Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Belangrijk
nl-NL: Lakebase Autoscaling is beschikbaar in de volgende regio's: eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia.
Lakebase Autoscaling is de nieuwste versie van Lakebase, met automatisch schalen van rekenkracht, schaal-tot-nul, branching-functionaliteit en direct herstellen. Als u een door Lakebase ingericht gebruiker bent, raadpleegt u Lakebase Ingericht.
Lakebase Postgres Autoscaling is een volledig beheerde Postgres-database die is geïntegreerd in het Databricks Data Intelligence Platform. Het is ontworpen voor elke toepassing waarvoor online transactieverwerking (OLTP) en lage latentie gegevensverwerking vereist zijn. Lakebase biedt deze mogelijkheden aan uw lakehouse, zodat u realtime transactionele toepassingen kunt bouwen naast uw analyseworkloads.
Lakebase Postgres Autoscaling combineert de betrouwbaarheid en bekendheid van Postgres met moderne databasemogelijkheden, waaronder automatisch schalen, schalen naar nul, vertakkingen en direct herstellen. Deze functies maken flexibele ontwikkelwerkstromen, kostenefficiënte bewerkingen en snelle iteratie mogelijk.
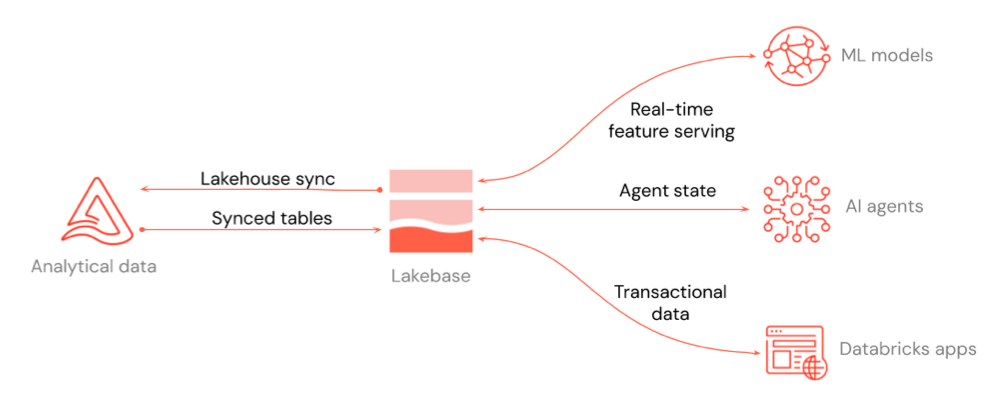
In het diagram ziet u hoe Lakebase kan worden geïntegreerd met de rest van het platform: realtime-functies die dienen voor ML-modellen en Feature Store, agentstatus voor AI-agents en transactionele gegevens voor Databricks-apps of een toepassing waarmee u verbinding maakt.
U kunt gegevens in beide richtingen verplaatsen tussen uw lakehouse en Lakebase. Gesynchroniseerde tabellen verplaatsen gegevens van lakehouse naar Lakebase, zodat uw toepassingen query's kunnen uitvoeren op lage latentie.
Voorbeeld van use cases en workloadtypen
Hier volgen slechts enkele voorbeelden van de vele manieren waarop u een OLTP Postgres-database zoals Lakebase in verschillende branches kunt gebruiken: gepersonaliseerde aanbevelingen en aanbiedingen gericht op e-commerce en retail, klinische proefgegevens en aanbevelingssystemen in de gezondheidszorg, geautomatiseerde handel en streaminganalyse in financiële services, en machinetelemetrie- en onderhoudswerkstromen in productie.
Veelvoorkomende workloadtypen voor OLTP-databases kunnen het volgende omvatten:
- Gegevensbediening: Inzichten uit belangrijke datasets beschikbaar stellen voor toepassingen met lage latentie en hoge QPS.
- Toepassingsstatus opslaan: Werkstroom- en agentstatus beheren in een transactioneel gegevensarchief.
- Feature serving: Gefeaturiseerde data met een lage latentie aanbieden aan ML-modellen.
Databricks-integratie
In het bovenstaande diagram ziet u drie belangrijke use cases voor integratie:
- Functies in realtime leveren: Gebruik Lakebase-projecten als een online winkel voor ML-modellen en Feature Store, zodat u met lage latentie gegevens kunt leveren. Zie Online Feature Store (Lakebase) en Feature Serving.
- Agentstatus voor AI-agents: Sla de status voor AI-agents op en beheer deze in een transactionele database, zodat gesprekken en werkstroomcontext tussen aanvragen blijven bestaan.
- Transactionele gegevens voor toepassingen: Gegevens behouden voor Databricks-apps of toepassingen die u verbindt met Lakebase. Voeg voor Databricks-apps een Lakebase-project toe als app-resource. Zie Een Lakebase-resource toevoegen aan een Databricks-app.
Lakebase geconfigureerd
Lakebase Provisioned is de oorspronkelijke Lakebase-aanbieding die gebruikmaakt van ingerichte rekenkracht die u handmatig schaalt. Bestaande voorziene instanties worden nog steeds ondersteund. De ontwikkeling van New Lakebase is gericht op automatisch schalen. Als u ingerichte instanties hebt of beide opties evalueert, zie Wat is Lakebase ingericht? en Automatisch schalen als standaard.
Wat is een project?
Resources voor Automatisch schalen van Lakebase worden ingedeeld in een projectstructuur . Een project is de container op het hoogste niveau voor uw databasebronnen. Wanneer u een Lakebase Autoscaling-database maakt, maakt u een project. Het project bevat uw vertakkingen (databaseomgevingen), berekeningen, rollen en databases. U kunt een project beschouwen als de organisatie-eenheid voor één toepassing of workload. U kunt meerdere projecten in een werkruimte hebben, elk met eigen vertakkingen en gegevens.
Hoe projecten worden georganiseerd
Als u de hiërarchie van objecten in een project begrijpt, kunt u uw resources ordenen en beheren:
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Elk niveau in de hiërarchie heeft een specifiek doel:
| Object | Description |
|---|---|
| Project | De container op het hoogste niveau voor uw databasebronnen. Een project bevat vertakkingen, databases, rollen en rekenresources. Zie Projecten beheren. |
| Filiaal | Een geïsoleerde databaseomgeving die opslag deelt met zijn hoofdvertakking. Elk project kan meerdere vertakkingen bevatten. Zie Vertakkingen beheren. |
| Rekenkracht | De Postgres-server die een vertakking aandrijft. Elke vertakking heeft een eigen rekenkracht die de verwerkingskracht en het geheugen biedt voor databasebewerkingen. Zie Berekeningen beheren. |
| Database | Een standaard Postgres-database binnen een vertakking. Elke tak kan meerdere databases bevatten, elk met hun eigen tabellen, schema's en gegevens. Zie Databases beheren. |
Vertakkingen begrijpen
Een van de krachtigste functies van Lakebase Postgres is vertakking. Net als vertakkingen in Git voor uw code, kunt u geïsoleerde databaseomgevingen creëren voor ontwikkeling en testen, zonder dat dit invloed heeft op de productie.
Waarom dit belangrijk is: Traditionele databasewerkstromen vereisen afzonderlijke ontwikkel- en faseringsservers, handmatige gegevensvernieuwing en zorgvuldige coördinatie. Met vertakkingen kunt u het volgende doen:
- Direct een ontwikkelomgeving maken met productiegegevens
- Schemawijzigingen veilig testen voordat u ze toepast op productie
- Herstel van fouten door vertakkingen te maken op enig moment in de tijd
- Alleen betalen voor de gegevens die u wijzigt, niet volledige dubbele databases
| Onderwerp | Description |
|---|---|
| Vestigingen | Leer hoe branches werken, ontdek veelvoorkomende werkstromen en aanbevolen procedures voor uw team. |
| Vertakkingen beheren | Branches aanmaken, resetten en verwijderen voor ontwikkeling en testen. |
| Beveiligde vertakkingen | Beveilig productievertakkingen tegen onbedoelde wijzigingen en verwijderingen. |
Basisconcepten
Lakebase is gebouwd op verschillende belangrijke innovaties die deze onderscheiden van traditionele databasesystemen:
- Gescheiden rekenkracht en opslag: Schaal rekenresources onafhankelijk van opslag voor kostenefficiëntie en flexibiliteit.
- Automatisch schalen: Rekenkracht wordt automatisch aangepast op basis van de vraag naar werkbelasting, met ondersteuning voor terugschalen naar nul tijdens niet-actieve perioden.
- Copy-on-write-opslag: Hiermee kunt u direct vertakken waarbij u alleen betaalt voor gegevenswijzigingen, niet volledige duplicaten.
- Instant Point-In-Time-bewerkingen: Vertakkingen maken of herstellen naar elk moment binnen het geconfigureerde herstelvenster (0-30 dagen)
Deze concepten werken samen om flexibele ontwikkelwerkstromen, kostenefficiënte bewerkingen en snel herstel van fouten mogelijk te maken.
Zie Basisconcepten voor een gedetailleerde uitleg van elk kernconcept.