Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Belangrijk
nl-NL: Lakebase Autoscaling is beschikbaar in de volgende regio's: eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia.
Lakebase Autoscaling is de nieuwste versie van Lakebase, met automatisch schalen van rekenkracht, schaal-tot-nul, branching-functionaliteit en direct herstellen. Als u een door Lakebase ingericht gebruiker bent, raadpleegt u Lakebase Ingericht.
Met gesynchroniseerde tabellen kunt u lakehouse-gegevens bedienen via Lakebase Postgres. Unity Catalog-tabellen worden gesynchroniseerd met Postgres, zodat toepassingen rechtstreeks met lage latentie query's kunnen uitvoeren op Lakehouse-gegevens. Dit proces wordt vaak omgekeerde ETL genoemd. Lakehouse is geoptimaliseerd voor analyses en verrijking, terwijl Lakebase is ontworpen voor operationele workloads die snelle query's in opzoekstijl en transactionele consistentie vereisen.
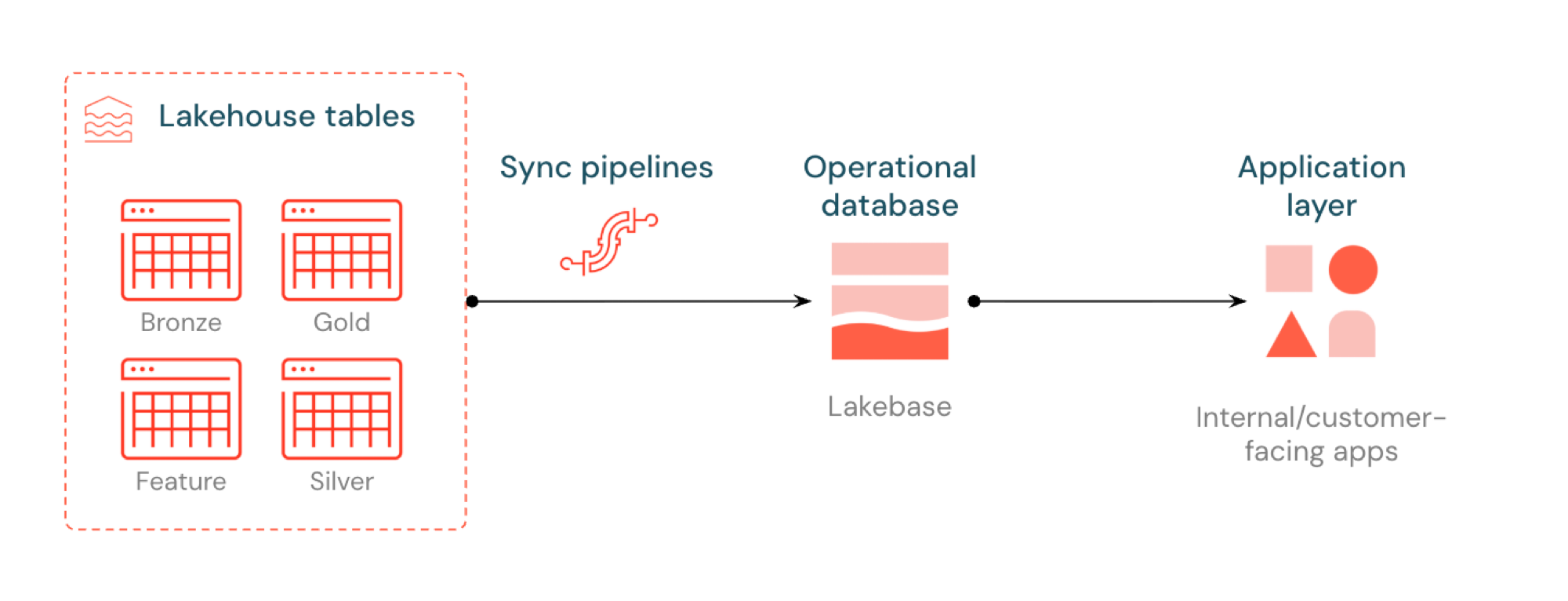
Wat zijn gesynchroniseerde tabellen?
Met gesynchroniseerde tabellen kunt u gegevens van Unity Catalog analyseren via Lakebase Postgres, zodat deze beschikbaar zijn voor toepassingen die query's met lage latentie (sub-10 ms) en volledige ACID-transacties nodig hebben. Ze overbruggen de kloof tussen analytische opslag en operationele systemen door uw gegevens gereed te houden voor realtime toepassingen.
Ondersteunde bronnen
Gesynchroniseerde tabellen ondersteunen de volgende Unity Catalog-brontypen:
- Beheerde en externe Delta-tabellen
- Beheerde en externe Iceberg-tabellen
- Weergaven en gematerialiseerde weergaven
Hoe werkt het?
Met Databricks gesynchroniseerde tabellen maakt u een beheerde kopie van uw Unity Catalog-gegevens in Lakebase. Wanneer u een gesynchroniseerde tabel maakt, krijgt u het volgende:
- Een gesynchroniseerde tabel in Unity Catalog die verwijst naar de synchronisatiepijplijn
- Een Postgres-tabel in Lakebase (alleen-lezen, doorzoekbaar door uw toepassingen)
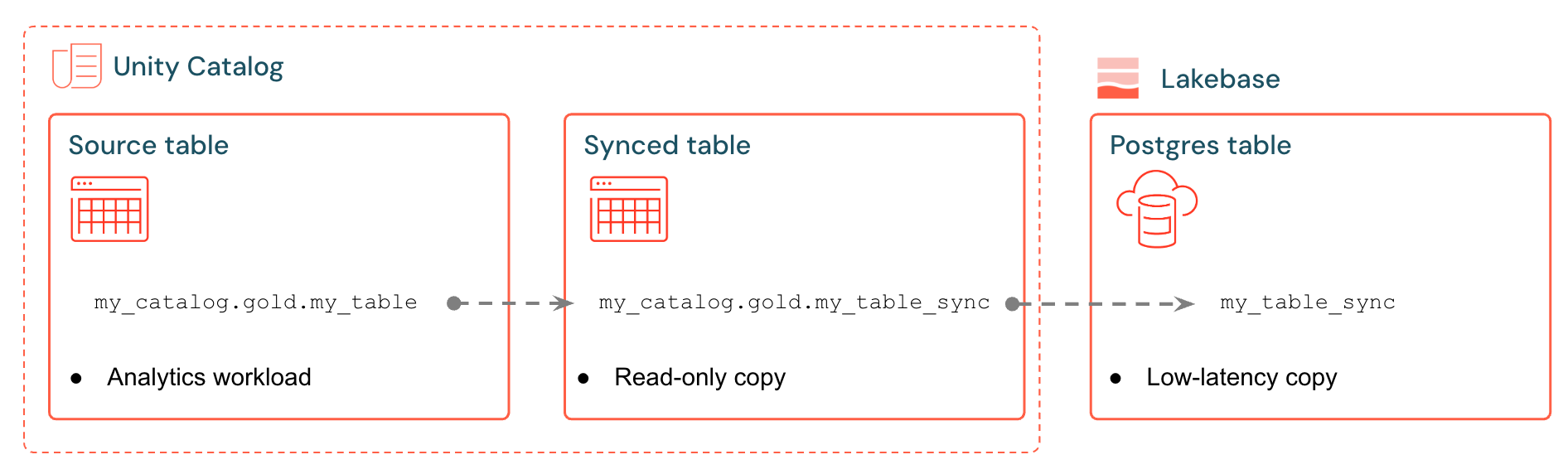
U kunt bijvoorbeeld gouden tabellen, ontworpen functies of ML-uitvoer synchroniseren van analytics.gold.user_profiles naar een nieuwe gesynchroniseerde tabel analytics.gold.user_profiles_synced. In Postgres wordt de naam van het Unity Catalog-schema de Postgres-schemanaam, dus dit wordt weergegeven als "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Toepassingen maken verbinding met standaardPostgres-stuurprogramma's en voeren een query uit op de gesynchroniseerde gegevens naast hun eigen operationele status.
Waarschuwing
Hoewel het mogelijk is om een gesynchroniseerde tabel rechtstreeks in Postgres te wijzigen, raadt Azure Databricks ten zeerste aan om alleen leesquery's uit te voeren om de gegevensintegriteit met de bron te beveiligen. Zie Ondersteunde bewerkingen voor ondersteunde bewerkingen voor gesynchroniseerde tabellen.
Synchronisatiepijplijnen maken gebruik van beheerde Lakeflow Spark-declaratieve pijplijnen om continu de gesynchroniseerde Tabel van Unity Catalog en de Postgres-tabel bij te werken met wijzigingen uit de brontabel. Elke synchronisatie kan maximaal 16 verbindingen met uw Lakebase-database gebruiken.
Lakebase Postgres ondersteunt maximaal 1.000 gelijktijdige verbindingen met transactionele garanties, zodat toepassingen verrijkte gegevens kunnen lezen terwijl ook inserts, updates en verwijderingen in dezelfde database worden verwerkt.
Synchronisatiemodi
Kies de juiste synchronisatiemodus op basis van uw toepassingsbehoeften:
| Mode | Beschrijving | Wanneer gebruiken | prestatie |
|---|---|---|---|
| Snapshot | Eenmalige kopie van alle gegevens | Bronwijzigingen >10% rijen per cyclus, of bron biedt geen ondersteuning voor CDF (weergaven, Iceberg-tabellen) | 10x efficiënter bij het wijzigen van >10% brongegevens |
| Geactiveerd | Geplande updates die op aanvraag of met intervallen worden uitgevoerd | Bronrijen worden op een bekend ritme gewijzigd. Invoegingen, updates en verwijderingen worden bij elke update doorgegeven. | Goede balans tussen kosten en vertraging. Duur indien deze bij intervallen van 5 minuten worden uitgevoerd < |
| Continue | Realtime streamen met seconden latentie | Wijzigingen moeten in Lakebase bijna in realtime worden weergegeven | Laagste vertraging, hoogste kosten. Minimumintervallen van 15 seconden |
Voor trigger- en continue modi moet de Change Data Feed (CDF) ingeschakeld zijn in uw brontabel. Als CDF niet is ingeschakeld, ziet u een waarschuwing in de gebruikersinterface met de exacte ALTER TABLE opdracht die moet worden uitgevoerd. Voor meer informatie over wijzigingenfeeds verwijzen wij naar Delta Lake-wijzigingenfeed gebruiken op Databricks.
Voorbeelden van gebruikssituaties
U kunt gesynchroniseerde tabellen gebruiken voor gebruiksscenario's voor datatoepassingen, zoals:
- Personalisatie-engines die nieuwe gebruikersprofielen leveren aan Databricks Apps
- Toepassingen die modelvoorspellingen of functiewaarden leveren die zijn berekend in lakehouse
- Klantgerichte dashboards die prestatie-indicatoren in real time leveren
- Fraudeopsporingsdiensten die risicoscores leveren voor directe actie
- Ondersteuningstools die verrijkte klantgegevens uit lakehouse-data aanbieden
Een gesynchroniseerde tabel maken (UI)
De ui-werkstroom wordt hieronder beschreven.
Vereiste voorwaarden
U hebt het volgende nodig:
- Een Databricks-werkruimte waarvoor Lakebase is ingeschakeld.
- Een Lakebase-project (zie Een project maken).
- Een Unity Catalog-tabel die moet worden gesynchroniseerd.
- Machtigingen voor het maken van gesynchroniseerde tabellen. U hebt USE_SCHEMA en CREATE_TABLE nodig voor elk schema dat u gebruikt. De catalogus- en schemaopties in de stroom Gesynchroniseerde tabellen maken bevatten alleen schema's waarin uw identiteit deze bevoegdheden heeft.
Zie Gegevenstypen en -compatibiliteit encapaciteitsplanning voor meer informatie over capaciteitsplanning en gegevenstypecompatibiliteit.
Stap 1: Selecteer uw brontabel
Ga naar Catalogus in de zijbalk van de werkruimte en selecteer de Unity Catalog-tabel die u wilt synchroniseren.
Stap 2: Wijzigingengegevensfeed inschakelen (indien nodig)
Als u van plan bent om Triggered of continue synchronisatiemodi te gebruiken, moet de Change Data Feed voor de brontabel zijn ingeschakeld. Controleer of cdf al is ingeschakeld voor uw tabel of voer deze opdracht uit in een SQL-editor of -notebook:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Vervang your_catalog.your_schema.your_table door de werkelijke tabelnaam.
Stap 3: Gesynchroniseerde tabel maken
Klik opGesynchroniseerde tabel> vanuit de tabeldetailsweergave.
Stap 4: Configureren
In het dialoogvenster Gesynchroniseerde tabel maken :
De catalogus- en schemalijsten bevatten alleen Unity Catalog-schema's waarbij de huidige gebruiker USE_SCHEMA en CREATE_TABLE bevoegdheden heeft. Als u geen schema ziet dat u verwacht, bevestigt u uw machtigingen bij de catalogusbeheerder.
- Tabelnaam: Voer een naam in voor de gesynchroniseerde tabel (deze wordt gemaakt in dezelfde catalogus en hetzelfde schema als de brontabel). Hiermee maakt u zowel een gesynchroniseerde Unity Catalog-tabel als een Postgres-tabel die u kunt opvragen.
- Database-type: Kies Serverloos Lakebase (Automatisch schalen).
- Synchronisatiemodus: Kies Momentopname, Geactiveerd of Doorlopend op basis van uw behoeften (zie de synchronisatiemodi hierboven).
- Configureer je selectie van projecten, vertakkingen en databases.
- Controleer of de primaire sleutel juist is (meestal automatisch gedetecteerd).
Als u Triggered- of Continue-modus hebt gekozen en de Change Data Feed nog niet hebt ingeschakeld, ziet u een waarschuwing met de exacte opdracht die moet worden uitgevoerd. Zie Gegevenstypen en compatibiliteit voor vragen over compatibiliteit van gegevenstypen.
Klik op Maken om de gesynchroniseerde tabel te maken.
Stap 5: Bewaken
Controleer na het maken de gesynchroniseerde tabel in Catalog. Op het tabblad Overzicht ziet u de synchronisatiestatus, configuratie, pijplijnstatus en tijdstempel van laatste synchronisatie. Gebruik Nu Synchroniseren voor handmatig vernieuwen.
Volgende synchronisaties plannen of activeren
De eerste momentopname wordt automatisch uitgevoerd bij het maken. Voor momentopname- en geactiveerde modi moeten volgende synchronisaties expliciet worden geactiveerd. Continue modus is zelfbeheerd.
Pijplijntaak databasetabelsynchronisatie
De Database Table Sync pipeline-taak in Lakeflow Jobs voert de pijplijn van een gesynchroniseerde tabel uit als een werkstroomstap. Configureer de taak met een trigger voor tabelupdate of een planning.
Trigger voor updates van de brontabel
De taak wordt geactiveerd wanneer de bron-Unity Catalog-tabel wordt bijgewerkt. Met Triggered modus worden alleen nieuwe wijzigingen incrementeel toegepast, waardoor bijna real-time actualisering mogelijk is zonder de altijd-aan kosten van de continue modus.
- Klik in de zijbalk op Werkstromen.
- Klik op Taak maken of open een bestaande taak.
- Klik op het tabblad Taken op + Een ander taaktype toevoegen.
- Selecteer onder Opname en transformatie de pijplijn voor databasetabelsynchronisatie.
- Selecteer in het veld Pijplijn de pijplijn die is gekoppeld aan de gesynchroniseerde tabel.
- Klik onder Planningen en triggers op Trigger toevoegen.
- Selecteer Tabelupdate als triggertype.
- Selecteer onder Tabellen de bron Unity Catalog-tabel die u wilt bewaken.
- Klik op Opslaan.
Triggeren volgens een schema
Hiermee wordt de synchronisatie uitgevoerd met een vaste frequentie. Geschikt voor de momentopnamemodus , waarbij een nachtelijke of wekelijkse volledige vernieuwing doorgaans het meest efficiënte patroon is.
- Volg stap 1 tot en met 5 hierboven om een databasetabelsynchronisatiepijplijntaak toe te voegen aan een taak.
- Klik onder Planningen en triggers op Trigger toevoegen.
- Selecteer Gepland als het triggertype.
- Stel uw cron-planning en -tijdzone in en klik vervolgens op Opslaan.
De SDK gebruiken
Activeer een synchronisatieuitvoering via een programma, bijvoorbeeld aan het einde van een upstream-notebook of pijplijn:
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get the pipeline ID from the synced table
table = w.database.get_synced_database_table(name="catalog.schema.synced_table")
pipeline_id = table.data_synchronization_status.pipeline_id
# Trigger a sync run
w.pipelines.start_update(pipeline_id=pipeline_id)
Gegevenstypen en compatibiliteit
Unity Catalog-gegevenstypen worden toegewezen aan Postgres-typen bij het maken van gesynchroniseerde tabellen. Complexe typen (ARRAY, MAP, STRUCT) worden opgeslagen als JSONB in Postgres.
| Bronkolomtype | Postgres-kolomtype |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p,s) | NUMERIEK |
| Dubbel | DUBBELE PRECISIE |
| FLOAT | WERKELIJK |
| INT | GEHEEL GETAL |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| STRING | Tekst |
| TIMESTAMP | TIJDSTEMPEL MET TIJDZONE |
| TIMESTAMP_NTZ | TIJDSTEMPEL ZONDER TIJDZONE |
| TINYINT | SMALLINT |
| ARRAY-elementType<> | JSONB |
| MAP<keyType, valueType> | JSONB |
| STRUCT<fieldName:fieldType[, ...]> | JSONB |
Opmerking
GEOGRAFIE, GEOMETRIE, VARIANT en OBJECTtypen worden niet ondersteund.
Ongeldige tekens verwerken
Bepaalde tekens, zoals null-bytes (0x00), zijn toegestaan in kolommen van Unity Catalog STRING, ARRAY, MAP of STRUCT, maar worden niet ondersteund in Postgres TEXT- of JSONB-kolommen. Dit kan synchronisatiefouten veroorzaken met fouten zoals:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Oplossingen:
Tekenreeksvelden opschonen: verwijder niet-ondersteunde tekens voordat u synchroniseert. Voor null-bytes in tekenreekskolommen:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableConverteren naar BINAIR: Voor STRING-kolommen waarbij onbewerkte bytes nodig zijn, moet u naar BINAIR type converteren.
Capaciteitsplanning
Houd rekening met de volgende resourcevereisten bij het plannen van de implementatie van gesynchroniseerde tabellen:
- Verbindingsgebruik: elke gesynchroniseerde tabel maakt gebruik van maximaal 16 verbindingen met uw Lakebase-database, die tellen mee voor de verbindingslimiet van het exemplaar.
- Groottelimieten: de totale limiet voor de grootte van logische gegevens voor alle gesynchroniseerde tabellen is 8 TB. Afzonderlijke tabellen hebben geen limieten, maar Databricks raadt aan niet meer dan 1 TB te overschrijden voor tabellen waarvoor vernieuwingen zijn vereist.
-
Naamgevingsvereisten: database-, schema- en tabelnamen mogen alleen alfanumerieke tekens en onderstrepingstekens (
[A-Za-z0-9_]+) bevatten. - Schemaontwikkeling: Alleen wijzigingen in additief schema (zoals het toevoegen van kolommen) worden ondersteund voor geactiveerde en continue modi.
- Updatesnelheid:: Voor Lakebase Autoscaling ondersteunt de synchronisatiepijplijn doorlopende en geactiveerde schrijfbewerkingen op ongeveer 150 rijen per seconde per capaciteitseenheid (CU) en Snapshot-schrijfbewerkingen met maximaal 2.000 rijen per seconde per CU.
Bewerkingen die zijn toegestaan voor gesynchroniseerde tabellen in Postgres
Azure Databricks raadt aan alleen de volgende bewerkingen uit te voeren in Postgres voor gesynchroniseerde tabellen om onbedoelde overschrijven of inconsistenties van gegevens te voorkomen:
- Query's met het kenmerk Alleen-lezen
- Indexen maken
- De tabel verwijderen (om ruimte vrij te maken na het verwijderen van de gesynchroniseerde tabel uit Unity Catalog)
Hoewel het mogelijk is om gesynchroniseerde tabellen in Postgres op andere manieren te wijzigen, wordt de synchronisatiepijplijn beïnvloed.
Een gesynchroniseerde tabel verwijderen
Als u een gesynchroniseerde tabel wilt verwijderen, moet u deze verwijderen uit zowel Unity Catalog als Postgres:
Verwijderen uit Unity Catalog: Zoek in Catalogus de gesynchroniseerde tabel, klik op het
 en selecteer Verwijderen. Hierdoor worden gegevens niet vernieuwd, maar blijft de tabel in Postgres.
en selecteer Verwijderen. Hierdoor worden gegevens niet vernieuwd, maar blijft de tabel in Postgres.Drop from Postgres: Maak verbinding met uw Lakebase-database en verwijder de tabel om ruimte vrij te maken.
DROP TABLE your_database.your_schema.your_table;
U kunt de SQL-editor of externe hulpprogramma's gebruiken om verbinding te maken met Postgres.
Meer informatie
| Opdracht | Beschrijving |
|---|---|
| Een project maken | Een Lakebase-project instellen |
| Verbinding maken met uw database | Meer informatie over verbindingsopties voor Lakebase |
| Database registreren in Unity Catalog | Uw Lakebase-gegevens zichtbaar maken in Unity Catalog voor geïntegreerde governance en query's voor meerdere bronnen |
| Integratie van Unity Catalog | Inzicht in governance en machtigingen |
Andere opties
Zie Partner Connect reverse ETL-oplossingen zoals Census of Hightouch voor het synchroniseren van gegevens in niet-Databricks-systemen.