Prestaties van Stream Analytics-taken analyseren met behulp van metrische gegevens en dimensies
Als u de status van een Azure Stream Analytics-taak wilt begrijpen, is het belangrijk om te weten hoe u de metrische gegevens en dimensies van de taak gebruikt. U kunt Azure Portal, de Visual Studio Code Stream Analytics-extensie of een SDK gebruiken om de metrische gegevens en dimensies op te halen waarin u geïnteresseerd bent.
In dit artikel wordt gedemonstreert hoe u metrische gegevens en dimensies van Stream Analytics-taken gebruikt om de prestaties van een taak te analyseren via Azure Portal.
Watermerkvertraging en vastgelegde invoergebeurtenissen zijn de belangrijkste metrische gegevens om de prestaties van uw Stream Analytics-taak te bepalen. Als de watermerkvertraging van uw taak voortdurend toeneemt en invoergebeurtenissen worden teruggelogd, kan uw taak niet op de hoogte blijven van de snelheid van invoergebeurtenissen en tijdig uitvoer produceren.
Laten we eens kijken naar verschillende voorbeelden om de prestaties van een taak te analyseren via de metrische gegevens voor watermerkvertraging als uitgangspunt.
Geen invoer voor een bepaalde partitie verhoogt de vertraging van het taakwatermerk
Als de watermerkvertraging van uw parallelle taak geleidelijk toeneemt, gaat u naar Metrische gegevens. Gebruik vervolgens deze stappen om erachter te komen of de hoofdoorzaak een gebrek aan gegevens is in sommige partities van uw invoerbron:
Controleer welke partitie de toenemende watermerkvertraging heeft. Selecteer de meetwaarde Watermerkvertraging en splitst deze op basis van de dimensie Partitie-id . In het volgende voorbeeld heeft partitie 465 een hoge watermerkvertraging.

Controleer of er invoergegevens ontbreken voor deze partitie. Selecteer de metrische gegevens voor invoerevenementen en filter deze op deze specifieke partitie-id.
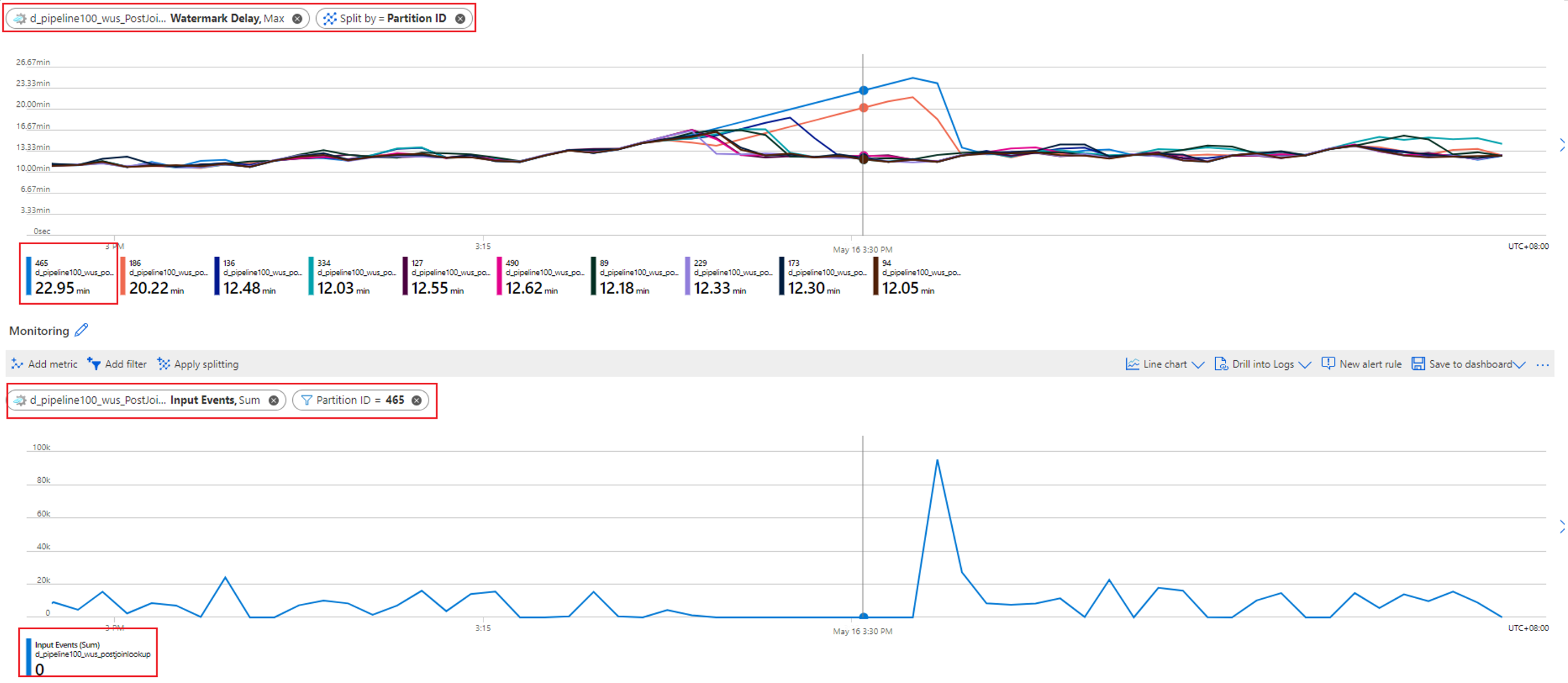


Welke verdere actie kunt u ondernemen?
De watermerkvertraging voor deze partitie neemt toe omdat er geen invoergebeurtenissen naar deze partitie stromen. Als het tolerantievenster van uw taak voor late aankomst enkele uren is en er geen invoergegevens naar een partitie stromen, wordt verwacht dat de watermerkvertraging voor die partitie blijft toenemen totdat het venster voor late aankomst is bereikt.
Als uw venster voor late aankomst bijvoorbeeld 6 uur is en invoergegevens niet naar invoerpartitie 1 stromen, neemt de watermerkvertraging voor uitvoerpartitie 1 toe totdat deze 6 uur bereikt. U kunt controleren of uw invoerbron gegevens produceert zoals verwacht.
Scheeftrekken van invoergegevens veroorzaakt een hoge watermerkvertraging
Zoals eerder vermeld, is het eerste wat u moet doen wanneer uw gênant parallelle taak een hoge watermerkvertraging heeft, de metrische gegevens voor watermerkvertraging opsplitsen met de dimensie Partitie-id. U kunt vervolgens bepalen of alle partities een hoge watermerkvertraging hebben of slechts een paar van deze partities.
In het volgende voorbeeld hebben partities 0 en 1 een hogere watermerkvertraging (ongeveer 20 tot 30 seconden) dan de andere acht partities hebben. De watermerkvertragingen van de andere partities zijn altijd stabiel op ongeveer 8 tot 10 seconden.

Laten we eens kijken hoe de invoergegevens eruit zien voor al deze partities met de metrische invoer gebeurtenissen gesplitst op partitie-id:

Welke verdere actie kunt u ondernemen?
Zoals in het voorbeeld wordt weergegeven, ontvangen de partities (0 en 1) met een hoge watermerkvertraging aanzienlijk meer invoergegevens dan andere partities. We noemen deze gegevens scheeftrekken. De streamingknooppunten die de partities verwerken met scheeftrekken van gegevens, moeten meer CPU- en geheugenresources verbruiken dan andere, zoals wordt weergegeven in de volgende schermopname.

Streamingknooppunten die partities verwerken met een hogere scheeftrekken van gegevens, vertonen een hoger CPU- en/of STREAMING-eenheidsgebruik (SU). Dit gebruik is van invloed op de prestaties van de taak en verhoogt de watermerkvertraging. Om dit te verhelpen, moet u uw invoergegevens gelijkmatiger partitioneren.
U kunt dit probleem ook oplossen met een fysiek taakdiagram. Zie fysiek taakdiagram: De ongelijke gedistribueerde invoergebeurtenissen (gegevensverschil) identificeren.
Overbelaste CPU of geheugen verhoogt de watermerkvertraging
Wanneer een gênant parallelle taak een toenemende watermerkvertraging heeft, kan het gebeuren op niet slechts één of meerdere partities, maar op alle partities. Hoe bevestigt u dat uw taak in dit geval valt?
Splits de metriek Watermerkvertraging op partitie-id. Voorbeeld:
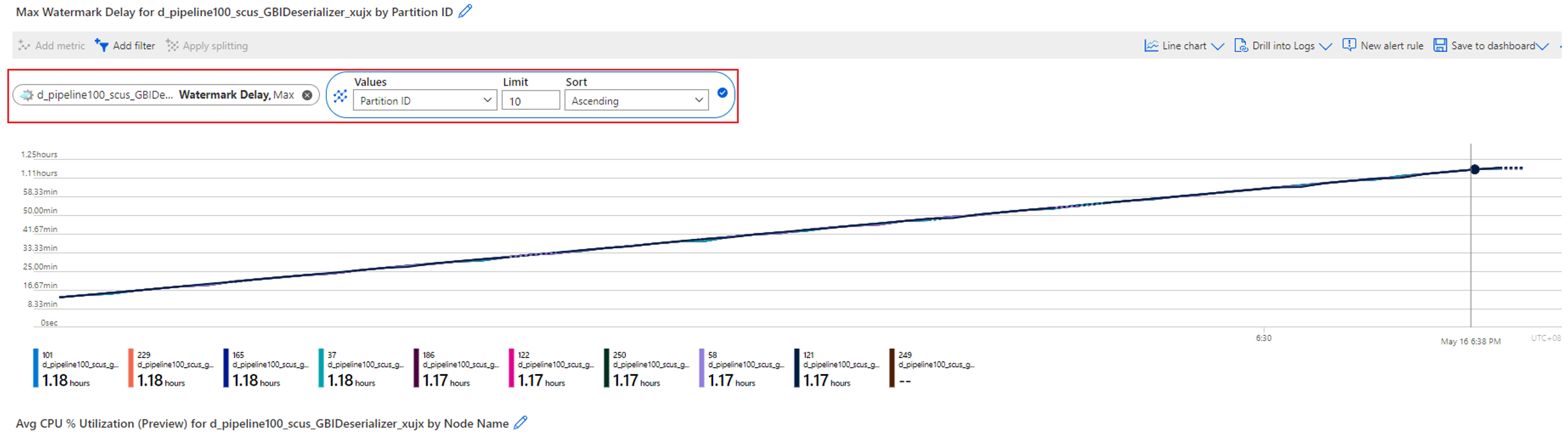
Splits de metrische gegevens voor invoergebeurtenissen op partitie-id om te bevestigen of er sprake is van scheeftrekken van gegevens in invoergegevens voor elke partitie.
Controleer het CPU- en SU-gebruik om te zien of het gebruik in alle streamingknooppunten te hoog is.
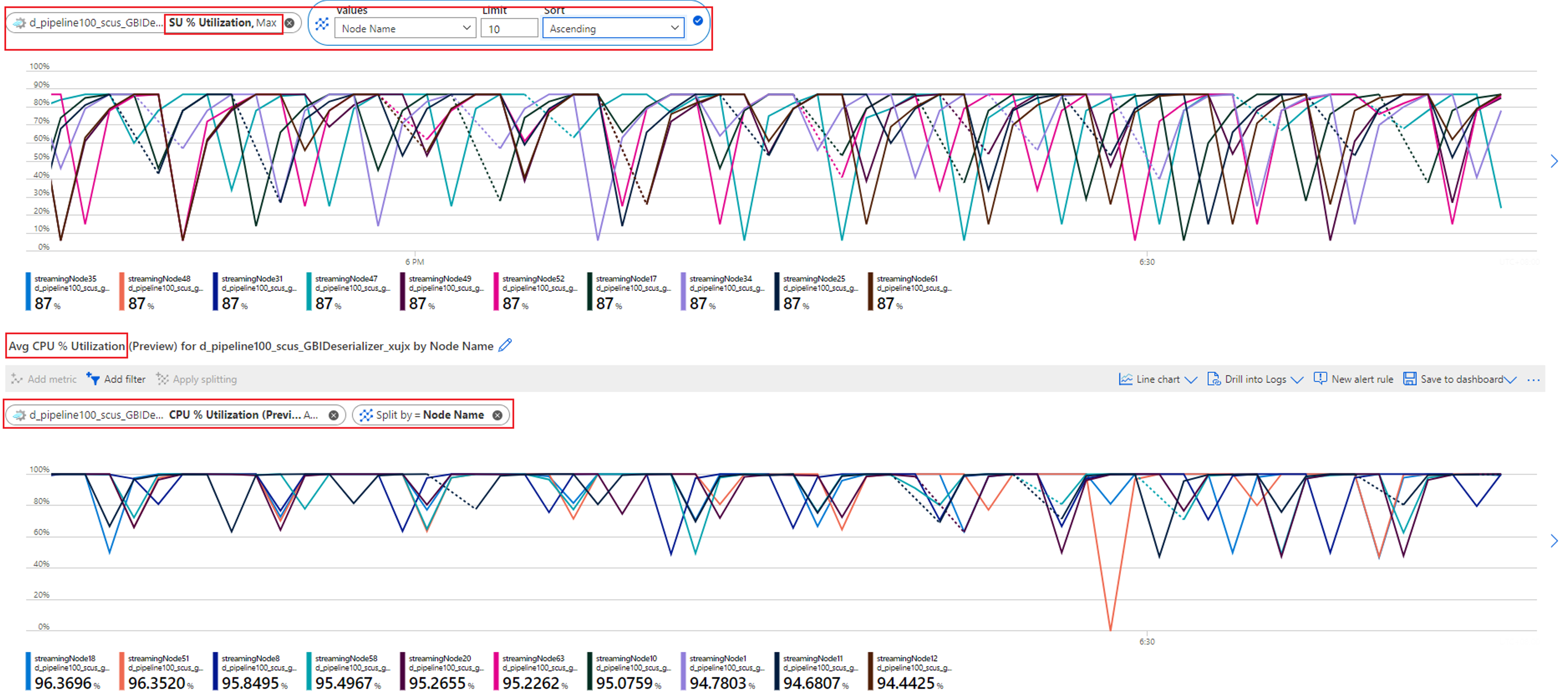
Als het CPU- en SU-gebruik zeer hoog is (meer dan 80 procent) in alle streamingknooppunten, kunt u concluderen dat deze taak een grote hoeveelheid gegevens bevat die binnen elk streamingknooppunt wordt verwerkt.
U kunt verder controleren hoeveel partities aan één streamingknooppunt worden toegewezen door de metrische gegevens voor invoerevenementen te controleren. Filter op streamingknooppunt-id met de dimensie Knooppuntnaam en splits op partitie-id.
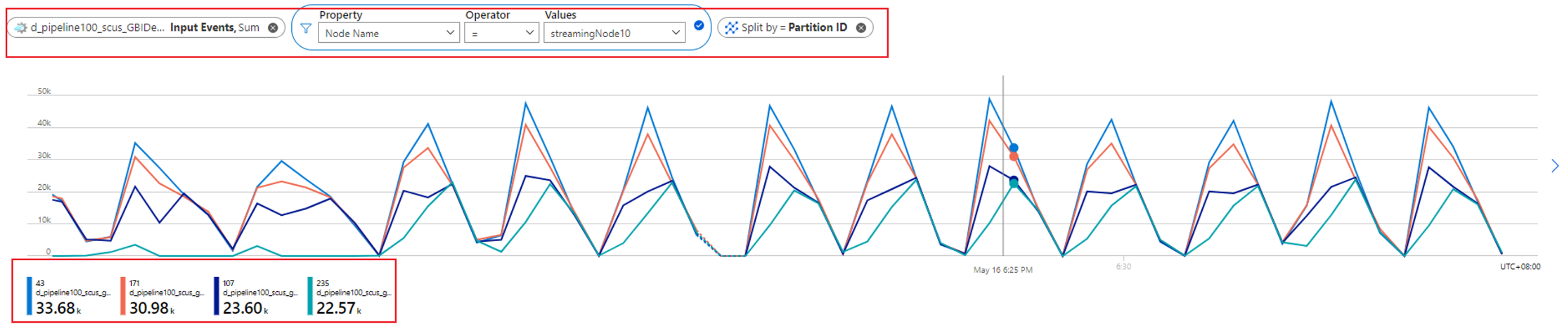
In de voorgaande schermopname ziet u dat vier partities worden toegewezen aan één streamingknooppunt dat ongeveer 90 tot 100 procent van de resource van het streamingknooppunt in beslag neemt. U kunt een vergelijkbare benadering gebruiken om de rest van de streamingknooppunten te controleren om te controleren of ze ook gegevens van vier partities verwerken.



Welke verdere actie kunt u ondernemen?
Mogelijk wilt u het aantal partities voor elk streamingknooppunt verminderen om de invoergegevens voor elk streamingknooppunt te verminderen. Om dit te bereiken, kunt u de SU's verdubbelen om elk streamingknooppunt gegevens van twee partities te laten verwerken. U kunt ook vier keer zo veel mogelijk de SU's gebruiken om elk streamingknooppunt gegevens uit één partitie te laten verwerken. Zie Streaming-eenheden begrijpen en aanpassen voor informatie over de relatie tussen su-toewijzing en het aantal streamingknooppunten.
Wat moet u doen als de watermerkvertraging nog steeds toeneemt wanneer één streamingknooppunt gegevens van één partitie verwerkt? Partitioneer uw invoer opnieuw met meer partities om de hoeveelheid gegevens in elke partitie te verminderen. Zie Repartitioning gebruiken om Azure Stream Analytics-taken te optimaliseren voor meer informatie.
U kunt dit probleem ook oplossen met een fysiek taakdiagram. Zie het diagram van de fysieke taak: de oorzaak van overbelaste CPU of geheugen identificeren.