Zelfstudie: Een afbeeldingsclassificatiemodel trainen en implementeren met een voorbeeld van Jupyter Notebook
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In deze zelfstudie gaat u een machine learning-model trainen op externe rekenresources. U gebruikt de trainings- en implementatiewerkstroom voor Azure Machine Learning in een Python Jupyter Notebook. Vervolgens kunt u het notebook gebruiken als een sjabloon voor het trainen van uw eigen machine learning-model met uw eigen gegevens.
In deze zelfstudie traint u een eenvoudig logistieke regressiemodel met behulp van de gegevensset MNIST en scikit-learn met Azure Machine Learning. MNIST is een populaire gegevensset die bestaat uit 70.000 afbeeldingen in grijstinten. Elke afbeelding is een handgeschreven cijfer van 28 x 28 pixels, dat een getal tussen 0-9 vertegenwoordigt. Het doel is om een classificatiemechanisme met meerdere klassen te maken om het cijfer te identificeren dat een bepaalde afbeelding vertegenwoordigt.
U leert hoe u de volgende acties uitvoert:
- Download een gegevensset en bekijk de gegevens.
- Een model voor afbeeldingsclassificatie en metrische logboekgegevens trainen met behulp van MLflow.
- Implementeer het model om realtime deductie uit te voeren.
Vereisten
- Voltooi de quickstart: Aan de slag met Azure Machine Learning om het volgende te doen :
- Een werkruimte maken.
- Maak een cloud-rekenproces dat moet worden gebruikt voor uw ontwikkelomgeving.
Een notebook uitvoeren vanuit uw werkruimte
Azure Machine Learning bevat een cloudnotebook-server in uw werkruimte voor een installatieloze en vooraf geconfigureerde ervaring. Gebruik uw eigen omgeving als u liever controle over uw omgeving, pakketten en afhankelijkheden hebt.
Een notebook-map klonen
U voltooit de volgende instellingen voor het experiment en voert stappen uit in Azure Machine Learning-studio. Deze geconsolideerde interface bevat machine learning-hulpprogramma's voor het uitvoeren van datawetenschap-scenario's voor datawetenschappers van alle vaardigheidsniveaus.
Meld u aan bij Azure Machine Learning Studio.
Selecteer uw abonnement en de werkruimte die u heeft gemaakt.
Selecteer aan de linkerkant Notebooks.
Selecteer bovenaan het tabblad Voorbeelden.
Open de map SDK v1 .
Selecteer de knop ... rechts van de map zelfstudies en selecteer vervolgens Klonen.
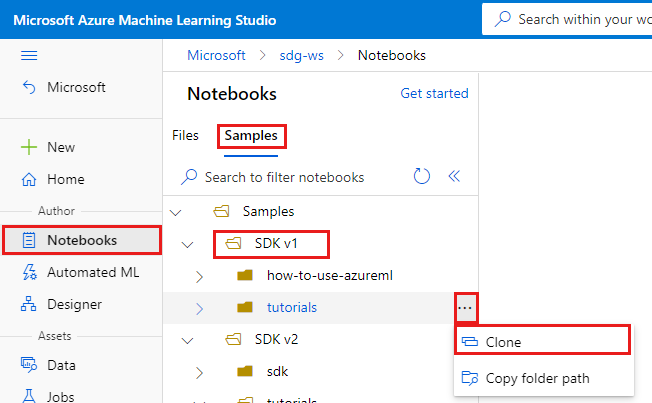
Er wordt een lijst met mappen weergegeven, met de verschillende gebruikers die toegang hebben tot de werkruimte. Selecteer uw map om de map Zelfstudies daar te klonen.
Het gekloonde notebook openen
Open de map zelfstudies die is gekloond in de sectie Gebruikersbestanden .
Selecteer het bestand quickstart-azureml-in-10mins.ipynb in de map tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins .

Pakketten installeren
Zodra het rekenproces wordt uitgevoerd en de kernel wordt weergegeven, voegt u een nieuwe codecel toe om pakketten te installeren die nodig zijn voor deze zelfstudie.
Voeg boven aan het notebook een codecel toe.

Voeg het volgende toe aan de cel en voer vervolgens de cel uit met behulp van het hulpmiddel Uitvoeren of met Shift+Enter.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Mogelijk ziet u enkele installatiewaarschuwingen. Deze kunnen veilig worden genegeerd.
Het notitieblok uitvoeren
Deze zelfstudie en het bijbehorende utils.py-bestand is ook beschikbaar op GitHub als u het wilt gebruiken in uw eigen lokale omgeving. Als u het rekenproces niet gebruikt, voegt u deze toe %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib aan de bovenstaande installatie.
Belangrijk
De rest van dit artikel bevat dezelfde inhoud als die u ziet in de notebook.
Schakel nu over naar het Jupyter Notebook als u de code wilt uitvoeren terwijl u mee leest. Als u één codecel in een notebook wilt uitvoeren, klikt u op de codecel en drukt u op Shift + Enter. U kunt ook de hele notebook uitvoeren door Alle uitvoeren te kiezen op de bovenste werkbalk.
Gegevens importeren
Voordat u een model traint, moet u de gegevens begrijpen die u gebruikt om het te trainen. In deze sectie leert u het volgende:
- De MNIST-gegevensset downloaden
- Enkele voorbeeldafbeeldingen weergeven
U gebruikt Azure Open Datasets om de onbewerkte MNIST-gegevensbestanden op te halen. Azure Open Datasets zijn gecureerde openbare gegevenssets die u kunt gebruiken om scenariospecifieke functies toe te voegen aan machine learning-oplossingen voor betere modellen. Elke gegevensset heeft een bijbehorende klasse, in dit geval MNIST, om de gegevens op verschillende manieren op te halen.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Bekijk de gegevens
Laad de gecomprimeerde bestanden in numpy-matrices. Gebruik vervolgens matplotlib om 30 willekeurige afbeeldingen uit de gegevensset te tekenen, met de bijbehorende labels erboven.
Houd er rekening mee dat voor deze stap een load_data functie is vereist die is opgenomen in een utils.py bestand. Dit bestand wordt in dezelfde map als dit notitieblok geplaatst. De functie load_data parseert de gecomprimeerde bestanden simpelweg in numpy-matrices.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
In de code wordt een willekeurige set afbeeldingen met hun labels weergegeven, vergelijkbaar met deze:

Metrische gegevens van modellen en logboeken trainen met MLflow
Train het model met behulp van de volgende code. Deze code maakt gebruik van automatische logboekregistratie van MLflow om metrische gegevens en logboekmodelartefacten bij te houden.
U gebruikt de LogisticRegression-classificatie van het SciKit Learn-framework om de gegevens te classificeren.
Notitie
Het duurt ongeveer 2 minuten voordat de modeltraining is voltooid.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Experiment weergeven
Selecteer taken in het linkermenu in Azure Machine Learning-studio en selecteer vervolgens uw taak (azure-ml-in10-mins-tutorial). Een taak is een groepering van veel uitvoeringen vanuit een opgegeven script of stukje code. Meerdere taken kunnen als experiment worden gegroepeerd.
Informatie voor de uitvoering wordt onder die taak opgeslagen. Als de naam niet bestaat wanneer u een taak indient, ziet u verschillende tabbladen met metrische gegevens, logboeken, uitleg, enzovoort als u uw uitvoering selecteert.
Versiebeheer voor uw modellen met het modelregister
U kunt modelregistratie gebruiken om uw modellen in uw werkruimte op te slaan en te versien. Geregistreerde modellen worden geïdentificeerd met naam en versie. Telkens wanneer u een model registreert met dezelfde naam als een bestaand model, wordt de versie in het register verhoogd. De onderstaande code registreert en versies van het model dat u hierboven hebt getraind. Zodra u de volgende codecel uitvoert, ziet u het model in het register door modellen te selecteren in het menu links in Azure Machine Learning-studio.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Het model implementeren voor realtime deductie
In deze sectie leert u hoe u een model implementeert, zodat een toepassing het model kan gebruiken (deductie) via REST.
Implementatieconfiguratie maken
De codecel krijgt een gecureerde omgeving, waarmee alle afhankelijkheden worden opgegeven die nodig zijn om het model te hosten (bijvoorbeeld de pakketten zoals scikit-learn). U maakt ook een implementatieconfiguratie, die de hoeveelheid rekenkracht aangeeft die nodig is om het model te hosten. In dit geval heeft de berekening 1CPU en 1 GB geheugen.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Model implementeren
In deze volgende codecel wordt het model geïmplementeerd in Azure Container Instance.
Notitie
Het duurt ongeveer 3 minuten voordat de implementatie is voltooid. Maar het kan langer duren totdat het beschikbaar is voor gebruik, misschien zo lang als 15 minuten.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Het scorescriptbestand waarnaar in de voorgaande code wordt verwezen, vindt u in dezelfde map als dit notebook en heeft twee functies:
- Een
initfunctie die eenmaal wordt uitgevoerd wanneer de service wordt gestart. In deze functie krijgt u normaal gesproken het model uit het register en stelt u globale variabelen in - Een
run(data)functie die wordt uitgevoerd telkens wanneer een aanroep naar de service wordt uitgevoerd. In deze functie formatteerde u normaal gesproken de invoergegevens, voert u een voorspelling uit en voert u het voorspelde resultaat uit.
Eindpunt weergeven
Zodra het model is geïmplementeerd, kunt u het eindpunt bekijken door naar Eindpunten te navigeren in het linkermenu in Azure Machine Learning-studio. U ziet de status van het eindpunt (in orde/niet in orde), logboeken en verbruiken (hoe toepassingen het model kunnen gebruiken).
De modelservice testen
U kunt het model testen door een onbewerkte HTTP-aanvraag te verzenden om de webservice te testen.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Resources opschonen
Als u dit model niet meer gaat gebruiken, verwijdert u de Modelservice met behulp van:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Als u de kosten verder wilt beheren, stopt u het rekenproces door de knop Rekenproces stoppen te selecteren naast de vervolgkeuzelijst Compute . Start vervolgens het rekenproces opnieuw de volgende keer dat u het nodig hebt.
Alles verwijderen
Gebruik deze stappen om uw Azure Machine Learning-werkruimte en alle rekenresources te verwijderen.
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.

Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
Verwante resources
- Meer informatie over alle implementatieopties voor Azure Machine Learning.
- Meer informatie over het verifiëren van het geïmplementeerde model.
- Doe asynchroon voorspellingen op grote hoeveelheden gegevens.
- Bewaak uw Azure Machine Learning-modellen met Application Insights.