Genormaliseerd databaseschema migreren van Azure SQL Database naar een gedenormaliseerde Azure Cosmos DB-container
In deze handleiding wordt uitgelegd hoe u een bestaand genormaliseerd databaseschema in Azure SQL Database gebruikt en converteert naar een gedenormaliseerd Azure Cosmos DB-schema voor laden in Azure Cosmos DB.
SQL-schema's worden doorgaans gemodelleerd met een derde normale vorm, wat resulteert in genormaliseerde schema's die een hoge mate van gegevensintegriteit bieden en minder dubbele gegevenswaarden. Query's kunnen entiteiten samenvoegen tussen tabellen om te lezen. Azure Cosmos DB is geoptimaliseerd voor super snelle transacties en het uitvoeren van query's in een verzameling of container via gedenormaliseerde schema's met gegevens op zichzelf in een document.
Met Behulp van Azure Data Factory bouwen we een pijplijn die gebruikmaakt van één toewijzing Gegevensstroom om te lezen uit twee genormaliseerde Azure SQL Database-tabellen die primaire en refererende sleutels bevatten als entiteitsrelatie. Data Factory voegt deze tabellen samen in één stroom met behulp van de Spark-engine voor de gegevensstroom, verzamelt samengevoegde rijen in matrices en produceert afzonderlijke opgeschoonde documenten om in te voegen in een nieuwe Azure Cosmos DB-container.
In deze handleiding wordt snel een nieuwe container gebouwd met de naam 'orders' die de SalesOrderHeader en SalesOrderDetail tabellen uit de standaard sql Server Adventure Works-voorbeelddatabase gaan gebruiken. Deze tabellen vertegenwoordigen verkooptransacties die zijn samengevoegd door SalesOrderID. Elke unieke detailrecord heeft een eigen primaire sleutel van SalesOrderDetailID. De relatie tussen koptekst en detail is 1:M. We voegen deel aan SalesOrderID in ADF en rollen vervolgens elke gerelateerde detailrecord in een matrix met de naam 'detail'.
De representatieve SQL-query voor deze handleiding is:
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
De resulterende Azure Cosmos DB-container sluit de interne query in één document in en ziet er als volgt uit:

Een pipeline maken
Selecteer +Nieuwe pijplijn om een nieuwe pijplijn te maken.
Een gegevensstroomactiviteit toevoegen
Selecteer nieuwe toewijzingsgegevensstroom in de gegevensstroomactiviteit.
We maken deze gegevensstroomgrafiek:

Definieer de bron voor SourceOrderDetails. Maak voor de gegevensset een nieuwe Azure SQL Database-gegevensset die verwijst naar de
SalesOrderDetailtabel.Definieer de bron voor SourceOrderHeader. Maak voor de gegevensset een nieuwe Azure SQL Database-gegevensset die verwijst naar de
SalesOrderHeadertabel.Voeg aan de bovenste bron een transformatie van afgeleide kolommen toe na SourceOrderDetails. Roep de nieuwe transformatie 'TypeCast' aan. We moeten de
UnitPricekolom afronden en casten naar een dubbel gegevenstype voor Azure Cosmos DB. Stel de formule in op:toDouble(round(UnitPrice,2)).Voeg nog een afgeleide kolom toe en noem deze 'MakeStruct'. Hier maken we een hiërarchische structuur voor het opslaan van de waarden uit de detailtabel. Details zijn een
M:1relatie met headers. Geef de nieuwe structuurorderdetailsstructeen naam en maak de hiërarchie op deze manier, waarbij elke subkolom wordt ingesteld op de naam van de binnenkomende kolom:
Nu gaan we naar de bron van de verkoopheader. Voeg een jointransformatie toe. Selecteer 'MakeStruct' aan de rechterkant. Laat deze ingesteld op inner join en kies
SalesOrderIDvoor beide zijden van de joinvoorwaarde.Selecteer het tabblad Gegevensvoorbeeld in de nieuwe join die u hebt toegevoegd, zodat u uw resultaten tot nu toe kunt zien. U ziet nu alle veldnamenrijen die zijn gekoppeld aan de detailrijen. Dit is het resultaat van de samenvoeging die wordt gevormd door de
SalesOrderID. Vervolgens combineren we de details van de gemeenschappelijke rijen in de detailstruct en aggregeren we de gemeenschappelijke rijen.
Voordat we de matrices kunnen maken om deze rijen te denormaliseren, moeten we eerst ongewenste kolommen verwijderen en ervoor zorgen dat de gegevenswaarden overeenkomen met azure Cosmos DB-gegevenstypen.
Voeg vervolgens een transformatie selecteren toe en stel de veldtoewijzing zo in dat deze er als volgt uitziet:

Nu gaan we weer een valutakolom casten, deze keer
TotalDue. Zoals we hierboven in stap 7 hebben gedaan, stelt u de formule in op:toDouble(round(TotalDue,2)).Hier ziet u waar we de rijen denormaliseren door de gemeenschappelijke sleutel
SalesOrderIDte groeperen. Voeg een statistische transformatie toe en stel de groep in opSalesOrderID.Voeg in de statistische formule een nieuwe kolom toe met de naam 'details' en gebruik deze formule om de waarden te verzamelen in de structuur die we eerder
orderdetailsstructhebben gemaakt:collect(orderdetailsstruct).De statistische transformatie levert alleen kolommen op die deel uitmaken van aggregaties of groeperen op formules. Daarom moeten we ook de kolommen uit de koptekst van de verkoop opnemen. Hiervoor voegt u een kolompatroon toe aan dezelfde statistische transformatie. Dit patroon omvat alle andere kolommen in de uitvoer, met uitzondering van de onderstaande kolommen (OrderQty, UnitPrice, SalesOrderID):
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
Gebruik de syntaxis 'this' ($$) in de andere eigenschappen, zodat we dezelfde kolomnamen behouden en de
first()functie gebruiken als een statistische functie. Dit vertelt ADF dat de eerste overeenkomende waarde moet worden gevonden:
We zijn klaar om de migratiestroom te voltooien door een sinktransformatie toe te voegen. Selecteer 'nieuw' naast de gegevensset en voeg een Azure Cosmos DB-gegevensset toe die verwijst naar uw Azure Cosmos DB-database. Voor de verzameling noemen we het 'orders' en het heeft geen schema en geen documenten omdat deze onmiddellijk wordt gemaakt.
In Sink-instellingen, partitiesleutel naar
/SalesOrderIDen verzamelingsactie om opnieuw te maken. Controleer of het tabblad Toewijzing er als volgt uitziet:
Selecteer een voorbeeld van gegevens om ervoor te zorgen dat deze 32 rijen zijn ingesteld om als nieuwe documenten in uw nieuwe container in te voegen:
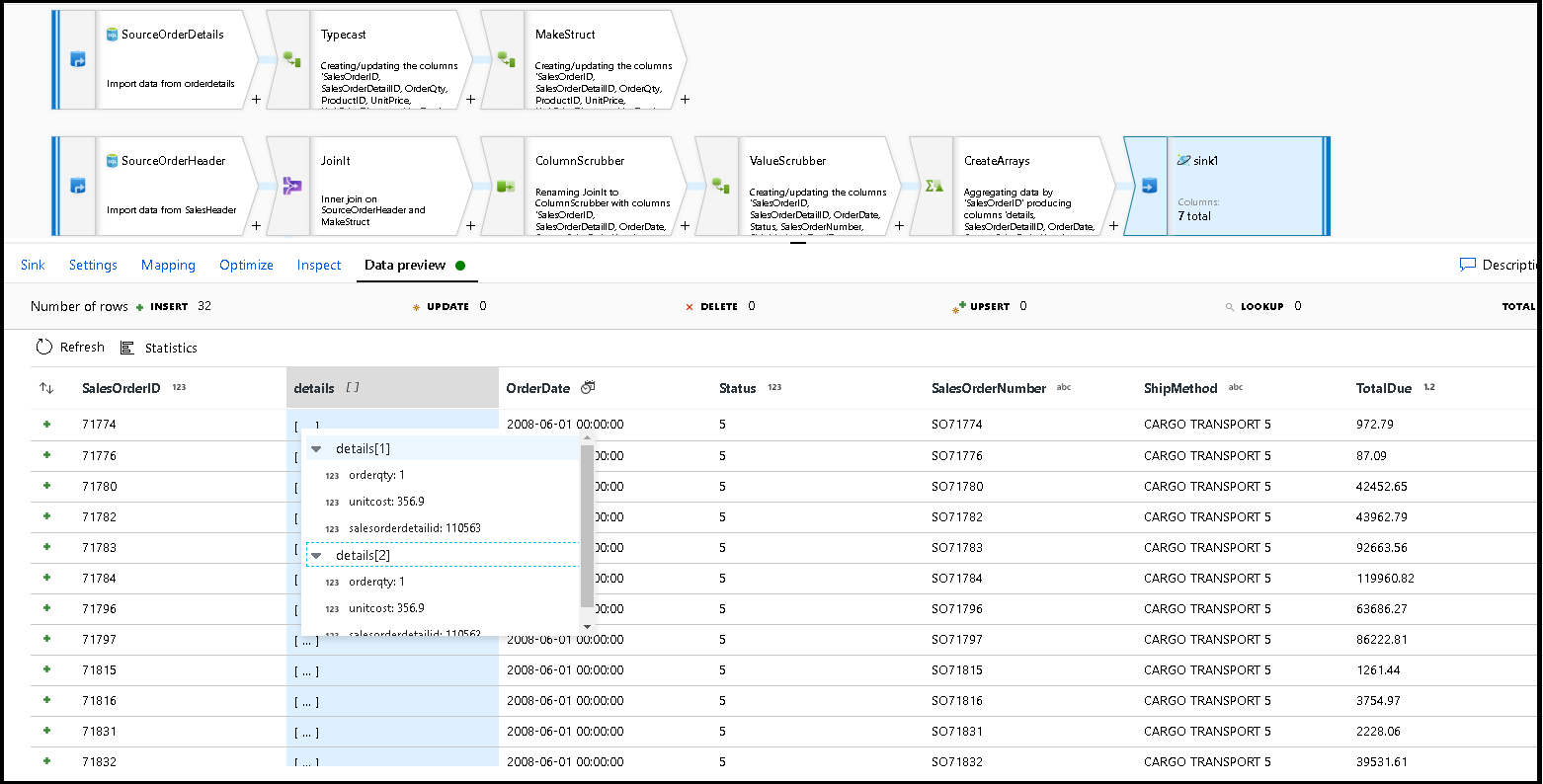
Als alles er goed uitziet, bent u nu klaar om een nieuwe pijplijn te maken, voegt u deze gegevensstroomactiviteit toe aan die pijplijn en voert u deze uit. U kunt uitvoeren vanuit foutopsporing of een geactiveerde uitvoering. Na een paar minuten hebt u een nieuwe gedenormaliseerde container met orders met de naam 'orders' in uw Azure Cosmos DB-database.
Gerelateerde inhoud
- Bouw de rest van uw gegevensstroomlogica met behulp van transformaties van toewijzingsgegevensstromen.
- Download de voltooide pijplijnsjabloon voor deze zelfstudie en importeer de sjabloon in uw fabriek.