Wat is Apache Hadoop in Azure HDInsight?
Apache Hadoop was het originele open-source framework voor gedistribueerde verwerking en analyse van sets met big data in clusters. Het Hadoop-ecosysteem omvat verwante software en hulpprogramma's, waaronder Apache Hive, Apache HBase, Spark en Kafka.
Azure HDInsight is een volledig beheerde, zeer uitgebreide opensource-analyseservice in de cloud voor bedrijven. Met het Apache Hadoop-clustertype in Azure HDInsight kunt u het Apache HDFS (Hadoop Distributed File System), Apache Hadoop YARN-resourcebeheer en een eenvoudig MapReduce-programmeermodel gebruiken om batchgegevens parallel te verwerken en te analyseren. Hadoop-clusters in HDInsight zijn compatibel met Azure Data Lake Storage Gen2.
Raadpleeg Onderdelen en versies die beschikbaar zijn in HDInsight om na te gaan welke onderdelen van de Hadoop-technologiestack in HDInsight beschikbaar zijn. Zie de pagina met Azure-functies voor HDInsight voor meer informatie over Hadoop in HDInsight.
Wat is MapReduce
Apache Hadoop MapReduce is een softwareframework om taken te schrijven waarmee enorme hoeveelheden gegevens worden verwerkt. Invoergegevens worden in losstaande segmenten opgedeeld. Elk segment wordt parallel verwerkt via de knooppunten in uw cluster. Een MapReduce-taak bestaat uit twee functies:
Mapper: verbruikt invoergegevens, analyseert deze (meestal met filter- en sorteerbewerkingen) en verzendt tuples (sleutel-waardeparen)
Reducer: verbruikt tuples die worden verzonden door mapper en voert een samenvattingsbewerking uit waarmee een kleiner, gecombineerd resultaat wordt gemaakt van de Mapper-gegevens
In het volgende diagram ziet u een voorbeeld een eenvoudige MapReduce-taak die woorden telt:
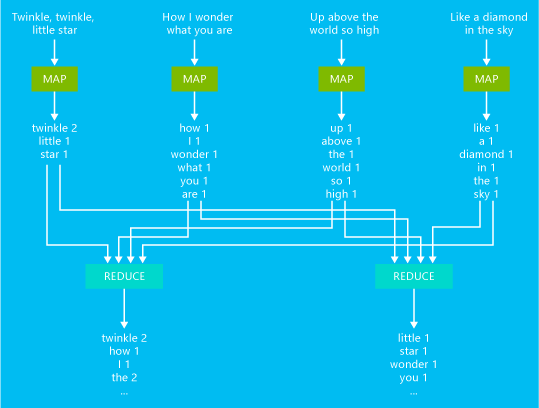
De uitvoer van deze taak is het aantal keer dat elk woord voorkomt in de tekst.
- De mapper neemt elke regel van de invoertekst als invoer en splitst die op in woorden. Het verzendt een sleutel/waarde-paar telkens wanneer een woord voorkomt en het woord wordt gevolgd door een 1. De uitvoer wordt gesorteerd voor deze naar de reducer wordt verzonden.
- De reducer somt deze individuele aantallen voor elk woord op en verzendt één sleutel/waarde-paar dat het woord en het aantal keer dat het voorkomt bevat.
MapReduce kan in verschillende talen worden geïmplementeerd. Java is de meest voorkomende implementatie en wordt in dit document gebruikt ter demonstratie.
Ontwikkelingstalen
Talen of frameworks die gebaseerd zijn op Java en de Java Virtual Machine, kunnen rechtstreeks als een MapReduce-taak worden uitgevoerd. Het voorbeeld dat in dit document gebruikt wordt, is een Java MapReduce-toepassing. Niet-Java-talen, zoals C#, Python of zelfstandige uitvoerbare bestanden, moeten Hadoop-streaming gebruiken.
Hadoop-streaming communiceert met de Mapper en de reducer via STDIN en STDOUT. De mapper en reducer lezen één regel gegevens per keer vanaf STDIN, en schrijven de uitvoer naar STDOUT. Elke regel de gelezen of geschreven wordt door de mapper en reducer moet de indeling van een sleutel/waarde-paar hebben, gescheiden door een tabteken:
[key]\t[value]
Zie Hadoop-streaming voor meer informatie.
Raadpleeg het volgende document voor voorbeelden van het gebruik van Hadoop-streaming met HDInsight:
Waar moet ik beginnen?
- Quickstart: Een Apache Hadoop-cluster maken in Azure HDInsight met behulp van Azure Portal
- Zelfstudie: Apache Hadoop-taken verzenden in HDInsight
- Java MapReduce-programma's ontwikkelen voor Apache Hadoop in HDInsight
- Apache Hive gebruiken als ETL-hulpprogramma (uitpakken, transformeren, laden)
- Uitpakken, transformeren en laden (ETL) op de juiste schaal
- Een pijplijn voor gegevensanalyse operationeel maken