Verbinding maken met gegevens met Azure Machine Learning Studio
In dit artikel wordt beschreven hoe u toegang hebt tot uw gegevens met de Azure Machine Learning-studio. Maak verbinding met uw gegevens in Azure Storage-services met Azure Machine Learning-gegevensarchieven. Pak die gegevens vervolgens in voor ML-werkstroomtaken met Azure Machine Learning-gegevenssets.
In deze tabel worden de voordelen van gegevensarchieven en gegevenssets gedefinieerd en samengevat.
| Object | Beschrijving | Vergoedingen |
|---|---|---|
| Gegevensarchieven | Als u veilig verbinding wilt maken met uw opslagservice in Azure, slaat u uw verbindingsgegevens (abonnements-id, tokenautorisatie, enzovoort) op in de sleutelkluis die is gekoppeld aan de werkruimte | Omdat uw gegevens veilig worden opgeslagen, plaatst u geen verificatiereferenties of oorspronkelijke gegevensbronnen in gevaar en hoeft u deze waarden niet meer in uw scripts vast te leggen |
| Gegevenssets | Het maken van een gegevensset maakt ook een verwijzing naar de locatie van de gegevensbron, samen met een kopie van de metagegevens. Met gegevenssets hebt u toegang tot gegevens tijdens het trainen van modellen, kunt u gegevens delen en samenwerken met andere gebruikers en kunt u opensourcebibliotheken, zoals pandas, gebruiken voor gegevensverkenning. | Omdat gegevenssets lazily worden geëvalueerd en de gegevens zich op de bestaande locatie bevinden, bewaart u één kopie van gegevens in uw opslag. Daarnaast worden er geen extra opslagkosten in rekening gebracht, vermijdt u onbedoelde wijzigingen in uw oorspronkelijke gegevensbronnen en verbetert u de prestaties van de ML-werkstroom. |
Als u wilt weten waar gegevensarchieven en gegevenssets passen in de algemene werkstroom voor Gegevenstoegang van Azure Machine Learning, gaat u naar Veilig toegang tot gegevens.
Zie voor meer informatie over de Azure Machine Learning Python SDK en een code-first-ervaring:
- Verbinding maken met Azure Storage-services met gegevensarchieven
- Azure Machine Learning-gegevenssets maken
Vereisten
Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning
Toegang tot Azure Machine Learning-studio
Een Azure Machine Learning-werkruimte. Werkruimtebronnen maken
- Wanneer u een werkruimte maakt, worden een Azure-blobcontainer en een Azure-bestandsshare automatisch als gegevensopslag geregistreerd bij de werkruimte. Ze hebben een naam
workspaceblobstoreenworkspacefilestorerespectievelijk. Voor voldoende blobopslagbronnen is deworkspaceblobstoreoptie ingesteld als het standaardgegevensarchief, dat al is geconfigureerd voor gebruik. Als u meer blobopslagresources nodig hebt, hebt u een Azure-opslagaccount nodig met een ondersteund opslagtype.
- Wanneer u een werkruimte maakt, worden een Azure-blobcontainer en een Azure-bestandsshare automatisch als gegevensopslag geregistreerd bij de werkruimte. Ze hebben een naam
Gegevensarchieven maken
U kunt gegevensarchieven maken op basis van deze Azure-opslagoplossingen. Voor niet-ondersteunde opslagoplossingen en om kosten voor uitgaande gegevens tijdens ML-experimenten op te slaan, moet u uw gegevens verplaatsen naar een ondersteunde Azure-opslagoplossing. Ga naar deze resource voor meer informatie over gegevensarchieven.
U kunt gegevensarchieven maken met op referenties gebaseerde toegang of op identiteit gebaseerde toegang.
Maak een nieuw gegevensarchief met de Azure Machine Learning-studio.
Belangrijk
Als uw gegevensopslagaccount zich in een virtueel netwerk bevindt, zijn er aanvullende configuratiestappen vereist om ervoor te zorgen dat de studio toegang heeft tot uw gegevens. Ga naar Netwerkisolatie en privacy voor meer informatie over de juiste configuratiestappen.
- Meld u aan bij Azure Machine Learning Studio.
- Selecteer Gegevens in het linkerdeelvenster onder Assets.
- Selecteer bovenaan Gegevensarchieven.
- Selecteer + Maken.
- Vul het formulier in om een nieuw gegevensarchief te maken en te registreren. Het formulier wordt op intelligente wijze bijgewerkt op basis van uw selecties voor azure-opslagtype en verificatietype. Ga naar de sectie opslagtoegang en machtigingen voor meer informatie over waar u de verificatiereferenties vindt die nodig zijn om dit formulier in te vullen.
In deze schermopname ziet u het deelvenster voor het maken van een Azure Blob-gegevensarchief :



Gegevensassets maken
Nadat u een gegevensarchief hebt gemaakt, maakt u een gegevensset om met uw gegevens te communiceren. Gegevenssets verpakken uw gegevens in een lazily geëvalueerd verbruiksobject voor machine learning-taken, bijvoorbeeld training. Ga naar Azure Machine Learning-gegevenssets maken voor meer informatie over gegevenssets.
Gegevenssets hebben twee typen: FileDataset en TabularDataset. FileDatasets maken verwijzingen naar één of meerdere bestanden of openbare URL's. TabularDatasets vertegenwoordigen gegevens in tabelvorm. U kunt TabularDatasets maken op basis van
- .csv
- .tsv
- .parket
- .json bestanden en uit SQL-queryresultaten.
In de volgende stappen wordt beschreven hoe u een gegevensset maakt in Azure Machine Learning-studio.
Notitie
Gegevenssets die zijn gemaakt via Azure Machine Learning-studio worden automatisch geregistreerd bij de werkruimte.
Ga naar Azure Machine Learning-studio
Selecteer Gegevens onder Assets in het linkernavigatievenster. Selecteer Maken op het tabblad Gegevensassets
Geef de gegevensasset een naam en een optionele beschrijving. Selecteer vervolgens onder Type een gegevenssettype, bestand of tabellair.

Het deelvenster Gegevensbron wordt nu geopend, zoals wordt weergegeven in deze schermopname:


U hebt verschillende opties voor uw gegevensbron. Kies 'Uit Azure-opslag' voor gegevens die al zijn opgeslagen in Azure. Als u gegevens wilt uploaden vanaf uw lokale station, kiest u 'Uit lokale bestanden'. Kies 'Uit webbestanden' voor gegevens die zijn opgeslagen op een openbare weblocatie. U kunt ook een gegevensasset maken vanuit een SQL-database of vanuit Azure Open Datasets.
Selecteer in de stap voor het selecteren van bestanden de locatie waar Azure uw gegevens moet opslaan en de gegevensbestanden die u wilt gebruiken.
- Schakel validatie overslaan in als uw gegevens zich in een virtueel netwerk bevinden. Meer informatie over isolatie en privacy van virtuele netwerken.
Volg de stappen om de instellingen en het schema voor het parseren van gegevens voor uw gegevensasset in te stellen. De instellingen worden vooraf ingevuld op basis van bestandstype en u kunt uw instellingen verder configureren voordat gegevensasset wordt gemaakt.
Zodra u bij de stap Controleren bent, selecteert u Maken op de laatste pagina
Voorbeeld van gegevens en profiel
Nadat u uw gegevensset hebt gemaakt, controleert u of u de preview en het profiel in de studio kunt bekijken:
- Meld u aan bij de Azure Machine Learning-studio
- Selecteer Gegevens onder Assets in het linkernavigatievenster.

- Selecteer de naam van de gegevensset die u wilt weergeven.
- Selecteer het tabblad Verkennen .
- Selecteer het tabblad Voorbeeld .

- Selecteer het tabblad Profiel .
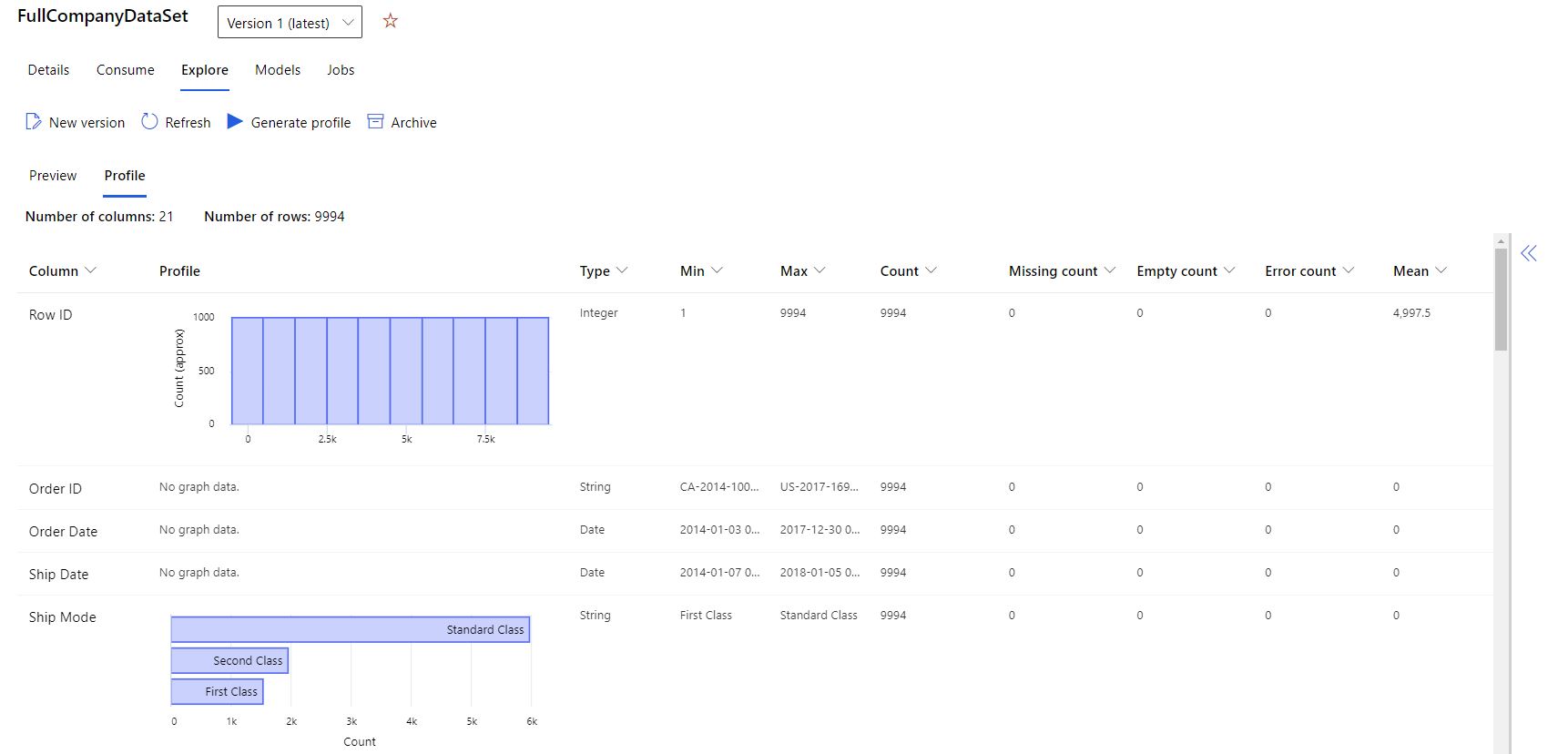
U kunt samenvattingsstatistieken in uw gegevensset gebruiken om te controleren of uw gegevensset gereed is voor ML. Voor niet-numerieke kolommen bevatten deze statistieken alleen basisstatistieken, bijvoorbeeld min, max en aantal fouten. Numerieke kolommen bieden statistische momenten en geschatte kwantielen.
Het gegevensprofiel van de Azure Machine Learning-gegevensset bevat:
Notitie
Lege vermeldingen worden weergegeven voor functies met irrelevante typen.
| Statistic | Beschrijving |
|---|---|
| Functie | De samengevatte kolomnaam |
| Profiel | Inlinevisualisatie op basis van het uitgestelde type. Tekenreeksen, booleaanse waarden en datums hebben waardeaantallen. Decimalen (numerieke waarden) hebben histogrammen geschat. Deze visualisaties bieden snel inzicht in de gegevensdistributie |
| Typedistributie | Aantal inline-waarden van typen in een kolom. Null-waarden zijn hun eigen type, zodat deze visualisatie afwijkende of ontbrekende waarden kan detecteren |
| Type | Afgeleid kolomtype. Mogelijke waarden zijn: tekenreeksen, booleaanse waarden, datums en decimalen |
| Min | Minimumwaarde van de kolom. Lege vermeldingen worden weergegeven voor functies waarvan het type geen inherente volgorde heeft (bijvoorbeeld Booleaanse waarden) |
| Max | Maximumwaarde van de kolom. |
| Tellen | Totaal aantal ontbrekende en niet-missende vermeldingen in de kolom |
| Niet-ontbrekend aantal | Aantal vermeldingen in de kolom die niet ontbreken. Lege tekenreeksen en fouten worden behandeld als waarden, dus ze dragen niet bij aan de 'ontbrekende telling'. |
| Kwantielen | Geschatte waarden bij elk kwantiel, om een beeld te geven van de gegevensdistributie |
| Gemiddelde | Rekenkundig gemiddelde of gemiddelde van de kolom |
| Standaarddeviatie | Meting van de hoeveelheid spreiding of variatie voor de gegevens van deze kolom |
| Verschil | Meting van hoe ver de gegevens van deze kolom zich uit de gemiddelde waarde uitspreiden |
| Asymmetrie | Meet het verschil tussen de gegevens van deze kolom uit een normale verdeling |
| Kurtosis | Meet de mate van 'tailness' van de gegevens van deze kolom, vergeleken met een normale verdeling |
Toegang en machtigingen voor opslag
Om ervoor te zorgen dat u veilig verbinding maakt met uw Azure Storage-service, moet u voor Azure Machine Learning gemachtigd zijn om toegang te krijgen tot de bijbehorende gegevensopslag. Deze toegang is afhankelijk van de verificatiereferenties die worden gebruikt om het gegevensarchief te registreren.
Virtueel netwerk
Als uw gegevensopslagaccount zich in een virtueel netwerk bevindt, zijn er extra configuratiestappen vereist om ervoor te zorgen dat Azure Machine Learning toegang heeft tot uw gegevens. Zie Gebruik Azure Machine Learning-studio in een virtueel netwerk om ervoor te zorgen dat de juiste configuratiestappen worden toegepast wanneer u uw gegevensarchief maakt en registreert.
Toegangsvalidatie
Waarschuwing
Toegang tussen tenants tot opslagaccounts wordt niet ondersteund. Als uw scenario toegang tussen tenants nodig heeft, neemt u contact op met de alias van het Azure Machine Learning Data Support-team op amldatasupport@microsoft.com voor hulp bij een aangepaste codeoplossing.
Als onderdeel van het eerste proces voor het maken en registreren van gegevensarchieven valideert Azure Machine Learning automatisch dat de onderliggende opslagservice bestaat en of de door de gebruiker geleverde principal (gebruikersnaam, service-principal of SAS-token) toegang heeft tot de opgegeven opslag.
Nadat het gegevensarchief is gemaakt, wordt deze validatie alleen uitgevoerd voor methoden waarvoor toegang tot de onderliggende opslagcontainer is vereist. De validatie wordt niet elke keer uitgevoerd wanneer gegevensopslagobjecten worden opgehaald. Validatie vindt bijvoorbeeld plaats wanneer u bestanden downloadt uit uw gegevensarchief. Als u echter uw standaardgegevensarchief wilt wijzigen, vindt er geen validatie plaats.
Als u uw toegang tot de onderliggende opslagservice wilt verifiëren, geeft u uw accountsleutel, SAS-tokens (Shared Access Signatures) of service-principal op volgens het gegevensarchieftype dat u wilt maken. De matrix van het opslagtype bevat de ondersteunde verificatietypen die overeenkomen met elk gegevensarchieftype.
U vindt informatie over de accountsleutel, het SAS-token en de service-principal in uw Azure-portal.
Als u een accountsleutel voor verificatie wilt verkrijgen, selecteert u Opslagaccounts in het linkerdeelvenster en kiest u het opslagaccount dat u wilt registreren
- De pagina Overzicht bevat informatie zoals de accountnaam, de container en de naam van de bestandsshare.
- Vouw het knooppunt Beveiliging en netwerken uit in het linkernavigatievenster
- Selecteer Toegangssleutels
- De beschikbare sleutelwaarden fungeren als accountsleutelwaarden
Als u een SAS-token wilt verkrijgen voor verificatie, selecteert u Opslagaccounts in het linkerdeelvenster en kiest u het gewenste opslagaccount
- Als u een toegangssleutelwaarde wilt verkrijgen, vouwt u het knooppunt Beveiliging en netwerken uit in het linkernavigatievenster
- Shared Access Signature selecteren
- Voltooi het proces om de SAS-waarde te genereren
Als u een service-principal wilt gebruiken voor verificatie, gaat u naar uw App-registraties en selecteert u welke app u wilt gebruiken.
- De bijbehorende overzichtspagina bevat vereiste informatie, zoals tenant-id en client-id.
Belangrijk
- Als u uw toegangssleutels voor een Azure Storage-account (accountsleutel of SAS-token) wilt wijzigen, moet u de nieuwe referenties synchroniseren met zowel uw werkruimte als de gegevensarchieven die eraan zijn gekoppeld. Ga naar Uw bijgewerkte referenties synchroniseren voor meer informatie.
- Als u de registratie ongedaan maakt en vervolgens een gegevensarchief met dezelfde naam opnieuw registreert en de registratie mislukt, is de Azure Key Vault voor uw werkruimte mogelijk niet ingeschakeld voor voorlopig verwijderen. Voorlopig verwijderen is standaard ingeschakeld voor het sleutelkluisexemplaren dat door uw werkruimte is gemaakt, maar is mogelijk niet ingeschakeld als u een bestaande sleutelkluis hebt gebruikt of een werkruimte hebt gemaakt vóór oktober 2020. Ga naar Voorlopig verwijderen inschakelen voor een bestaande sleutelkluis voor meer informatie over het inschakelen van voorlopig verwijderen.
Machtigingen
Voor Azure Blob-container en Azure Data Lake Gen 2-opslag moet u ervoor zorgen dat uw verificatiereferenties toegang hebben tot Storage Blob Data Reader . Meer informatie over Storage Blob Data Reader. Een SAS-accounttoken heeft standaard geen machtigingen.
Voor leestoegang tot gegevens moeten uw verificatiereferenties een minimum aan lijst- en leesmachtigingen hebben voor containers en objecten.
Voor schrijftoegang tot gegevens zijn ook schrijf- en toevoegmachtigingen vereist.
Trainen met gegevenssets
Gebruik uw gegevenssets in uw machine learning-experimenten voor het trainen van ML-modellen. Meer informatie over het trainen met gegevenssets.