Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Beperk de systeembronnen die een toepassingsexemplaar, een afzonderlijke tenant of een gehele service kan verbruiken. Hierdoor kan de systeemfunctie voldoen aan de serviceniveaudoelstellingen (SLO's) onder plotselinge of aanhoudende belasting.
Context en probleem
De belasting van een cloudtoepassing varieert in de loop van de tijd op basis van actieve gebruikers en hun activiteit. Meer gebruikers melden zich tijdens kantooruren aan en het systeem voert aan het einde van elke maand rekenkundige dure analyses uit. Plotselinge pieken treden ook op. Als de verwerkingsvraag de beschikbare capaciteit overschrijdt, vertraagt of mislukt het systeem. Wanneer het systeem een overeengekomen serviceniveau heeft, schendt die fout de SLO.
Verschillende strategieën verwerken verschillende belasting, afhankelijk van de bedrijfsdoelen van de toepassing. Eén strategie is automatisch schalen, waarbij ingerichte middelen op de huidige vraag worden afgestemd en de kosten worden beheerst. Het inrichten van nieuwe resources kost echter tijd en voegt kosten toe. De vraag die de capaciteitsgroei overschrijdt of het budget overschrijdt, leidt tot een tekort aan resources.
Solution
Een alternatief voor autoschaling is het gebruik van resources te begrenzen en verzoeken te vertragen wanneer dat gebruik die limiet overschrijdt. De workload bewaakt het eigen resourcegebruik en beperkt aanvragen van een of meer gebruikers wanneer het gebruik de drempelwaarde overschrijdt. Het systeem blijft functioneren en voldoet aan de SLO's.
Snelheidsbegrenzing is een regelkring, geen eenmalige beslissing over toelating. Het systeem heeft signalen met lage latentie nodig op drie lagen: infrastructuurgebruik, toepassingsstatus en prestatiemeteritems per principal. Het meet continu verzadiging, dwingt limieten af bij goed gedefinieerde grenzen en past deze limieten aan wanneer verkeerspatronen veranderen. Overbelasting is een normale bedrijfsmodus waaruit een volwassen systeem detecteert en herstelt. Throttling biedt mogelijkheden voor zelfbescherming voor uw workload.
Het systeem kan verschillende throttlingstrategieën of verwante strategieën implementeren:
Limieten per principal: Wijs aanvragen af van een gebruiker die de geconfigureerde limiet al heeft overschreden binnen een bepaald tijdvenster. Deze strategie vereist dat het systeem elke aanvraag aan een principal toewijst en het resourcegebruik voor die principal meet. Zie Het verbruik van elke tenant meten voor multitenant-workloads.
Respijtende functievermindering: Schakel niet-essentiële functies uit of degradeer deze zodat essentiële functies voldoende resources hebben. Deze strategie ruilt de volledigheid van antwoorden in voor beschikbaarheid. Een toepassing voor videostreaming kan bijvoorbeeld dalen naar een lagere resolutie.
Herverdeling van belasting: Vloeiend activiteitsvolume met behulp van een wachtrij. In een multitenantomgeving verlaagt nivellering de prestaties voor elke tenant. Wanneer tenants verschillende service level agreements (SLA's) hebben, verwerken ze onmiddellijk werk voor hoogwaardige tenants en houden ze werk met een lagere prioriteit vast totdat de achterstand is versoepeld. Implementeer deze methode met behulp van het patroon Priority Queue of door afzonderlijke eindpunten voor elke prioriteitslaag weer te geven.
Uitstel op basis van prioriteit: Bewerkingen uitstellen namens toepassingen of tenants met een lagere prioriteit. Onderbreekt of beperk bewerkingen en retourneer een uitzondering waarmee de tenant later opnieuw moet proberen.
Uitgaande frequentielimieten: Beperk uw eigen uitgaande oproepen wanneer een externe afhankelijkheid mislukt of fouten retourneert. Verlaag het aantal lopende aanvragen om te voorkomen dat de logboeken volstromen en om kosten van nieuwe pogingen bij een ongezonde afhankelijkheid te vermijden. Herstel de normale aanvraagstroom nadat de afhankelijkheid is hersteld. NServiceBus implementeert deze functionaliteit bijvoorbeeld.
In de volgende grafiek ziet u resourcegebruik (een combinatie van geheugen, CPU, bandbreedte en andere factoren) voor een toepassing die gebruikmaakt van drie functies, A, B en C. Een functie is een specifiek functionaliteitsgebied, zoals een onderdeel dat een specifieke set taken uitvoert, een stukje code dat een complexe berekening uitvoert of een element dat een service zoals een cache in het geheugen biedt.
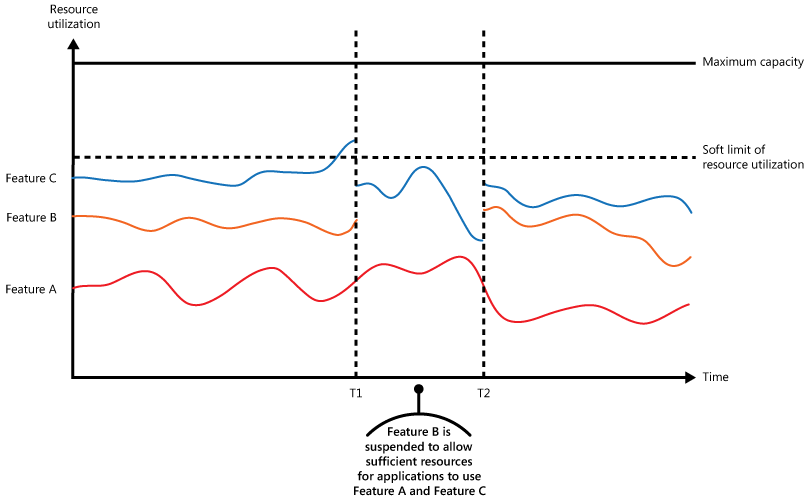
Een lijngrafiek zet het resourcegebruik op de y-as uit tegen de tijd op de x-as. Drie gekleurde lijnen vertegenwoordigen Functie A, Functie B en Functie C, waarbij de lijn van functie A het laagst is, de lijn van functie B in het midden en de lijn van functie C hoogste. Een ononderbroken horizontale lijn boven aan de grafiek markeert de maximale capaciteit en een onderbroken horizontale lijn eronder markeert de zachte limiet van het resourcegebruik. Twee verticale stippellijnen markeren tijden T1 en T2. Vóór T1 fluctueren alle drie de featurelijnen, en de lijn van feature C stijgt en kruist de zachte limiet. Op T1 daalt de lijn van functie B naar nul en blijft daar tot T2, omdat functie B wordt opgeschort om middelen vrij te maken voor functie A en functie C. De lijn van functie C daalt tussen T1 en T2 weer tot onder de zachte limiet, terwijl functie A normaal blijft functioneren. Bij T2 wordt Feature B hervat en blijven alle drie de lijnen onder de soft limit fluctueren.
De grafiek is een gestapelde vlakgrafiek. In het gebied onder de regel van functie A ziet u de resources die functie A verbruikt, het gebied tussen de regels van functie A en functie B de resources die functie B verbruikt, en het gebied tussen de regels van functie B en functie C toont de resources die functie C verbruikt. De lijn van functie C bevindt zich boven aan de stack, zodat ook het totale gebruik van systeembronnen in de loop van de tijd wordt weergegeven.
De grafiek toont een geleidelijke afname van functionaliteit. Net voor tijd T1 nadert het totale resourcegebruik de drempelwaarde en loopt het risico dat de beschikbare capaciteit wordt uitgeput. Functie B is minder kritiek dan Functie A of Functie C, dus het systeem schakelt functie B uit en publiceert de resources. Tussen tijden T1 en T2 worden functie A en functie C normaal voortgezet. Op tijd T2 daalt het totale resourcegebruik voldoende om functie B weer in te schakelen.
U kunt automatisch schalen, geleidelijke degradatie en snelheidsbeperking combineren om applicaties responsief te houden en binnen de SLA's te blijven. Wanneer u verwacht dat de vraag hoog blijft, blijft de bandbreedtebeperking stabiel terwijl het systeem uitschaalt. Nadat het schalen is voltooid, herstelt het systeem de volledige functionaliteit.
De volgende grafiek toont het totale resourcegebruik in de loop van de tijd en hoe throttling samengaat met automatisch schalen en andere compenserende maatregelen.
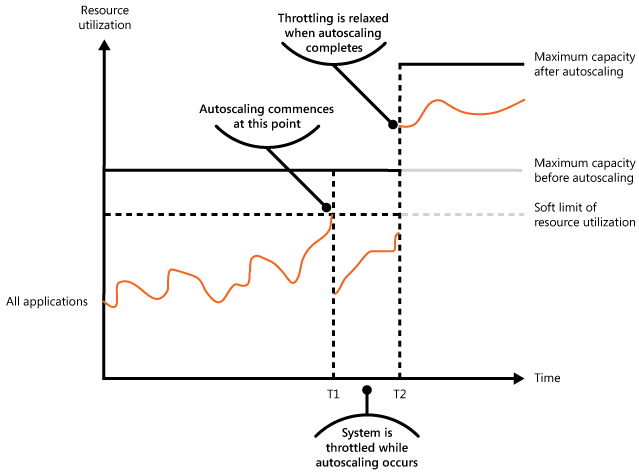
Een lijngrafiek zet de resourcebenutting van alle toepassingen op de y-as uit tegen de tijd op de x-as. Twee horizontale referentielijnen markeren de zachte limiet van het gebruik van resources en de maximale capaciteit voordat automatisch schalen plaatsvindt. Een hogere horizontale lijn, die begint op tijd T2, markeert de maximale capaciteit na automatisch schalen. De gebruikslijn stijgt en fluctueert in de loop van de tijd. Het overschrijdt de zachte limiet op tijd T1, het punt waar automatisch schalen begint. Tussen T1 en T2 wordt het systeem afgeremd terwijl automatisch schalen plaatsvindt, en blijft de benutting onder de maximale capaciteit van vóór het automatisch schalen. Op tijdstip T2 is het automatisch schalen voltooid, wordt de beperking versoepeld en springt de benuttingslijn omhoog om vervolgens onder de nieuwe, hogere maximale capaciteit te blijven fluctueren.
Op het moment T1 bereikt het systeem de zachte limiet en begint het uit te schalen. Als nieuwe resources niet op tijd aankomen, kan de vraag de bestaande resources uitputten en kan het systeem mislukken. Throttling weigert extra verzoeken tijdens het opschalen om het resourceverbruik onder de harde limiet te houden, en heft die beperkingen vervolgens op zodra de nieuwe capaciteit beschikbaar komt.
Tip
Edge-controls en het throttlingpatroon pakken verschillende problemen aan. Beveiligingsmaatregelen aan de rand, zoals Azure DDoS Protection en snelheidsbeperkingsregels van een web application firewall (WAF), worden aan de netwerkgrens toegepast en houden omvangrijk of schadelijk verkeer tegen voordat het uw toepassing bereikt. Het throttlingpatroon draait binnen uw toepassing en toetst legitiem verkeer aan door de toepassing gedefinieerde limieten. Gebruik beide lagen samen. DDoS-beveiliging voorkomt niet dat een legitieme gebruiker uw service overbelast en toepassingsbeperking absorbeert geen volumetrische aanval.
Problemen en overwegingen
Houd rekening met de volgende punten wanneer u besluit hoe u dit patroon implementeert:
Neem vroegtijdig beslissingen over beperkingen. Throttling is een architecturale beslissing die het hele systeem beïnvloedt. Achteraf aanpassen is duur.
Stem de smoorlimieten af op het onderdeel dat als eerste verzadigd raakt.
Aanvraagsnelheid is de meest bekende dimensie om te beperken, maar het echte knelpunt is vaak gelijktijdige aanvragen tijdens vlucht, wachtrijdiepte, CPU- of geheugengebruik, of de eigen limieten van een downstream-afhankelijkheid. Een limiet voor aanvragen per seconde beveiligt geen systeem waarvan het knelpunt gelijktijdigheid is op een fan-outpunt.
Bepaal bij elke grens waar snelheidsbeperking wordt afgedwongen, zoals de gateway, de service, een partitie of een afhankelijke downstreamservice, wat het eerst verzadigd raakt en stel de limiet in op basis van die dimensie. Zie het Bulkhead-patroon voor beveiliging met een begrenzing op gelijktijdigheid bij fan-outpunten; het vormt een aanvulling op snelheidsbeperking.
Kies opzettelijk een beperkend algoritme. Koppel het aan de tolerantie van het onderdeel dat u beveiligt.
Algoritme Gedrag en beste pasvorm Tokenbucket Ondersteunt pieken tot een ingestelde grootte en handhaaft een constante aanvulsnelheid. Gebruik dit voor gateways die korte pieken moeten absorberen. Lekkende emmer Verzendt met een constante snelheid. Gebruik deze functie voor back-ends waarvoor een constante ingangssnelheid nodig is. Vast venster Eenvoudig te implementeren, maar geeft back-to-back bursts toe aan venstergrenzen. Schuifvenster Verzacht het grensprobleem van vaste vensters, ten koste van meer statusinformatie. Beslis voor wie de limiet geldt. Verkeersbeperking op een grof afgebakend niveau, zoals een regionale gateway, kan veel andere, niet-verwante gebruikers treffen wanneer slechts enkelen van hen voor de belasting zorgen.
Bepaal waar de teller zich bevindt wanneer één limiet meerdere knooppunten omvat. Lokale tellers zijn snel, maar tellen te laag als dezelfde oproeper meerdere replica's bereikt. Een gecentraliseerd teller in een gedeelde winkel, zoals Redis, ziet elke aanvraag, maar voegt latentie toe aan elke beslissing. Om een globale frequentielimiet te benaderen, verdeelt u de limiet over replica's en synchroniseert u deze periodiek.
Neem snel bandbreedtebeperkingsbeslissingen. Het systeem moet toenemende belasting detecteren, reageren en terugkeren naar de normale toestand nadat de belasting afneemt. Voor dit proces is continue prestatie-instrumentatie vereist.
Verminder de belasting proactief, niet pas vlak voor instorting. Een begrenzer die pas verzoeken afwijst nadat een component verzadigd raakt, zorgt ervoor dat de latentie sterk oploopt voordat aanroepers enige tegendruk zien.
Naarmate het gebruik de harde limiet nadert, kunt u beginnen met het weigeren van een groeiende fractie van aanvragen. Vroegtijdige afwijzing geeft aan aanroepende clients het signaal om gas terug te nemen en voorkomt de latentie-instorting die abrupte limieten vaak veroorzaken. Gebruik p99-latentie ten opzichte van uw SLO als belangrijkste trigger. De gemiddelde benutting kan er gezond uitzien, terwijl de p99-waarde al is overschreden.
Waar u onderscheid kunt maken tussen de waarde van aanvragen, kunt u het best eerst minder waardevol werk of werk dat gemakkelijker opnieuw kan worden geprobeerd afstoten. Zie het patroon Prioriteitswachtrij voor meer informatie.
Geef een statuscode terug die de client laat weten wanneer een tijdelijke afwijzing het gevolg is van snelheidsbeperking:
- HTTP 429 (te veel aanvragen): De beller overschrijdt een geconfigureerde aanvraagsnelheid via een gedefinieerd venster.
- HTTP 503 (service niet beschikbaar): De service kan de aanvraag momenteel niet verwerken, vaak vanwege een onverwachte belastingpiek.
Neem een
Retry-AfterHTTP-header op zodat de client een strategie voor opnieuw proberen kan kiezen. Retourneer voldoende context voor de beller om het opzettelijk opnieuw te proberen in plaats van te raden. Geef bijvoorbeeld de limiet op die de beller overschrijdt, verheldeer het betreffende bereik of stel een snelheid voor die zou slagen. Onverklaarbare afwijzingen helpen bellers zich niet aan te passen.Signalen van overbelasting van uw afhankelijkheden doorgeven in plaats van ze te absorberen. Een service die aanroepen van callers afremt, moet ook rekening houden met de throttlingreacties die deze ontvangt van de eigen downstream-afhankelijkheden. Als uw service een downstream-respons met statuscode 429 of 503 verbergt door deze stilzwijgend opnieuw te proberen of door een algemene HTTP 500-respons (interne serverfout) te retourneren, kunnen aanroepende systemen niet vertragen, nemen retries toe en plant de overbelasting zich stroomopwaarts voort. Het retry storm-antipatroon beschrijft deze faalmodus. Geef tegendruk door aan upstream aanroepers, zodat de hele aanroepketen gezamenlijk belasting afbouwt.
Maak afwijzing goedkoper dan het werk dat hiermee wordt voorkomen. Als het weigeren van een aanvraag zware verificatie, grondige parsering of complexe beleidsevaluatie vereist, kan een overstroming van geweigerde aanvragen het systeem nog steeds overbelasten. Wijs verzoeken zo vroeg mogelijk in de requestpijplijn af en voer ook een belastingstest uit op het afwijzingspad zelf.
Houd rekening met situaties waarin throttling niet genoeg tijd oplevert voor automatisch opschalen. Als de vraag sneller groeit dan nieuwe capaciteit online komt, kan zelfs een beperkt systeem mislukken. Wanneer dit resultaat onaanvaardbaar is, behoudt u grotere capaciteitsreserves en configureert u agressievere automatische schaalaanpassing.
Gebruik cache niet als vervanging voor snelheidsbeperking. Een cache verlaagt de gemiddelde belasting van de oorsprong, maar de piekbelasting wordt niet gebonden. Elke aanvraag die niet in de cache wordt gevonden, wordt doorgestuurd naar de oorspronkelijke bron, en wanneer een veelgebruikte sleutel bij veel verkeer vervalt, kunnen veel aanroepen tegelijk proberen die opnieuw te vullen. Gebruik caching om de normale belasting te verlagen en throttling om het worstcasescenario te begrenzen. Voor meer informatie, zie het Cache-Aside-patroon.
Normaliseer resourcekosten voor verschillende bewerkingen, omdat ze doorgaans geen gelijke uitvoeringskosten hebben. De limieten voor throttling kunnen bijvoorbeeld hoger zijn voor leesbewerkingen en lager voor schrijfbewerkingen. Het negeren van kosten per bewerking kan de capaciteit uitputten en een aanvalsvector maken.
Maak de throttlingconfiguratie tijdens runtime wijzigbaar. Wanneer abnormale belasting binnenkomt, moet u limieten aanpassen zonder een implementatie. Implementaties zijn traag en riskant tijdens een incident. Het patroon voor externe configuratieopslag plaatst de configuratie extern, zodat u deze tijdens de uitvoering kunt wijzigen.
Overweeg adaptieve limieten in plaats van statische limieten. Sommige SDK's voor snelheidsbeperking reageren op latentie- of wachtrijdieptesignalen, zodat de limiet wordt afgestemd op de werkelijke toestand van componenten. Koppel altijd een adaptieve begrenzer met een ingesteld maximum.
Herzie uw limieten naarmate de workload verandert. Adaptieve begrenzers kunnen niet elk soort drift bijhouden, zoals SLO-wijzigingen, wijzigingen in afhankelijkheidscapaciteit of verschuivingen in kosten per bewerking. Plan periodieke beoordeling van operatoren aan de hand van die invoer.
Wanneer gebruikt u dit patroon?
Gebruik dit patroon:
Om een systeem binnen de SLO's te houden.
Om te voorkomen dat één tenant toepassingsbronnen in beslag kan maken.
Om pieken in activiteit te verwerken.
Als u het maximale resourceniveau wilt beperken dat een systeem nodig heeft.
Om rekenwerk met een lage prioriteit te verminderen tijdens periodes van hoge CO2-intensiteit van het elektriciteitsnet.
Werklastontwerp
Beoordeel hoe u het throttlingpatroon in het ontwerp van een workload kunt gebruiken om de doelstellingen en principes aan te pakken die aan bod komen in de pijlers van het Azure Well-Architected Framework. De volgende tabel bevat richtlijnen over hoe dit patroon de doelstellingen van elke pijler ondersteunt.
| Pijler | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| betrouwbaarheid ontwerpbeslissingen helpen uw workload tolerant te worden defect te raken en ervoor te zorgen dat deze herstelt naar een volledig functionerende status nadat er een storing is opgetreden. | U ontwerpt de limieten om resourceuitputting te voorkomen die tot storingen kan leiden. U kunt dit patroon ook gebruiken als controlemechanisme binnen een geleidelijk degradatieplan. - RE:07 Zelfbehoud |
| Beslissingen over beveiligingsontwerpen helpen de vertrouwelijkheid, integriteit en beschikbaarheid van de gegevens en systemen van uw workload te waarborgen. | U kunt de limieten ontwerpen om resourceuitputting te voorkomen die kan leiden tot geautomatiseerd misbruik van het systeem. - SE:06 Netwerkbeheer - SE:08 Versterking van middelen |
| Kostenoptimalisatie is gericht op het ondersteunen en verbeteren van het rendement van uw workload op investeringen. | De afgedwongen limieten kunnen kostenmodellering informeren en kunnen rechtstreeks worden gekoppeld aan het bedrijfsmodel van uw toepassing. Ze leggen ook duidelijke bovengrenzen op het gebruik, die kunnen worden meegenomen in de grootte van resources. - CO:02 Kostenmodel - CO:12 Schaalvoordelen |
| Prestatie-efficiëntie helpt uw workload efficiënt te voldoen aan de vereisten door middel van optimalisaties in schalen, gegevens en code. | Wanneer het systeem onder hoge vraag staat, helpt dit patroon congestie te beperken die kan leiden tot knelpunten in de prestaties. U kunt het ook gebruiken om proactief lawaaierige buurscenario's te voorkomen. - PE:02 Capaciteitsplanning - PE:05 Schaalverdeling en partitioneren |
Als dit patroon compromissen binnen een pijler introduceert, moet u deze tegen de doelstellingen van de andere pijlers overwegen.
Example
Het volgende diagram toont throttling in een multitenantsysteem.
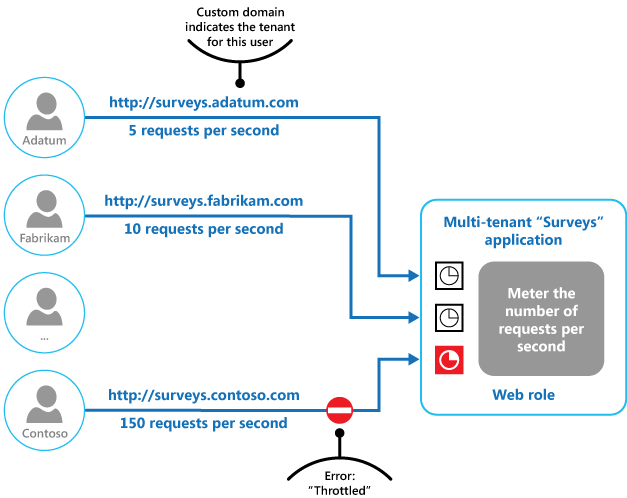
Drie gelabelde gebruikers aan de linkerkant vertegenwoordigen de tenants van de multitenant-toepassing Surveys: Adatum, Fabrikam en Contoso. Elke gebruiker verzendt aanvragen via een tenantspecifiek aangepast domein dat door de toepassing wordt gebruikt om de tenant te identificeren. Adatum verzendt 5 aanvragen per seconde via surveys.adatum.com, Fabrikam verzendt 10 aanvragen per seconde via surveys.fabrikam.com en Contoso verzendt 150 aanvragen per seconde via surveys.contoso.com. Rechts meet de webrol van de enquêtetoepassing het aantal aanvragen per seconde voor elke tenant. De Adatum- en Fabrikam-aanvraagstromen worden doorgegeven aan de toepassing. De Contoso-aanvraagstroom wordt geblokkeerd door een fout: beperkt antwoord omdat de snelheid de limiet per tenant overschrijdt.
Gebruikers van verschillende tenantorganisaties hebben toegang tot een in de cloud gehoste toepassing om enquêtes in te vullen en in te dienen. De toepassing bevat instrumentatie waarmee de snelheid wordt gecontroleerd waarmee de gebruikers van elke tenant aanvragen indienen.
Om te voorkomen dat gebruikers van één tenant de reactiesnelheid en beschikbaarheid voor gebruikers in andere tenants verminderen, beperkt de toepassing het aantal aanvragen per seconde dat elke tenant kan indienen. De toepassing blokkeert aanvragen die deze limiet overschrijden.
Volgende stap
Gerelateerde bronnen
- Het verbruik van elke tenant meten
- Autoscaling in Azure
- Wachtrijgebaseerd nivelleringspatroon
- Prioriteitswachtrijpatroon
- Patroon voor externe configuratie-opslag