Betrouwbaarheid in Azure Event Grid en Event Grid-naamruimte
Dit artikel bevat gedetailleerde informatie over regionale tolerantie voor Event Grid- en Event Grid-naamruimten met beschikbaarheidszones en herstel na noodgevallen in meerdere regio's en bedrijfscontinuïteit.
Zie Azure-betrouwbaarheid voor een architectuuroverzicht van betrouwbaarheid in Azure.
Ondersteuning voor beschikbaarheidszone
Azure-beschikbaarheidszones zijn ten minste drie fysiek afzonderlijke groepen datacenters binnen elke Azure-regio. Datacenters binnen elke zone zijn uitgerust met onafhankelijke energie-, koelings- en netwerkinfrastructuur. In het geval van een storing in een lokale zone worden beschikbaarheidszones zodanig ontworpen dat als de ene zone wordt beïnvloed, regionale services, capaciteit en hoge beschikbaarheid worden ondersteund door de resterende twee zones.
Fouten kunnen variëren van software- en hardwarefouten tot gebeurtenissen zoals aardbevingen, overstromingen en brand. Tolerantie voor fouten wordt bereikt met redundantie en logische isolatie van Azure-services. Zie Regio's en beschikbaarheidszones voor meer informatie over beschikbaarheidszones in Azure.
Services met azure-beschikbaarheidszones zijn ontworpen om het juiste niveau van betrouwbaarheid en flexibiliteit te bieden. Ze kunnen op twee manieren worden geconfigureerd. Ze kunnen zone-redundant zijn, met automatische replicatie tussen zones of zonegebonden, waarbij exemplaren zijn vastgemaakt aan een specifieke zone. U kunt deze benaderingen ook combineren. Zie Aanbevelingen voor het gebruik van beschikbaarheidszones en regio's voor meer informatie over zone-redundante architectuur en zone-redundante architectuur.
Event Grid-resourcedefinities voor onderwerpen, systeemonderwerpen, domeinen en gebeurtenisabonnementen en gebeurtenisgegevens worden automatisch gerepliceerd in drie beschikbaarheidszones. Wanneer er sprake is van een regionale storing in een van de beschikbaarheidszones, failover van Event Grid-resources naar een andere beschikbaarheidszone zonder menselijke tussenkomst. Op dit moment is het niet mogelijk om deze functie te beheren (in- of uitschakelen). Wanneer een bestaande regio beschikbaarheidszones gaat ondersteunen, worden bestaande Event Grid-resources automatisch een failover uitgevoerd om van deze functie te profiteren. De gebruiker hoeft verder niets te doen.
Azure Event Grid-naamruimte bereikt ook hoge beschikbaarheid binnen regio's met behulp van beschikbaarheidszones.
Vereisten
Voor ondersteuning van beschikbaarheidszones moeten uw Event Grid-resources zich in een regio bevinden die beschikbaarheidszones ondersteunt. Als u wilt controleren welke regio's beschikbaarheidszones ondersteunen, raadpleegt u de lijst met ondersteunde regio's.
Prijzen
Omdat Event Grid beschikbaarheidszones automatisch ondersteunt in regio's die beschikbaarheidszones ondersteunen, zijn er geen wijzigingen in de prijs.
Een resource maken waarvoor beschikbaarheidszones zijn ingeschakeld
Omdat Event Grid beschikbaarheidszones automatisch ondersteunt in regio's die beschikbaarheidszones ondersteunen, is er geen vereiste configuratie vereist.
Migreren naar ondersteuning voor beschikbaarheidszones
Als u uw Event Grid-resources verplaatst naar een regio die beschikbaarheidszones ondersteunt, ontvangt u automatisch ondersteuning voor beschikbaarheidszones. Als u wilt weten hoe u uw resources verplaatst naar een andere regio die beschikbaarheidszones ondersteunt, raadpleegt u het volgende:
- Azure Event Grid-systeemonderwerpen verplaatsen naar een andere regio
- Aangepaste onderwerpen van Azure Event Grid verplaatsen naar een andere regio
- Azure Event Grid-domeinen verplaatsen naar een andere regio
Herstel na noodgevallen en bedrijfscontinuïteit tussen regio's
Herstel na noodgevallen (DR) gaat over het herstellen van gebeurtenissen met een hoge impact, zoals natuurrampen of mislukte implementaties die downtime en gegevensverlies tot gevolg hebben. Ongeacht de oorzaak is de beste oplossing voor een noodgeval een goed gedefinieerd en getest DR-plan en een toepassingsontwerp dat actief dr ondersteunt. Zie aanbevelingen voor het ontwerpen van een strategie voor herstel na noodgevallen voordat u begint na te denken over het maken van uw plan voor herstel na noodgevallen.
Als het gaat om herstel na noodgevallen, gebruikt Microsoft het model voor gedeelde verantwoordelijkheid. In een model voor gedeelde verantwoordelijkheid zorgt Microsoft ervoor dat de basisinfrastructuur en platformservices beschikbaar zijn. Tegelijkertijd repliceren veel Azure-services niet automatisch gegevens of vallen ze terug van een mislukte regio om kruislings te repliceren naar een andere ingeschakelde regio. Voor deze services bent u verantwoordelijk voor het instellen van een plan voor herstel na noodgevallen dat geschikt is voor uw workload. De meeste services die worden uitgevoerd op PaaS-aanbiedingen (Platform as a Service) van Azure bieden functies en richtlijnen ter ondersteuning van herstel na noodgeval en u kunt servicespecifieke functies gebruiken om snel herstel te ondersteunen om uw DR-plan te ontwikkelen.
Herstel na noodgevallen omvat meestal het maken van een back-upresource om onderbrekingen te voorkomen wanneer een regio beschadigd raakt. Tijdens dit proces zijn een primaire en secundaire regio van Azure Event Grid-resources nodig in uw workload.
Er zijn verschillende manieren om te herstellen van een ernstig verlies van toepassingsfunctionaliteit. In deze sectie beschrijven we de controlelijst die u moet volgen om uw client voor te bereiden op het herstellen van een fout vanwege een beschadigde resource of regio.
Event Grid ondersteunt zowel handmatige als automatische geo-herstel na noodgevallen (GeoDR) aan de serverzijde. U kunt de logica voor noodherstel aan de clientzijde nog steeds implementeren als u meer controle wilt over het failoverproces. Zie Herstel na geonoodgeval aan de serverzijde in Azure Event Grid voor meer informatie over automatische GeoDR. ZieFailover-implementatie aan de clientzijde in Azure Event Grid voor meer informatie over het implementeren van herstel na noodgevallen aan de clientzijde.
In de volgende tabel ziet u de ondersteuning voor failover aan de clientzijde en ondersteuning voor geo-herstel na noodgevallen in Event Grid.
| Event Grid-resource | Ondersteuning voor failover aan clientzijde | Ondersteuning voor geo-herstel na noodgevallen (GeoDR) |
|---|---|---|
| Aangepaste onderwerpen | Ondersteund | Cross-Geo/Regionaal |
| Systeemonderwerpen | Niet ondersteund | Automatisch ingeschakeld |
| Domeinen | Ondersteund | Cross-Geo/Regionaal |
| Partnernaamruimten | Ondersteund | Niet ondersteund |
| Naamruimten | Ondersteund | Niet ondersteund |
Event Grid-naamruimte
Event Grid-naamruimte biedt geen ondersteuning voor herstel na noodgevallen tussen regio's. U kunt echter hoge beschikbaarheid tussen regio's bereiken via failover-implementatie aan de clientzijde door primaire en secundaire naamruimten te maken.
Met een failover-implementatie aan de clientzijde kunt u het volgende doen:
Implementeer een aangepast (handmatig of geautomatiseerd) proces om naamruimte, clientidentiteiten en andere configuraties** te repliceren, waaronder CA-certificaten, clientgroepen, onderwerpruimten, machtigingsbindingen, routering, tussen primaire en secundaire regio's.
Implementeer een concierge-service die clients primaire en secundaire eindpunten biedt door een statuscontrole uit te voeren op eindpunten. De concierge-service kan een webtoepassing zijn die wordt gerepliceerd en bereikbaar wordt gehouden met behulp van DNS-omleidingstechnieken, bijvoorbeeld met behulp van Azure Traffic Manager.
Bereik een Oplossing voor actief-actief herstel na noodgevallen door de metagegevens te repliceren en de taak voor taakverdeling in de naamruimten te verdelen. Een actief-passieve dr-oplossing kan worden bereikt door de metagegevens te repliceren om de secundaire naamruimte gereed te houden, zodat wanneer de primaire naamruimte niet beschikbaar is, het verkeer kan worden omgeleid naar secundaire naamruimte.
Herstel na noodgeval instellen
Voor regio's die zijn gekoppeld, biedt Event Grid een mogelijkheid om een failover van het publicatieverkeer naar de gekoppelde regio uit te voeren voor aangepaste onderwerpen, systeemonderwerpen en domeinen. Achter de schermen synchroniseert Event Grid automatisch resourcedefinities van onderwerpen, systeemonderwerpen, domeinen en gebeurtenisabonnementen naar de gekoppelde regio. Gebeurtenisgegevens worden echter niet gerepliceerd naar de gekoppelde regio. In de normale status worden gebeurtenissen opgeslagen in de regio die u voor die resource hebt geselecteerd. Wanneer er een regiostoring is en Microsoft de failover initieert, beginnen nieuwe gebeurtenissen naar de geografisch gekoppelde regio te stromen en worden ze vanaf daar verzonden zonder tussenkomst van u. Gebeurtenissen die zijn gepubliceerd en geaccepteerd in de oorspronkelijke regio, worden daar verzonden nadat de storing is verzacht.
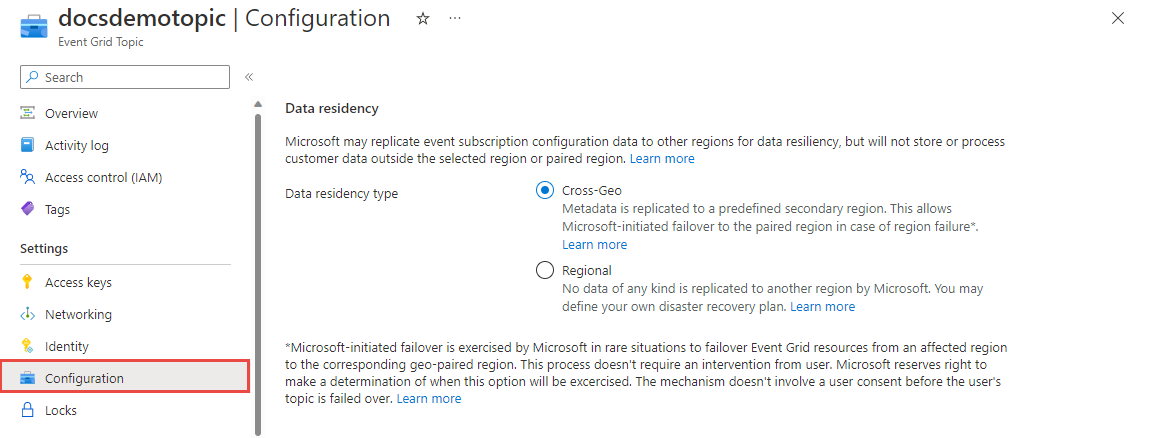
U kunt kiezen tussen twee failoveropties, door Microsoft geïnitieerde failover en door de klant geïnitieerd. Zie Gegevenslocatie configureren voor gedetailleerde stappen voor het configureren van beide instellingen.
Door Microsoft geïnitieerde failover wordt in zeldzame gevallen uitgevoerd door Microsoft om een failover uit te voeren van Event Grid-resources van een betrokken regio naar de bijbehorende geografisch gekoppelde regio. Microsoft behoudt zich het recht voor om te bepalen wanneer deze optie wordt uitgeoefend. Dit mechanisme omvat geen gebruikerstoestemming voordat het verkeer van de gebruiker wordt overgeschakeld.
Schakel deze functionaliteit in door de configuratie voor uw onderwerp of domein bij te werken. Selecteer Cross-Geo (standaard) om door Microsoft geïnitieerde failover in te schakelen.
Door de klant geïnitieerde failover wordt gedefinieerd door uw aangepast plan voor herstel na noodgevallen voor Azure Event Grid-onderwerpen en -domeinen. Er worden geen gegevens van welke aard dan ook gerepliceerd naar een andere regio door Microsoft. Hoewel deze failover-optie wat meer moeite kost, wordt snellere failover mogelijk en hebt u de controle over het kiezen van secundaire regio's. Als u herstel na noodgevallen aan de clientzijde wilt implementeren voor Azure Event Grid-onderwerpen, raadpleegt u Uw eigen herstel na noodgevallen aan de clientzijde bouwen voor Azure Event Grid-onderwerpen.
Er zijn enkele redenen waarom u mogelijk de door Microsoft geïnitieerde failoverfunctie wilt uitschakelen:
- Door Microsoft geïnitieerde failover wordt op basis van best effort uitgevoerd.
- Sommige geoparen voldoen niet aan de gegevenslocatievereisten van uw organisatie.
Schakel deze functionaliteit in door de configuratie voor uw onderwerp of domein bij te werken. Selecteer Regionaal.
Failover-ervaring voor herstel na noodgevallen
Herstel na noodgevallen wordt gemeten met twee metrische gegevens, Recovery Point Objective (RPO) en Recovery Time Objective (RTO).
De automatische failover van Event Grid heeft verschillende RPO's en RTO's voor uw metagegevens (onderwerpen, domeinen, gebeurtenisabonnementen) en gegevens (gebeurtenissen). Als u een andere specificatie nodig hebt dan de volgende, kunt u nog steeds uw eigen failover aan de clientzijde implementeren met behulp van de onderwerpstatus-API's.
Recovery Point Objective (RPO)
RPO voor metagegevens: nul minuten. Wanneer een resource wordt gemaakt/bijgewerkt/verwijderd, wordt de resourcedefinitie synchroon gerepliceerd naar het geo-paar wanneer een resource wordt gemaakt/bijgewerkt/verwijderd. Wanneer een failover optreedt, gaan er geen metagegevens verloren.
Gegevens-RPO: wanneer er een failover plaatsvindt, worden nieuwe gegevens verwerkt vanuit de gekoppelde regio. Zodra de storing voor de getroffen regio wordt beperkt, worden de niet-verwerkte gebeurtenissen daar verzonden. Als het herstel van de regio langere tijd vereist dan de time-to-live-waarde die is ingesteld op gebeurtenissen, kunnen de gegevens worden verwijderd. Als u dit gegevensverlies wilt beperken, raden we u aan een dode letter voor een gebeurtenisabonnement in te stellen. Als de getroffen regio verloren gaat en niet kan worden hersteld, gaan er gegevens verloren. In het beste geval blijft de abonnee de publicatiesnelheid bij en gaat er slechts een paar seconden aan gegevens verloren. Het ergste scenario zou zijn wanneer de abonnee niet actief gebeurtenissen verwerkt en met een maximale duur van 24 uur, kan het gegevensverlies maximaal 24 uur duren.
Beoogde hersteltijd (RTO)
RTO voor metagegevens: het nemen van failover-beslissingen is gebaseerd op factoren zoals beschikbare capaciteit in gekoppelde regio's en kan in het bereik van 60 minuten of langer duren. Zodra de failover is gestart, begint Event Grid binnen vijf minuten aanroepen voor het maken/bijwerken/verwijderen van onderwerpen en abonnementen te accepteren.
Gegevens-RTO: Hetzelfde als de bovenstaande informatie.
Belangrijk
- In het geval van herstel na noodgevallen aan de serverzijde, als de gekoppelde regio geen extra capaciteit heeft om het extra verkeer op te nemen, kan Event Grid failover niet initiëren. Het herstel wordt op basis van best effort uitgevoerd.
- Er worden geen kosten in rekening gebracht voor het gebruik van deze functie.
- Herstel na geo-noodgeval wordt niet ondersteund voor partnernaamruimten en partneronderwerpen.
Volgende stappen
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor