Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Meer informatie over het maken van een nieuwe pijplijn met behulp van Lakeflow Spark Declarative Pipelines (SDP) voor gegevensindeling en Automatisch laden. In deze handleiding wordt de voorbeeldpijplijn van gegevens uitgebreid door de gegevens te reinigen en een query te maken om de top 100 gebruikers te vinden.
In deze zelfstudie leert u hoe u de Lakeflow Pipelines Editor gebruikt voor het volgende:
- Maak een nieuwe pijplijn met de standaardmapstructuur en begin met een set voorbeeldbestanden.
- Beperkingen voor gegevenskwaliteit definiëren aan de hand van verwachtingen.
- Gebruik de editorfuncties om de pijplijn uit te breiden met een nieuwe transformatie om analyses uit te voeren op uw gegevens.
Requirements
Voordat u aan deze zelfstudie begint, moet u het volgende doen:
- Meld u aan bij een Azure Databricks werkruimte.
- Laat Unity Catalog zijn ingeschakeld voor uw werkruimte.
- U bent gemachtigd om een rekenresource te maken of toegang te krijgen tot een rekenresource.
- Machtigingen hebben om een nieuw schema in een catalogus te maken. De vereiste machtigingen zijn
ALL PRIVILEGESofUSE CATALOGenCREATE SCHEMA.
Stap 1: Een pijplijn maken
In deze stap maakt u een pijplijn met behulp van de standaardmapstructuur en codevoorbeelden. De codevoorbeelden verwijzen naar de users tabel in de wanderbricks voorbeeldgegevensbron.
Klik in uw Azure Databricks-werkruimte op
 Nieuw en vervolgens
Nieuw en vervolgens  ETL-pijplijn. Hiermee opent u de pijplijneditor met een standaardpijplijnnaam, zoals
ETL-pijplijn. Hiermee opent u de pijplijneditor met een standaardpijplijnnaam, zoals New Pipeline <date> <time>.(Optioneel) Selecteer de naam en voer een beschrijvende naam in voor de pijplijn.
(Optioneel) Klik rechts van de naam op de catalogus en het schema om verschillende standaardwaarden in te stellen.
(Optioneel) Selecteer in het
my_transformationbronbestand dat voor u is gemaakt Python of SQL in de vervolgkeuzelijst taal om de taal voor het bestand in te stellen.Klik op
 Gebruik voorbeeldcode.
Gebruik voorbeeldcode.Voorbeeldcode in de geselecteerde taal wordt weergegeven in het
my_transformationbronbestand in detransformationsmap. De uitvoergegevenssets zijn nog niet gemaakt en de pijplijngrafiek aan de rechterkant van het scherm is leeg.Als u de pijplijncode (de code in de
transformationsmap) wilt uitvoeren, klikt u in de rechterbovenhoek van het scherm op Pijplijn uitvoeren .Nadat de uitvoering is afgerond, worden onder in de werkruimte de twee nieuwe tabellen weergegeven die zijn gemaakt:
sample_users_<date_time>ensample_aggregation_<date_time>. De pijplijngrafiek aan de rechterkant van de werkruimte toont nu de twee tabellen, waarbijsample_usersde bron is voorsample_aggregation. Noteer de volledigesample_users_<date_time>tabelnaam. In de volgende stap verwijst u ernaar.
Stap 2: Gegevenskwaliteitscontroles toepassen
In deze stap voegt u een gegevenskwaliteitscontrole toe aan de sample_users tabel. U gebruikt pijplijnwachtingen om de gegevens te beperken. In dit geval verwijdert u alle gebruikersrecords die geen geldig e-mailadres hebben en voert u de opgeschoonde tabel uit als users_cleaned.
Klik in de browser voor pijplijnasset aan de linkerkant op
en selecteer Transformatie.Maak in het dialoogvenster Nieuw transformatiebestand maken de volgende selecties:
- Kies Python of SQL voor de Language. Dit hoeft niet overeen te komen met uw vorige selectie.
- Geef het bestand een naam. Kies
users_cleanedin dit geval . - Laat voor het doelpad de standaardwaarde staan.
- Voor het type gegevensset laat u het op Geen geselecteerd staan of kiest u gematerialiseerde weergave. Als u gerealiseerde weergave selecteert, wordt voorbeeldcode voor u gegenereerd.
Klik op Maken om het transformatiecodebestand te maken.
Bewerk de code in het nieuwe codebestand zodat deze overeenkomt met het volgende (gebruik SQL of Python, op basis van uw selectie op het vorige scherm). Vervang
sample_users_<date_time>door de volledige naam van desample_userstabel uit de vorige sectie.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Klik op Pijplijn uitvoeren om de pijplijn bij te werken. Er moeten nu drie tabellen zijn.
Stap 3: De belangrijkste gebruikers analyseren
Haal vervolgens de top 100 gebruikers op op het aantal boekingen dat ze hebben gemaakt. Voeg de wanderbricks.bookings tabel toe aan de users_cleaned gerealiseerde weergave.
Klik in de browser voor pijplijnasset aan de linkerkant op
en selecteer Transformatie.Maak in het dialoogvenster Nieuw transformatiebestand maken de volgende selecties:
- Kies Python of SQL voor de Language. Dit hoeft niet overeen te komen met uw vorige selecties.
- Geef het bestand een naam. Kies
users_and_bookingsin dit geval . - Laat voor het doelpad de standaardwaarde staan.
- Voor het type gegevensset laat u het op Geen geselecteerd.
Klik op Maken om het transformatiecodebestand te maken.
Bewerk de code in het nieuwe codebestand zodat deze overeenkomt met het volgende (gebruik SQL of Python, op basis van uw selectie op het vorige scherm).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Klik op Pijplijn uitvoeren om de gegevenssets bij te werken. Wanneer de uitvoering is voltooid, ziet u in de pijplijngrafiek dat er vier tabellen zijn, inclusief de nieuwe
users_and_bookingstabel.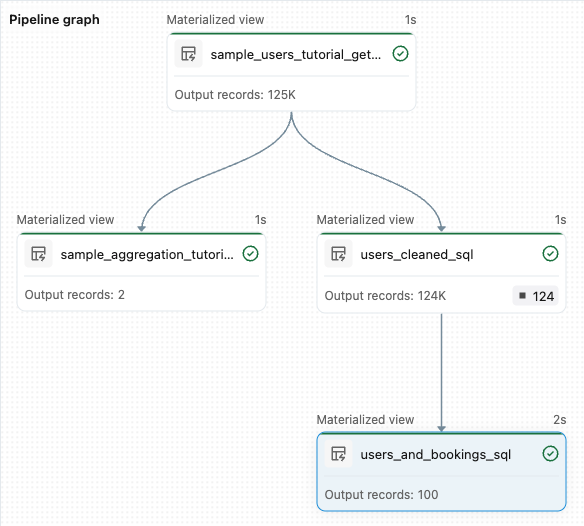
Volgende stappen
Nu u hebt geleerd hoe u enkele van de functies van de Lakeflow-pijplijneditor kunt gebruiken en een pijplijn kunt maken, vindt u hier enkele andere functies voor meer informatie over:
Hulpprogramma's voor het werken met transformaties en foutopsporing tijdens het maken van pijplijnen:
- Selectieve uitvoering
- Voorbeeldweergaven van gegevens
- Interactieve pijplijngrafiek (grafiek van de gegevenssets in uw pijplijn)
Ingebouwde declaratieve Automation Bundles-integratie voor efficiënte samenwerking, versiebeheer en CI/CD-integratie rechtstreeks vanuit de editor: