Zoeken over Azure Blob Storage-inhoud
Zoeken in de verschillende inhoudstypen die zijn opgeslagen in Azure Blob Storage kan een moeilijk probleem zijn, maar Azure AI Search biedt diepgaande integratie op de inhoudslaag, waarbij tekstinformatie wordt geëxtraheerd en uitgesteld, die vervolgens kan worden opgevraagd in een zoekindex.
In dit artikel bekijkt u de basiswerkstroom voor het extraheren van inhoud en metagegevens uit blobs en het verzenden ervan naar een zoekindex in Azure AI Search. De resulterende index kan worden opgevraagd met behulp van zoeken in volledige tekst. U kunt eventueel verwerkte blob-inhoud verzenden naar een kennisarchief voor scenario's die niet kunnen worden gezocht.
Notitie
Bent u al bekend met de werkstroom en compositie? Een blobindexeerfunctie configureren is de volgende stap.
Wat betekent het toevoegen van zoeken in volledige tekst aan blobgegevens
Azure AI Search is een zelfstandige zoekservice die ondersteuning biedt voor het indexeren en opvragen van workloads via door de gebruiker gedefinieerde indexen die uw persoonlijke doorzoekbare inhoud bevatten die wordt gehost in de cloud. Het vinden van uw doorzoekbare inhoud met de query-engine in de cloud is nodig voor prestaties, waarbij resultaten worden geretourneerd met een snelheid die gebruikers hebben verwacht van zoekquery's.
Azure AI Search kan worden geïntegreerd met Azure Blob Storage op de indexeringslaag, waarbij u uw blob-inhoud importeert als zoekdocumenten die worden geïndexeerd in omgekeerde indexen en andere querystructuren die ondersteuning bieden voor vrije tekstquery's en filterexpressies. Omdat uw blob-inhoud is geïndexeerd in een zoekindex, kunt u het volledige scala aan queryfuncties in Azure AI Search gebruiken om informatie in uw blob-inhoud te vinden.
Invoer is uw blobs, in één container, in Azure Blob Storage. Blobs kunnen vrijwel elk type tekstgegevens zijn. Als uw blobs afbeeldingen bevatten, kunt u AI-verrijking toevoegen om tekst en functies van afbeeldingen te maken en te extraheren.
Uitvoer is altijd een Azure AI Search-index die wordt gebruikt voor snelle tekstzoekopdrachten, ophalen en verkennen in clienttoepassingen. Tussendoor is de indexeringspijplijnarchitectuur zelf. De pijplijn is gebaseerd op de functie indexeerfunctie , die verder wordt besproken in dit artikel.
Zodra de index is gemaakt en gevuld, bestaat deze onafhankelijk van uw blobcontainer, maar u kunt indexeringsbewerkingen opnieuw uitvoeren om de index te vernieuwen op basis van gewijzigde documenten. Tijdstempelinformatie over afzonderlijke blobs wordt gebruikt voor wijzigingsdetectie. U kunt kiezen voor geplande uitvoering of indexering op aanvraag als vernieuwingsmechanisme.
Resources die worden gebruikt in een blobzoekoplossing
U hebt Azure AI Search, Azure Blob Storage en een client nodig. Azure AI Search is doorgaans een van de verschillende onderdelen in een oplossing, waarbij uw toepassingscode query-API-aanvragen opvraagt en het antwoord afhandelt. U kunt ook toepassingscode schrijven voor het afhandelen van indexering, hoewel het gebruikelijk is om de Azure-portal als zoekclient te gebruiken voor test- en impromptu-taken.
In Blob Storage hebt u een container nodig die broninhoud biedt. U kunt bestandsopname- en uitsluitingscriteria instellen en opgeven welke delen van een blob worden geïndexeerd in Azure AI Search.
U kunt rechtstreeks beginnen op de portalpagina van uw opslagaccount.
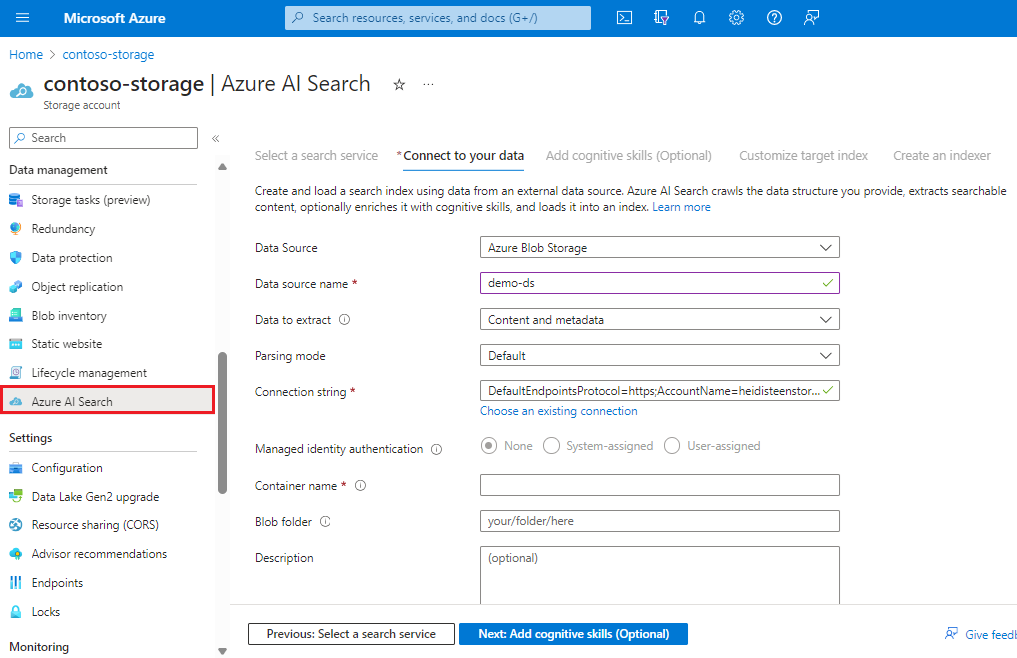
Selecteer Op de linkernavigatiepagina onder Gegevensbeheer Azure AI Search om een zoekservice te selecteren of te maken.
Volg de stappen in de wizard om doorzoekbare inhoud uit uw blobs te extraheren en optioneel te maken. De werkstroom is de wizard Gegevens importeren. De werkstroom maakt een indexeerfunctie, gegevensbron, index en optieset op uw Azure AI-Search-service.
Gebruik Search Explorer op de pagina van de zoekportal om een query uit te voeren op uw inhoud.
De wizard is de beste plek om te beginnen, maar u ontdekt meer flexibele opties wanneer u zelf een blobindexeerfunctie configureert. U kunt een REST-client gebruiken. Zelfstudie: Semi-gestructureerde gegevens (JSON-blobs) indexeren en doorzoeken begeleidt u bij de stappen voor het aanroepen van de REST API.
Hoe blobs worden geïndexeerd
Standaard worden de meeste blobs geïndexeerd als één zoekdocument in de index, inclusief blobs met gestructureerde inhoud, zoals JSON of CSV, die worden geïndexeerd als één stuk tekst. Voor JSON- of CSV-documenten met een interne structuur (scheidingstekens) kunt u echter parseringsmodi toewijzen om afzonderlijke zoekdocumenten te genereren voor elke regel of elk element:
Een samengesteld of ingesloten document (zoals een ZIP-archief, een Word-document met ingesloten Outlook-e-mail met bijlagen of een . MSG-bestand met bijlagen) wordt ook geïndexeerd als één document. Bijvoorbeeld alle afbeeldingen die zijn geëxtraheerd uit de bijlagen van een . MSG-bestand wordt geretourneerd in het veld normalized_images. Als u afbeeldingen hebt, kunt u OVERWEGEN OM AI-verrijking toe te voegen om meer zoekhulpprogramma's van die inhoud te krijgen.
Tekstuele inhoud van een document wordt geëxtraheerd in een tekenreeksveld met de naam 'inhoud'. U kunt ook standaard en door de gebruiker gedefinieerde metagegevens extraheren.
Notitie
Azure AI Search legt indexeerlimieten op voor de hoeveelheid tekst die wordt geëxtraheerd, afhankelijk van de prijscategorie. Er wordt een waarschuwing weergegeven in het antwoord op de status van de indexeerfunctie als documenten worden afgekapt.
Een blobindexeerfunctie gebruiken voor inhoudextractie
Een indexeerfunctie is een gegevensbronbewuste subservice in Azure AI Search, uitgerust met interne logica voor het nemen van steekproeven, het lezen en ophalen van gegevens en metagegevens, en het serialiseren van gegevens uit systeemeigen indelingen in JSON-documenten voor volgende import.
Blobs in Azure Storage worden geïndexeerd met behulp van de blob-indexeerfunctie. U kunt deze indexeerfunctie aanroepen met behulp van de Azure AI Search-opdracht in Azure Storage, de wizard Gegevens importeren, een REST API of de .NET SDK. In code gebruikt u deze indexeerfunctie door het type in te stellen en door verbindingsgegevens op te geven die samen met een blobcontainer een Azure Storage-account bevatten. U kunt uw blobs subseten door een virtuele map te maken, die u vervolgens kunt doorgeven als een parameter of door te filteren op een bestandsextensie.
Een indexeerfunctie 'scheurt een document' en opent een blob om inhoud te inspecteren. Nadat u verbinding hebt gemaakt met de gegevensbron, is dit de eerste stap in de pijplijn. Voor blobgegevens worden hier PDF-, Office-documenten en andere inhoudstypen gedetecteerd. Document kraken met tekstextractie is niet in rekening gebracht. Als uw blobs afbeeldingsinhoud bevatten, worden afbeeldingen genegeerd, tenzij u AI-verrijking toevoegt. Standaardindexering is alleen van toepassing op tekstinhoud.
De Azure Blob-indexeerfunctie wordt geleverd met configuratieparameters en ondersteunt het bijhouden van wijzigingen als de onderliggende gegevens voldoende informatie bieden. Meer informatie over de kernfunctionaliteit in Indexgegevens vindt u in Azure Blob Storage.
Ondersteunde toegangslagen
Blob Storage-toegangslagen zijn onder andere dynamisch, statisch, koud en archief. Indexeerfuncties kunnen blobs ophalen op dynamische, statische en koude toegangslagen.
Ondersteunde inhoudstypen
Door een blobindexeerfunctie uit te voeren over een container, kunt u tekst en metagegevens extraheren uit de volgende inhoudstypen met één query:
- CSV (zie CSV-blobs indexeren)
- EML
- EPUB
- GZ
- HTML
- JSON (zie JSON-blobs indexeren)
- KML (XML voor geografische weergaven)
- Microsoft Office-indelingen: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (e-mailberichten van Outlook), XML (zowel 2003 als 2006 WORD XML)
- Documentindelingen openen: ODT, ODS, ODP
- Tekstbestanden zonder opmaak (zie ook Indexering van tekst zonder opmaak)
- RTF
- XML
- ZIP
Bepalen welke blobs worden geïndexeerd
U kunt bepalen welke blobs worden geïndexeerd en welke worden overgeslagen door het bestandstype van de blob of door eigenschappen in te stellen op de blob zelf, waardoor de indexeerfunctie deze overslaat.
Voeg specifieke bestandsextensies toe door in te stellen "indexedFileNameExtensions" op een door komma's gescheiden lijst met bestandsextensies (met een voorlooppunt). Sluit specifieke bestandsextensies uit door de extensies in te stellen "excludedFileNameExtensions" die moeten worden overgeslagen. Als dezelfde extensie zich in beide lijsten bevindt, wordt deze uitgesloten van indexering.
PUT /indexers/[indexer name]?api-version=2024-07-01
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Metagegevens overslaan toevoegen aan de blob
De configuratieparameters van de indexeerfunctie zijn van toepassing op alle blobs in de container of map. Soms wilt u bepalen hoe afzonderlijke blobs worden geïndexeerd.
Voeg de volgende metagegevenseigenschappen en -waarden toe aan blobs in Blob Storage. Wanneer de indexeerfunctie deze eigenschap tegenkomt, wordt de blob of de inhoud ervan in de indexeringsuitvoering overgeslagen.
| Eigenschapsnaam | Eigenschapwaarde | Uitleg |
|---|---|---|
| "AzureSearch_Skip" | "true" |
Hiermee geeft u de blob-indexeerfunctie de opdracht om de blob volledig over te slaan. Er wordt niet geprobeerd om metagegevens te extraheren of inhoud te extraheren. Dit is handig wanneer een bepaalde blob herhaaldelijk mislukt en het indexeringsproces onderbreekt. |
| "AzureSearch_SkipContent" | "true" |
Dit komt overeen met de "dataToExtract" : "allMetadata" instelling die hierboven is beschreven voor een bepaalde blob. |
Blobmetagegevens indexeren
Een veelvoorkomend scenario waarmee u eenvoudig door blobs van elk inhoudstype kunt sorteren, is door zowel aangepaste metagegevens als systeemeigenschappen voor elke blob te indexeren. Op deze manier wordt informatie voor alle blobs geïndexeerd, ongeacht het documenttype, die is opgeslagen in een index in uw zoekservice. Met behulp van de nieuwe index kunt u vervolgens doorgaan met sorteren, filteren en facet voor alle blobopslaginhoud.
Notitie
Blob-indextags worden systeemeigen geïndexeerd door de Blob Storage-service en beschikbaar gesteld voor query's. Als de sleutel-/waardekenmerken van uw blobs indexerings- en filtermogelijkheden vereisen, moeten blobindextags worden gebruikt in plaats van metagegevens.
Zie Gegevens beheren en zoeken in Azure Blob Storage met Blob Index voor meer informatie over Blob Index.
Blob-inhoud zoeken in een zoekindex
De uitvoer van een indexeerfunctie is een zoekindex die wordt gebruikt voor interactieve verkenning met behulp van vrije tekst en gefilterde query's in een client-app. Voor de eerste verkenning en verificatie van inhoud raden we u aan te beginnen met Search Explorer in de portal om de documentstructuur te onderzoeken. In Search Explorer kunt u het volgende gebruiken:
Een permanentere oplossing is het verzamelen van query-invoer en het antwoord presenteren als zoekresultaten in een clienttoepassing. In de volgende C#-zelfstudie wordt uitgelegd hoe u een zoektoepassing bouwt: Zoekfunctie toevoegen aan een MVC-toepassing (ASP.NET Core).