Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Semantische modellen in een Premium-capaciteit waarvoor het XMLA-eindpunt is ingeschakeld voor lees-/schrijfbewerkingen, bieden geavanceerdere vernieuwing, partitiebeheer en alleen metagegevensimplementaties via hulpprogramma's, scripts en API-ondersteuning. Bovendien zijn vernieuwingsbewerkingen via het XMLA-eindpunt niet beperkt tot 48 vernieuwingen per dag en wordt de geplande vernieuwingstijdlimiet niet opgelegd.
Partitions
Semantische modeltabelpartities zijn niet zichtbaar en kunnen niet worden beheerd met behulp van Power BI Desktop of de Power BI-service. Voor modellen in een werkruimte die is toegewezen aan een Premium-capaciteit, kunnen partities worden beheerd via het XMLA-eindpunt. U kunt hulpprogramma's zoals SQL Server Management Studio (SSMS) of de opensource Tabular Editor gebruiken om partities te beheren via scripts met TMSL (Tabular Model Scripting Language) en programmatisch met het Tabular Object Model (TOM).
Wanneer u voor het eerst een model publiceert naar de Power BI-service, heeft elke tabel in het nieuwe model één partitie. Voor tabellen zonder beleid voor incrementeel vernieuwen bevat die ene partitie alle rijen met gegevens voor die tabel, tenzij filters worden toegepast. Voor tabellen met een beleid voor incrementeel vernieuwen bestaat die ene eerste partitie alleen omdat power BI het beleid nog niet heeft toegepast. U configureert de eerste partitie in Power BI Desktop wanneer u het datum-/tijdsbereikfilter voor uw tabel definieert op basis van de RangeStart parameters en RangeEnd eventuele andere filters die worden toegepast in de Power Query-editor. Deze eerste partitie bevat alleen de rijen met gegevens die voldoen aan uw filtercriteria.
Wanneer u de eerste vernieuwingsbewerking uitvoert, worden alle rijen in tabellen zonder incrementeel vernieuwingsbeleid vernieuwd in de standaardpartitie van die tabel. Voor tabellen met een beleid voor incrementeel vernieuwen worden automatisch vernieuwings- en historische partities gemaakt en worden er rijen in geladen op basis van de datum/tijd voor elke rij. Als het beleid voor incrementeel vernieuwen het ophalen van gegevens in realtime omvat, voegt Power BI ook een DirectQuery-partitie toe aan de tabel.
Belangrijk
Wanneer u incrementele verversing gebruikt met realtime gegevens (hybride modus), moeten tabellen die zijn gerelateerd aan de hybride tabel Dual storage mode gebruiken om prestatieverlies te voorkomen. Bovendien kan het cacheren van visuals live-updates doen vertragen totdat visuals de gegevens heropvragen. Zie Problemen met incrementeel vernieuwen en realtimegegevens oplossen voor meer informatie.
Deze eerste vernieuwingsbewerking kan enige tijd duren, afhankelijk van de hoeveelheid gegevens die uit de gegevensbron moet worden geladen. De complexiteit van het model kan ook een belangrijke factor zijn, omdat vernieuwingsbewerkingen meer verwerking en herberekening moeten uitvoeren. Deze bewerking kan worden opgestart. Zie Time-outs voorkomen bij de eerste volledige vernieuwing voor meer informatie.
Partities worden gemaakt voor en benoemd op periodegranulariteit: jaren, kwartalen, maanden en dagen. De meest recente partities, de vernieuwingspartities , bevatten rijen in de vernieuwingsperiode die u in het beleid opgeeft. Historische partities bevatten rijen per volledige periode tot aan de vernieuwingsperiode. Als realtime is ingeschakeld, worden met een DirectQuery-partitie gegevenswijzigingen opgehaald die zijn opgetreden na de einddatum van de vernieuwingsperiode. Granulariteit voor verversing en historische gegevenspartities is afhankelijk van de verversings- en historische (opslag)perioden die u kiest wanneer u een beleid definieert.
Als de datum van vandaag bijvoorbeeld 2 februari 2021 is en de tabel FactInternetSales in de gegevensbron rijen tot en met vandaag bevat, als ons beleid aangeeft dat realtimewijzigingen moeten worden opgenomen, worden rijen vernieuwd in de laatste vernieuwingsperiode van één dag en worden rijen opgeslagen in de afgelopen drie jaar historische periode. Vervolgens wordt met de eerste vernieuwingsbewerking een DirectQuery-partitie gemaakt voor wijzigingen in de toekomst. Er wordt een nieuwe importpartitie gemaakt voor de rijen van vandaag en er wordt een historische partitie gemaakt voor gisteren, een hele dagperiode, 1 februari 2021. Er wordt een historische partitie gemaakt voor de vorige hele maandperiode (januari 2021). Er wordt een historische partitie gemaakt voor het gehele voorgaande jaar (2020). En historische partities voor perioden van het hele jaar 2019 en 2018 worden gemaakt. Er worden geen hele kwartaalpartities gemaakt omdat op 2 februari het eerste volledige kwartaal van 2021 nog niet is voltooid.
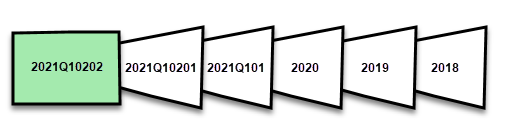
Bij elke vernieuwingsbewerking worden alleen de partities voor de vernieuwingsperiode vernieuwd. Het datumfilter van de DirectQuery-partitie wordt bijgewerkt, zodat alleen wijzigingen worden opgenomen die plaatsvinden na de huidige vernieuwingsperiode. Er wordt een nieuwe vernieuwingspartitie gemaakt voor nieuwe rijen met een nieuwe datum/tijd binnen de bijgewerkte vernieuwingsperiode. Bestaande rijen met een datum/tijd die al binnen bestaande partities in de vernieuwingsperiode vallen, worden vernieuwd met updates. Rijen met een datum/tijd ouder dan de updateperiode worden niet meer bijgewerkt.
Wanneer hele perioden worden afgesloten, worden partities samengevoegd. Als er bijvoorbeeld een vernieuwingsperiode van één dag en een periode van drie jaar historische opslag is opgegeven in het beleid, worden op de eerste dag van de maand alle partities voor de vorige maand samengevoegd in een maandpartitie. Op de eerste dag van een nieuw kwartaal worden alle drie de vorige maandpartities samengevoegd in een kwartpartitie. Op de eerste dag van een nieuw jaar worden alle vier de vorige kwartaalpartities samengevoegd in een jaarpartitie.
Een model behoudt altijd partities voor de hele historische opslagperiode plus gehele periodepartities tot en met de huidige vernieuwingsperiode. In het voorbeeld worden drie volledige jaren aan historische gegevens bewaard in partities voor 2018, 2019 en 2020, en ook voor partities van de maandperiode 2021Q101, de dagperiode 2021Q10201 en de huidige dagvernieuwingsperiode. Omdat in het voorbeeld historische gegevens drie jaar worden bewaard, wordt de partitie 2018 bewaard tot de eerste vernieuwing op 1 januari 2022.
Met incrementele verversing en realtime-gegevens van Power BI verwerkt de service het partitiebeheer voor u volgens het beleid. Hoewel de service al het partitiebeheer voor u kan verwerken, kunt u met behulp van hulpprogramma's via het XMLA-eindpunt selectief partities afzonderlijk, opeenvolgend of parallel vernieuwen.
Algemene patronen voor het vernieuwen van partities
Houd bij het werken met XMLA-eindpuntbewerkingen rekening met deze algemene patronen voor het beheren van vernieuwingsbewerkingen:
- Frequente kleine vernieuwingen: voer tijdens kantooruren meerdere kleine, gerichte vernieuwingsbewerkingen uit met behulp van XMLA-partitieopdrachten of de verbeterde REST API om recente gegevens actueel te houden zonder de hele tabel te verwerken.
-
Selectieve historische backfills: Voer grotere historische partitievernieuwingen of eenmalige gegevenscorrecties uit tijdens off-hours met TMSL
applyRefreshPolicy: falseom specifieke historische perioden opnieuw te bouwen zonder dat dit van invloed is op het gedrag van het automatische beleid. - Gefaseerde initiële belastingen: Voor grote historische perioden breekt u de initiële vernieuwing in kleinere batches op door incrementeel partities te verwerken om time-outs te voorkomen en het resourceverbruik te beheren.
Met deze patronen kunt u de versheid van realtime gegevens in balans houden met systeemprestaties en resourcebeperkingen.
Beheer vernieuwen met SQL Server Management Studio
SQL Server Management Studio (SSMS) kan worden gebruikt voor het weergeven en beheren van partities die zijn gemaakt door de toepassing van beleid voor incrementeel vernieuwen. Met behulp van SSMS kunt u bijvoorbeeld een specifieke historische partitie niet in de incrementele vernieuwingsperiode vernieuwen om een back-date update uit te voeren zonder dat u alle historische gegevens hoeft te vernieuwen. SSMS kan ook worden gebruikt bij bootstrapping om historische gegevens voor grote modellen te laden door incrementeel historische partities toe te voegen of te vernieuwen in batches.
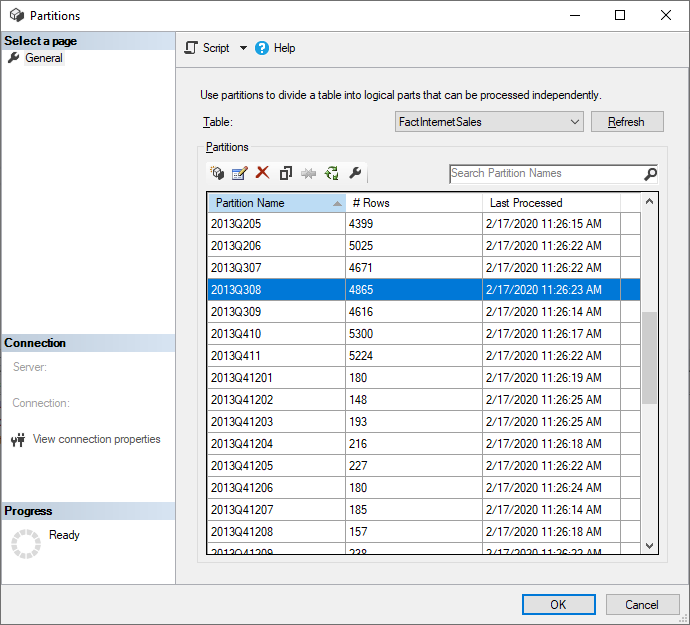
Incrementeel vernieuwingsgedrag overschrijven
Met SSMS hebt u ook meer controle over het aanroepen van vernieuwingen met behulp van tabellaire modelscripttaal en het tabellaire objectmodel. Klik bijvoorbeeld in SSMS in Objectverkenner met de rechtermuisknop op een tabel en selecteer vervolgens de menuoptie Procestabel en selecteer vervolgens de knop Script om een TMSL-vernieuwingsopdracht te genereren.
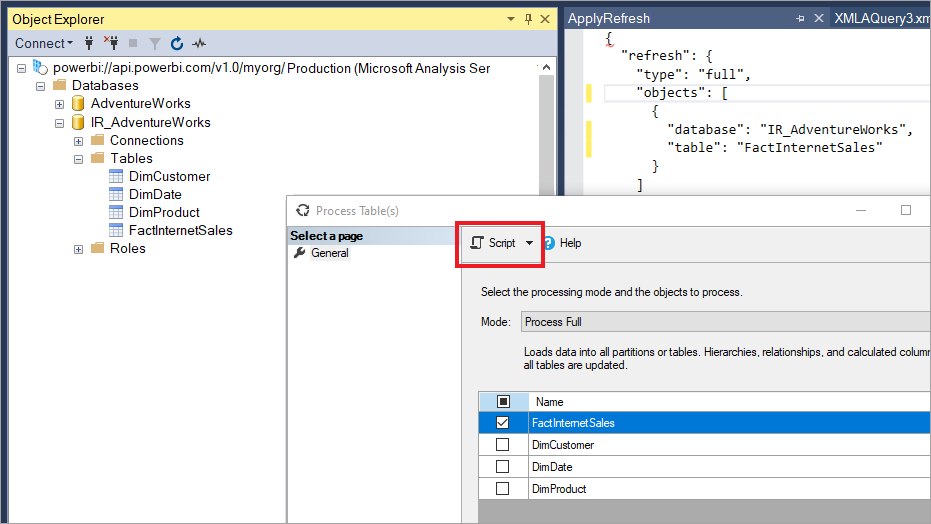
Deze parameters kunnen worden gebruikt met de TMSL-vernieuwingsopdracht om het standaardgedrag voor incrementeel vernieuwen te overschrijven:
applyRefreshPolicy. Als een tabel een beleid voor incrementeel vernieuwen heeft gedefinieerd,
applyRefreshPolicybepaalt u of het beleid al dan niet wordt toegepast. Als het beleid niet wordt toegepast, laat een volledig bewerkingsproces de partitiedefinities ongewijzigd en worden alle partities in de tabel volledig vernieuwd. De standaardwaarde is waar.effectiveDate. Als een beleid voor incrementeel vernieuwen wordt toegepast, moet deze de huidige datum kennen om het bereik van lopende vensters voor de incrementele vernieuwing en historische perioden te bepalen. Met
effectiveDatede parameter kunt u de huidige datum overschrijven. Deze parameter is handig voor het testen, demo's en bedrijfsscenario's waarbij gegevens incrementeel worden vernieuwd tot een datum in het verleden of de toekomst, bijvoorbeeld budgetten in de toekomst. De standaardwaarde is de huidige datum.
{
"refresh": {
"type": "full",
"applyRefreshPolicy": true,
"effectiveDate": "12/31/2013",
"objects": [
{
"database": "IR_AdventureWorks",
"table": "FactInternetSales"
}
]
}
}
Zie de opdracht Vernieuwen voor meer informatie over het overschrijven van het standaardgedrag voor incrementeel vernieuwen met TMSL.
Beleidsregels beheren met Tabular Editor
Naast SSMS kunt u Tabular Editor gebruiken om beleid voor incrementeel vernieuwen rechtstreeks te maken en te wijzigen op basis van semantische modellen via het XMLA-eindpunt. Met deze methode kunt u beleidsinstellingen, zoals vernieuwingsperioden, historische perioden en bronexpressies, aanpassen zonder het model opnieuw te publiceren vanuit Power BI Desktop. Tabular Editor kan ook worden gebruikt om vernieuwingsbeleid toe te passen op bestaande tabellen en RangeStart parameterexpressies te beheren RangeEnd. Zie Incrementeel vernieuwen in de documentatie van de tabellaire editor voor meer informatie.
Indeling en automatisering vernieuwen
Naast het gebruik van SSMS, TMSL en TOM voor het beheren van vernieuwingen via het XMLA-eindpunt. U kunt ook semantische vernieuwingsbewerkingen voor modellen organiseren met behulp van de Power BI REST API. De verbeterde vernieuwings-API biedt meer mogelijkheden, waaronder vernieuwen op tabel- en partitieniveau, logica voor opnieuw proberen, annuleren en aangepast time-outbeheer. Deze methode is handig voor het integreren van vernieuwingsbewerkingen in geautomatiseerde werkstromen en CI/CD-pijplijnen. Zie Verbeterde vernieuwing met de Power BI REST API voor gedetailleerde richtlijnen.
Optimale prestaties garanderen
Bij elke vernieuwingsbewerking kan de Power BI-service initialisatiequery's verzenden naar de gegevensbron voor elke incrementele vernieuwingspartitie. Mogelijk kunt u de prestaties van incrementeel vernieuwen verbeteren door het aantal initialisatiequery's te verminderen door de volgende configuratie te garanderen:
- De tabel waarvoor u incrementeel vernieuwen configureert, moet gegevens ophalen uit één gegevensbron. Als de tabel gegevens ophaalt uit meer dan één gegevensbron, wordt het aantal query's dat door de service wordt verzonden voor elke vernieuwingsbewerking vermenigvuldigd met het aantal gegevensbronnen, waardoor de vernieuwingsprestaties mogelijk worden verminderd. Zorg ervoor dat de query voor de incrementele vernieuwingstabel betrekking heeft op één gegevensbron.
- Voor oplossingen met zowel incrementeel vernieuwen van importpartities als realtimegegevens met Direct Query moeten alle partities query's uitvoeren op gegevens uit één gegevensbron.
- Als uw beveiligingsvereisten het toestaan, stelt u het privacyniveau van de gegevensbron in op Organisatie of Openbaar. Standaard is het privacyniveau Privé. Dit niveau kan echter voorkomen dat gegevens worden uitgewisseld met andere cloudbronnen. Als u het privacyniveau wilt instellen, selecteert u het menu Meer optiesen kiest u> vervolgens instellingenvoor gegevensbronreferenties>>van de instelling Privacyniveau voor deze gegevensbron. Als het privacyniveau is ingesteld in het Power BI Desktop-model voordat het naar de service wordt gepubliceerd, wordt het niet overgebracht naar de service wanneer u publiceert. U moet deze nog steeds instellen in semantische modelinstellingen in de service. Zie Privacyniveaus voor meer informatie.
- Als u een on-premises gegevensgateway gebruikt, zorg er dan voor dat u versie 3000.77.3 of hoger gebruikt.
Time-outs voorkomen bij eerste volledige vernieuwing
Nadat u naar de Power BI-service hebt gepubliceerd, creëert de eerste volledige vernieuwingsbewerking voor het model partities voor de incrementele vernieuwtabel, laadt en verwerkt historische gegevens voor de hele periode die is gedefinieerd in het incrementele vernieuwingsbeleid. Voor sommige modellen die grote hoeveelheden gegevens laden en verwerken, kan de hoeveelheid tijd die de initiële vernieuwingsbewerking duurt, de vernieuwingstijd overschrijden die is opgelegd door de service of een door de gegevensbron opgelegde tijdslimiet voor query's.
Het opstarten van de initiële vernieuwingsbewerking stelt de service in staat partitieobjecten te creëren voor de incrementele vernieuwtabel, maar historische gegevens niet te laden en te verwerken in de partities. SSMS wordt vervolgens gebruikt om partities selectief te verwerken. Afhankelijk van de hoeveelheid gegevens die voor elke partitie moet worden geladen, kunt u elke partitie sequentieel of in kleine batches verwerken. Deze methode vermindert het potentieel voor een of meer van deze partities om een time-out te veroorzaken. De volgende methoden werken voor elke gegevensbron.
Vernieuwingsbeleid toepassen
Het opensource-hulpprogramma Tabular Editor 2 biedt een eenvoudige manier om een initiële vernieuwingsbewerking op te starten. Nadat u een model hebt gepubliceerd met een beleid voor incrementeel vernieuwen dat hiervoor is gedefinieerd vanuit Power BI Desktop naar de service, maakt u verbinding met het model met behulp van het XMLA-eindpunt in de modus Lezen/schrijven. Voer Beleid voor vernieuwen toepassen uit op de tabel incrementeel vernieuwen. Wanneer alleen het beleid is toegepast, worden partities gemaakt, maar worden er geen gegevens in geladen. Maak vervolgens verbinding met SSMS om de partities opeenvolgend of in batches te vernieuwen om de gegevens te laden en te verwerken. Zie Incrementeel vernieuwen in de documentatie van de tabellaire editor voor meer informatie.
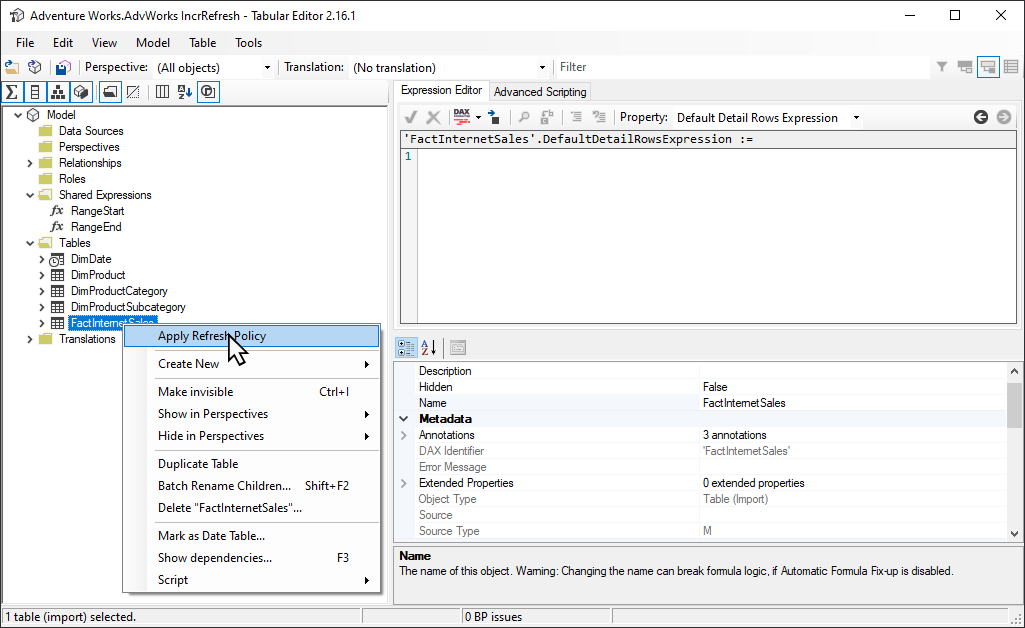
Power Query-filter voor lege partities
Voordat u het model naar de service publiceert, voegt u in de Power Query Editor nog een filter toe aan de ProductKey-kolom, zodat alle waardes behalve 0 worden gefilterd, waardoor effectief alle gegevens uit de tabel FactInternetSales worden uitgesloten.
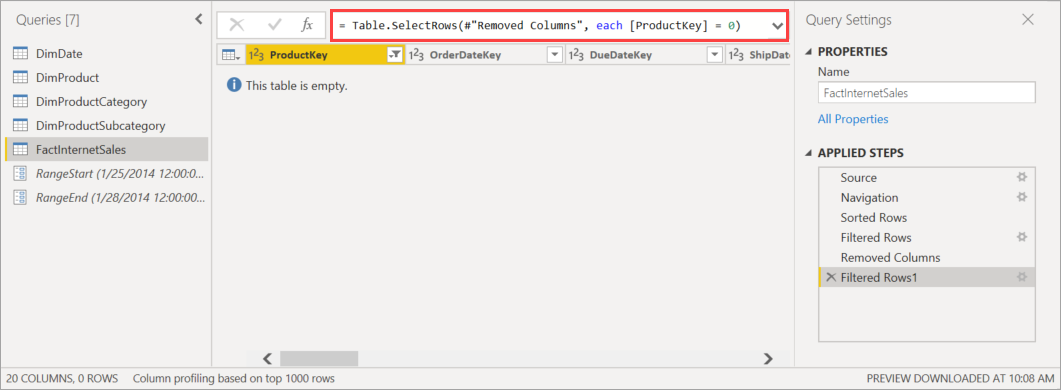
Nadat u Sluiten en toepassen hebt geselecteerd in de Power Query-editor, het beleid voor incrementeel vernieuwen hebt gedefinieerd en het model hebt opgeslagen, wordt het model gepubliceerd naar de service. Vanuit de service wordt de eerste vernieuwingsbewerking uitgevoerd op het model. Partities voor de tabel FactInternetSales worden gemaakt volgens het beleid, maar er worden geen gegevens geladen en verwerkt omdat alle gegevens worden gefilterd.
Nadat de eerste vernieuwingsbewerking is voltooid, wordt het andere filter op de ProductKey kolom verwijderd in de Power Query-editor. Nadat u Sluiten en toepassen hebt geselecteerd in de Power Query-editor en het model hebt opgeslagen, wordt het model niet opnieuw gepubliceerd. Als het model opnieuw wordt gepubliceerd, worden de beleidsinstellingen voor incrementeel vernieuwen overschreven en wordt er een volledige vernieuwingsproces van het model geforceerd wanneer er een volgende vernieuwingsbewerking wordt gestart vanuit de service. Voer in plaats daarvan alleen een implementatie van metagegevens uit met behulp van de ALM-toolkit (Application Lifecycle Management) waarmee het filter op de ProductKey kolom uit het model wordt verwijderd. SSMS kan vervolgens worden gebruikt om partities selectief te verwerken. Wanneer alle partities volledig zijn verwerkt, inclusief een procesherberekening voor alle partities vanuit SSMS, worden de volgende vernieuwingen op het model alleen uitgevoerd voor de incrementele vernieuwingspartities vanuit de service.
Aanbeveling
Bekijk video's, blogs en meer van power BI-experts.
Zie Procesdatabase, tabel of partities (Analysis Services) voor meer informatie over het verwerken van tabellen en partities in SSMS. Zie De opdracht Vernieuwen (TMSL) voor meer informatie over het verwerken van modellen, tabellen en partities met behulp van TMSL.
Aangepaste query's voor het detecteren van gegevenswijzigingen
TMSL en TOM kunnen worden gebruikt om het gedrag van gedetecteerde gegevenswijzigingen te overschrijven. Deze methode kan worden gebruikt om te voorkomen dat de kolom voor de laatste update in de cache in het geheugen behouden blijft. Het kan ook scenario's mogelijk maken waarbij een configuratie- of instructietabel wordt voorbereid door ETL-processen (extract, transform, and load) te extraheren, transformeren en laden. Hiermee kunt u alleen de partities markeren die moeten worden vernieuwd. Met deze methode kunt u een efficiënter incrementeel vernieuwingsproces maken waarbij alleen de vereiste perioden worden vernieuwd, ongeacht hoe lang geleden gegevensupdates plaatsvonden.
Het pollingExpression is bedoeld als een lichtgewicht M-expressie of -naam van een andere M-query. Het moet een scalaire waarde retourneren en wordt uitgevoerd voor elke partitie. Als de geretourneerde waarde verschilt van wat de laatste keer is dat een incrementele vernieuwing heeft plaatsgevonden, wordt de partitie gemarkeerd voor volledige verwerking.
In het volgende voorbeeld worden alle 120 maanden in de historische periode voor wijzigingen met terugwerkende kracht behandeld. Het opgeven van 120 maanden in plaats van 10 jaar betekent dat gegevenscompressie mogelijk niet zo efficiënt is. Het voorkomt echter dat u een heel historisch jaar moet bijwerken, wat duurder zou zijn wanneer een maand voldoende zou zijn voor een verandering met terugwerkende kracht.
"refreshPolicy": {
"policyType": "basic",
"rollingWindowGranularity": "month",
"rollingWindowPeriods": 120,
"incrementalGranularity": "month",
"incrementalPeriods": 120,
"pollingExpression": "<M expression or name of custom polling query>",
"sourceExpression": [
"let ..."
]
}
Aanbeveling
Bekijk video's, blogs en meer van power BI-experts.
Implementatie van alleen metagegevens
Wanneer u een nieuwe versie van een PBIX-bestand publiceert vanuit Power BI Desktop naar een werkruimte. U ziet de volgende prompt om het bestaande model te vervangen, als er al een model met dezelfde naam bestaat.
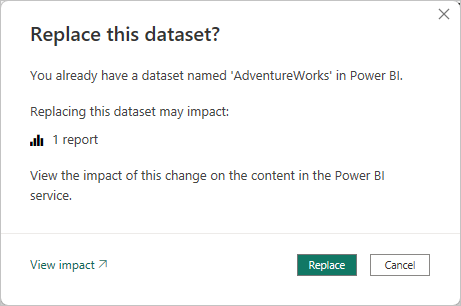
In sommige gevallen wilt u het model mogelijk niet vervangen, met name door incrementeel vernieuwen. Het model in Power BI Desktop kan aanzienlijk kleiner zijn dan het model in de Power BI-service. Als voor het model in de Power BI-service een beleid voor incrementeel vernieuwen is toegepast, gaan mogelijk enkele jaren historische gegevens verloren als het model wordt vervangen. Het vernieuwen van alle historische gegevens kan uren duren en leidt tot systeem downtime voor gebruikers.
In plaats daarvan is het beter om alleen een implementatie van metagegevens uit te voeren, waardoor nieuwe objecten kunnen worden geïmplementeerd zonder dat de historische gegevens verloren gaan. Als u bijvoorbeeld slechts enkele metingen toevoegt, kunt u alleen de nieuwe metingen implementeren zonder dat u de gegevens hoeft te vernieuwen, wat tijd bespaart.
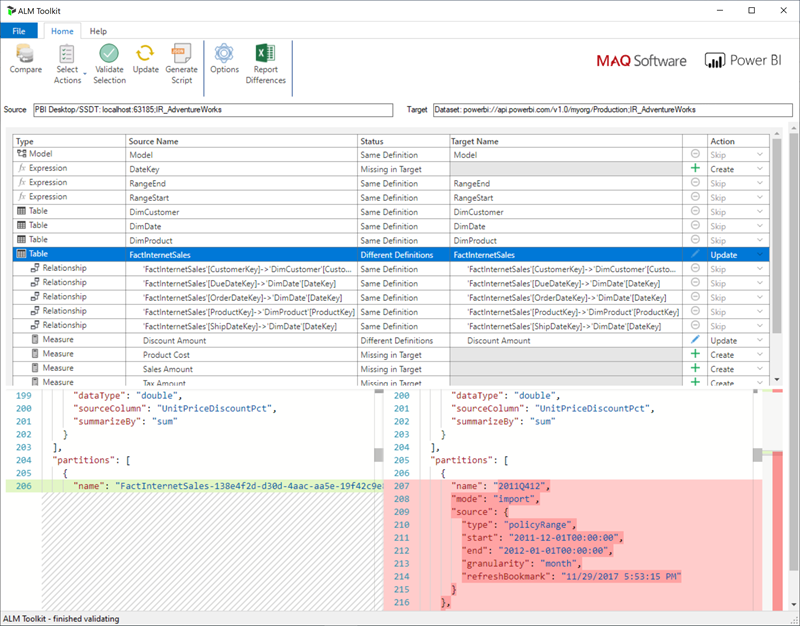
Voor werkruimten die zijn toegewezen aan een Premium-capaciteit die is geconfigureerd voor lezen/schrijven van XMLA-eindpunten, maken compatibele hulpprogramma's alleen implementatie van metagegevens mogelijk. De ALM Toolkit is bijvoorbeeld een hulpprogramma voor schemaverschil voor Power BI-modellen en kan alleen worden gebruikt om de implementatie van metagegevens uit te voeren.
Download en installeer de nieuwste versie van de ALM Toolkit vanuit de Git-opslagplaats van Analysis Services. Stapsgewijze richtlijnen voor het gebruik van ALM Toolkit zijn niet opgenomen in de Microsoft-documentatie. Alm Toolkit-documentatiekoppelingen en informatie over ondersteuning zijn beschikbaar op het Help-lint . Als u alleen een implementatie van metagegevens wilt uitvoeren, voert u een vergelijking uit en selecteert u het actieve Power BI Desktop-exemplaar als de bron en het bestaande model in de Power BI-service als doel. Houd rekening met de verschillen die worden weergegeven en sla de update van de tabel over met incrementele vernieuwingspartities of gebruik het dialoogvenster Opties om partities voor tabelupdates te behouden. Valideer de selectie om de integriteit van het doelmodel te waarborgen en werk vervolgens bij.
Beleid voor incrementeel vernieuwen en realtime gegevens programmatisch toevoegen
U kunt de TMSL en TOM ook gebruiken om een beleid voor incrementeel vernieuwen toe te voegen aan een bestaand model via het XMLA-eindpunt.
Opmerking
Als u compatibiliteitsproblemen wilt voorkomen, moet u de nieuwste versie van de Analysis Services-clientbibliotheken gebruiken. Als u bijvoorbeeld wilt werken met hybride beleidsregels, moet de versie 19.27.1.8 of hoger zijn.
Het proces bevat de volgende stappen:
Zorg ervoor dat het doelmodel het vereiste minimale compatibiliteitsniveau heeft. Klik in SSMS met de rechtermuisknop op hetcompatibiliteitsniveau>>. Als u het compatibiliteitsniveau wilt verhogen, gebruikt u een TMSL-script createOrReplace of controleert u de volgende TOM-voorbeeldcode voor een voorbeeld.
a. Import policy - 1550 b. Hybrid policy - 1565Voeg de
RangeStartenRangeEndparameters toe aan de modelexpressies. Voeg indien nodig ook een functie toe om datum-/tijdwaarden te converteren naar datumsleutels.Definieer een
RefreshPolicyobject met de gewenste archivering (rolling window) en incrementele vernieuwingsperioden, evenals een bronexpressie waarmee de doeltabel wordt gefilterd op basis van deRangeStartenRangeEndparameters. Stel de beleidsmodus vernieuwen in op Importeren of Hybride , afhankelijk van uw realtime-gegevensvereisten. Hybride zorgt ervoor dat Power BI een DirectQuery-partitie toevoegt aan de tabel om de meest recente wijzigingen op te halen uit de gegevensbron die zich na de laatste vernieuwingstijd heeft voorgedaan.Voeg het vernieuwingsbeleid toe aan de tabel en voer een volledige vernieuwing uit, zodat Power BI de tabel partitioneert op basis van uw vereisten.
In het volgende codevoorbeeld ziet u hoe u de vorige stappen uitvoert met behulp van TOM. Als u dit voorbeeld wilt gebruiken, moet u een kopie hebben voor de AdventureWorksDW-database en de tabel FactInternetSales importeren in een model. In het codevoorbeeld wordt ervan uitgegaan dat de RangeStart en RangeEnd parameters en de DateKey functie niet in het model bestaan. Importeer de tabel FactInternetSales en publiceer het model naar een werkruimte in Power BI Premium. Werk vervolgens de workspaceUrl code bij zodat het codevoorbeeld verbinding kan maken met uw model. Werk zo nodig alle coderegels bij.
using System;
using TOM = Microsoft.AnalysisServices.Tabular;
namespace Hybrid_Tables
{
class Program
{
static string workspaceUrl = "<Enter your Workspace URL here>";
static string databaseName = "AdventureWorks";
static string tableName = "FactInternetSales";
static void Main(string[] args)
{
using (var server = new TOM.Server())
{
// Connect to the dataset.
server.Connect(workspaceUrl);
TOM.Database database = server.Databases.FindByName(databaseName);
if (database == null)
{
throw new ApplicationException("Database cannot be found!");
}
if(database.CompatibilityLevel < 1565)
{
database.CompatibilityLevel = 1565;
database.Update();
}
TOM.Model model = database.Model;
// Add RangeStart, RangeEnd, and DateKey function.
model.Expressions.Add(new TOM.NamedExpression {
Name = "RangeStart",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 30, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "RangeEnd",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 31, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "DateKey",
Kind = TOM.ExpressionKind.M,
Expression =
"let\n" +
" Source = (x as datetime) => Date.Year(x)*10000 + Date.Month(x)*100 + Date.Day(x)\n" +
"in\n" +
" Source"
});
// Apply a RefreshPolicy with Real-Time to the target table.
TOM.Table salesTable = model.Tables[tableName];
TOM.RefreshPolicy hybridPolicy = new TOM.BasicRefreshPolicy
{
Mode = TOM.RefreshPolicyMode.Hybrid,
IncrementalPeriodsOffset = -1,
RollingWindowPeriods = 1,
RollingWindowGranularity = TOM.RefreshGranularityType.Year,
IncrementalPeriods = 1,
IncrementalGranularity = TOM.RefreshGranularityType.Day,
SourceExpression =
"let\n" +
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW\"),\n" +
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],\n" +
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= DateKey(RangeStart) and [OrderDateKey] < DateKey(RangeEnd))\n" +
"in\n" +
" #\"Filtered Rows\""
};
salesTable.RefreshPolicy = hybridPolicy;
model.RequestRefresh(TOM.RefreshType.Full);
model.SaveChanges();
}
Console.WriteLine("{0}{1}", Environment.NewLine, "Press [Enter] to exit...");
Console.ReadLine();
}
}
}