databaseressurser.
Azure SQL Database pleide å være begrenset til 4 TB lagringsplass per database. Hyperscale-tjenestenivået tillater imidlertid nå at databaser overskrider 100 TB. Hyperskala bruker vannrett skalering til å legge til databehandlingsnoder etter hvert som dataene vokser. Selv om kostnaden ligner på vanlig Azure SQL Database, er det en ekstra lagringskostnad per terabyte.
Forstå fordelene
Hyperscale-tjenestenivået eliminerer mange av de praktiske begrensningene som vanligvis finnes i skydatabaser. I motsetning til de fleste andre databaser som er begrenset av ressursene til én enkelt node, har ikke Hyperscale-databaser slike begrensninger. Med den fleksible lagringsarkitekturen utvides lagringsplassen etter behov, og det finnes ingen forhåndsdefinert maksimumsstørrelse. Du betaler bare for kapasiteten du bruker. For leseintensive arbeidsbelastninger tilbyr Hyperscale rask utskalering ved å klargjøre ekstra replikaer for å avlaste leseoperasjoner.
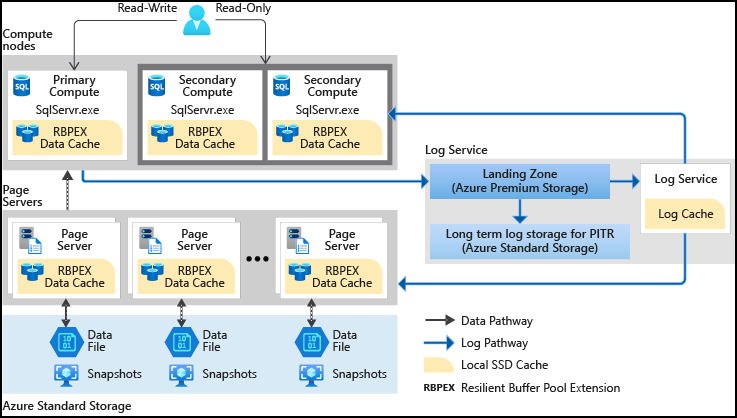
I tillegg er tiden det tar å opprette databasesikkerhetskopier eller skalere opp eller ned, ikke lenger avhengig av datavolumet i databasen. Hyperskaladatabaser kan sikkerhetskopieres umiddelbart. Du kan også skalere en database med titalls terabyte opp eller ned i løpet av minutter. Denne funksjonen frigjør deg fra bekymringer om å bli begrenset av de første konfigurasjonsvalgene. Hyperscale gir også raske databasegjenopprettinger, og fullfører i minutter i stedet for timer eller dager.
Hyperscale gir rask skalerbarhet basert på arbeidsbelastningsbehovet.
| Funksjon | Beskrivelse | Gode | Brukstilfelle |
|---|---|---|---|
| Skaler opp/ned | Du kan skalere opp den primære databehandlingsstørrelsen når det gjelder ressurser som CPU og minne, og deretter skalere ned, i konstant tid. Fordi lagringsplassen er delt, er ikke oppskalering og nedskalering koblet til datavolumet i databasen. | Sikrer fleksibilitet og effektivitet i ressursadministrasjon. | Ideell for programmer med ulike arbeidsbelastninger som krever ulike nivåer av databehandlingskraft. |
| Skaler inn/ut | Du kan også klargjøre én eller flere databehandlingsreplikaer for å håndtere leseforespørslene dine. Disse ekstra databehandlingsreplikaene fungerer som skrivebeskyttede replikaer, og avlaster lesearbeidsbelastningen fra den primære databehandlingen. I tillegg fungerer disse replikaene som hot-standbys, klar til å ta over hvis det er en primær databehandlingsfeil. | Forbedrer ytelsen og påliteligheten ved å avlaste lesearbeidsbelastninger og gi failover-funksjoner. | Passer for leseintensive programmer som trenger høy tilgjengelighet og rask failover. |
Maksimer ytelse
Hyperscale-tjenestenivået er utformet for kunder med store lokale SQL Server-databaser som ønsker å modernisere programmene sine ved å flytte til skyen. Det er også ideelt for kunder som allerede bruker Azure SQL Database, som ønsker å utvide vekstpotensialet i databasen betydelig. I tillegg er Hyperscale perfekt for de som søker både høy ytelse og høy skalerbarhet
I tillegg til raske skaleringsfunksjoner gir Hyperscale følgende ytelsesfunksjoner.
- Databasesikkerhetskopier er nesten øyeblikkelige, uavhengig av størrelse, uten noen effekt på databehandlingsressurser.
- Databasegjenopprettinger fullføres i minutter, i stedet for timer eller dager.
- Samlet ytelse forbedres på grunn av høyere gjennomstrømming av transaksjonslogg og raskere utføringstider for transaksjoner, uavhengig av datavolumer.
Merk deg
Hvis du vil distribuere en Hyperscale-database i Azure SQL Database, kan du se
Distribuer en Azure SQL Database Hyperscale
Slik distribuerer du Azure SQL Database med Hyperscale-nivået:
Logg på Azure-portalen.
Gå til Azure SQL-siden , og velg deretter + Opprett.
Velg SQL-database, enkeltdatabase og Opprett-knappen .
Velg ønsket abonnement, ressursgruppe og databasenavn på Grunnleggende-fanen på siden Opprett SQL-database .
Velg Opprett ny kobling for serveren, og fyll ut den nye serverinformasjonen, for eksempel servernavn, serveradministratorpålogging og passord og plassering.
Velg konfigurer databasekoblingen under Databehandling + lagring.
Velg Hyperscale for Service-nivå og Klargjort for databehandlingsnivå.
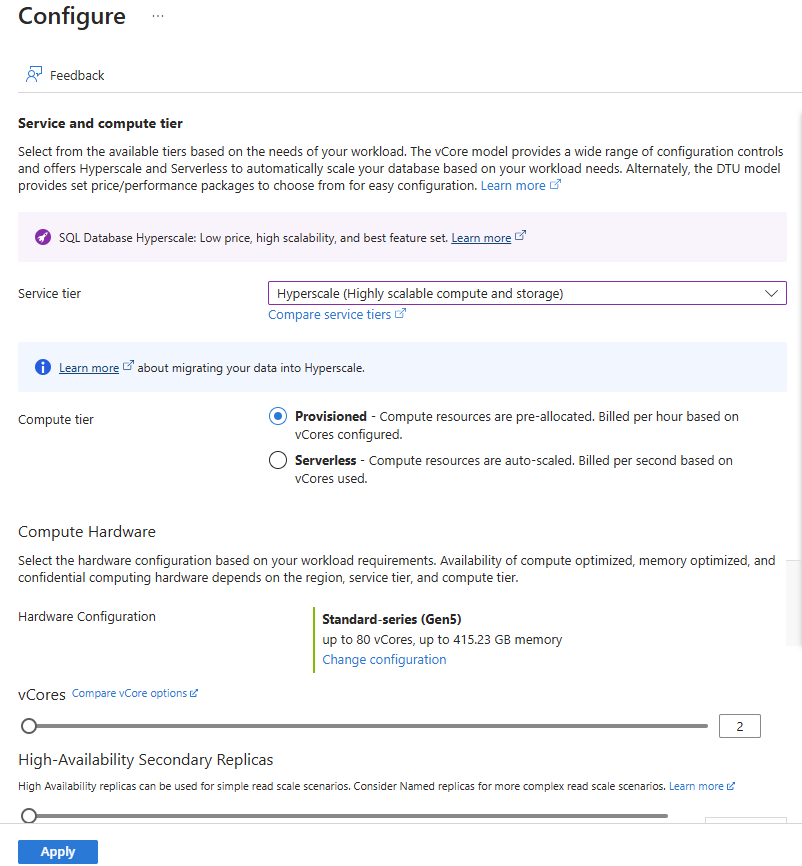
Velg koblingen Endre konfigurasjon under Maskinvarekonfigurasjon. Se gjennom de tilgjengelige maskinvarekonfigurasjonene, og velg den mest relevante konfigurasjonen for databasen. I dette eksemplet går vi over til standardalternativet Standardserie (Gen5 ).
Du kan eventuelt justere glidebryteren for vCores hvis du vil øke antallet vCores for databasen.
Juster glidebryteren High-Availability sekundære replikaer for å opprette én replika. Velg Bruk.
Velg Neste: Nettverk nederst på siden.
Angi Legg til gjeldende klient-IP-adresse til Ja på Nettverk-fanen.
Velg knappen Se gjennom + opprett , og velg deretter Opprett.

Merk deg
Når du har konvertert en database til Hyperscale, er det ikke mulig å tilbakestille den tilbake til en vanlig Azure SQL Database. Hvis du vil lære mer om begrensninger i Hyperscale, kan du se kjente begrensninger for Hyperscale-tjenestenivå.
Koble til en skrivebeskyttet replika
Du kan koble til en skrivebeskyttet replika ved å angi ApplicationIntent-argumentet på tilkoblingsstrengen til ReadOnly. Alle tilkoblinger med ReadOnly-programhensikten rutes automatisk til en av de skrivebeskyttede databehandlingsreplikaene.
Server=tcp:<your_server_name>.database.windows.net,1433;Database=<your_database_name>;User ID=<your_username>@<your_server_name>;Password=<your_password>;Encrypt=true;Connection Timeout=30;ApplicationIntent=ReadOnly;