Fouten in machine learning-modellen evalueren
Een van de grootste uitdagingen met de huidige procedures voor modelopsporing is het gebruik van statistische metrische gegevens om modellen te scoren op een benchmarkgegevensset. De nauwkeurigheid van het model is mogelijk niet uniform voor subgroepen met gegevens en er kunnen invoercohorten zijn waarvoor het model vaker mislukt. De directe gevolgen van deze fouten zijn een gebrek aan betrouwbaarheid en veiligheid, het verschijnen van getrouwheidsproblemen en een verlies van vertrouwen in machine learning.

Foutanalyse wordt verwijderd van metrische gegevens voor aggregatienauwkeurigheid. Het maakt de distributie van fouten op een transparante manier beschikbaar voor ontwikkelaars en stelt hen in staat om fouten efficiënt te identificeren en te diagnosticeren.
Het onderdeel foutanalyse van het verantwoordelijke AI-dashboard biedt machine learning-gebruikers een dieper inzicht in de verdeling van modelfouten en helpt hen snel onjuiste cohorten met gegevens te identificeren. Dit onderdeel identificeert de cohorten van gegevens met een hoger foutpercentage ten opzichte van het algehele benchmarkfoutpercentage. Het draagt bij aan de identificatiefase van de levenscycluswerkstroom van het model door middel van:
- Een beslissingsstructuur die cohorten met hoge foutpercentages weergeeft.
- Een heatmap die visualiseert hoe invoerfuncties van invloed zijn op de foutfrequentie in cohorten.
Discrepanties in fouten kunnen optreden wanneer het systeem ondermaats presteert voor specifieke demografische groepen of zelden waargenomen invoercohorten in de trainingsgegevens.
De mogelijkheden van dit onderdeel zijn afkomstig van het pakket Foutanalyse , waarmee modelfoutprofielen worden gegenereerd.
Gebruik foutenanalyse wanneer u het volgende moet doen:
- Krijg een diepgaand inzicht in hoe modelfouten worden verdeeld over een gegevensset en over verschillende invoer- en functiedimensies.
- De statistische prestatiegegevens opsplitsen om automatisch foutieve cohorten te detecteren om uw gerichte risicobeperkingsstappen te informeren.
Foutstructuur
Foutpatronen zijn vaak complex en hebben betrekking op meer dan een of twee functies. Ontwikkelaars kunnen moeite hebben met het verkennen van alle mogelijke combinaties van functies om verborgen gegevensvakken met kritieke fouten te ontdekken.
Om de belasting te verlichten, partitioneert de visualisatie van de binaire structuur de benchmarkgegevens automatisch in interpreteerbare subgroepen met onverwacht hoge of lage foutpercentages. Met andere woorden, de structuur gebruikt de invoerfuncties om modelfouten maximaal te scheiden van succes. Voor elk knooppunt dat een gegevenssubgroep definieert, kunnen gebruikers de volgende informatie onderzoeken:
- Foutfrequentie: een deel van de exemplaren in het knooppunt waarvoor het model onjuist is. Het wordt weergegeven door de intensiteit van de rode kleur.
- Foutdekking: een deel van alle fouten die in het knooppunt vallen. Deze wordt weergegeven via de vulsnelheid van het knooppunt.
- Gegevensweergave: het aantal exemplaren in elk knooppunt van de foutstructuur. Deze wordt weergegeven via de dikte van de binnenkomende rand naar het knooppunt, samen met het totale aantal exemplaren in het knooppunt.

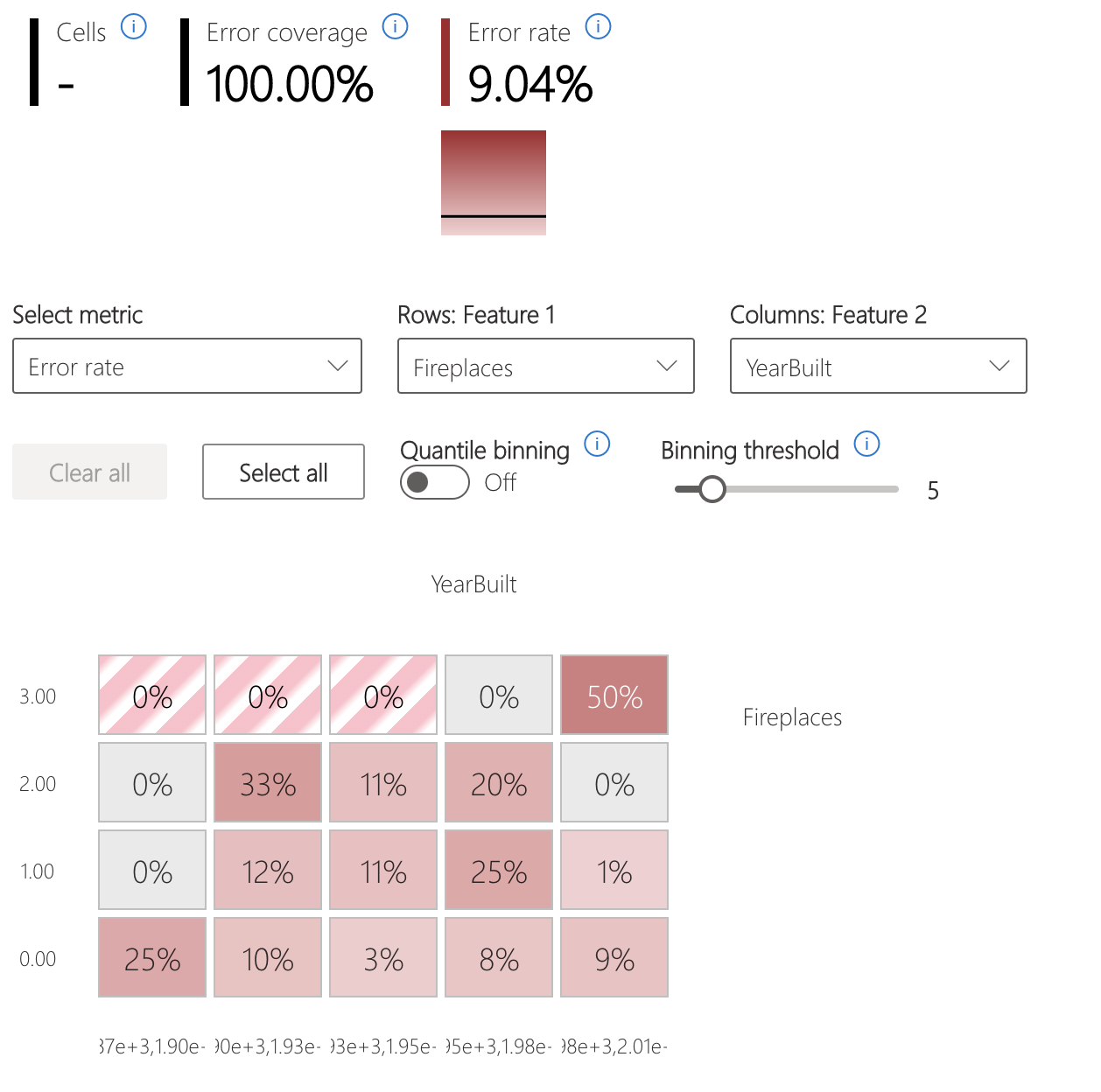
Fout in heatmap
De weergave segmenteert de gegevens op basis van een eendimensionaal of tweedimensionaal raster met invoerfuncties. Gebruikers kunnen de invoerfuncties kiezen die van belang zijn voor analyse.
De heatmap visualiseert cellen met een hoge fout door een donkerdere rode kleur te gebruiken om de aandacht van de gebruiker naar die regio's te brengen. Deze functie is vooral handig wanneer de foutthema's verschillen tussen partities, wat in de praktijk vaak gebeurt. In deze foutidentificatieweergave wordt de analyse sterk geleid door de gebruikers en hun kennis of hypothesen van welke functies het belangrijkst zijn voor het begrijpen van fouten.
Volgende stappen
- Meer informatie over het genereren van het verantwoordelijke AI-dashboard via CLI en SDK of Azure Machine Learning-studio ui.
- Verken de ondersteunde visualisaties voor foutanalyse.
- Meer informatie over het genereren van een scorecard voor verantwoordelijke AI op basis van de inzichten die zijn waargenomen in het dashboard Verantwoordelijke AI.
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor