Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Belangrijk
nl-NL: Lakebase Autoscaling is beschikbaar in de volgende regio's: eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia.
Lakebase Autoscaling is de nieuwste versie van Lakebase, met automatisch schalen van rekenkracht, schaal-tot-nul, branching-functionaliteit en direct herstellen. Als u een door Lakebase ingericht gebruiker bent, raadpleegt u Lakebase Ingericht.
Wanneer u een project maakt, maakt Lakebase verschillende Postgres-rollen in het project:
- Een Postgres-rol voor de Azure Databricks-identiteit van de projecteigenaar (bijvoorbeeld
user@databricks.com), die eigenaar is van de standaarddatabasedatabricks_postgres - Een
databricks_superuserbeheerdersrol
Beide rollen zijn zichtbaar op het tabblad Rollen en databases wanneer u uw project voor het eerst opent.
De databricks_postgres database wordt gemaakt, zodat u direct na het maken van het project verbinding kunt maken en Lakebase kunt uitproberen.
Er worden ook verschillende door het systeem beheerde rollen gemaakt. Dit zijn interne rollen die worden gebruikt door Azure Databricks-services voor beheer, bewaking en gegevensbewerkingen.
Opmerking
Postgres-rollen beheren databasetoegang (wie kan een query uitvoeren op gegevens). Zie Project-machtigingen voor projectmachtigingen (wie infrastructuur kan beheren). Zie Zelfstudie: Project- en databasetoegang verlenen aan een nieuwe gebruiker voor een zelfstudie over het instellen van beide.
Zie Vooraf gemaakte rollen en systeemrollen.
Postgres-rollen maken
Lakebase ondersteunt twee typen Postgres-rollen voor databasetoegang:
-
OAuth-rollen voor Azure Databricks-identiteiten: Maak deze met behulp van de Gebruikersinterface van Lakebase, de
databricks_authextensie met SQL of de Python SDK en REST API. Hiermee kunnen Azure Databricks-identiteiten (gebruikers, service-principals en groepen) verbinding maken met behulp van OAuth-tokens. - Systeemeigen Postgres-wachtwoordrollen: Maak deze met behulp van de Gebruikersinterface van Lakebase, SQL of de Python SDK en REST API. Gebruik een geldige rolnaam met wachtwoordverificatie.
Zie verificatieoverzicht voor hulp bij het kiezen van het type rol dat u wilt gebruiken. Elk is ontworpen voor verschillende gebruiksvoorbeelden.
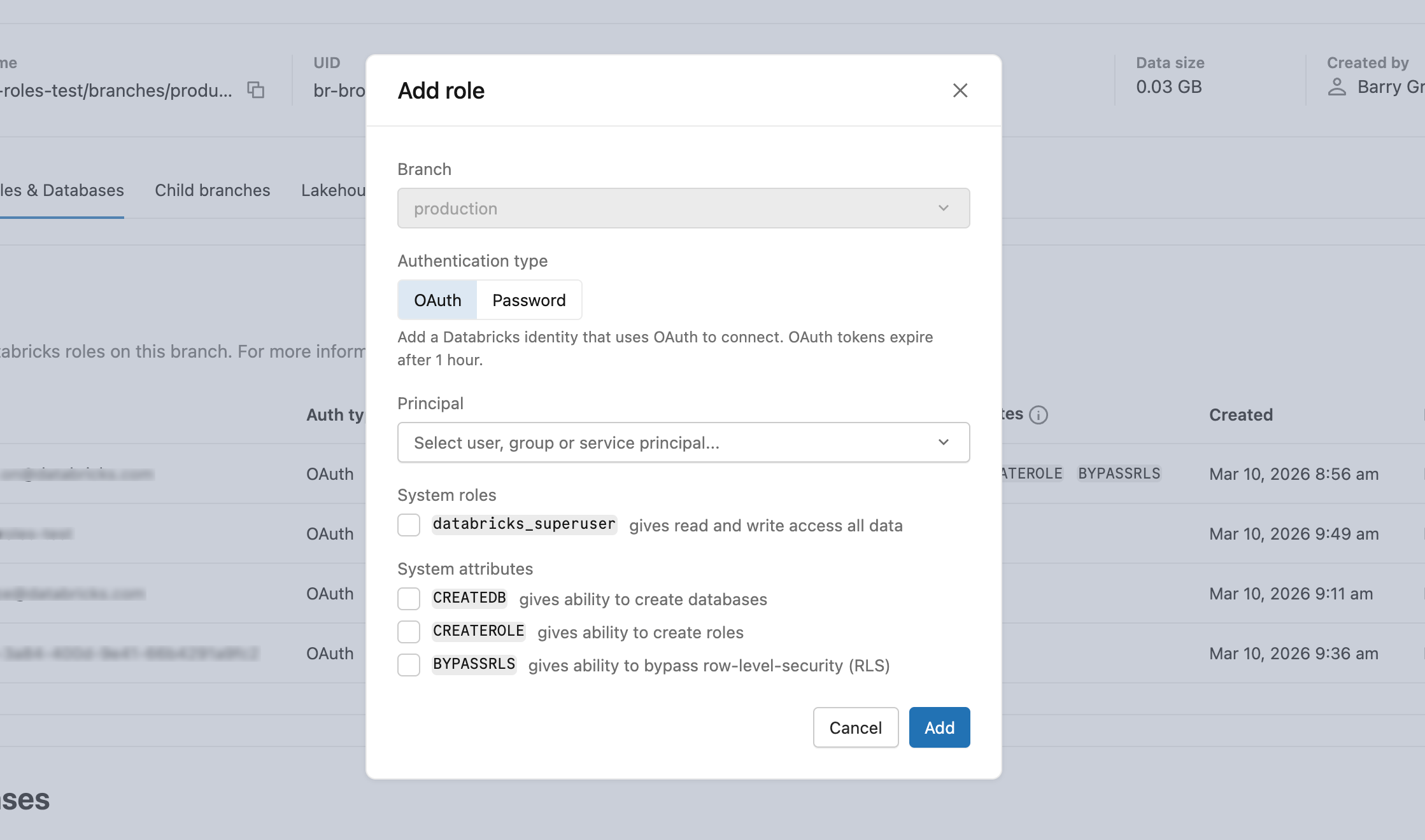
Een OAuth-rol maken voor Azure Databricks-identiteiten
Als u wilt toestaan dat Azure Databricks-identiteiten (gebruikers, service-principals of groepen) verbinding kunnen maken met behulp van OAuth-tokens, maakt u een OAuth-rol met behulp van de Lakebase-gebruikersinterface, de databricks_auth extensie met SQL of de REST API.
Zie Een OAuth-token verkrijgen in een gebruikers-naar-machine-stroom en een OAuth-token verkrijgen in een machine-naar-machine-stroom voor gedetailleerde instructies voor het verkrijgen van OAuth-tokens.
UI (Gebruikersinterface)
- Selecteer op het tabblad Rollen en databases> rolOAuth> de gebruiker, service-principal of groep waaraan u databasetoegang wilt verlenen.
- Nadat u de rol hebt gemaakt, verleent u de juiste databasebevoegdheden. Meer informatie: Machtigingen beheren
SQL
Voorwaarden:
- U moet beschikken over
CREATEenCREATE ROLEmachtigingen voor de database. - U moet worden geauthenticeerd als een Azure Databricks-identiteit met een geldig OAuth-token
- Geverifieerde systeemeigen Postgres-sessies kunnen geen OAuth-rollen maken
Maak de
databricks_authextensie. Elke Postgres-database moet een eigen extensie hebben.CREATE EXTENSION IF NOT EXISTS databricks_auth;Gebruik de
databricks_create_rolefunctie om een Postgres-rol te maken voor de Azure Databricks-identiteit:SELECT databricks_create_role('identity_name', 'identity_type');Voor een Azure Databricks-gebruiker:
SELECT databricks_create_role('myuser@databricks.com', 'USER');Voor een Azure Databricks-service-principal:
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');Voor een Azure Databricks-groep:
SELECT databricks_create_role('My Group Name', 'GROUP');De groepsnaam is hoofdlettergevoelig en moet exact overeenkomen zoals deze wordt weergegeven in uw Azure Databricks-werkruimte. Wanneer u een Postgres-rol voor een groep maakt, kan elk direct of indirect lid (gebruiker of service-principal) van die Databricks-groep zich verifiëren bij Postgres als de groepsrol met behulp van hun afzonderlijke OAuth-token. Hiermee kunt u machtigingen beheren op groepsniveau in Postgres in plaats van machtigingen voor afzonderlijke gebruikers te onderhouden.
Databasemachtigingen verlenen aan de nieuw gemaakte rol.
De databricks_create_role() functie maakt een Postgres-rol met alleen LOGIN permissie. Nadat u de rol hebt gemaakt, moet u de juiste databasebevoegdheden en -machtigingen verlenen voor de specifieke databases, schema's of tabellen die de gebruiker moet openen. Meer informatie: Machtigingen beheren
Python SDK
Stel identity_type in op USER, SERVICE_PRINCIPAL, of GROUP. Stel postgres_role in op respectievelijk het e-mailadres van de identiteit, de toepassings-ID (UUID) of de weergavenaam van de groep. Deze waarde wordt de postgres-rolnaam en is wat u gebruikt in verbindingsreeksen en GRANT instructies.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
identity_type="USER",
postgres_role="user@example.com"
)
)
)
role = operation.wait()
print(f"Created role: {role.name}")
Nadat u de rol hebt gemaakt, verleent u de juiste databasebevoegdheden. Meer informatie: Machtigingen beheren
curl
Stel identity_type in op USER, SERVICE_PRINCIPAL, of GROUP. Stel postgres_role in op respectievelijk het e-mailadres van de identiteit, de toepassings-ID (UUID) of de weergavenaam van de groep. Deze waarde wordt de postgres-rolnaam en is wat u gebruikt in verbindingsreeksen en GRANT instructies.
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"identity_type": "USER",
"postgres_role": "user@example.com"
}
}' | jq
Het eindpunt geeft een langdurige taak terug. Poll totdat donetrue is, en gebruik dan het name-veld voor volgende API-aanroepen. Zie Langlopende bewerkingen.
Nadat u de rol hebt gemaakt, verleent u de juiste databasebevoegdheden. Meer informatie: Machtigingen beheren
Verificatie op basis van groepen
Wanneer u een Postgres-rol voor een Azure Databricks-groep maakt, schakelt u verificatie op basis van groepen in. Hierdoor kan elk lid van de Azure Databricks-groep zich verifiëren bij Postgres met behulp van de rol van de groep, waardoor het machtigingsbeheer wordt vereenvoudigd.
Hoe werkt het:
- Maak een Postgres-rol voor een Databricks-groep.
- Databasemachtigingen verlenen aan de groepsrol in Postgres. Zie Machtigingen beheren.
- Elk direct of indirect lid (gebruiker of service-principal) van de Databricks-groep kan verbinding maken met Postgres met behulp van hun afzonderlijke OAuth-token.
- Wanneer er een connectie wordt gemaakt, authenticeert het lid als de groepsrol en worden alle machtigingen overgenomen die aan die rol zijn verleend.
Verificatiestroom:
Wanneer een groepslid verbinding maakt, geven ze de Postgres-rolnaam van de groep op als gebruikersnaam en hun eigen OAuth-token als het wachtwoord:
export PGPASSWORD='<OAuth token of a group member>'
export GROUP_ROLE_NAME='<pg-case-sensitive-group-role-name>'
psql -h $HOSTNAME -p 5432 -d databricks_postgres -U $GROUP_ROLE_NAME
Belangrijke overwegingen:
- Validatie van groepslidmaatschap: Groepslidmaatschap wordt alleen gevalideerd op het moment van verificatie. Als een lid wordt verwijderd uit de Azure Databricks-groep na het tot stand brengen van een verbinding, blijft de verbinding actief. Nieuwe verbindingspogingen van verwijderde leden worden geweigerd.
- Bereik van werkruimte: Alleen groepen die zijn toegewezen aan dezelfde Azure Databricks-werkruimte als het project, worden ondersteund voor verificatie op basis van groepen. Zie Groepen beheren voor meer informatie over het toewijzen van groepen aan een werkruimte.
-
Hoofdlettergevoeligheid: De groepsnaam die in
databricks_create_role()wordt gebruikt, moet exact overeenkomen met de groepsnaam zoals deze wordt weergegeven in uw Azure Databricks-werkruimte, inclusief hoofdlettergebruik. - Machtigingsbeheer: Het beheren van machtigingen op groepsniveau in Postgres is efficiënter dan het beheren van afzonderlijke gebruikersmachtigingen. Wanneer u machtigingen verleent aan de groepsrol, nemen alle huidige en toekomstige groepsleden deze machtigingen automatisch over.
- Naam wijzigen van identiteit: Als de e-mail of weergavenaam van een gebruiker of groep in Azure Databricks verandert, zullen de verificatie en bestaande databasetoewijzingen falen. Verwijder de oude rol, maak een nieuwe met de bijgewerkte naam en werk verbindingsreeksen en toekenningen bij.
Opmerking
Rolnamen mogen niet langer zijn dan 63 tekens en sommige namen zijn niet toegestaan. Meer informatie: Rollen beheren
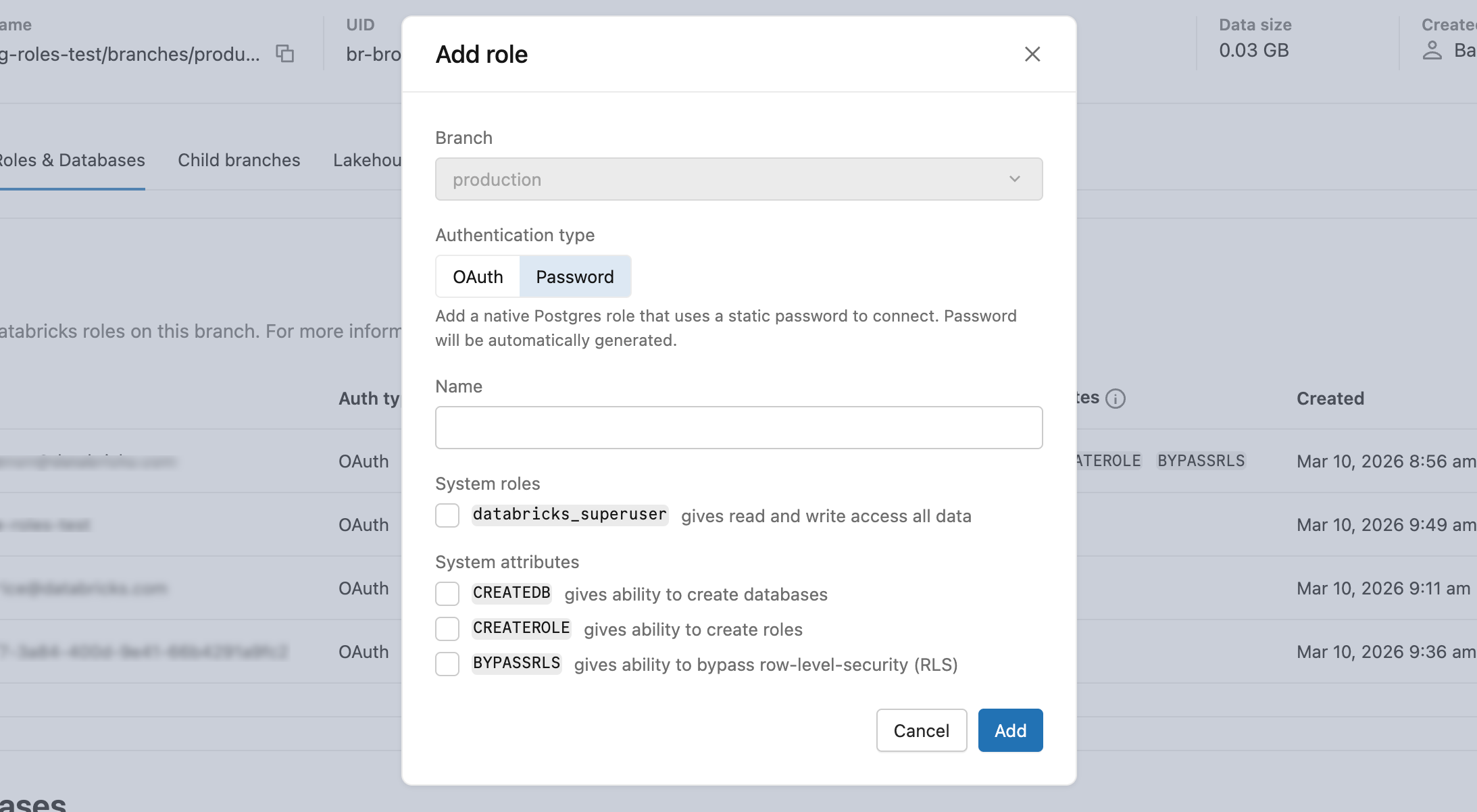
Een systeemeigen Postgres-wachtwoordrol maken
Wachtwoordverbindingen kunnen worden uitgeschakeld op project- of rekenniveau. Zie Wachtwoordverbindingen blokkeren.
UI (Gebruikersinterface)
- Voer op het tabblad Rollen en databases> eenrolwachtwoord> toe en geef eventueel
databricks_superusereen rolnaam op of systeemkenmerken (CREATEDB,CREATEROLE, ).BYPASSRLS - Kopieer het gegenereerde wachtwoord en geef het veilig op aan de gebruiker. Het wordt niet opnieuw weergegeven.
SQL
CREATE ROLE role_name WITH LOGIN PASSWORD 'your_secure_password';
Het wachtwoord moet minstens 12 tekens bevatten met een combinatie van kleine letters, hoofdletters, cijfers en symbooltekens. Door de gebruiker gedefinieerde wachtwoorden worden tijdens het maken gevalideerd om 60-bits entropie te garanderen.
Python SDK
identity_type weglaten om een wachtwoordrol aan te maken. De API retourneert een gegenereerd wachtwoord in het antwoord.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
postgres_role="my-app-role"
)
)
)
role = operation.wait()
print(f"Created role: {role.name}")
curl
identity_type weglaten om een wachtwoordfunctie te maken. Het eindpunt retourneert een langdurige bewerking. Peiling tot done is true.
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"postgres_role": "my-app-role"
}
}' | jq
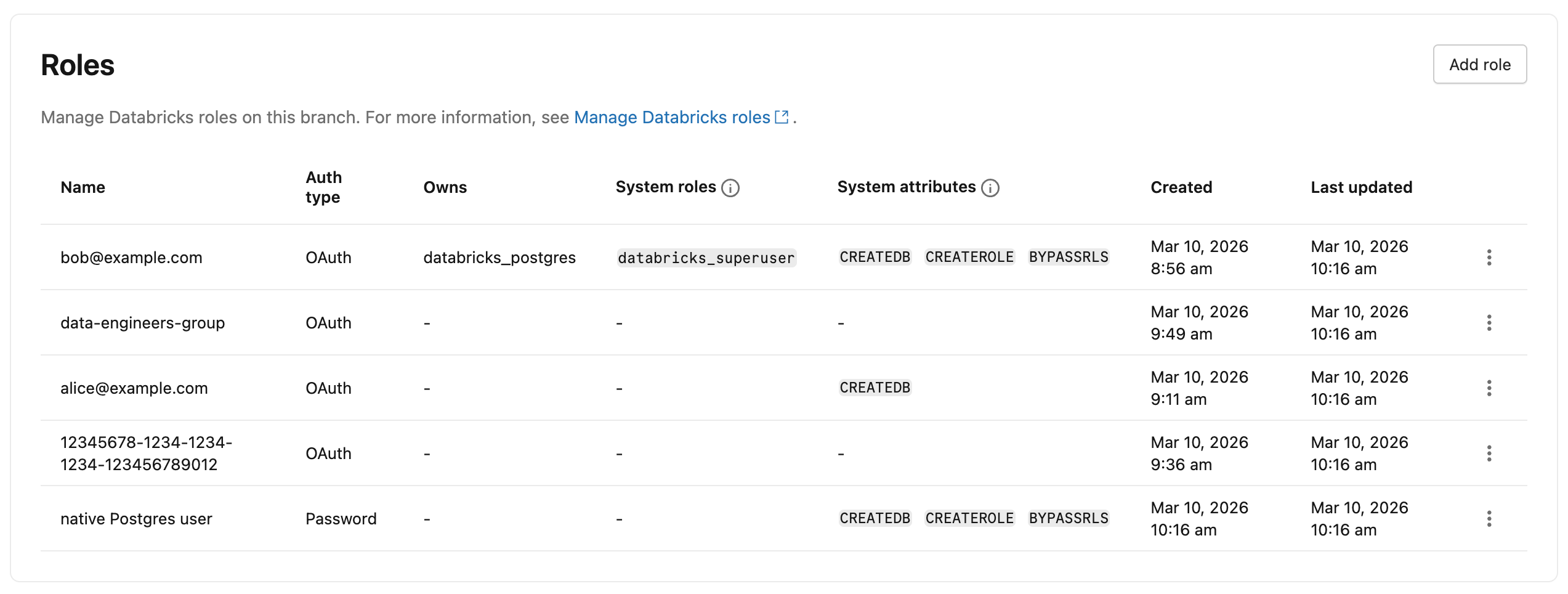
Postgres-rollen weergeven
UI (Gebruikersinterface)
Als u alle Postgres-rollen in uw project wilt weergeven, gaat u naar het tabblad Rollen en databases van uw vertakking in de Lakebase-app. Alle rollen die in de tak zijn aangemaakt, met uitzondering van systeemrollen, worden vermeld. De kolom Verificatietype geeft aan of elke rol OAuth of Wachtwoordverificatie gebruikt.
PostgreSQL
Alle rollen weergeven met \du opdracht:
U kunt alle Postgres-rollen, inclusief systeemrollen, weergeven met behulp van de \du metaopdracht van elke Postgres-client (zoals psql) of de Lakebase SQL-editor:
\du
List of roles
Role name | Attributes
-----------------------------+------------------------------------------------------------
cloud_admin | Superuser, Create role, Create DB, Replication, Bypass RLS
my.user@databricks.com | Create role, Create DB, Bypass RLS
databricks_control_plane | Superuser
databricks_gateway |
databricks_monitor |
databricks_reader_12345 | Create role, Create DB, Replication, Bypass RLS
databricks_replicator | Replication
databricks_superuser | Create role, Create DB, Cannot login, Bypass RLS
databricks_writer_12345 | Create role, Create DB, Replication, Bypass RLS
Python SDK
Alle rollen weergeven:
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
roles = w.postgres.list_roles(parent="projects/my-project/branches/production")
for role in roles:
print(f"{role.status.postgres_role} ({role.status.identity_type or 'PASSWORD'}): {role.name}")
Een specifieke rol ophalen:
role = w.postgres.get_role(
name="projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx"
)
print(role)
curl
Alle rollen weergeven:
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Een specifieke rol ophalen:
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Het antwoord bevat het name veld (bijvoorbeeld rol-xxxx-xxxxxxxxxx) dat is vereist voor het bijwerken en verwijderen van aanroepen.
Een rol bijwerken
Als u de kenmerken van een rol in de gebruikersinterface wilt bijwerken, selecteert u Rol bewerken in het rolmenu op het tabblad Rollen en databases .
Gebruik de API om de systeemrollen of -kenmerken van een rol bij te werken. Gebruik update_mask als queryparameter om op te geven welke velden moeten worden gewijzigd. Alleen de gemaskeerde velden worden gewijzigd.
Opmerking
Als u de resourcenaam van een rol wilt ophalen voor gebruik in bijwerk- en verwijderoproepen, gebruikt u het eindpunt van de lijstrollen . Namen van rolresources gebruiken een systeem-gegenereerde id (bijvoorbeeld rol-xxxx-xxxxxxxxxx) en niet de waarde die bij de creatie is opgegeven postgres_role.
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx?update_mask=spec.membership_roles%2Cspec.attributes.createdb" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx",
"spec": {
"membership_roles": ["DATABRICKS_SUPERUSER"],
"attributes": { "createdb": true }
}
}' | jq
Als u wilt verwijderen databricks_superuser, geeft u een lege matrix door: "membership_roles": [].
Een Postgres-rol verwijderen
U kunt zowel op Identiteit gebaseerde rollen op basis van Databricks als systeemeigen Postgres-wachtwoordrollen verwijderen.
UI (Gebruikersinterface)
Het verwijderen van een rol is een permanente actie die niet ongedaan kan worden gemaakt. Als u een rol wilt verwijderen die eigenaar is van een database, moet u de rol opgeven waaraan u de eigendomsobjecten opnieuw wilt toewijzen. Anders moet de database handmatig worden verwijderd voordat u de rol verwijdert die eigenaar is van de database.
Een Postgres-rol verwijderen met behulp van de gebruikersinterface:
- Navigeer naar het tabblad Rollen en databases van uw vertakking in de Lakebase-app.
- Selecteer Rol verwijderen in het rolmenu en bevestig de verwijdering.
PostgreSQL
U kunt elke Postgres-rol verwijderen met behulp van standaard Postgres-opdrachten. Zie de PostgreSQL-documentatie over het verwijderen van rollen voor meer informatie.
Een rol verwijderen:
DROP ROLE role_name;
Nadat een op identiteit gebaseerde Azure Databricks-rol is verwijderd, kan die identiteit Postgres niet meer verifiëren met behulp van OAuth-tokens totdat er een nieuwe rol is aangemaakt.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_role(
name="projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx"
)
operation.wait()
curl
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Vooraf gemaakte rollen
Nadat een project is gemaakt, maakt Azure Databricks automatisch Postgres-rollen voor projectbeheer en opstartprocedures.
| Rol | Description | Overgenomen bevoegdheden |
|---|---|---|
<project_owner_role> |
De Azure Databricks-identiteit van de maker van het project (bijvoorbeeld my.user@databricks.com). Deze rol is eigenaar van de standaarddatabase databricks_postgres en kan zich aanmelden en het project beheren. |
Lid van databricks_superuser |
databricks_superuser |
Een interne administratieve rol. Wordt gebruikt voor het configureren en beheren van toegang in het hele project. Deze rol krijgt brede bevoegdheden. | Neemt over van pg_read_all_data, pg_write_all_dataen pg_monitor. |
Meer informatie over de specifieke mogelijkheden en bevoegdheden van deze rollen: Vooraf gemaakte rolmogelijkheden
Systeemrollen die zijn gemaakt door Azure Databricks
Azure Databricks maakt de volgende systeemrollen die vereist zijn voor interne services. U kunt deze rollen weergeven door een \du opdracht uit te geven vanuit psql of de Lakebase SQL-editor.
| Rol | Purpose |
|---|---|
cloud_admin |
Rol van supergebruiker die wordt gebruikt voor cloudinfrastructuurbeheer |
databricks_control_plane |
Superuser-rol die wordt gebruikt door interne Databricks-onderdelen voor beheerbewerkingen |
databricks_monitor |
Gebruikt door services voor het verzamelen van interne metrische gegevens |
databricks_replicator |
Wordt gebruikt voor databasereplicatiebewerkingen |
databricks_writer_<dbid> |
De rol per database die wordt gebruikt voor het maken en beheren van gesynchroniseerde tabellen |
databricks_reader_<dbid> |
De rol per database die wordt gebruikt voor het lezen van tabellen die zijn geregistreerd in Unity Catalog |
databricks_gateway |
Wordt gebruikt voor interne verbindingen voor beheerde dataservices |
Als u wilt weten hoe rollen, bevoegdheden en rollidmaatschappen werken in Postgres, gebruikt u de volgende resources in de Postgres-documentatie: