High-densitysampling in Power BI-spreidingsdiagrammen
Het Power BI-sampling-algoritme verbetert hoe spreidingsdiagrammen high-densitygegevens vertegenwoordigen.
U kunt bijvoorbeeld een spreidingsdiagram maken op basis van de verkoopactiviteit van uw organisatie, waarbij elke winkel elk jaar tienduizenden gegevenspunten heeft. Een spreidingsdiagram van dergelijke informatie zou voorbeeldgegevens uit een zinvolle weergave van die gegevens bevatten om te illustreren hoe de verkoop in de loop van de tijd heeft plaatsgevonden. De details van high-densitygegevenssampling worden beschreven in dit artikel.

Notitie
Het high-densitysampling-algoritme dat in dit artikel wordt beschreven, is beschikbaar in de spreidingsdiagrammen voor power BI Desktop en de Power BI-service.
Hoe high-densityspreidingsdiagrammen werken
Eerder heeft Power BI een verzameling voorbeeldgegevenspunten geselecteerd in het volledige bereik van onderliggende gegevens op een deterministische manier om een spreidingsdiagram te maken. Power BI selecteert met name de eerste en laatste rijen met gegevens in de reeks spreidingsdiagrammen en verdeelt vervolgens de resterende rijen gelijkmatig, zodat het totaal van 3500 gegevenspunten in het spreidingsdiagram is uitgezet. Als de steekproef bijvoorbeeld 35.000 rijen had, worden de eerste en laatste rijen geselecteerd voor plotting, dan wordt elke tiende rij ook getekend (35.000 / 10 = elke tiende rij = 35.500 gegevenspunten). Ook eerder werden null-waarden of punten die niet konden worden uitgezet, zoals tekstwaarden, niet weergegeven in gegevensreeksen en werden dus niet meegenomen bij het genereren van de visual. Bij dergelijke steekproeven was de waargenomen dichtheid van het spreidingsdiagram ook gebaseerd op de representatieve gegevenspunten, dus de impliciete visuele dichtheid was een omstandigheid van de steekproefpunten, niet de volledige verzameling van de onderliggende gegevens.
Wanneer u high-densitysampling inschakelt, implementeert Power BI een algoritme dat overlappende punten elimineert en ervoor zorgt dat de punten in de visual kunnen worden bereikt bij interactie met de visual. Het algoritme zorgt er ook voor dat alle punten in de gegevensset worden weergegeven in de visual, waardoor context wordt geboden aan de betekenis van geselecteerde punten, in plaats van alleen een representatieve steekproef te tekenen.
High-densitygegevens worden per definitie genomen om visualisaties te maken die reageren op interactiviteit. Te veel gegevenspunten in een visual kunnen deze vertragen en de zichtbaarheid van trends afleiden. De manier waarop gegevens worden bemonsterd, bepaalt het maken van het sampling-algoritme om de beste visualisatie-ervaring te bieden en ervoor te zorgen dat alle gegevens worden weergegeven. In Power BI is het algoritme verbeterd om de beste combinatie van reactiesnelheid, representatie en het duidelijke behoud van belangrijke punten in de algemene gegevensset te bieden.
Notitie
Spreidingsdiagrammen met behulp van het high-densitysampling-algoritme worden het beste uitgezet op vierkante visuals, net als bij alle spreidingsdiagrammen.
Hoe het sampling-algoritme voor spreidingsdiagrammen werkt
Het algoritme voor high-densitysampling voor spreidingsdiagrammen maakt gebruik van methoden die de onderliggende gegevens effectiever vastleggen en vertegenwoordigen en overlappende punten elimineert. Het algoritme begint met een kleine straal voor elk gegevenspunt. Dit is de grootte van de visuele cirkel voor een bepaald punt in de visualisatie. Vervolgens wordt de straal van alle gegevenspunten verhoogd. Wanneer twee of meer gegevenspunten elkaar overlappen, vertegenwoordigt één cirkel van de verhoogde radius die overlappende gegevenspunten. Het algoritme blijft de radius van gegevenspunten verhogen totdat die radiuswaarde resulteert in een redelijk aantal gegevenspunten (3500) dat in het spreidingsdiagram wordt weergegeven.
De methoden in dit algoritme zorgen ervoor dat uitbijters worden weergegeven in de resulterende visual. Het algoritme respecteert ook de schaal bij het bepalen van overlapping, zodat exponentiële schalen worden gevisualiseerd met betrouwbaarheid voor de onderliggende gevisualiseerde punten.
Het algoritme behoudt ook de algehele vorm van het spreidingsdiagram.
Notitie
Wanneer u het high-densitysamplingalgoritme voor spreidingsdiagrammen gebruikt, is de nauwkeurige verdeling van de gegevens het doel, niet impliciete visuele dichtheid. U ziet bijvoorbeeld een spreidingsdiagram met veel cirkels die elkaar overlappen (dichtheid) in een bepaald gebied en stel dat er veel gegevenspunten moeten worden geclusterd. Omdat het high-densitysampling-algoritme één cirkel kan gebruiken om veel gegevenspunten weer te geven, wordt een dergelijke impliciete visuele dichtheid of 'clustering' niet weergegeven. Voor meer details in een bepaald gebied kunt u slicers gebruiken om in te zoomen.
Bovendien worden gegevenspunten die niet kunnen worden uitgezet, zoals null-waarden of tekstwaarden, genegeerd, zodat een andere waarde die kan worden uitgezet, is geselecteerd. Dit zorgt er verder voor dat de werkelijke vorm van het spreidingsdiagram behouden blijft.
Wanneer het standaardalgoritmen voor spreidingsdiagrammen wordt gebruikt
Er zijn omstandigheden waaronder high-densitysampling niet kan worden toegepast op een spreidingsdiagram en het oorspronkelijke algoritme wordt gebruikt. Deze omstandigheden zijn:
Als u met de rechtermuisknop op een waarde onder Waarden klikt en deze instelt op Items zonder gegevens uit het menu weergeven, wordt het spreidingsdiagram teruggezet naar het oorspronkelijke algoritme.
Alle waarden in het veld Afspeelas leiden ertoe dat het spreidingsdiagram wordt teruggezet naar het oorspronkelijke algoritme.
Als zowel X- als Y-assen ontbreken in een spreidingsdiagram, wordt het diagram teruggezet naar het oorspronkelijke algoritme.
Als u een verhoudingslijn in het deelvenster Analyse gebruikt, wordt de grafiek teruggezet naar het oorspronkelijke algoritme.
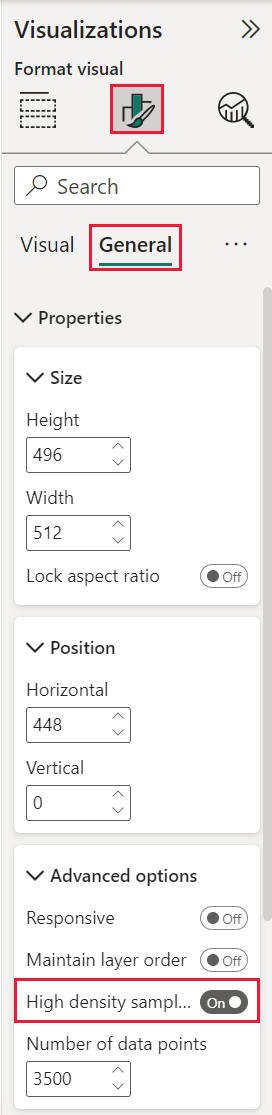
High-densitysampling inschakelen voor een spreidingsdiagram
Als u high-densitysampling wilt overschakelen naar Aan, selecteert u een spreidingsdiagram, gaat u naar het deelvenster Visuele opmaak, vouwt u de kaart Algemeen uit en schuift u de schuifregelaar voor high-densitysampling naar Aan.
Notitie
Nadat de switch is ingeschakeld, probeert Power BI waar mogelijk het high-densitysampling-algoritme te gebruiken. Wanneer het algoritme niet kan worden gebruikt, bijvoorbeeld wanneer u een waarde op de afspeelas plaatst, blijft de schakeloptie ingeschakeld , ook al is de grafiek teruggezet naar het standaardalgoritmen. Als u vervolgens een waarde van de Afspeelas verwijdert of als de voorwaarden veranderen om het gebruik van het high-densitysampling-algoritme in te schakelen, gebruikt de grafiek automatisch high-densitysampling voor die grafiek omdat de functie actief is.
Notitie
Gegevenspunten worden gegroepeerd of geselecteerd door de index. Het hebben van een legenda heeft geen invloed op steekproeven voor het algoritme. Dit is alleen van invloed op de volgorde van de visual.
Overwegingen en beperkingen
Het high-densitysampling-algoritme is een belangrijke verbetering in Power BI. Het high-densitysampling-algoritme werkt echter alleen met liveverbindingen met op Power BI-service gebaseerde modellen, geïmporteerde modellen of DirectQuery.