Semantiske språkmodeller
Note
Se fanen Tekst og bilder for mer informasjon!
Som state of the art for NLP har avansert, har evnen til å trene modeller som innkapsler det semantiske forholdet mellom tokener ført til fremveksten av kraftige dype læringsspråkmodeller. Kjernen i disse modellene er kodingen av språktokener som vektorer (flerverdimatriser med tall) kjent som innebygginger.
Denne vektorbaserte tilnærmingen til modellering av tekst ble vanlig med teknikker som Word2Vec og GloVe, hvor teksttokens representeres som tette vektorer med flere dimensjoner. Under modelltrening tildeles dimensjonsverdiene for å reflektere de semantiske egenskapene til hver token basert på bruken i treningsteksten. De matematiske relasjonene mellom vektorene kan da utnyttes for å utføre vanlige tekstanalyseoppgaver mer effektivt enn eldre rent statistiske teknikker. Et nyere fremskritt i denne tilnærmingen er å bruke en teknikk kalt oppmerksomhet for å betrakte hver token i kontekst, og beregne innflytelsen til tokenene rundt den. De resulterende kontekstualiserte embeddingene, slik som de som finnes i GPT-familien av modeller, danner grunnlaget for moderne generativ AI.
Å representere tekst som vektorer
Vektorer representerer punkter i flerdimensjonalt rom, definert av koordinater langs flere akser. Hver vektor beskriver en retning og avstand fra origo. Semantisk like tokens bør resultere i vektorer med lignende orientering – med andre ord peker de i lignende retninger.
For eksempel, vurder følgende tredimensjonale innleiringer for noen vanlige ord:
| Ord | Vektor |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Vi kan visualisere disse vektorene i tredimensjonalt rom som vist her:

Vektorene for "dog" og "cat" er like (begge husdyr), det samme er "puppy" og "kitten" (begge unge dyr). Ordene "tree", "young", og ball" har tydelig forskjellige vektororienteringer, noe som reflekterer deres ulike semantiske betydninger.
Den semantiske karakteristikken kodet i vektorene gjør det mulig å bruke vektorbaserte operasjoner som sammenligner ord og muliggjør analytiske sammenligninger.
Å finne relaterte begreper
Siden orienteringen til vektorer bestemmes av deres dimensjonsverdier, har ord med lignende semantiske betydninger en tendens til å ha lignende orienteringer. Dette betyr at du kan bruke beregninger som cosinuslikhet mellom vektorer for å gjøre meningsfulle sammenligninger.
For eksempel, for å bestemme «oddetallet» mellom "dog", "cat", og "tree", kan du beregne cosinuslikheten mellom par av vektorer. Cosinuslikheten beregnes som:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Hvor A · B er prikkproduktet og ||A|| er størrelsen til vektor A.
Beregning av likheter mellom de tre ordene:
dog[0,8, 0,6, 0,1] ogcat[0,7, 0,5, 0,2]:- Punktprodukt: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Størrelse på
dog: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Magnitude av
cat: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Kosinuslikhet: 0,88 / (1,005 × 0,883) ≈ 0,992 (høy likhet)
dog[0,8, 0,6, 0,1] ogtree[0,2, 0,1, 0,9]:- Prikkprodukt: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Størrelse av
tree: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Cosinuslikhet: 0,31 / (1,005 × 0,927) ≈ 0,333 (lav likhet)
cat[0,7, 0,5, 0,2] ogtree[0,2, 0,1, 0,9]:- Punktprodukt: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Cosinuslikhet: 0,37 / (0,883 × 0,927) ≈ 0,452 (lav likhet)
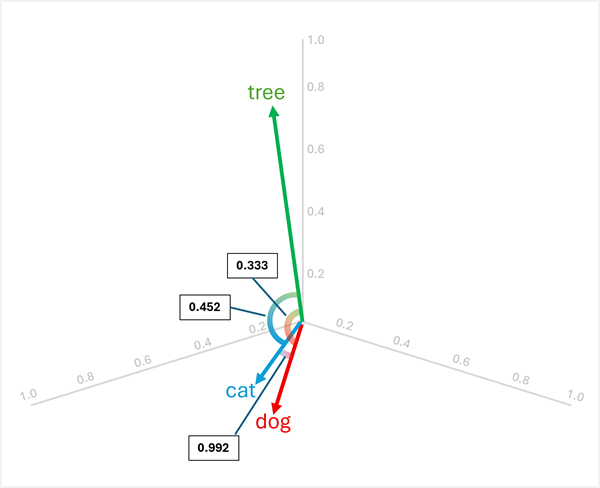
Resultatene viser at "dog" og "cat" er svært like (0,992), mens "tree" har lavere likhet med både "dog" (0,333) og "cat" (0,452). Derfor er han tree tydeligvis den som skiller seg ut.
Vektortranslasjon gjennom addisjon og subtraksjon
Du kan legge til eller trekke fra vektorer for å produsere nye vektorbaserte resultater; som deretter kan brukes til å finne tokens med matchende vektorer. Denne teknikken muliggjør intuitiv aritmetikkbasert logikk for å bestemme passende termer basert på språklige relasjoner.
For eksempel, ved å bruke vektorene fra tidligere:
-
dog+young= [0,8, 0,6, 0,1] + [0,1, 0,1, 0,3] = [0,9, 0,7, 0,4] =puppy -
cat+young= [0,7, 0,5, 0,2] + [0,1, 0,1, 0,3] = [0,8, 0,6, 0,5] =kitten
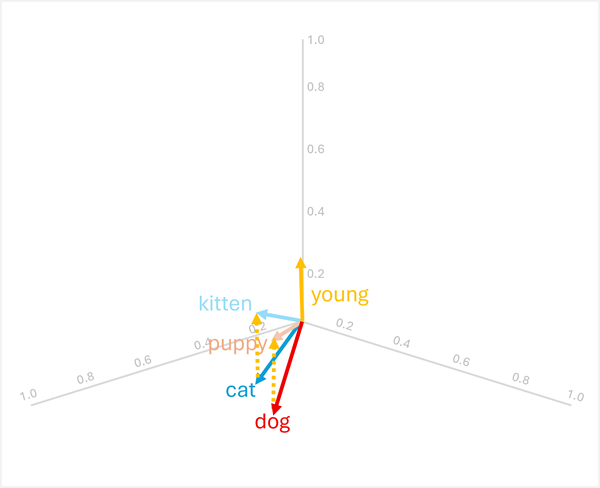
Disse operasjonene fungerer fordi vektoren for "young" koder den semantiske transformasjonen fra et voksent dyr til dets unge motpart.
Note
I praksis gir vektoraritmetikk sjelden eksakte treff; I stedet ville du søke etter ordet hvis vektor er nærmest (mest likt) resultatet.
Aritmetikken fungerer også motsatt:
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0,8, 0,6, 0,5] - [0,1, 0,1, 0,3] = [0,7, 0,5, 0,2] =cat
Analogisk resonnement
Vektoraritmetikk kan også svare på analogispørsmål som «puppy er til som dogkitten er til ?»
For å løse dette, beregn: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0,1, -0,1, 0,1] + [0,8, 0,6, 0,1]
- = [0,7, 0,5, 0,2]
- =
cat
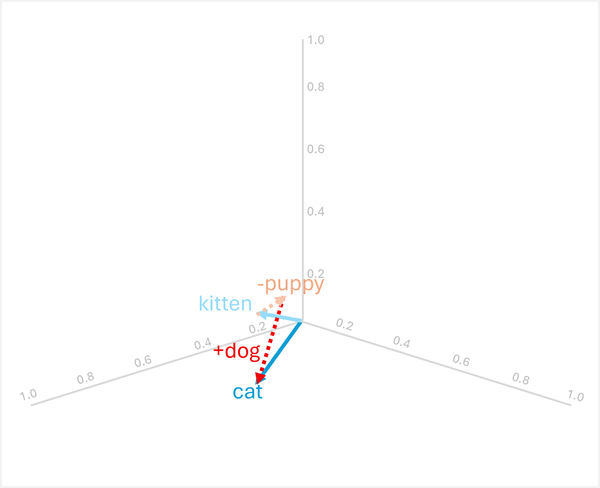
Disse eksemplene viser hvordan vektoroperasjoner kan fange språklige relasjoner og muliggjøre resonnement om semantiske mønstre.
Bruk av semantiske modeller for tekstanalyse
Vektorbaserte semantiske modeller gir kraftige muligheter for mange vanlige tekstanalyseoppgaver.
Tekstoppsummering
Semantiske innleiringer muliggjør ekstraktiv oppsummering ved å identifisere setninger med vektorer som er mest representative for hele dokumentet. Ved å kode hver setning som en vektor (ofte ved å gjennomsnittliggjøre eller samle embeddingene til dens bestanddeler), kan du beregne hvilke setninger som er mest sentrale for dokumentets betydning. Disse sentrale setningene kan trekkes ut for å danne et sammendrag som fanger opp hovedtemaene.
Nøkkelorduttrekking
Vektorlikhet kan identifisere de viktigste termene i et dokument ved å sammenligne hvert ords innbygging med dokumentets overordnede semantiske representasjon. Ord hvis vektorer ligner mest på dokumentets vektor, eller som er mest sentrale når man vurderer alle ordvektorer i dokumentet, er sannsynligvis nøkkelbegreper som representerer hovedtemaene.
Navngitt enhetsgjenkjenning
Semantiske modeller kan finjusteres til å gjenkjenne navngitte enheter (personer, organisasjoner, lokasjoner osv.) ved å lære vektorrepresentasjoner som grupperer lignende entitetstyper sammen. Under inferensen undersøker modellen hver tokens embedding og kontekst for å avgjøre om den representerer en navngitt enhet, og i så fall hvilken type.
Tekstklassifisering
For oppgaver som sentimentanalyse eller temakategorisering kan dokumenter representeres som aggregerte vektorer (for eksempel gjennomsnittet av alle ordinnlegginger i dokumentet). Disse dokumentvektorene kan deretter brukes som funksjoner for maskinlæringsklassifikatorer, eller sammenlignes direkte med klasseprototypevektorer for å tildele kategorier. Fordi semantisk like dokumenter har lignende vektororienteringer, grupperer denne tilnærmingen effektivt relatert innhold og skiller mellom ulike kategorier.