Zelfstudie: Apache Spark-taakdefinitie maken in Synapse Studio
Deze zelfstudie laat zien hoe u Synapse Studio gebruikt om Apache Spark-taakdefinities te maken en deze vervolgens naar een serverloze Apache Spark-pool te verzenden.
Deze zelfstudie bestaat uit de volgende taken:
- Een Apache Spark-taakdefinitie maken voor PySpark (Python)
- Een Apache Spark-taakdefinitie maken voor Spark (Scala)
- Een Apache Spark-taakdefinitie maken voor .NET Spark (C#/F#)
- Taakdefinitie maken door een JSON-bestand te importeren
- Een Apache Spark-taakdefinitiebestand exporteren naar lokaal
- Een Apache Spark-taakdefinitie verzenden als batchtaak
- Een Apache Spark-taakdefinitie toevoegen aan de pijplijn
Vereisten
Zorg ervoor dat u aan de volgende vereisten voldoet voordat u met deze zelfstudie begint:
- Een Azure Synapse Analytics-werkruimte. Zie Een Azure Synapse Analytics-werkruimte maken voor instructies.
- Een serverloze Apache Spark-pool.
- Een ADLS Gen2-opslagaccount. U moet de bijdrager voor opslagblobgegevens zijn van het ADLS Gen2-bestandssysteem waarmee u wilt werken. Als dat niet het geval is, moet u de machtiging handmatig toevoegen.
- Als u de standaardopslag van de werkruimte niet wilt gebruiken, koppelt u het vereiste ADLS Gen2-opslagaccount in Synapse Studio.
Een Apache Spark-taakdefinitie maken voor PySpark (Python)
In deze sectie maakt u een Apache Spark-taakdefinitie voor PySpark (Python).
Open Synapse Studio.
U kunt naar Voorbeeldbestanden voor het maken van Apache Spark-taakdefinities gaan om voorbeeldbestanden voor python.zip te downloaden. Pak het gecomprimeerde pakket vervolgens uit, inclusief de bestanden wordcount.py en shakespeare.txt.

Selecteer Data -Linked ->>Azure Data Lake Storage Gen2 en upload wordcount.py en shakespeare.txt naar uw ADLS Gen2-bestandssysteem.

Selecteer de hub Ontwikkelen, selecteer het pictogram ‘+’ en selecteer Spark-taakdefinitie om een nieuwe Spark-taakdefinitie te maken.

Selecteer PySpark (Python) in de vervolgkeuzelijst Taal in het hoofdvenster van de Apache Spark-taakdefinitie.

Vul de gegevens in voor de Apache Spark-taakdefinitie.
Eigenschappen Beschrijving Naam van taakdefinitie Voer een naam in voor de Apache Spark-taakdefinitie. Deze naam kan op elk gewenst moment worden bijgewerkt totdat deze wordt gepubliceerd.
Voorbeeld:job definition samplePrimair definitiebestand Het primaire bestand dat wordt gebruikt voor de taak. Selecteer een PY-bestand uit uw opslag. U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount.
Voorbeeld:abfss://…/path/to/wordcount.pyOpdrachtregelargumenten Optionele argumenten voor de taak.
Monster:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Opmerking: Twee argumenten voor de definitie van de voorbeeldtaak worden gescheiden door een spatie.Verwijzingsbestanden Aanvullende bestanden die worden gebruikt voor verwijzingen in het hoofddefinitiebestand. U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount. Spark-pool De taak wordt verzonden naar de geselecteerde Apache Spark-pool. Spark-versie De versie van Apache Spark waarin de Apache Spark-pool wordt uitgevoerd. Uitvoerders Aantal uitvoerders dat moet worden opgegeven in de gespecificeerde Apache Spark-pool voor de taak. Grootte van uitvoerder Aantal kernen en het geheugen die moet worden gebruikt voor de uitvoerders die in de gespecificeerde Apache Spark-pool voor de taak zijn opgegeven. Grootte van stuurprogramma Aantal kernen en het geheugen die moet worden gebruikt voor het stuurprogramma dat in de gespecificeerde Apache Spark-pool voor de taak is opgegeven. Apache Spark-configuratie Pas configuraties aan door hieronder eigenschappen toe te voegen. Als u geen eigenschap toevoegt, gebruikt Azure Synapse indien van toepassing de standaardwaarde. 
Selecteer Publiceren om de Apache Spark-taakdefinitie op te slaan.

Een Apache Spark-taakdefinitie maken voor Apache Spark (Scala)
In deze sectie maakt u een Apache Spark-taakdefinitie voor Apache Spark (Scala).
Open Azure Synapse Studio.
U kunt naar Voorbeeldbestanden voor het maken van Apache Spark-taakdefinities gaan om voorbeeldbestanden voor scala.zip te downloaden. Pak het gecomprimeerde pakket vervolgens uit, inclusief de bestanden wordcount.jar en shakespeare.txt.

Selecteer Data -Linked ->>Azure Data Lake Storage Gen2 en upload wordcount.jar en shakespeare.txt naar uw ADLS Gen2-bestandssysteem.

Selecteer de hub Ontwikkelen, selecteer het pictogram ‘+’ en selecteer Spark-taakdefinitie om een nieuwe Spark-taakdefinitie te maken. (De voorbeeldafbeelding is hetzelfde als stap 4 van Een Apache Spark-taakdefinitie (Python) maken voor PySpark.)
Selecteer Spark(Scala) in de vervolgkeuzelijst Taal in het hoofdvenster van de Apache Spark-taakdefinitie.

Vul de gegevens in voor de Apache Spark-taakdefinitie. U kunt de voorbeeldgegevens kopiëren.
Eigenschappen Beschrijving Naam van taakdefinitie Voer een naam in voor de Apache Spark-taakdefinitie. Deze naam kan op elk gewenst moment worden bijgewerkt totdat deze wordt gepubliceerd.
Voorbeeld:scalaPrimair definitiebestand Het primaire bestand dat wordt gebruikt voor de taak. Selecteer een JAR-bestand uit uw opslag. U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount.
Voorbeeld:abfss://…/path/to/wordcount.jarHoofdklassenaam De volledig gekwalificeerde id of de hoofdklasse die zich in het hoofddefinitiebestand bevindt.
Voorbeeld:WordCountOpdrachtregelargumenten Optionele argumenten voor de taak.
Monster:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Opmerking: Twee argumenten voor de definitie van de voorbeeldtaak worden gescheiden door een spatie.Verwijzingsbestanden Aanvullende bestanden die worden gebruikt voor verwijzingen in het hoofddefinitiebestand. U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount. Spark-pool De taak wordt verzonden naar de geselecteerde Apache Spark-pool. Spark-versie De versie van Apache Spark waarin de Apache Spark-pool wordt uitgevoerd. Uitvoerders Aantal uitvoerders dat moet worden opgegeven in de gespecificeerde Apache Spark-pool voor de taak. Grootte van uitvoerder Aantal kernen en het geheugen die moet worden gebruikt voor de uitvoerders die in de gespecificeerde Apache Spark-pool voor de taak zijn opgegeven. Grootte van stuurprogramma Aantal kernen en het geheugen die moet worden gebruikt voor het stuurprogramma dat in de gespecificeerde Apache Spark-pool voor de taak is opgegeven. Apache Spark-configuratie Pas configuraties aan door hieronder eigenschappen toe te voegen. Als u geen eigenschap toevoegt, gebruikt Azure Synapse indien van toepassing de standaardwaarde. 
Selecteer Publiceren om de Apache Spark-taakdefinitie op te slaan.

Een Apache Spark-taakdefinitie maken voor .NET Spark (C#/F#)
In deze sectie maakt u een Apache Spark-taakdefinitie voor .NET Spark(C#/F#).
Open Azure Synapse Studio.
U kunt naar Voorbeeldbestanden voor het maken van Apache Spark-taakdefinities gaan om voorbeeldbestanden voor dotnet.zip te downloaden. Pak het gecomprimeerde pakket vervolgens uit, inclusief de bestanden wordcount.zip en shakespeare.txt.

Selecteer Data -Linked ->>Azure Data Lake Storage Gen2 en upload wordcount.zip en shakespeare.txt naar uw ADLS Gen2-bestandssysteem.

Selecteer de hub Ontwikkelen, selecteer het pictogram ‘+’ en selecteer Spark-taakdefinitie om een nieuwe Spark-taakdefinitie te maken. (De voorbeeldafbeelding is hetzelfde als stap 4 van Een Apache Spark-taakdefinitie (Python) maken voor PySpark.)
Selecteer .NET Spark(C#/F#) in de vervolgkeuzelijst Taal in het hoofdvenster van de Apache Spark-taakdefinitie.

Vul de gegevens in voor de Apache Spark-taakdefinitie. U kunt de voorbeeldgegevens kopiëren.
Eigenschappen Beschrijving Naam van taakdefinitie Voer een naam in voor de Apache Spark-taakdefinitie. Deze naam kan op elk gewenst moment worden bijgewerkt totdat deze wordt gepubliceerd.
Voorbeeld:dotnetPrimair definitiebestand Het primaire bestand dat wordt gebruikt voor de taak. Selecteer een ZIP-bestand dat uw .NET voor Apache Spark-toepassing bevat (dat wil zeggen, het belangrijkste uitvoerbare bestand, DLL's met door de gebruiker gedefinieerde functies en andere vereiste bestanden) van uw opslag. U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount.
Voorbeeld:abfss://…/path/to/wordcount.zipUitvoerbaar hoofdbestand Het belangrijkste uitvoerbare bestand in het primaire ZIP-definitiebestand.
Voorbeeld:WordCountOpdrachtregelargumenten Optionele argumenten voor de taak.
Monster:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Opmerking: Twee argumenten voor de definitie van de voorbeeldtaak worden gescheiden door een spatie.Verwijzingsbestanden Aanvullende bestanden die nodig zijn voor de werkknooppunten voor het uitvoeren van de .NET voor Apache Spark-toepassing die niet is opgenomen in het bestand met de primaire definitie (dat wil zeggen, afhankelijke JAR's, aanvullende door de gebruiker gedefinieerde functie-DLL's en andere configuratiebestanden). U kunt Bestand uploaden selecteren om het bestand te uploaden naar een opslagaccount. Spark-pool De taak wordt verzonden naar de geselecteerde Apache Spark-pool. Spark-versie De versie van Apache Spark waarin de Apache Spark-pool wordt uitgevoerd. Uitvoerders Aantal uitvoerders dat moet worden opgegeven in de gespecificeerde Apache Spark-pool voor de taak. Grootte van uitvoerder Aantal kernen en het geheugen die moet worden gebruikt voor de uitvoerders die in de gespecificeerde Apache Spark-pool voor de taak zijn opgegeven. Grootte van stuurprogramma Aantal kernen en het geheugen die moet worden gebruikt voor het stuurprogramma dat in de gespecificeerde Apache Spark-pool voor de taak is opgegeven. Apache Spark-configuratie Pas configuraties aan door hieronder eigenschappen toe te voegen. Als u geen eigenschap toevoegt, gebruikt Azure Synapse indien van toepassing de standaardwaarde. 
Selecteer Publiceren om de Apache Spark-taakdefinitie op te slaan.

Notitie
Als voor apache Spark-configuratie de Apache Spark-taakdefinitie voor de Apache Spark-configuratie niets speciaals doet, wordt de standaardconfiguratie gebruikt bij het uitvoeren van de taak.
Apache Spark-taakdefinitie maken door een JSON-bestand te importeren
U kunt een bestaand lokaal JSON-bestand importeren in de Azure Synapse-werkruimte vanuit het menu Acties (...) van de Apache Spark-taakdefinitieverkenner om een nieuwe Apache Spark-taakdefinitie te maken.

De Spark-taakdefinitie is volledig compatibel met livy-API. U kunt extra parameters toevoegen voor andere Livy-eigenschappen (Livy Docs - REST API (apache.org) in het lokale JSON-bestand. U kunt ook de spark-configuratieparameters opgeven in de configuratie-eigenschap, zoals hieronder wordt weergegeven. Vervolgens kunt u het JSON-bestand opnieuw importeren om een nieuwe Apache Spark-taakdefinitie te maken voor uw batchtaak. Voorbeeld van JSON voor spark-definitie importeren:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}

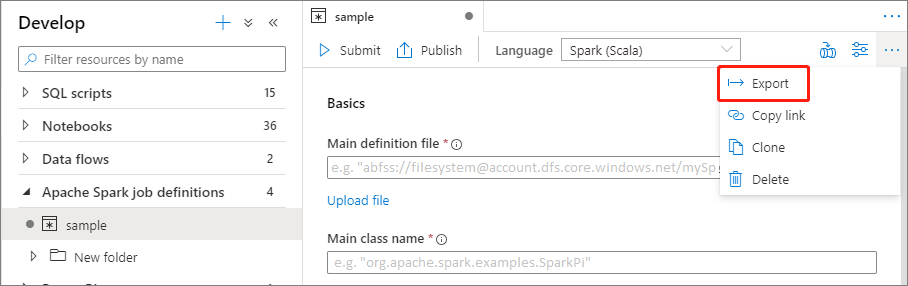
Een bestaand Apache Spark-taakdefinitiebestand exporteren
U kunt bestaande Apache Spark-taakdefinitiebestanden exporteren naar lokaal vanuit het menu Acties (...) van het Bestandenverkenner. U kunt het JSON-bestand verder bijwerken voor aanvullende Livy-eigenschappen en het opnieuw importeren om zo nodig een nieuwe taakdefinitie te maken.

Een Apache Spark-taakdefinitie verzenden als batchtaak
Nadat u een Apache Spark-taakdefinitie hebt gemaakt, kunt u deze verzenden naar een Apache Spark-pool. Zorg ervoor dat u de bijdrager voor opslagblobgegevens bent van het ADLS Gen2-bestandssysteem waarmee u wilt werken. Als dat niet het geval is, moet u de machtiging handmatig toevoegen.
Scenario 1: Apache Spark-taakdefinitie verzenden
Open een Apache Spark-taakdefinitievenster door deze te selecteren.

Selecteer de knop Verzenden om uw project te verzenden naar de geselecteerde Apache Spark-pool. U kunt het tabblad URL voor Spark-bewaking selecteren om de LogQuery van de Apache Spark-toepassing weer te geven.


Scenario 2: Voortgang van Apache Spark-taak weergeven
Selecteer Bewaken en selecteer vervolgens de optie Apache Spark-toepassingen. U kunt de verzonden Apache Spark-toepassing vinden.

Selecteer vervolgens een Apache Spark-toepassing; het venster SparkJobDefinition-taak wordt weergegeven. U kunt de voortgang van de taakuitvoering van daaruit bekijken.

Scenario 3: Uitvoerbestand controleren
Selecteer Data -Linked ->>Azure Data Lake Storage Gen2 (hozhaobdbj), open de eerder gemaakte resultaatmap, ga naar de resultatenmap en controleer of de uitvoer is gegenereerd.

Een Apache Spark-taakdefinitie toevoegen aan de pijplijn
In deze sectie voegt u een Apache Spark-taakdefinitie toe aan de pijplijn.
Open een bestaande Apache Spark-taakdefinitie.
Selecteer het pictogram in de rechterbovenhoek van de Apache Spark-taakdefinitie, kies Bestaande pijplijn of Nieuwe pijplijn. U kunt de pijplijnpagina raadplegen voor meer informatie.


Volgende stappen
Vervolgens kunt u de Azure Synapse Studio gebruiken om Power BI-gegevenssets te maken en Power BI-gegevens te beheren. Ga naar het artikel Een Power BI-werkruimte koppelen aan een Synapse-werkruimte voor meer informatie.