Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Fabric Runtime biedt een naadloze integratie met Azure. Het biedt een geavanceerde omgeving voor zowel data engineering- als data science-projecten die gebruikmaken van Apache Spark. Dit artikel bevat een overzicht van de essentiële functies en onderdelen van Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 is een GA-runtimeversie met de volgende onderdelen en upgrades die zijn ontworpen om uw gegevensverwerkingsmogelijkheden te verbeteren:
Apache Spark 3.5
Besturingssysteem: Mariner 2.0
Java: 11
Scala: 2.12.17
Python: 3.11
Delta Lake: 3.2
R: 4.4.1
Aanbeveling
Fabric Runtime 1.3 bevat ondersteuning voor de systeemeigen uitvoeringsengine, die de prestaties aanzienlijk kan verbeteren zonder meer kosten. Als u de systeemeigen uitvoeringsengine voor alle taken en notebooks in uw omgeving wilt inschakelen, gaat u naar uw omgevingsinstellingen, selecteert u Spark-berekening, gaat u naar het tabblad Versnelling en schakelt u systeemeigen uitvoeringsengine inschakelen in. Nadat u deze instelling hebt opgeslagen en gepubliceerd, wordt deze instelling toegepast in de omgeving, zodat alle nieuwe taken en notebooks automatisch overnemen en profiteren van de verbeterde prestatiemogelijkheden.
Runtime 1.3 integreren
Opmerking
Zie Apache Spark Runtimes in Fabric voor informatie over alle beschikbare Fabric-runtimes en hun huidige status.
Gebruik de volgende instructies om runtime 1.3 te integreren in uw werkruimte en de nieuwe functies te gebruiken:
Navigeer naar het tabblad Werkruimte-instellingen in uw Fabric-werkruimte.
Ga naar het tabblad Data-engineer/Wetenschap en selecteer Spark-instellingen.
Selecteer het tabblad Omgeving.
De vervolgkeuzelijst uitvouwen onder Runtimeversies.
Selecteer 1.3 (Spark 3.5, Delta 3.2) en sla uw wijzigingen op. Met deze actie wordt 1.3 ingesteld als de standaardruntime voor uw werkruimte.
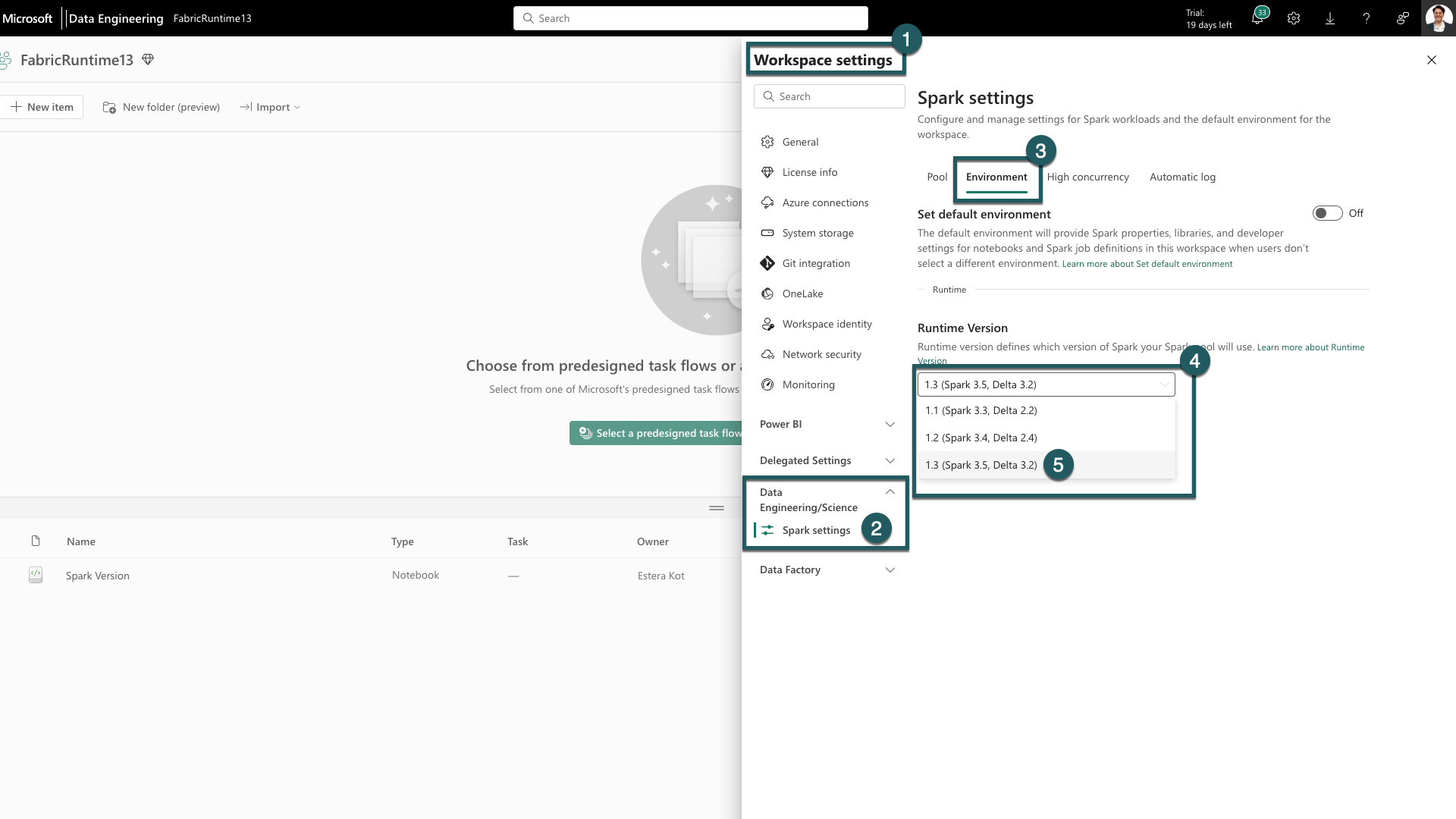

U kunt nu aan de slag gaan met de nieuwste verbeteringen en functionaliteiten die zijn geïntroduceerd in Fabric Runtime 1.3 (Spark 3.5 en Delta Lake 3.2).
Meer informatie over Apache Spark 3.5
Apache Spark 3.5.0 is de zesde versie in de 3.x-serie. Deze versie is een product van uitgebreide samenwerking binnen de opensource-community, die meer dan 1300 problemen aanpakt, zoals vastgelegd in Jira.
In deze versie is er een upgrade in compatibiliteit voor gestructureerd streamen. Daarnaast wordt in deze release de functionaliteit in PySpark en SQL uitgebreid. Er worden functies toegevoegd, zoals de SQL-id-component, benoemde argumenten in SQL-functieaanroepen en het opnemen van SQL-functies voor geschatte aggregaties van HyperLogLog.
Andere nieuwe mogelijkheden zijn ook door de gebruiker gedefinieerde python-tabelfuncties, de vereenvoudiging van gedistribueerde training via DeepSpeed en nieuwe gestructureerde streamingmogelijkheden, zoals watermerkdoorgifte en de bewerking dropDuplicatesWithinWatermark .
U kunt de volledige lijst en gedetailleerde wijzigingen hier bekijken: Spark Release 3.5.0.
Meer informatie over Delta Spark
Delta Lake 3.2 markeert een collectieve toezegging om Delta Lake interoperabel te maken tussen verschillende indelingen, gemakkelijker te werken en beter te presteren. Delta Spark 3.2 is gebouwd op Apache Spark™ 3.5. De naam van het Delta Spark-maven-artefact wordt gewijzigd van delta-core in delta-spark.
U kunt hier de volledige lijst en gedetailleerde wijzigingen controleren: https://docs.delta.io/index.html.
Onderdelen en bibliotheken
Voor actuele informatie, een gedetailleerde lijst met wijzigingen en specifieke release-opmerkingen voor Fabric-runtimes controleer en abonneer je op Spark Runtime-releases en -updates.
Opmerking
EventHubConnector is afgeschaft in Fabric Runtime 1.3 (Spark 3.5) en wordt verwijderd uit toekomstige Fabric Runtime-versies. Klanten worden aangemoedigd om in plaats daarvan Kafka Spark Connector te gebruiken, omdat Event Hubs al compatibel is met Kafka. Meer informatie over het gebruik van Kafka Spark Connector met Event Hubs vindt u hier: Event Hubs Kafka Spark-zelfstudie
Gerelateerde inhoud
- Meer informatie over Apache Spark Runtimes in Fabric - Overzicht, Versiebeheer, Ondersteuning voor meerdere runtimes en het upgraden van Delta Lake Protocol
- Spark Core-migratiehandleiding
- Migratiehandleidingen voor SQL, Gegevenssets en DataFrame
- Migratiehandleiding voor gestructureerd streamen
- Migratiehandleiding voor MLlib (Machine Learning)
- Migratiehandleiding voor PySpark (Python op Spark)
- Migratiehandleiding voor SparkR (R in Spark)