Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
U kunt de gegevens verkennen die zijn gerepliceerd vanuit uw gespiegelde database met Spark-query's in notebooks.
Notebooks zijn een krachtig code-item voor het ontwikkelen van Apache Spark-taken en machine learning-experimenten op uw gegevens. U kunt notebooks in Fabric Lakehouse gebruiken om uw gespiegelde tabellen te verkennen.
Vereiste voorwaarden
- Voltooi de zelfstudie om een gespiegelde database te maken op basis van uw brondatabase.
- Zelfstudie: Een gespiegelde Microsoft Fabric-database configureren voor Azure Cosmos DB
- Zelfstudie: Gespiegelde Databases van Microsoft Fabric configureren vanuit Azure Databricks
- Zelfstudie: Gespiegelde Databases van Microsoft Fabric configureren vanuit Azure SQL Database
- Zelfstudie: Gespiegelde Databases van Microsoft Fabric configureren vanuit Azure SQL Managed Instance
- Zelfstudie: Gespiegelde Microsoft Fabric-databases configureren vanuit Snowflake
- Zelfstudie: Gespiegelde Databases van Microsoft Fabric configureren vanuit SQL Server
- Zelfstudie: Een geopende gespiegelde database maken
Een snelkoppeling maken
U moet eerst een snelkoppeling maken op basis van uw gespiegelde tabellen in Lakehouse en vervolgens notebooks bouwen met Spark-query's in uw Lakehouse.
Open Data Engineering in de Fabric-portal.
Als u nog geen Lakehouse hebt gemaakt, selecteert u Lakehouse en maakt u een nieuw Lakehouse door deze een naam te geven.
Selecteer Gegevens ophalen ->Nieuwe snelkoppeling.
Selecteer Microsoft OneLake.
U kunt al uw gespiegelde databases zien in de werkruimte Fabric.
Selecteer de gespiegelde database die u als snelkoppeling wilt toevoegen aan uw Lakehouse.
Selecteer de gewenste tabellen in de gespiegelde database.
Selecteer Volgende en vervolgens Maken.
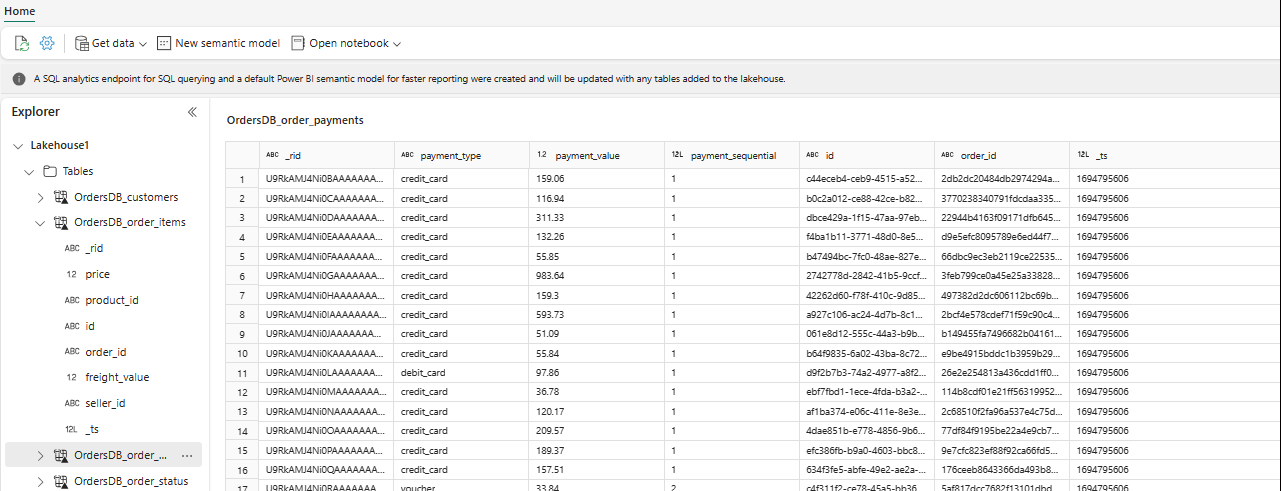
In Explorer kunt u nu geselecteerde tabelgegevens in uw Lakehouse bekijken.
Aanbeveling
U kunt andere gegevens rechtstreeks toevoegen in Lakehouse of snelkoppelingen zoals S3, ADLS Gen2 gebruiken. U kunt naar het SQL-analyse-eindpunt van Lakehouse navigeren en de gegevens naadloos samenvoegen in al deze bronnen met gespiegelde gegevens.
Als u deze gegevens in Spark wilt verkennen, selecteert u de
...puntjes naast een tabel. Selecteer Nieuw notitieblok of bestaand notitieblok om de analyse te starten.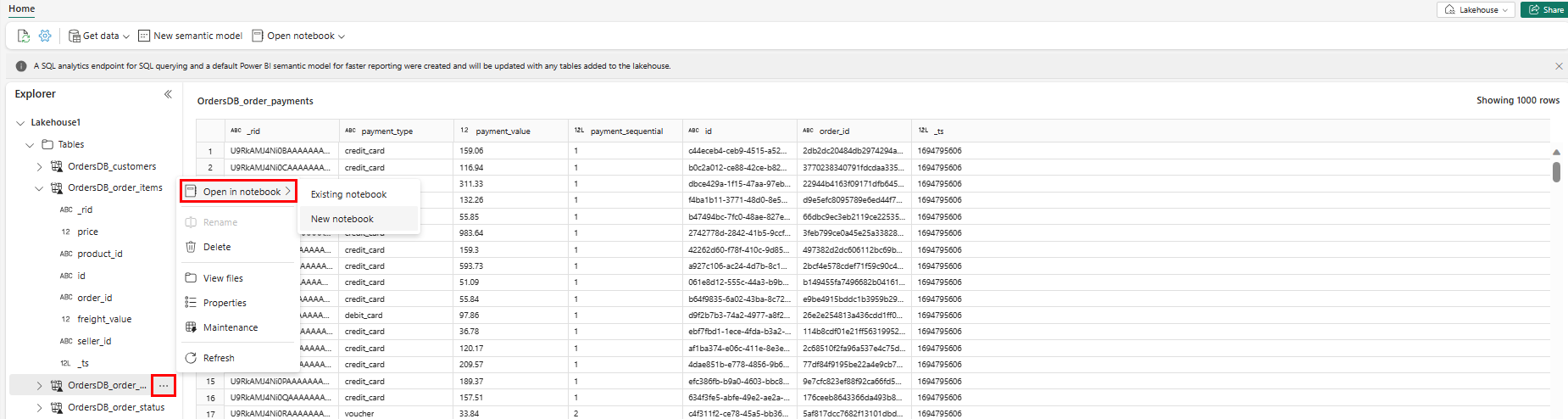
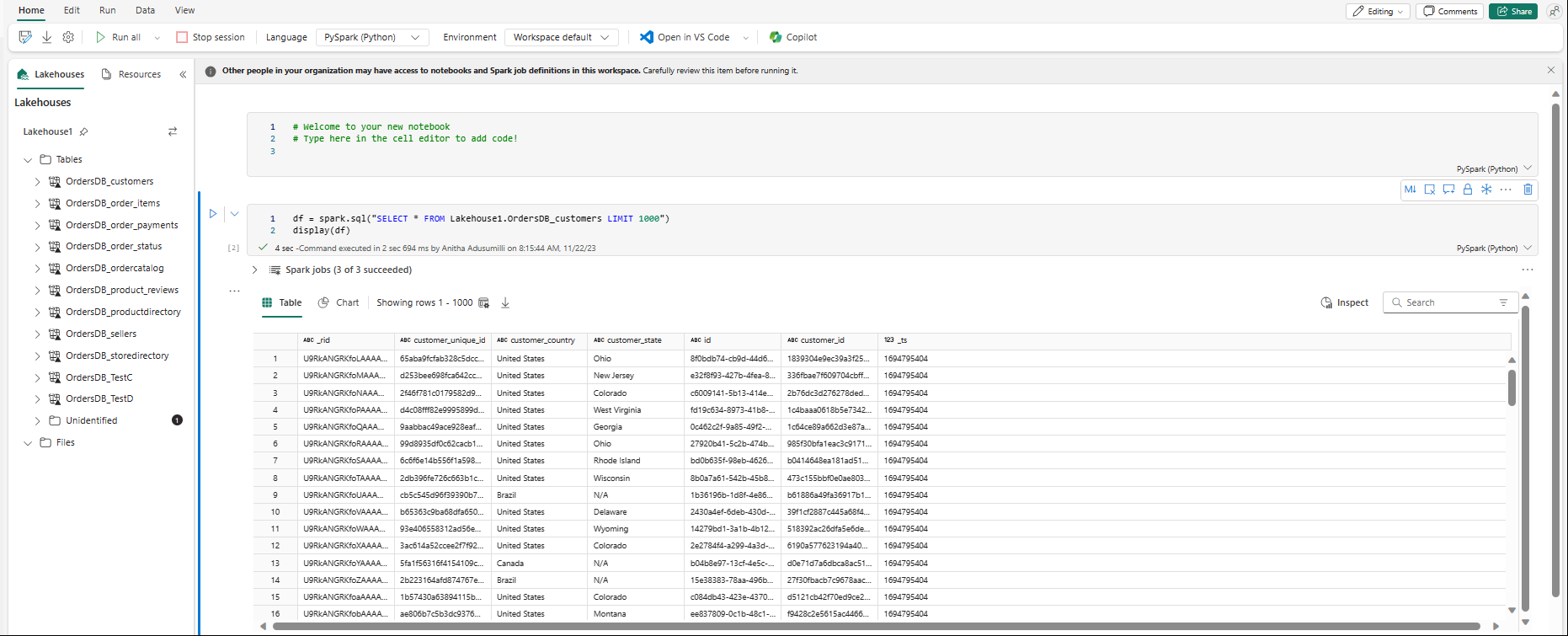
Het notebook wordt automatisch geopend en het gegevensframe wordt geladen met een
SELECT ... LIMIT 1000Spark SQL-query.- Het laden van nieuwe notebooks kan maximaal twee minuten duren. U kunt deze vertraging voorkomen door een bestaand notitieblok met een actieve sessie te gebruiken.
- Het laden van nieuwe notebooks kan maximaal twee minuten duren. U kunt deze vertraging voorkomen door een bestaand notitieblok met een actieve sessie te gebruiken.


