Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Spiegeling in Fabric biedt een eenvoudige manier om complexe ETL-processen (Extract, Transform, Load) te voorkomen en naadloos uw bestaande Google BigQuery-magazijngegevens te integreren met de rest van uw gegevens in Fabric. U kunt uw Google BigQuery-gegevens continu rechtstreeks repliceren naar OneLake van Fabric. Eenmaal in Fabric kunt u profiteren van krachtige mogelijkheden voor business intelligence, AI, data engineering, data science en het delen van gegevens.
Voor een zelfstudie over het configureren van uw Google BigQuery-database voor spiegeling in Fabric raadpleegt u Zelfstudie: Gespiegelde Databases van Microsoft Fabric configureren vanuit Google BigQuery.
Belangrijk
Spiegeling voor Google BigQuery is nu in proefversie. Productieworkloads worden niet ondersteund tijdens de preview-versie.
Waarom spiegeling gebruiken in Fabric?
Spiegelen in Microsoft Fabric verwijdert de complexiteit van het samenvoegen van hulpprogramma's van verschillende providers. U hoeft uw gegevens niet te migreren. Maak vrijwel realtime verbinding met uw Google BigQuery-gegevens om de reeks aan analysehulpprogramma's van Fabric te gebruiken. Fabric werkt ook naadloos samen met Microsoft-producten, Google BigQuery en een breed scala aan technologieën die ondersteuning bieden voor de opensource Delta Lake-tabelindeling.
Welke analyse-ervaringen zijn ingebouwd?
Met spiegeling worden twee items gemaakt in uw Fabric-werkruimte:
- Het gespiegelde database-item. Spiegeling beheert de replicatie van gegevens in OneLake en conversie naar Parquet, in een indeling die gereed is voor analyse. Spiegeling maakt downstreamscenario's mogelijk, zoals data engineering, data science en meer. Gespiegelde databases verschillen van eindpuntitems voor magazijn- en SQL-analyse.
- Een SQL Analytics-eindpunt
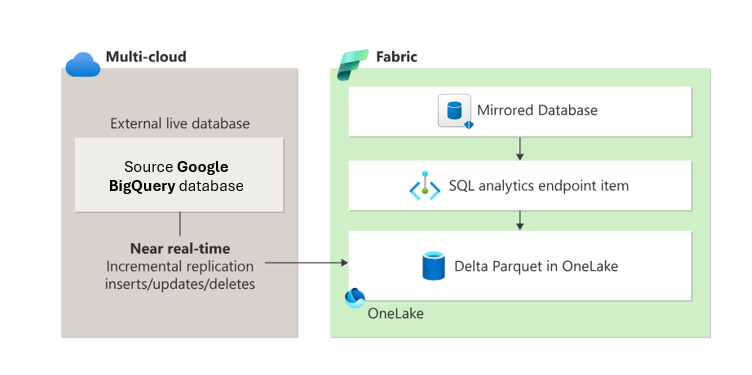
Vanuit elke gespiegelde database biedt een SQL-analyse-eindpunt een alleen-lezen analyse-ervaring boven op de Delta-tabellen die zijn gemaakt tijdens mirroring. Dit eindpunt ondersteunt T-SQL-syntaxis voor het definiëren en opvragen van gegevensobjecten, maar staat geen directe gegevenswijzigingen toe, omdat de gegevens alleen-lezen zijn.
Met het SQL Analytics-eindpunt kunt u het volgende doen:
- Blader door tabellen die verwijzen naar uw Delta Lake-gegevens die zijn gespiegeld vanuit BigQuery.
- Bouw query's en weergaven zonder code en verken gegevens visueel, geen SQL vereist.
- Maak SQL-weergaven, inline tabelwaardefuncties (TVF's) en opgeslagen procedures om bedrijfslogica toe te voegen met behulp van T-SQL.
- Machtigingen voor objecten instellen en beheren.
- Query's uitvoeren op gegevens in andere magazijnen en Lakehouses binnen dezelfde werkruimte.
Naast de SQL-queryeditor is er een breed ecosysteem van hulpprogramma's waarmee u query's kunt uitvoeren op het SQL Analytics-eindpunt, waaronder SQL Server Management Studio (SSMS), de mssql-extensie met Visual Studio Code en zelfs GitHub Copilot.
Beveiligingsoverwegingen
Er zijn specifieke gebruikersmachtigingen voor het inschakelen van Fabric Mirroring.
Fabric biedt ook functies voor gegevensbeveiliging voor het beheren van toegang binnen Microsoft Fabric. Zie de documentatie over de functies voor gegevensbescherming voor meer informatie.
Gespiegelde kostenoverwegingen voor BigQuery
Het Fabric-rekenproces dat wordt gebruikt om uw gegevens te repliceren naar Fabric OneLake is gratis. De opslagkosten voor spiegelen zijn gratis tot een limiet op basis van capaciteit. De berekening voor het uitvoeren van query's op gegevens met behulp van SQL, Power BI of Spark wordt regelmatig in rekening gebracht.
Fabric brengt geen kosten in rekening voor inkomend netwerkgegevens in OneLake voor spiegeling.
Er zijn Google BigQuery-reken- en cloudquerykosten wanneer gegevens worden gespiegeld: BigQuery Change Data Capture (CDC) maakt gebruik van BigQuery-berekening voor rijaanpassing, Storage Write-API voor gegevensopname, BigQuery-opslag voor gegevensopslag waarvoor allemaal kosten in rekening worden gebracht.
Zie de prijsinformatie voor meer informatie over de kosten voor het spiegelen van Google BigQuery.