Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Leer hoe u een aangepast deep learning-model traint met behulp van transfer learning, een vooraf getraind TensorFlow-model en de ML.NET Afbeeldingsclassificatie-API om afbeeldingen van betonoppervlakken te classificeren als gekraakt of ongebroken.
In deze handleiding leer je hoe je:
- Het probleem begrijpen
- Meer informatie over ML.NET Afbeeldingsclassificatie-API
- Meer informatie over het vooraf getrainde model
- Transfer learning gebruiken om een aangepast TensorFlow-afbeeldingsclassificatiemodel te trainen
- Afbeeldingen classificeren met het aangepaste model
Vereiste voorwaarden
Het probleem begrijpen
Afbeeldingsclassificatie is een computer vision-probleem. Afbeeldingsclassificatie neemt een afbeelding als invoer en categoriseert deze in een voorgeschreven klasse. Afbeeldingsclassificatiemodellen worden vaak getraind met deep learning en neurale netwerken. Zie Deep Learning versus machine learning voor meer informatie.
Enkele scenario's waarin afbeeldingsclassificatie nuttig is, zijn onder andere:
- Gezichtsherkenning
- Emotiedetectie
- Medische diagnose
- Detectie van oriëntatiepunten
In deze zelfstudie wordt een aangepast afbeeldingsclassificatiemodel getraind om geautomatiseerde visuele inspectie van brugdeks uit te voeren om structuren te identificeren die zijn beschadigd door scheuren.
API voor afbeeldingsclassificatie ML.NET
ML.NET biedt verschillende manieren om afbeeldingsclassificatie uit te voeren. In deze zelfstudie wordt transfer learning toegepast met behulp van de Image Classification API. De Api voor afbeeldingsclassificatie maakt gebruik van TensorFlow.NET, een bibliotheek op laag niveau die C#-bindingen biedt voor de TensorFlow C++-API.
Wat is kennisoverdracht?
Leren overdragen past kennis die is opgedaan van het oplossen van één probleem op een ander gerelateerd probleem toe.
Voor het trainen van een volledig nieuw deep learning-model moeten verschillende parameters, een grote hoeveelheid gelabelde trainingsgegevens en een grote hoeveelheid rekenresources (honderden GPU-uren) worden ingesteld. Met behulp van een vooraf getraind model en het leren van overdrachten kunt u het trainingsproces snel doorlopen.
Trainingsproces
De Afbeeldingsclassificatie-API start het trainingsproces door een vooraf getraind TensorFlow-model te laden. Het trainingsproces bestaat uit twee stappen:
- Knelpuntfase.
- Trainingsfase.
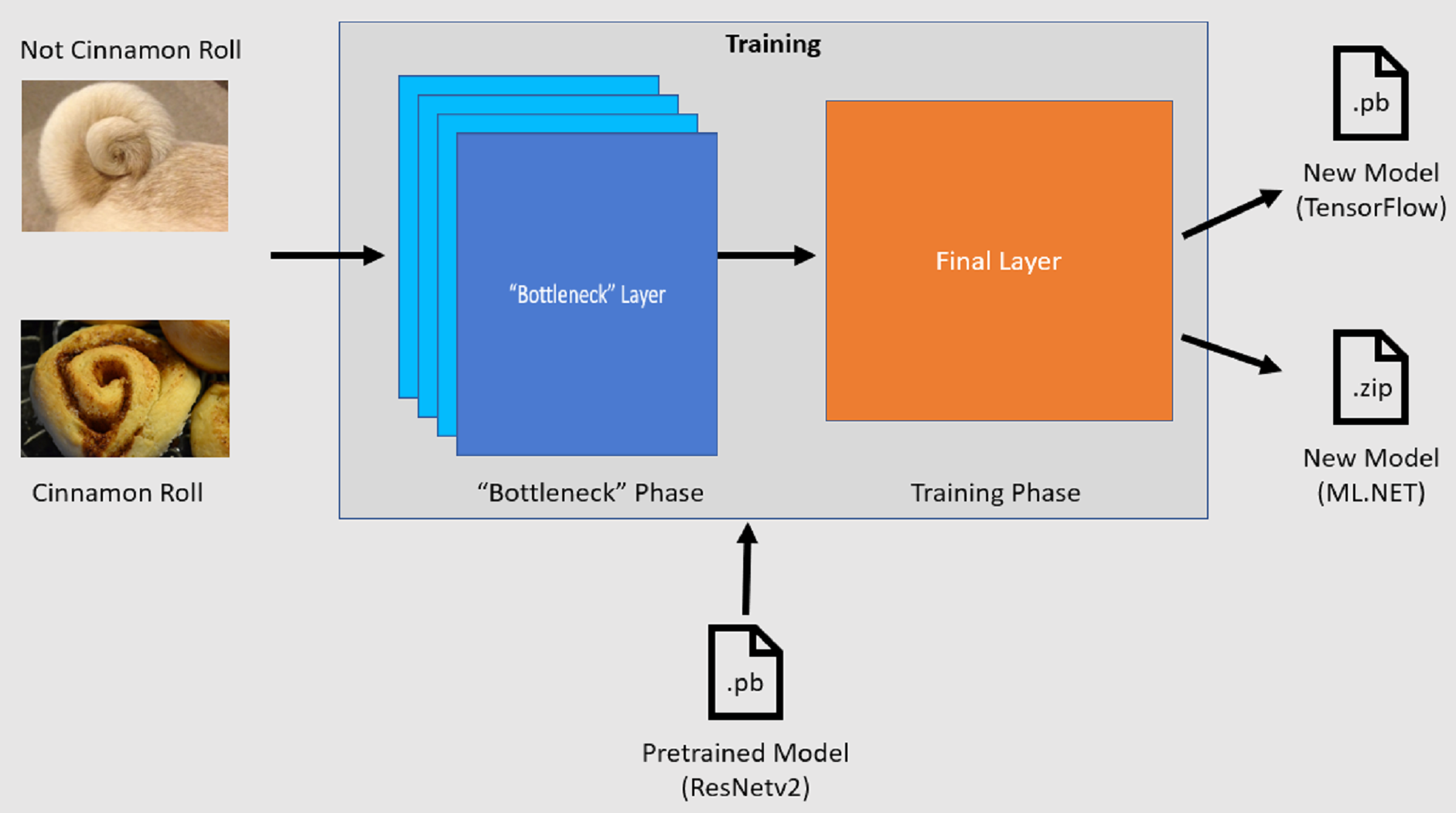
Knelpuntfase
Tijdens de knelpuntfase wordt de set trainingsafbeeldingen geladen en worden de pixelwaarden gebruikt als invoer, of functies, voor de bevroren lagen van het vooraf getrainde model. De bevroren lagen omvatten alle lagen in het neurale netwerk tot aan de voorlaatste laag, informeel bekend als de knelpuntlaag. Deze lagen worden bevroren genoemd omdat er geen training op deze lagen plaatsvindt en bewerkingen passthrough zijn. Het is in deze bevroren lagen waar de patronen op lager niveau die een model helpen onderscheid te maken tussen de verschillende klassen worden berekend. Hoe groter het aantal lagen, hoe meer rekenintensief deze stap is. Gelukkig, omdat dit een eenmalige berekening is, kunnen de resultaten in de cache worden opgeslagen en in latere uitvoeringen worden gebruikt bij het experimenteren met verschillende parameters.
Trainingsfase
Zodra de uitvoerwaarden van de knelpuntfase zijn berekend, worden ze gebruikt als invoer om de laatste laag van het model opnieuw te trainen. Dit proces is iteratief en wordt uitgevoerd voor het aantal keren dat is opgegeven door modelparameters. Tijdens elke uitvoering worden het verlies en de nauwkeurigheid geëvalueerd. Vervolgens worden de juiste aanpassingen aangebracht om het model te verbeteren met als doel het verlies te minimaliseren en de nauwkeurigheid te maximaliseren. Zodra de training is voltooid, worden twee modelindelingen uitgevoerd. Een van deze is de .pb versie van het model en de andere is de .zip ML.NET geserialiseerde versie van het model. Wanneer u werkt in omgevingen die worden ondersteund door ML.NET, is het raadzaam om de .zip versie van het model te gebruiken. In omgevingen waarin ML.NET niet wordt ondersteund, hebt u echter de mogelijkheid om de .pb versie te gebruiken.
Meer informatie over het vooraf getrainde model
Het vooraf getrainde model dat in deze zelfstudie wordt gebruikt, is de 101-laagvariant van het ResNet-model (Residual Network) v2. Het oorspronkelijke model is getraind om afbeeldingen in duizend categorieën te classificeren. Het model neemt als invoer een afbeelding van grootte 224 x 224 en voert de klassenkans uit voor elk van de klassen waarop het is getraind. Een deel van dit model wordt gebruikt om een nieuw model te trainen met behulp van aangepaste afbeeldingen om voorspellingen te doen tussen twee klassen.
Console-applicatie maken
Nu u een algemeen begrip hebt van het leren overdragen en de API voor afbeeldingsclassificatie, is het tijd om de toepassing te bouwen.
Maak een C# -consoletoepassing met de naam 'DeepLearning_ImageClassification_Binary'. Klik op de knop Volgende.
Kies .NET 8 als het framework dat u wilt gebruiken en selecteer vervolgens Maken.
Installeer het Microsoft.ML NuGet-pakket:
Opmerking
In dit voorbeeld wordt de laatste stabiele versie van de vermelde NuGet-pakketten gebruikt, tenzij anders vermeld.
- Klik in Solution Explorer met de rechtermuisknop op uw project en selecteer NuGet-pakketten beheren.
- Kies 'nuget.org' als pakketbron.
- Selecteer het tabblad Bladeren.
- Schakel het selectievakje Prerelease opnemen in.
- Zoek naar Microsoft.ML.
- Selecteer de knop Installeren .
- Selecteer de knop Accepteren in het dialoogvenster Licentie accepteren als u akkoord gaat met de licentievoorwaarden voor de vermelde pakketten.
- Herhaal deze stappen voor de NuGet-pakketten Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (versie 2.3.1) en Microsoft.ML.ImageAnalytics .
De gegevens voorbereiden en begrijpen
Opmerking
De gegevenssets voor deze zelfstudie zijn afkomstig van Maguire, Marc; Dorafshan, Sattar; en Thomas, Robert J., "SDNET2018: Een gegevensset met betonscheurafbeeldingen voor machine learning-toepassingen" (2018). Blader door alle gegevenssets. Papier 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 is een afbeeldingsgegevensset die aantekeningen bevat voor gebarsten en niet-gebarsten betonstructuren (brugdeks, muren en bestrating).

De gegevens zijn ingedeeld in drie submappen:
- D bevat brugdekafbeeldingen
- P bevat bestratingsafbeeldingen
- W bevat wandafbeeldingen
Elk van deze submappen bevat twee extra voorvoegselsubmappen:
- C is het voorvoegsel dat wordt gebruikt voor gebarsten oppervlakken
- U is het voorvoegsel dat wordt gebruikt voor niet-gekrakte oppervlakken
In deze zelfstudie worden alleen brugdekafbeeldingen gebruikt.
- Downloaden de dataset en unzip het.
- Maak een map met de naam Assets in uw project om uw gegevenssetbestanden op te slaan.
- Kopieer de cd - en UD-submappen van de onlangs uitgepakte map naar de map Assets .
Invoer- en uitvoerklassen maken
Open het bestand Program.cs en vervang de bestaande inhoud door de volgende
usinginstructies:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Maak een klasse met de naam
ImageData. Deze klasse wordt gebruikt om de in eerste instantie geladen gegevens weer te geven.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatabevat de volgende eigenschappen:-
ImagePathis het volledig pad waar de afbeelding wordt opgeslagen. -
Labelis de categorie waartoe de afbeelding behoort. Dit is de waarde die moet worden voorspeld.
-
Maak klassen voor uw invoer- en uitvoergegevens.
Definieer onder de klasse het schema van uw invoergegevens in een nieuwe klasse met de
ImageDatanaamModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputbevat de volgende eigenschappen:-
Imageis debyte[]weergave van de afbeelding. Het model verwacht dat afbeeldingsgegevens van dit type zijn voor training. -
LabelAsKeyis de numerieke weergave van deLabel. -
ImagePathis het volledig gekwalificeerde pad waar de image is opgeslagen. -
Labelis de categorie waartoe de afbeelding behoort. Dit is de waarde die moet worden voorspeld.
Alleen
ImageenLabelAsKeyworden gebruikt om het model te trainen en voorspellingen te doen. DeImagePathenLabeleigenschappen worden voor het gemak bewaard om toegang te krijgen tot de oorspronkelijke bestandsnaam en categorie van het afbeeldingsbestand.-
Definieer vervolgens onder de klasse het schema van uw uitvoergegevens in een nieuwe klasse met de
ModelInputnaamModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputbevat de volgende eigenschappen:-
ImagePathis het volledig gekwalificeerde pad waar de image is opgeslagen. -
Labelis de oorspronkelijke categorie waartoe de afbeelding behoort. Dit is de waarde die moet worden voorspeld. -
PredictedLabelis de waarde die door het model wordt voorspeld.
ModelInputNet als bij , is alleen hetPredictedLabelvereist om voorspellingen te doen, omdat deze de voorspelling bevat die door het model is gemaakt. DeImagePatheigenschappen enLabeleigenschappen worden voor het gemak bewaard om toegang te krijgen tot de oorspronkelijke naam en categorie van het afbeeldingsbestand.-
Paden definiëren en variabelen initialiseren
Voeg onder de
usinginstructies de volgende code toe aan:Definieer de locatie van de assets.
Initialiseer de
mlContextvariabele met een nieuw exemplaar van MLContext.De MLContext-klasse is een startpunt voor alle ML.NET bewerkingen en het initialiseren van mlContext maakt een nieuwe ML.NET-omgeving die kan worden gedeeld in de werkstroomobjecten voor het maken van modellen. Het is vergelijkbaar, conceptueel gezien, met
DbContextin Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
De gegevens laden
Methode voor het laden van gegevens maken
De afbeeldingen worden opgeslagen in twee submappen. Voordat u de gegevens laadt, moet deze worden opgemaakt in een lijst ImageData met objecten. Hiervoor maakt u de LoadImagesFromDirectory methode:
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
De methode LoadImagesFromDirectory:
- Hiermee haalt u alle bestandspaden op uit de submappen.
- Doorloopt elk van de bestanden met behulp van een
foreachinstructie en controleert of de bestandsextensies worden ondersteund. De API voor afbeeldingsclassificatie ondersteunt JPEG- en PNG-indelingen. - Hiermee haalt u het label voor het bestand op. Als de
useFolderNameAsLabelparameter is ingesteld optrue, wordt de bovenliggende map waarin het bestand wordt opgeslagen als het label gebruikt. Anders wordt verwacht dat het label een voorvoegsel is van de bestandsnaam of de bestandsnaam zelf. - Hiermee maakt u een nieuw exemplaar van
ModelInput.
De gegevens voorbereiden
Voeg de volgende code toe na de regel waar u het nieuwe exemplaar van MLContextmaakt.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
De vorige code:
Roept de
LoadImagesFromDirectoryhulpprogrammamethode aan om de lijst met afbeeldingen op te halen die worden gebruikt voor training na het initialiseren van demlContextvariabele.Laadt de afbeeldingen in een
IDataViewmet behulp van deLoadFromEnumerablemethode.Hiermee worden de gegevens met behulp van de
ShuffleRowsmethode in willekeurige volgorde geschoven. De gegevens worden geladen in de volgorde waarin ze uit de mappen zijn gelezen. De willekeurige volgorde wordt uitgevoerd om deze te verdelen.Voert een voorverwerking uit op de gegevens voorafgaand aan de training. Dit gebeurt omdat machine learning-modellen verwachten dat invoer een numerieke indeling heeft. Met de voorverwerkingscode wordt een
EstimatorChainbestaande uit deMapValueToKeyenLoadRawImageBytestransformaties gemaakt. DeMapValueToKeytransformatie neemt de categorische waarde in deLabelkolom, converteert deze naar een numeriekeKeyTypewaarde en slaat deze op in een nieuwe kolom met de naamLabelAsKey. DeLoadImageswaarden uit deImagePathkolom worden samen met deimageFolderparameter gebruikt om afbeeldingen te laden voor training.Hiermee gebruikt u de
Fitmethode om de gegevens toe te passen op depreprocessingPipelineEstimatorChaingevolgde methodeTransform, die eenIDataViewmet de vooraf verwerkte gegevens retourneert.Splitst de gegevens in trainings-, validatie- en testsets.
Als u een model wilt trainen, is het belangrijk dat u een trainingsgegevensset en een validatiegegevensset hebt. Het model wordt getraind in de trainingsset. Hoe goed het voorspellingen doet over ongelezen gegevens, wordt gemeten door de prestaties van de validatieset. Op basis van de resultaten van die prestaties brengt het model aanpassingen aan wat het heeft geleerd in een poging om te verbeteren. De validatieset kan afkomstig zijn van het splitsen van uw oorspronkelijke gegevensset of van een andere bron die hiervoor al is gereserveerd.
In het codevoorbeeld worden twee splitsingen uitgevoerd. Ten eerste worden de vooraf verwerkte gegevens gesplitst en worden er 70% gebruikt voor training terwijl de resterende 30% wordt gebruikt voor validatie. Vervolgens wordt de validatieset van 30% verder gesplitst in validatie- en testsets waarbij 90% wordt gebruikt voor validatie en 10% wordt gebruikt voor testen.
Een manier om na te denken over het doel van deze gegevenspartities is het nemen van een examen. Bij het studeren voor een examen bekijkt u uw notities, boeken of andere bronnen om inzicht te krijgen in de concepten die op het examen staan. Dit is waar de treinset voor is. Vervolgens kunt u een proefexamen nemen om uw kennis te valideren. Dit is waar de validatieset handig is. U wilt controleren of u de concepten goed begrijpt voordat u het daadwerkelijke examen gaat afleggen. Op basis van deze resultaten noteert u wat u verkeerd hebt ontvangen of niet goed begrijpt en uw wijzigingen opneemt terwijl u het echte examen bekijkt. Ten slotte neemt u het examen. Dit is waarvoor de testset wordt gebruikt. U hebt nog nooit de vragen gezien die op het examen staan, en gebruik nu wat u hebt geleerd van de training en validatie om uw kennis toe te passen op de taak die voor u ligt.
Wijst de partities hun respectieve waarden toe voor de train-, validatie- en testgegevens.
De trainingspijplijn definiëren
Modeltraining bestaat uit twee stappen. Eerst wordt de Afbeeldingsclassificatie-API gebruikt om het model te trainen. Vervolgens worden de gecodeerde labels in de PredictedLabel kolom terug geconverteerd naar de oorspronkelijke categorische waarde met behulp van de MapKeyToValue transformatie.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
De vorige code:
Hiermee maakt u een nieuwe variabele voor het opslaan van een set vereiste en optionele parameters voor een ImageClassificationTrainer. Een ImageClassificationTrainer maakt gebruik van verschillende optionele parameters:
-
FeatureColumnNameis de kolom die wordt gebruikt als invoer voor het model. -
LabelColumnNameis de kolom voor de waarde die moet worden voorspeld. -
ValidationSetis deIDataViewdie de validatiegegevens bevat. -
Archdefinieert welke van de vooraf getrainde modelarchitecturen moeten worden gebruikt. In deze zelfstudie wordt gebruikgemaakt van de 101-laagvariant van het ResNetv2-model. -
MetricsCallbackverbindt een functie om de voortgang tijdens de training bij te houden. -
TestOnTrainSetgeeft aan dat het model de prestaties moet meten op basis van de trainingsset wanneer er geen validatieset aanwezig is. -
ReuseTrainSetBottleneckCachedValuesgeeft aan of het model de waarden in de cache van de knelpuntfase in volgende uitvoeringen moet gebruiken. De knelpuntfase is een eenmalige passthrough-berekening die de eerste keer dat deze wordt uitgevoerd, rekenintensief is. Als de trainingsgegevens niet veranderen en u wilt experimenteren met een ander aantal tijdvakken of batchgrootten, vermindert het gebruik van de waarden in de cache aanzienlijk de hoeveelheid tijd die nodig is om een model te trainen. -
ReuseValidationSetBottleneckCachedValuesis vergelijkbaar metReuseTrainSetBottleneckCachedValuesalleen dat in dit geval voor de validatiegegevensset.
-
Definieert de
EstimatorChaintrainingspijplijn die bestaat uit zowel demapLabelEstimatorals de ImageClassificationTrainer.Gebruikt de
Fitmethode om het model te trainen.
Het model gebruiken
Nu u het model hebt getraind, is het tijd om het te gebruiken om afbeeldingen te classificeren.
Maak een nieuwe hulpprogrammamethode die wordt aangeroepen OutputPrediction om voorspellingsgegevens weer te geven in de console.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Een enkele afbeelding classificeren
Maak een methode die wordt aangeroepen
ClassifySingleImageom één afbeeldingsvoorspelling te maken en uit te voeren.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }De methode
ClassifySingleImage:- Hiermee maakt u een
PredictionEnginein deClassifySingleImagemethode. DePredictionEngineis een handige API waarmee u gegevens kunt doorgeven en vervolgens een voorspelling kunt uitvoeren voor één exemplaar van gegevens. - Als u toegang wilt krijgen tot één
ModelInputexemplaar, converteert u dedataIDataViewnaar eenIEnumerablemethode met behulp van deCreateEnumerablemethode en haalt u vervolgens de eerste observatie op. - Hiermee wordt de
Predictmethode gebruikt om de afbeelding te classificeren. - De voorspelling wordt naar de console gestuurd met de
OutputPrediction-methode.
- Hiermee maakt u een
Aanroepen
ClassifySingleImagenadat u deFitmethode hebt aangeroepen met behulp van de testset met afbeeldingen.ClassifySingleImage(mlContext, testSet, trainedModel);
Meerdere afbeeldingen classificeren
Maak een methode die wordt aangeroepen
ClassifyImagesom meerdere voorspellingen voor afbeeldingen te maken en uit te voeren.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }De methode
ClassifyImages:- Hiermee maakt u een
IDataViewdat de voorspellingen bevat door gebruik te maken van deTransform-methode. - Als u de voorspellingen wilt herhalen, converteert u de
predictionDataIDataViewnaar eenIEnumerablemethode met behulp van deCreateEnumerablemethode en haalt u vervolgens de eerste 10 waarnemingen op. - Hiermee worden de oorspronkelijke en voorspelde labels voor de voorspellingen geïtereerd en uitgegeven.
- Hiermee maakt u een
Aanroepen
ClassifyImagesnadat u deClassifySingleImage()methode hebt aangeroepen met behulp van de testset met afbeeldingen.ClassifyImages(mlContext, testSet, trainedModel);
De toepassing uitvoeren
Voer uw console-app uit. De uitvoer moet vergelijkbaar zijn met de volgende uitvoer.
Opmerking
Mogelijk ziet u waarschuwingen of verwerkingsberichten; deze berichten zijn ter verduidelijking uit de volgende resultaten verwijderd. Om het kort te houden, is de uitvoer ingekort.
Bottleneckfase
Er wordt geen waarde afgedrukt voor de naam van de afbeelding, omdat de afbeeldingen worden geladen als zodanig byte[] dat er geen afbeeldingsnaam wordt weergegeven.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Trainingsfase
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Uitvoer van afbeeldingen classificeren
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Na inspectie van de 7001-220.jpg afbeelding kunt u controleren of deze niet is gekraakt, zoals het model heeft voorspeld.

Gefeliciteerd! U hebt nu een Deep Learning-model gebouwd voor het classificeren van afbeeldingen.
Het model verbeteren
Als u niet tevreden bent met de resultaten van het model, kunt u proberen de prestaties te verbeteren door een aantal van de volgende benaderingen uit te proberen:
- Meer gegevens: hoe meer voorbeelden een model leert, hoe beter het presteert. Download de volledige SDNET2018 gegevensset en gebruik deze om te trainen.
- De gegevens uitbreiden: Een veelgebruikte techniek om variëteiten toe te voegen aan de gegevens is het uitbreiden van de gegevens door een afbeelding te maken en verschillende transformaties toe te passen (draaien, spiegelen, verschuiven, bijsnijden). Dit voegt gevarieerdere voorbeelden toe voor het model om van te leren.
- Een langere tijd trainen: hoe langer u traint, hoe meer afgestemd het model zal zijn. Het verhogen van het aantal tijdvakken kan de prestaties van uw model verbeteren.
- Experimenteer met de hyperparameters: naast de parameters die in deze zelfstudie worden gebruikt, kunnen andere parameters worden afgestemd om de prestaties mogelijk te verbeteren. Het wijzigen van de leersnelheid, die de grootte bepaalt van de updates die na elke periode in het model zijn aangebracht, kan de prestaties verbeteren.
- Gebruik een andere modelarchitectuur: afhankelijk van hoe uw gegevens eruit zien, kan het model dat het beste kan leren wat de functies ervan zijn, verschillen. Als u niet tevreden bent over de prestaties van uw model, kunt u proberen de architectuur te wijzigen.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u een aangepast deep learning-model bouwt met behulp van transfer learning, een vooraf getraind TensorFlow-model en de ML.NET Api voor afbeeldingsclassificatie om afbeeldingen van betonoppervlakken te classificeren als gebarsten of ongebroken.
Ga naar de volgende tutorial om meer te leren.
Zie ook
Werk met ons samen op GitHub
De bron voor deze inhoud vindt u op GitHub, waar u ook problemen en pull-aanvragen kunt maken en bekijken. Raadpleeg onze gids voor inzenders voor meer informatie.