Medal medalhouse-architectuur implementeren in Microsoft Fabric
In dit artikel maakt u kennis met medalsight lake-architectuur en wordt beschreven hoe u een lakehouse in Microsoft Fabric kunt implementeren. Het is gericht op meerdere doelgroepen:
- Data engineers: technisch personeel dat infrastructuren en systemen ontwerpt, bouwt en onderhoudt waarmee hun organisatie grote hoeveelheden gegevens kan verzamelen, opslaan, verwerken en analyseren.
- Center of Excellence, IT en BI-team: de teams die verantwoordelijk zijn voor het toezicht op analyses in de hele organisatie.
- Infrastructuurbeheerders: de beheerders die verantwoordelijk zijn voor het toezicht op Fabric in de organisatie.
De medal organizations lakehouse architectuur, ook wel bekend als medalsight-architectuur, is een ontwerppatroon dat door organisaties wordt gebruikt om gegevens in een lakehouse logisch te organiseren. Het is de aanbevolen ontwerpbenadering voor Fabric.
De medaillestructuur bestaat uit drie verschillende lagen( of zones). Elke laag geeft de kwaliteit aan van gegevens die zijn opgeslagen in lakehouse, met hogere niveaus die een hogere kwaliteit vertegenwoordigen. Deze benadering met meerdere lagen helpt u bij het bouwen van één bron van waarheid voor zakelijke gegevensproducten.
Belangrijk is dat de medalbytes-architectuur de ACID-set eigenschappen (Atomiciteit, Consistentie, Isolatie en Duurzaamheid) garandeert wanneer gegevens door de lagen worden uitgevoerd. Vanaf onbewerkte gegevens worden met een reeks validaties en transformaties gegevens voorbereid die zijn geoptimaliseerd voor efficiënte analyses. Er zijn drie medaillestadia: brons (onbewerkt), zilver (gevalideerd) en goud (verrijkt).
Zie Wat is de medaille-lakehousearchitectuur voor meer informatie.
OneLake en Lakehouse in Fabric
De basis van een modern datawarehouse is een data lake. Microsoft OneLake, één, geïntegreerde, logische data lake voor uw hele organisatie. Het wordt automatisch ingericht met elke Fabric-tenant en is ontworpen als één locatie voor al uw analysegegevens.
U kunt OneLake gebruiken om het volgende te doen:
- Verwijder silo's en verminder beheerinspanningen. Alle organisatiegegevens worden opgeslagen, beheerd en beveiligd binnen één Data Lake-resource. Omdat OneLake is ingericht met uw Fabric-tenant, zijn er geen resources meer om in te richten of te beheren.
- Verminder gegevensverplaatsing en duplicatie. Het doel van OneLake is om slechts één kopie van gegevens op te slaan. Minder kopieën van gegevens leiden tot minder processen voor gegevensverplaatsing en dat leidt tot efficiëntieverbeteringen en vermindering van de complexiteit. Indien nodig kunt u een snelkoppeling maken om te verwijzen naar gegevens die zijn opgeslagen op andere locaties, in plaats van deze te kopiëren naar OneLake.
- Gebruik met meerdere analytische engines. De gegevens in OneLake worden opgeslagen in een open indeling. Op die manier kunnen de gegevens worden opgevraagd door verschillende analytische engines, waaronder Analysis Services (gebruikt door Power BI), T-SQL en Apache Spark. Andere niet-Fabric-toepassingen kunnen ook API's en SDK's gebruiken voor toegang tot OneLake .
Zie OneLake, oneDrive voor gegevens voor meer informatie.
Als u gegevens wilt opslaan in OneLake, maakt u een lakehouse in Fabric. Een lakehouse is een platform voor gegevensarchitectuur voor het opslaan, beheren en analyseren van gestructureerde en ongestructureerde gegevens op één locatie. Het kan eenvoudig worden geschaald naar grote gegevensvolumes van alle bestandstypen en grootten, en omdat deze op één locatie worden opgeslagen, wordt deze eenvoudig gedeeld en opnieuw gebruikt in de hele organisatie.
Elk lakehouse heeft een ingebouwd SQL-analyse-eindpunt dat mogelijkheden voor datawarehouse ontgrendelt zonder gegevens te hoeven verplaatsen. Dit betekent dat u query's kunt uitvoeren op uw gegevens in lakehouse met behulp van SQL-query's en zonder speciale instellingen.
Zie Wat is een lakehouse in Microsoft Fabric? voor meer informatie.
Tabellen en bestanden
Wanneer u een Lakehouse in Fabric maakt, worden twee fysieke opslaglocaties automatisch ingericht voor tabellen en bestanden.
- Tabellen is een beheerd gebied voor het hosten van tabellen van alle indelingen in Apache Spark (CSV, Parquet of Delta). Alle tabellen, die automatisch of expliciet worden gemaakt, worden herkend als tabellen in het lakehouse. Delta-tabellen, die Parquet-gegevensbestanden zijn met een transactielogboek op basis van bestanden, worden ook herkend als tabellen.
- Bestanden zijn een onbeheerd gebied voor het opslaan van gegevens in elke bestandsindeling. Delta-bestanden die in dit gebied zijn opgeslagen, worden niet automatisch herkend als tabellen. Als u een tabel wilt maken via een Delta Lake-map in het onbeheerde gebied, moet u expliciet een snelkoppeling of een externe tabel maken met een locatie die verwijst naar de onbeheerde map die de Delta Lake-bestanden in Apache Spark bevat.
Het belangrijkste onderscheid tussen het beheerde gebied (tabellen) en het onbeheerde gebied (bestanden) is het automatische detectie- en registratieproces voor tabellen. Dit proces wordt alleen uitgevoerd op elke map die in het beheerde gebied is gemaakt, maar niet in het onbeheerde gebied.
In Microsoft Fabric biedt de Lakehouse Explorer een uniforme grafische weergave van het hele Lakehouse, zodat gebruikers hun gegevens kunnen navigeren, openen en bijwerken.
Zie Automatische tabeldetectie en -registratie voor meer informatie over automatische tabeldetectie.
Delta Lake-opslag
Delta Lake is een geoptimaliseerde opslaglaag die de basis biedt voor het opslaan van gegevens en tabellen. Het ondersteunt ACID-transacties voor big data-workloads en daarom is het de standaardopslagindeling in een Fabric Lakehouse.
Belangrijk is dat Delta Lake betrouwbaarheid, beveiliging en prestaties levert in lakehouse voor zowel streaming- als batchbewerkingen. Intern worden gegevens opgeslagen in de Parquet-bestandsindeling, maar het onderhoudt ook transactielogboeken en statistieken die functies en prestatieverbetering bieden ten opzichte van de standaard Parquet-indeling.
Delta Lake-indeling via algemene bestandsindelingen biedt de volgende belangrijke voordelen.
- Ondersteuning voor ACID-eigenschappen en met name duurzaamheid om beschadiging van gegevens te voorkomen.
- Snellere leesquery's.
- Verbeterde versheid van gegevens.
- Ondersteuning voor zowel batch- als streamingworkloads.
- Ondersteuning voor het terugdraaien van gegevens met behulp van Delta Lake time travel.
- Verbeterde naleving en controle van regelgeving met behulp van de delta lake-tabelgeschiedenis.
Fabric standaardiseert de opslagbestandsindeling met Delta Lake en standaard maakt elke workload-engine in Fabric Delta-tabellen wanneer u gegevens naar een nieuwe tabel schrijft. Zie De tabellen Lakehouse en Delta Lake voor meer informatie.
Medal medal medal architecture in Fabric
Het doel van de medalsight-architectuur is om de structuur en kwaliteit van gegevens stapsgewijs te verbeteren naarmate deze zich door elke fase bevindt.
De medaillestructuur bestaat uit drie verschillende lagen (of zones).
- Brons: Ook wel bekend als de onbewerkte zone, slaat deze eerste laag brongegevens op in de oorspronkelijke indeling. De gegevens in deze laag zijn doorgaans alleen toevoegen en onveranderbaar.
- Zilver: Ook wel bekend als de verrijkte zone, slaat deze laag gegevens op die afkomstig zijn uit de bronlaag. De onbewerkte gegevens zijn opgeschoond en gestandaardiseerd en zijn nu gestructureerd als tabellen (rijen en kolommen). Het kan ook worden geïntegreerd met andere gegevens om een bedrijfsweergave te bieden van alle bedrijfsentiteiten, zoals klant, product en andere.
- Gold: Ook wel bekend als de gecureerde zone, slaat deze laatste laag gegevens op die afkomstig zijn van de zilveren laag. De gegevens worden verfijnd om te voldoen aan specifieke bedrijfs- en analysevereisten voor downstream. Tabellen voldoen doorgaans aan het ontwerp van stervormige schema's, die ondersteuning bieden voor de ontwikkeling van gegevensmodellen die zijn geoptimaliseerd voor prestaties en bruikbaarheid.
Belangrijk
Omdat een Fabric Lakehouse één zone vertegenwoordigt, maakt u één lakehouse voor elk van de drie zones.
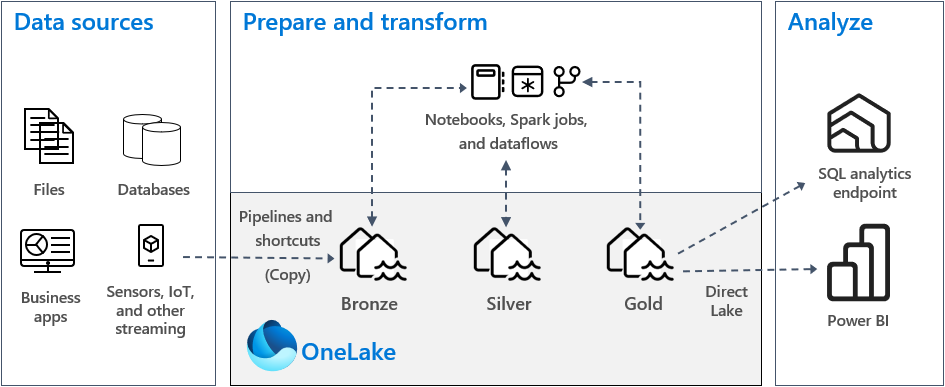
In een typische implementatie van de medalsight-architectuur in Fabric slaat de bronszone de gegevens op in dezelfde indeling als de gegevensbron. Wanneer de gegevensbron een relationele database is, zijn Delta-tabellen een goede keuze. De zilver- en goudzones bevatten Delta-tabellen.
Tip
Als u wilt weten hoe u een lakehouse maakt, voert u de end-to-end-scenariozelfstudie van Lakehouse uit.
Richtlijnen voor Fabric Lakehouse
In deze sectie vindt u richtlijnen met betrekking tot het implementeren van uw Fabric Lakehouse met behulp van de medalsight-architectuur.
Implementatiemodel
Voor het implementeren van de medalsight-architectuur in Fabric kunt u lakehouses (één voor elke zone), een datawarehouse of een combinatie van beide gebruiken. Uw beslissing moet zijn gebaseerd op uw voorkeur en de expertise van uw team. Houd er rekening mee dat Fabric u flexibiliteit biedt: u kunt verschillende analyse-engines gebruiken die werken aan de ene kopie van uw gegevens in OneLake.
Hier volgen twee patronen die u moet overwegen.
- Patroon 1: Maak elke zone als lakehouse. In dit geval hebben zakelijke gebruikers toegang tot gegevens met behulp van het SQL-analyse-eindpunt.
- Patroon 2: Maak de bronzen en zilveren zones als lakehouses en de gouden zone als datawarehouse. In dit geval hebben zakelijke gebruikers toegang tot gegevens met behulp van het datawarehouse-eindpunt.
Hoewel u alle lakehouses in één Fabric-werkruimte kunt maken, raden we u aan om elk lakehouse in een eigen, afzonderlijke Fabric-werkruimte te maken. Deze aanpak biedt u meer controle en betere governance op zoneniveau.
Voor de bronszone raden we u aan om de gegevens in de oorspronkelijke indeling op te slaan of Parquet of Delta Lake te gebruiken. Bewaar de gegevens indien mogelijk in de oorspronkelijke indeling. Als de brongegevens afkomstig zijn van OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 of Google, maakt u een snelkoppeling in de bronszone in plaats van de gegevens over te kopiëren.
Voor de zilver- en goudzones raden we u aan Delta-tabellen te gebruiken vanwege de extra mogelijkheden en prestatieverbeteringen die ze bieden. Fabric standaardiseert de Delta Lake-indeling en standaard schrijft elke engine in Fabric gegevens in deze indeling. Verder maken deze engines gebruik van V-Order schrijftijdoptimalisatie naar de Parquet-bestandsindeling. Deze optimalisatie maakt extreem snelle leesbewerkingen mogelijk door Fabric-rekenengines, zoals Power BI, SQL, Apache Spark en andere. Zie Optimalisatie van Delta Lake-tabellen en V-Order voor meer informatie.
Tot slot hebben veel organisaties tegenwoordig te maken met een enorme groei in gegevensvolumes, samen met een toenemende behoefte aan het organiseren en beheren van die gegevens op een logische manier, terwijl het efficiënter en efficiënter gebruik en governance wordt vergemakkelijkt. Dit kan ertoe leiden dat u met governance een gedecentraliseerde of federatieve gegevensorganisatie tot stand brengt en beheert.
Om aan dit doel te voldoen, kunt u overwegen een data mesh-architectuur te implementeren. Data mesh is een architectuurpatroon dat zich richt op het maken van gegevensdomeinen die gegevens als product aanbieden.
U kunt een data mesh-architectuur maken voor uw gegevensomgeving in Fabric door gegevensdomeinen te maken. U kunt domeinen maken die zijn toegewezen aan uw bedrijfsdomeinen, bijvoorbeeld marketing, verkoop, voorraad, human resources en andere. Vervolgens kunt u de medalsight-architectuur implementeren door binnen elk van uw domeinen gegevenszones in te stellen.
Zie Domeinen voor meer informatie over domeinen.
Inzicht in gegevensopslag in Delta-tabellen
In deze sectie worden andere richtlijnen behandeld met betrekking tot het implementeren van een medal medal lakehouse-architectuur in Fabric.
Bestandsgrootte
Over het algemeen presteert een big data-platform beter wanneer het een klein aantal grote bestanden heeft in plaats van een groot aantal kleine bestanden. Dat komt doordat prestatievermindering optreedt wanneer de berekeningsengine veel metagegevens en bestandsbewerkingen moet beheren. Voor betere queryprestaties raden we u aan om te streven naar gegevensbestanden die ongeveer 1 GB groot zijn.
Delta Lake heeft een functie genaamd voorspellende optimalisatie. Met voorspellende optimalisatie hoeft u geen onderhoudsbewerkingen voor Delta-tabellen handmatig te beheren. Wanneer deze functie is ingeschakeld, identificeert Delta Lake automatisch tabellen die baat hebben bij onderhoudsbewerkingen en optimaliseert ze vervolgens hun opslag. Het kan transparant veel kleinere bestanden samenvoegen tot grote bestanden, en zonder enige invloed op andere lezers en schrijvers van de gegevens. Hoewel deze functie deel moet uitmaken van uw operationele uitmuntendheid en uw werkzaamheden voor gegevensvoorbereiding, heeft Fabric de mogelijkheid om deze gegevensbestanden te optimaliseren tijdens het schrijven van gegevens. Zie Voorspellende optimalisatie voor Delta Lake voor meer informatie.
Historische retentie
Delta Lake onderhoudt standaard een geschiedenis van alle wijzigingen die zijn aangebracht. Dit betekent dat de grootte van historische metagegevens in de loop van de tijd toeneemt. Op basis van uw zakelijke vereisten moet u ervoor zorgen dat historische gegevens slechts gedurende een bepaalde periode worden bewaard om de opslagkosten te verlagen. Overweeg om historische gegevens voor alleen de afgelopen maand of een andere geschikte periode te bewaren.
U kunt oudere historische gegevens uit een Delta-tabel verwijderen met behulp van de opdracht VACUUM. Houd er echter rekening mee dat u historische gegevens in de afgelopen zeven dagen standaard niet kunt verwijderen. Dit is om de consistentie in gegevens te behouden. Het standaardaantal dagen wordt bepaald door de tabeleigenschap delta.deletedFileRetentionDuration = "interval <interval>". Het bepaalt de periode dat een bestand moet worden verwijderd voordat het kan worden beschouwd als een kandidaat voor een vacuümbewerking.
Tabelpartities
Wanneer u gegevens in elke zone opslaat, wordt u aangeraden waar van toepassing een gepartitioneerde mapstructuur te gebruiken. Deze techniek helpt bij het verbeteren van de beheerbaarheid van gegevens en queryprestaties. Over het algemeen resulteert gepartitioneerde gegevens in een mapstructuur in een snellere zoekopdracht naar specifieke gegevensvermeldingen dankzij partitionering/verwijdering.
Normaal gesproken voegt u gegevens toe aan uw doeltabel wanneer er nieuwe gegevens binnenkomen. In sommige gevallen kunt u echter gegevens samenvoegen omdat u bestaande gegevens tegelijk moet bijwerken. In dat geval kunt u een upsert-bewerking uitvoeren met behulp van de opdracht MERGE. Wanneer de doeltabel is gepartitioneerd, moet u een partitiefilter gebruiken om de bewerking te versnellen. Op die manier kan de engine partities elimineren die niet hoeven te worden bijgewerkt.
Toegang tot gegevens
Ten slotte moet u plannen en beheren wie toegang nodig heeft tot specifieke gegevens in het lakehouse. U moet ook de verschillende transactiepatronen begrijpen die ze gaan gebruiken tijdens het openen van deze gegevens. Vervolgens kunt u het juiste tabelpartitioneringsschema definiëren en gegevenskolommen definiëren met Delta Lake Z-orderindexen.
Gerelateerde inhoud
Zie de volgende resources voor meer informatie over het implementeren van een Fabric Lakehouse.
- Zelfstudie: End-to-End-scenario van Lakehouse
- Lakehouse- en Delta Lake-tabellen
- Beslissingshandleiding voor Microsoft Fabric: een gegevensarchief kiezen
- Optimalisatie van Delta Lake-tabellen en V-order
- De noodzaak voor het optimaliseren van schrijfbewerkingen in Apache Spark
- Vragen? Probeer de Fabric-community te vragen.
- Suggesties? Ideeën bijdragen om Fabric te verbeteren.
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor