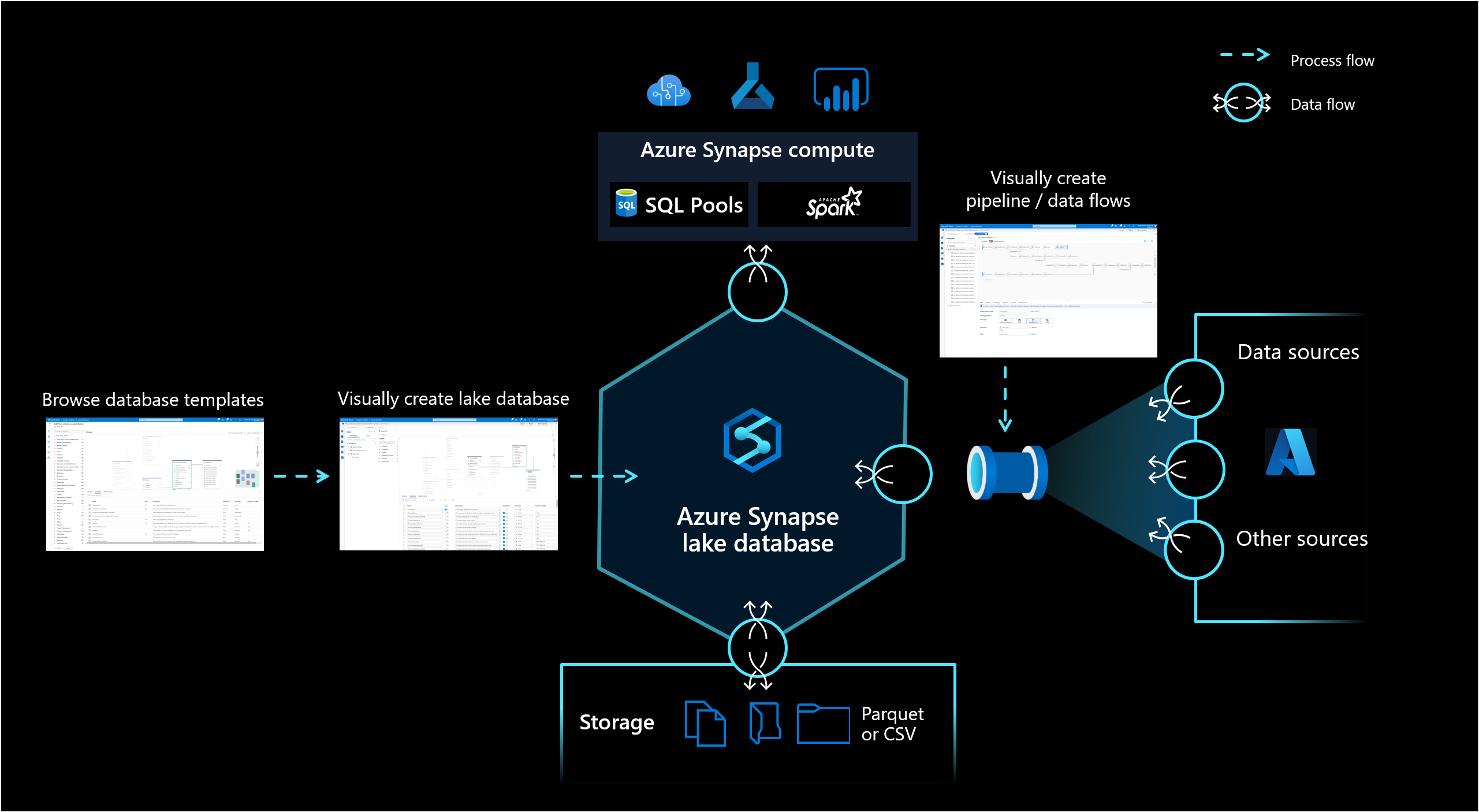
Lake-database
Met de lake-database in Azure Synapse Analytics kunnen klanten het databaseontwerp, meta-informatie over de opgeslagen gegevens en de mogelijkheid om te beschrijven hoe en waar de gegevens moeten worden opgeslagen, samenbrengen. Lake-database is een oplossing voor de uitdaging van de huidige data lakes, waar het moeilijk is om te begrijpen hoe gegevens zijn gestructureerd.
Databaseontwerper
De nieuwe databaseontwerper in Synapse Studio biedt u de mogelijkheid om een gegevensmodel voor uw lake-database te maken en er aanvullende informatie aan toe te voegen. Elke entiteit en elk kenmerk kunnen worden beschreven om meer informatie te bieden over het model, dat niet alleen entiteiten, maar ook relaties bevat. Met name het onvermogen om relaties te modelleren is een uitdaging geweest voor de interactie op de data lake. Deze uitdaging wordt nu aangepakt met een geïntegreerde ontwerper die mogelijkheden biedt die beschikbaar waren in databases, maar niet op het meer. Door de mogelijkheid om beschrijvingen en mogelijke demowaarden toe te voegen aan het model, kunnen personen die er in de toekomst mee werken, informatie krijgen waar ze deze nodig hebben om een beter inzicht te krijgen in de gegevens.
Gegevensopslag
Lake-databases gebruiken een data lake in het Azure Storage-account om de gegevens van de database op te slaan. De gegevens kunnen worden opgeslagen in Parquet-, Delta- of CSV-indeling en er kunnen verschillende instellingen worden gebruikt om de opslag te optimaliseren. Elke lake-database maakt gebruik van een gekoppelde service om de locatie van de hoofdgegevensmap te definiëren. Voor elke entiteit worden standaard afzonderlijke mappen gemaakt in deze databasemap op de data lake. Standaard hebben alle tabellen in een lake-database dezelfde indeling, maar de indelingen en locatie van de gegevens kunnen per entiteit worden gewijzigd als dat wordt aangevraagd.
Notitie
Als u een lake-database publiceert, worden er geen onderliggende structuren of schema's gemaakt die nodig zijn om query's uit te voeren op de gegevens in Spark of SQL. Na het publiceren laadt u gegevens in uw lake-database met behulp van pijplijnen om te beginnen met het uitvoeren van query's.
Momenteel wordt ondersteuning voor Delta-indeling voor lake-databases niet ondersteund in Synapse Studio.
De synchronisatie van lake-databaseobjecten tussen storage en Synapse is in één richting. Zorg ervoor dat u een lake-databaseobject maakt of een schema wijzigt met behulp van de databaseontwerper in Synapse Studio. Als u in plaats daarvan dergelijke wijzigingen aanbrengt vanuit Spark of rechtstreeks in de opslag, worden de definities van uw lake-databases niet meer gesynchroniseerd. Als dit gebeurt, ziet u mogelijk oude lake-databasedefinities in de databaseontwerper. U moet dergelijke wijzigingen repliceren en publiceren in de databaseontwerper om uw lake-databases weer gesynchroniseerd te maken.
Database compute
De lake-database wordt weergegeven in synapse SQL serverloze SQL-pool en Apache Spark, zodat gebruikers de mogelijkheid hebben om opslag los te koppelen van rekenkracht. Met de metagegevens die zijn gekoppeld aan de Lake-database, kunnen verschillende rekenengines niet alleen een geïntegreerde ervaring bieden, maar ook aanvullende informatie gebruiken (bijvoorbeeld relaties) die oorspronkelijk niet werd ondersteund in de data lake.
Volgende stappen
Ga verder met het verkennen van de mogelijkheden van de databaseontwerper met behulp van de onderstaande koppelingen.