Gegevensmodellering in Azure Cosmos DB
VAN TOEPASSING OP: ![]() NoSQL
NoSQL
Hoewel databases zonder schema's, zoals Azure Cosmos DB, het super eenvoudig maken om ongestructureerde en semi-gestructureerde gegevens op te slaan en op te vragen, moet u enige tijd besteden aan uw gegevensmodel om het meeste uit de service te halen wat betreft prestaties en schaalbaarheid en laagste kosten.
Hoe worden gegevens opgeslagen? Hoe gaat uw toepassing gegevens ophalen en er query's op uitvoeren? Is uw toepassing leesintensief of schrijfintensief?
Na het lezen van dit artikel kunt u de volgende vragen beantwoorden:
- Wat is gegevensmodellering en waarom kan het mij schelen?
- Hoe verschilt het modelleren van gegevens in Azure Cosmos DB in een relationele database?
- Hoe kan ik gegevensrelaties uitdrukken in een niet-relationele database?
- Wanneer kan ik gegevens insluiten en wanneer maak ik een koppeling naar gegevens?
Getallen in JSON
In Azure Cosmos DB worden documenten opgeslagen in JSON. Dit betekent dat u zorgvuldig moet bepalen of het nodig is getallen om te zetten in tekenreeksen voordat u ze opslaat in json of niet. Alle getallen moeten idealiter worden geconverteerd naar een String, als er een kans is dat ze zich buiten de grenzen van dubbele precisienummers bevinden volgens IEEE 754 binary64. De Json-specificatie noemt de redenen waarom het gebruik van getallen buiten deze grens in het algemeen een slechte gewoonte is in JSON vanwege waarschijnlijke interoperabiliteitsproblemen. Deze problemen zijn met name relevant voor de partitiesleutelkolom, omdat deze onveranderbaar is en gegevensmigratie later moet worden gewijzigd.
Gegevens insluiten
Wanneer u begint met het modelleren van gegevens in Azure Cosmos DB, probeert u uw entiteiten te behandelen als zelfstandige items die worden weergegeven als JSON-documenten.
Laten we eerst eens kijken hoe we gegevens in een relationele database kunnen modelleren. In het volgende voorbeeld ziet u hoe een persoon kan worden opgeslagen in een relationele database.
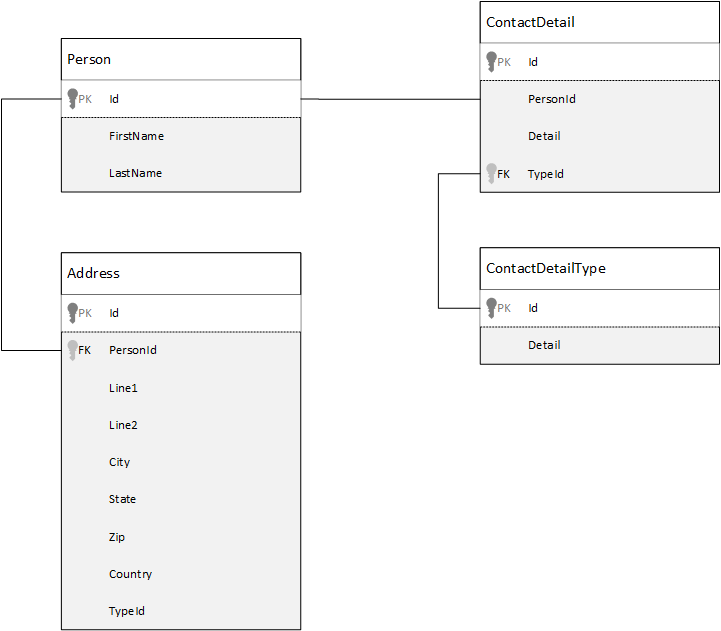
De strategie, bij het werken met relationele databases, is het normaliseren van al uw gegevens. Het normaliseren van uw gegevens omvat doorgaans het nemen van een entiteit, zoals een persoon, en het opsplitsen ervan in afzonderlijke onderdelen. In het bovenstaande voorbeeld kan een persoon meerdere records met contactgegevens en meerdere adresrecords hebben. Contactgegevens kunnen verder worden uitgesplitst door algemene velden zoals een type te extraheren. Hetzelfde geldt voor adres, elke record kan van het type Thuisgebruik of Zakelijk zijn.
Het uitgangspunt bij het normaliseren van gegevens is het voorkomen dat redundante gegevens op elke record worden opgeslagen en eerder verwijzen naar gegevens. Als u in dit voorbeeld een persoon met al hun contactgegevens en adressen wilt lezen, moet u JOINS gebruiken om uw gegevens effectief op te stellen (of te denormaliseren) tijdens runtime.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Schrijfbewerkingen in veel afzonderlijke tabellen zijn vereist om de contactgegevens en adressen van één persoon bij te werken.
Laten we nu eens kijken hoe we dezelfde gegevens modelleren als een zelfstandige entiteit in Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Met behulp van de bovenstaande benadering hebben we de persoonsrecord gedenormaliseerd door alle informatie over deze persoon, zoals contactgegevens en adressen, in te sluiten in één JSON-document. Bovendien hebben we, omdat we niet beperkt zijn tot een vast schema, de flexibiliteit om dingen te doen, zoals het volledig hebben van contactgegevens van verschillende shapes.
Het ophalen van een volledige persoonsrecord uit de database is nu één leesbewerking voor één container en voor één item. Het bijwerken van de contactgegevens en adressen van een persoonsrecord is ook één schrijfbewerking voor één item.
Door gegevens te denormaliseren, moet uw toepassing mogelijk minder query's en updates uitgeven om algemene bewerkingen te voltooien.
Wanneer moet ik insluiten?
Gebruik in het algemeen ingesloten gegevensmodellen wanneer:
- Er zijn ingesloten relaties tussen entiteiten.
- Er zijn een-op-weinig relaties tussen entiteiten.
- Er zijn ingesloten gegevens die onregelmatig worden gewijzigd.
- Er zijn ingesloten gegevens die niet zonder gebonden worden.
- Er zijn ingesloten gegevens die regelmatig samen worden opgevraagd.
Notitie
Normaal gesproken gedenormaliseerde gegevensmodellen bieden betere leesprestaties .
Wanneer niet insluiten
Hoewel de vuistregel in Azure Cosmos DB is om alles te denormaliseren en alle gegevens in één item in te sluiten, kan dit leiden tot bepaalde situaties die moeten worden vermeden.
Neem dit JSON-fragment.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Dit kan zijn hoe een postentiteit met ingesloten opmerkingen eruit zou zien als we een typisch blog- of CMS-systeem modelleren. Het probleem met dit voorbeeld is dat de opmerkingenmatrix niet afhankelijk is, wat betekent dat er geen (praktische) limiet is voor het aantal opmerkingen dat één bericht kan hebben. Dit kan een probleem worden omdat de grootte van het item oneindig groot kan worden, dus is een ontwerp dat u moet vermijden.
Naarmate de grootte van het item groter wordt, wordt de mogelijkheid om de gegevens over de kabel te verzenden en het item op schaal te lezen en bij te werken, beïnvloed.
In dit geval is het beter om rekening te houden met het volgende gegevensmodel.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Dit model heeft een document voor elke opmerking met een eigenschap die de post-id bevat. Hierdoor kunnen berichten een willekeurig aantal opmerkingen bevatten en kunnen ze efficiënt groeien. Gebruikers die meer willen zien dan de meest recente opmerkingen, voeren een query uit op deze container die de postId doorgeeft. Dit moet de partitiesleutel voor de opmerkingencontainer zijn.
Een ander geval waarbij het insluiten van gegevens niet een goed idee is, is wanneer de ingesloten gegevens vaak worden gebruikt in items en vaak worden gewijzigd.
Neem dit JSON-fragment.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Dit kan de aandelenportefeuille van een persoon vertegenwoordigen. We hebben ervoor gekozen om de voorraadgegevens in elk portfoliodocument in te sluiten. In een omgeving waarin gerelateerde gegevens vaak veranderen, zoals een beurstoepassing, betekent het insluiten van gegevens die vaak veranderen, dat u elk portfoliodocument voortdurend bijwerkt telkens wanneer een aandelen worden verhandeld.
Aandelen zbzb kunnen in één dag vele honderden keren worden verhandeld en duizenden gebruikers kunnen zbzb in hun portfolio hebben. Met een gegevensmodel zoals hierboven moeten we vele duizenden portfoliodocumenten vaak elke dag bijwerken, wat leidt tot een systeem dat niet goed kan worden geschaald.
Verwijzingsgegevens
Het insluiten van gegevens werkt in veel gevallen goed, maar er zijn scenario's waarin het denormaliseren van uw gegevens meer problemen veroorzaakt dan het waard is. Wat doen we nu?
Relationele databases zijn niet de enige plaats waar u relaties tussen entiteiten kunt maken. In een documentdatabase hebt u mogelijk informatie in het ene document dat betrekking heeft op gegevens in andere documenten. We raden u niet aan systemen te bouwen die beter geschikt zijn voor een relationele database in Azure Cosmos DB of een andere documentdatabase, maar eenvoudige relaties zijn prima en kunnen nuttig zijn.
In de JSON hieronder hebben we ervoor gekozen om het voorbeeld van een aandelenportefeuille van eerder te gebruiken, maar deze keer verwijzen we naar het aandelenitem in de portfolio in plaats van het insluiten ervan. Op deze manier is het enige document dat moet worden bijgewerkt, wanneer het voorraaditem de hele dag regelmatig wordt gewijzigd, het enige document dat moet worden bijgewerkt.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Een direct nadeel van deze aanpak is echter als uw toepassing informatie moet weergeven over elk aandeel dat wordt bewaard bij het weergeven van het portfolio van een persoon; In dit geval moet u meerdere ritten naar de database maken om de informatie voor elk voorraaddocument te laden. Hier hebben we besloten om de efficiëntie van schrijfbewerkingen te verbeteren, die de hele dag vaak plaatsvinden, maar op zijn beurt gecompromitteerd met de leesbewerkingen die mogelijk minder invloed hebben op de prestaties van dit specifieke systeem.
Notitie
Genormaliseerde gegevensmodellen kunnen meer retouren naar de server vereisen.
Hoe zit het met refererende sleutels?
Omdat er momenteel geen concept van een beperking, refererende sleutel of anderszins is, zijn alle relaties tussen documenten die u in documenten hebt effectief 'zwakke koppelingen' en worden ze niet geverifieerd door de database zelf. Als u ervoor wilt zorgen dat de gegevens waarnaar een document verwijst, daadwerkelijk bestaan, moet u dit doen in uw toepassing of met behulp van triggers aan de serverzijde of opgeslagen procedures in Azure Cosmos DB.
Wanneer moet worden verwezen
Gebruik over het algemeen genormaliseerde gegevensmodellen wanneer:
- Een-op-veel-relaties vertegenwoordigen.
- Veel-op-veel-relaties vertegenwoordigen.
- Gerelateerde gegevens worden regelmatig gewijzigd.
- Gegevens waarnaar wordt verwezen, kunnen niet-afhankelijk zijn.
Notitie
Normaliseren biedt doorgaans betere schrijfprestaties .
Waar zet ik de relatie?
De groei van de relatie helpt bepalen in welk document de verwijzing moet worden opgeslagen.
Als we de JSON hieronder bekijken, zien we uitgevers en boeken.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Als het aantal boeken per uitgever klein is met een beperkte groei, kan het opslaan van de boekreferentie in het uitgeversdocument nuttig zijn. Als het aantal boeken per uitgever echter niet afhankelijk is, zou dit gegevensmodel leiden tot veranderlijke, groeiende matrices, zoals in het bovenstaande voorbeelduitgeverdocument.
Als u een beetje wisselt, resulteert dit in een model dat nog steeds dezelfde gegevens vertegenwoordigt, maar nu voorkomt u deze grote onveranderbare verzamelingen.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
In het bovenstaande voorbeeld hebben we de niet-gebonden verzameling in het uitgeversdocument verwijderd. In plaats daarvan hebben we alleen een verwijzing naar de uitgever op elk boekdocument.
Hoe kan ik veel-op-veel-relaties modelleren?
In een relationele database worden veel-op-veel-relaties vaak gemodelleerd met samenvoegingstabellen, die alleen records uit andere tabellen samenvoegen.
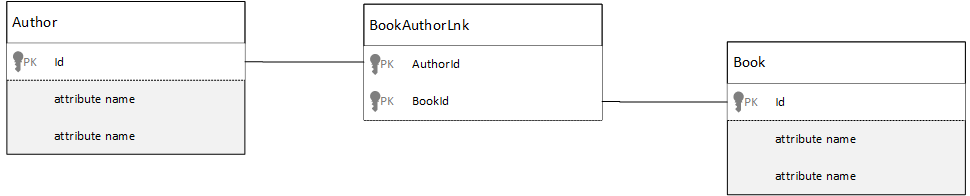
U bent misschien geneigd om hetzelfde te repliceren met behulp van documenten en een gegevensmodel te produceren dat er ongeveer als volgt uitziet.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Dit zou werken. Het laden van een auteur met hun boeken of het laden van een boek met de auteur vereist echter altijd ten minste twee extra query's voor de database. Eén query naar het samenvoegingsdocument en vervolgens een andere query om het werkelijke document dat wordt toegevoegd, op te halen.
Als deze join slechts twee stukjes gegevens aan elkaar lijmt, waarom dan niet helemaal wegvallen? Bekijk het volgende voorbeeld.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Als ik een auteur had, weet ik meteen welke boeken ze hebben geschreven, en omgekeerd als ik een boekdocument had geladen, zou ik de id's van de auteur(s) weten. Hierdoor wordt deze tussenliggende query opgeslagen in de jointabel, waardoor het aantal retouren van de server dat uw toepassing moet maken, wordt verminderd.
Hybride gegevensmodellen
We hebben nu gekeken naar het insluiten (of denormaliseren) en verwijzen naar (of normaliseren) gegevens. Elke aanpak heeft voordelen en compromissen.
Het hoeft niet altijd een van beide te zijn of, wees niet bang om dingen een beetje te verwarren.
Op basis van de specifieke gebruikspatronen en werkbelastingen van uw toepassing kunnen er gevallen zijn waarin het combineren van ingesloten en verwezen gegevens zinvol is en kan leiden tot eenvoudigere toepassingslogica met minder serverrondes en tegelijkertijd een goed prestatieniveau behouden.
Houd rekening met de volgende JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Hier hebben we (meestal) het ingesloten model gevolgd, waarbij gegevens van andere entiteiten zijn ingesloten in het document op het hoogste niveau, maar naar andere gegevens wordt verwezen.
Als u het boekdocument bekijkt, zien we een paar interessante velden wanneer we kijken naar de matrix met auteurs. Er is een id veld dat het veld is dat we gebruiken om terug te verwijzen naar een auteurdocument, standaardpraktijk in een genormaliseerd model, maar dan hebben name we ook en thumbnailUrl. We kunnen de toepassing vastlopen id en verlaten om eventuele aanvullende informatie op te halen die nodig is uit het respectieve auteurdocument met behulp van de koppeling, maar omdat in onze toepassing de naam van de auteur en een miniatuurafbeelding worden weergegeven, kunnen we een retour naar de server per boek opslaan in een lijst door enkele gegevens van de auteur te denormaliseren.
Als de naam van de auteur is gewijzigd of als ze hun foto willen bijwerken, moeten we elk boek dat ze ooit hebben gepubliceerd, bijwerken, maar voor onze toepassing, op basis van de veronderstelling dat auteurs hun namen niet vaak wijzigen, is dit een acceptabel ontwerpbesluit.
In het voorbeeld zijn er vooraf berekende waarden om dure verwerking te besparen bij een leesbewerking. In het voorbeeld zijn sommige van de gegevens die zijn ingesloten in het auteurdocument gegevens die tijdens runtime worden berekend. Telkens wanneer een nieuw boek wordt gepubliceerd, wordt er een boekdocument gemaakt en wordt het veld countOfBooks ingesteld op een berekende waarde op basis van het aantal boekdocumenten dat voor een bepaalde auteur bestaat. Deze optimalisatie zou goed zijn in leesintensieve systemen, waar we het ons kunnen veroorloven om berekeningen op schrijfbewerkingen uit te voeren om leesbewerkingen te optimaliseren.
De mogelijkheid om een model met vooraf berekende velden te hebben, wordt mogelijk gemaakt omdat Azure Cosmos DB ondersteuning biedt voor transacties met meerdere documenten. Veel NoSQL-winkels kunnen geen transacties uitvoeren in documenten en daarom pleiten voor ontwerpbeslissingen, zoals 'altijd alles insluiten', vanwege deze beperking. Met Azure Cosmos DB kunt u triggers aan de serverzijde of opgeslagen procedures gebruiken die boeken invoegen en auteurs bijwerken, allemaal binnen een ACID-transactie. Nu hoeft u niet alles in één document in te sluiten om er zeker van te zijn dat uw gegevens consistent blijven.
Onderscheid maken tussen verschillende documenttypen
In sommige scenario's wilt u mogelijk verschillende documenttypen combineren in dezelfde verzameling; Dit is meestal het geval wanneer u meerdere gerelateerde documenten in dezelfde partitie wilt hebben. U kunt bijvoorbeeld zowel boeken als boekrecensies in dezelfde collectie plaatsen en partitioneren door bookId. In dergelijke situaties wilt u meestal aan uw documenten toevoegen met een veld dat hun type identificeert om ze te onderscheiden.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Gegevensmodellering voor Analytische opslag van Azure Synapse Link en Azure Cosmos DB
Azure Synapse Link voor Azure Cosmos DB is een cloudeigen HTAP-mogelijkheid (Hybrid Transactional and Analytical Processing) waarmee u bijna realtime analyses kunt uitvoeren op operationele gegevens in Azure Cosmos DB. Azure Synapse Link zorgt voor een naadloze integratie tussen Azure Cosmos DB en Azure Synapse Analytics.
Deze integratie vindt plaats via analytische opslag van Azure Cosmos DB, een kolomweergave van uw transactionele gegevens die grootschalige analyses mogelijk maken zonder dat dit van invloed is op uw transactionele workloads. Deze analytische opslag is geschikt voor snelle, rendabele query's op grote operationele gegevenssets, zonder gegevens te kopiëren en de prestaties van uw transactionele workloads te beïnvloeden. Wanneer u een container maakt waarvoor analytische opslag is ingeschakeld, of wanneer u analytische opslag inschakelt voor een bestaande container, worden alle transactionele invoegingen, updates en verwijderingen in bijna realtime gesynchroniseerd met analytische opslag. Er zijn geen wijzigingenfeed- of ETL-taken vereist.
Met Azure Synapse Link kunt u nu rechtstreeks verbinding maken met uw Azure Cosmos DB-containers vanuit Azure Synapse Analytics en toegang krijgen tot de analytische opslag, zonder kosten voor aanvraageenheden (aanvraageenheden). Azure Synapse Analytics ondersteunt momenteel Azure Synapse Link met Synapse Apache Spark en serverloze SQL-pools. Als u een wereldwijd gedistribueerd Azure Cosmos DB-account hebt nadat u analytische opslag voor een container hebt ingeschakeld, is dit beschikbaar in alle regio's voor dat account.
Automatische schemadeductie van analytische opslag
Azure Cosmos DB transactionele opslag wordt beschouwd als rijgeoriënteerde semi-gestructureerde gegevens, maar analytische opslag heeft een kolom- en gestructureerde indeling. Deze conversie wordt automatisch uitgevoerd voor klanten met behulp van de schemadeductieregels voor de analytische opslag. Er zijn limieten in het conversieproces: het maximum aantal geneste niveaus, het maximum aantal eigenschappen, niet-ondersteunde gegevenstypen en meer.
Notitie
In de context van analytische opslag beschouwen we de volgende structuren als eigenschap:
- JSON-elementen of tekenreeks-waardeparen gescheiden door een
:". - JSON-objecten, gescheiden door
{en}. - JSON-matrices, gescheiden door
[en].
U kunt de impact van de schemadeductieconversies minimaliseren en uw analytische mogelijkheden maximaliseren met behulp van de volgende technieken.
Normalisatie
Normalisatie wordt betekenisloos omdat u met Azure Synapse Link verbinding kunt maken tussen uw containers met behulp van T-SQL of Spark SQL. De verwachte voordelen van normalisatie zijn:
- Kleinere gegevensvoetafdruk in zowel transactionele als analytische opslag.
- Kleinere transacties.
- Minder eigenschappen per document.
- Gegevensstructuren met minder geneste niveaus.
Houd er rekening mee dat deze laatste twee factoren, minder eigenschappen en minder niveaus, helpen bij de prestaties van uw analytische query's, maar ook de kans verkleinen dat delen van uw gegevens niet worden weergegeven in de analytische opslag. Zoals beschreven in het artikel over regels voor automatische schemadeductie, zijn er limieten voor het aantal niveaus en eigenschappen dat wordt weergegeven in de analytische opslag.
Een andere belangrijke factor voor normalisatie is dat serverloze SQL-pools in Azure Synapse resultatensets ondersteunen met maximaal 1000 kolommen en dat het weergeven van geneste kolommen ook telt voor die limiet. Met andere woorden, zowel analytische opslag als serverloze Synapse SQL-pools hebben een limiet van 1000 eigenschappen.
Maar wat te doen sinds denormalisatie is een belangrijke gegevensmodelleringstechniek voor Azure Cosmos DB? Het antwoord is dat u de juiste balans moet vinden voor uw transactionele en analytische workloads.
Partitiesleutel
Uw Azure Cosmos DB-partitiesleutel (PK) wordt niet gebruikt in de analytische opslag. En nu kunt u aangepaste partitionering van analytische opslag gebruiken om kopieën van analytische opslag te maken met behulp van pk's die u wilt gebruiken. Vanwege deze isolatie kunt u een PK voor uw transactionele gegevens kiezen met de focus op gegevensopname en puntleesbewerkingen, terwijl query's tussen partities kunnen worden uitgevoerd met Azure Synapse Link. Laten we een voorbeeld bekijken:
In een hypothetisch globaal IoT-scenario is het een goede PK omdat device id alle apparaten een vergelijkbaar gegevensvolume hebben en daarmee geen probleem met een hot partition hebben. Maar als u de gegevens van meer dan één apparaat wilt analyseren, zoals 'alle gegevens van gisteren' of 'totalen per stad', hebt u mogelijk problemen omdat dit query's tussen partities zijn. Deze query's kunnen uw transactionele prestaties schaden, omdat ze een deel van uw doorvoer gebruiken in aanvraageenheden om uit te voeren. Maar met Azure Synapse Link kunt u deze analytische query's zonder kosten voor aanvraageenheden uitvoeren. Kolomindeling voor analytische opslag is geoptimaliseerd voor analytische query's en Azure Synapse Link past dit kenmerk toe om goede prestaties met Azure Synapse Analytics-runtimes mogelijk te maken.
Namen van gegevenstypen en eigenschappen
In het artikel met regels voor automatische schemadeductie wordt vermeld wat de ondersteunde gegevenstypen zijn. Hoewel niet-ondersteund gegevenstype de weergave in de analytische opslag blokkeert, kunnen ondersteunde gegevenstypen anders worden verwerkt door de Azure Synapse-runtimes. Een voorbeeld hiervan is: Wanneer u DateTime-tekenreeksen gebruikt die voldoen aan de ISO 8601 UTC-standaard, vertegenwoordigen Spark-pools in Azure Synapse deze kolommen als tekenreeks en SERVERloze SQL-pools in Azure Synapse worden deze kolommen weergegeven als varchar(8000).
Een andere uitdaging is dat niet alle tekens worden geaccepteerd door Azure Synapse Spark. Hoewel witruimten worden geaccepteerd, worden tekens zoals dubbele punt, accent grave en komma niet geaccepteerd. Stel dat uw document een eigenschap heeft met de naam Voornaam, Achternaam. Deze eigenschap wordt weergegeven in de analytische opslag en de serverloze Synapse SQL-pool kan deze zonder problemen lezen. Maar omdat het zich in de analytische opslag bevindt, kan Azure Synapse Spark geen gegevens lezen uit de analytische opslag, inclusief alle andere eigenschappen. Aan het einde van de dag kunt u Azure Synapse Spark niet gebruiken wanneer u één eigenschap hebt met behulp van de niet-ondersteunde tekens in hun naam.
Gegevens platmaken
Alle eigenschappen op het hoofdniveau van uw Azure Cosmos DB-gegevens worden weergegeven in de analytische opslag als kolom en alle andere eigenschappen die zich in diepere niveaus van uw documentgegevensmodel bevinden, worden weergegeven als JSON, ook in geneste structuren. Geneste structuren vereisen extra verwerking van Azure Synapse-runtimes om de gegevens in gestructureerde indeling te platmaken, wat een uitdaging kan zijn in big data-scenario's.
Het onderstaande document heeft slechts twee kolommen in de analytische opslag en id contactDetails. Alle andere gegevens email en phone, vereisen extra verwerking via SQL-functies om afzonderlijk te worden gelezen.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Het onderstaande document bevat drie kolommen in de analytische opslag, id, en phoneemail. Alle gegevens zijn rechtstreeks toegankelijk als kolommen.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Gegevenslagen
Met Azure Synapse Link kunt u de kosten verlagen vanuit de volgende perspectieven:
- Minder query's die worden uitgevoerd in uw transactionele database.
- Een PK die is geoptimaliseerd voor gegevensopname en puntleesbewerkingen, waardoor de gegevensvoetafdruk, dynamische partitiescenario's en partities worden gesplitst.
- Gegevenslagen omdat analytische time-to-live (attl) onafhankelijk is van transactionele time-to-live (tttl). U kunt uw transactionele gegevens enkele dagen, weken, maanden bewaren en de gegevens in de analytische opslag jarenlang of voor altijd bewaren. Kolomindeling voor analytische opslag zorgt voor een natuurlijke gegevenscompressie, van 50% tot 90%. En de kosten per GB zijn ongeveer 10% van de werkelijke prijs van het transactionele archief. Zie het overzicht van analytische opslag voor meer informatie over de huidige back-upbeperkingen.
- Er worden geen ETL-taken uitgevoerd in uw omgeving, wat betekent dat u hiervoor geen aanvraageenheden hoeft in te richten.
Gecontroleerde redundantie
Dit is een goed alternatief voor situaties waarin al een gegevensmodel bestaat en niet kan worden gewijzigd. En het bestaande gegevensmodel past niet goed in de analytische opslag vanwege automatische schemadeductieregels, zoals de limiet van geneste niveaus of het maximum aantal eigenschappen. Als dit het geval is, kunt u Azure Cosmos DB-wijzigingenfeed gebruiken om uw gegevens te repliceren naar een andere container, waarbij u de vereiste transformaties toepast voor een gebruiksvriendelijk gegevensmodel van Azure Synapse Link. Laten we een voorbeeld bekijken:
Scenario
Container CustomersOrdersAndItems wordt gebruikt voor het opslaan van on-line orders, inclusief klant- en itemsgegevens: factureringsadres, leveringsadres, leveringsmethode, leveringsstatus, prijs van artikelen, enzovoort. Alleen de eerste 1000 eigenschappen worden weergegeven en belangrijke informatie is niet opgenomen in de analytische opslag, waardoor het gebruik van Azure Synapse Link wordt geblokkeerd. De container heeft EEN DATABASE met records. Het is niet mogelijk om de toepassing te wijzigen en de gegevens opnieuw te modelleren.
Een ander perspectief van het probleem is het big data-volume. Miljarden rijen worden voortdurend gebruikt door de analyseafdeling, wat voorkomt dat ze tttl gebruiken voor oude gegevensverwijdering. Het onderhouden van de volledige gegevensgeschiedenis in de transactionele database vanwege analytische behoeften dwingt hen om de inrichting van aanvraageenheden voortdurend te verhogen, wat van invloed is op de kosten. Transactionele en analytische workloads concurreren tegelijkertijd voor dezelfde resources.
Wat u moet doen?
Oplossing met wijzigingenfeed
- Het technische team heeft besloten om wijzigingenfeed te gebruiken om drie nieuwe containers te vullen:
Customers,OrdersenItems. Met Wijzigingenfeed worden de gegevens genormaliseerd en platgemaakt. Overbodige informatie wordt verwijderd uit het gegevensmodel en elke container heeft bijna 100 eigenschappen, waardoor gegevensverlies wordt voorkomen als gevolg van automatische schemadeductielimieten. - Deze nieuwe containers hebben analytische opslag ingeschakeld en nu gebruikt de Analyseafdeling Synapse Analytics om de gegevens te lezen, waardoor het gebruik van aanvraageenheden wordt verminderd omdat de analytische query's plaatsvinden in Synapse Apache Spark en serverloze SQL-pools.
- Container
CustomersOrdersAndItemsheeft nu tttl ingesteld om alleen gegevens zes maanden te bewaren, waardoor het gebruik van aanvraageenheden kan worden verminderd, omdat er minimaal 1 aanvraageenheden per GB in Azure Cosmos DB zijn. Minder gegevens, minder aanvraageenheden.
Opgedane kennis
De belangrijkste punten uit dit artikel zijn om te begrijpen dat gegevensmodellering in een wereld die schemavrij is, net zo belangrijk is als ooit.
Net zoals er geen enkele manier is om een stukje gegevens op een scherm weer te geven, is er geen enkele manier om uw gegevens te modelleren. U moet uw toepassing begrijpen en hoe deze de gegevens produceert, verbruikt en verwerkt. Door vervolgens enkele van de hier gepresenteerde richtlijnen toe te passen, kunt u instellen hoe u een model maakt dat tegemoetkomt aan de onmiddellijke behoeften van uw toepassing. Wanneer uw toepassingen moeten veranderen, kunt u de flexibiliteit van een database zonder schema gebruiken om die wijziging te omarmen en uw gegevensmodel eenvoudig te ontwikkelen.
Volgende stappen
Raadpleeg de documentatiepagina van de service voor meer informatie over Azure Cosmos DB.
Als u wilt weten hoe u uw gegevens over meerdere partities kunt sharden, raadpleegt u Partitioneringsgegevens in Azure Cosmos DB.
Voor meer informatie over het modelleren en partitioneren van gegevens in Azure Cosmos DB met behulp van een praktijkvoorbeeld, raadpleegt u Gegevensmodellering en partitionering, een praktijkvoorbeeld.
Zie de trainingsmodule voor het modelleren en partitioneren van uw gegevens in Azure Cosmos DB.
Configureer en gebruik Azure Synapse Link voor Azure Cosmos DB.
Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB? U kunt informatie over uw bestaande databasecluster gebruiken voor capaciteitsplanning.
- Als alles wat u weet het aantal vCores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor