Door de gebruiker gedefinieerde aggregaties
Aggregaties in Power BI kunnen de queryprestaties verbeteren ten opzichte van grote semantische DirectQuery-modellen. Door aggregaties te gebruiken, slaat u gegevens op het geaggregeerde niveau in het geheugen op. Aggregaties in Power BI kunnen handmatig worden geconfigureerd in het gegevensmodel, zoals beschreven in dit artikel. Voor Premium-abonnementen wordt de functie Automatische aggregaties automatisch ingeschakeld in model Instellingen.
Aggregatietabellen maken
Afhankelijk van het gegevensbrontype kan een aggregatietabel worden gemaakt in de gegevensbron als een tabel of weergave, systeemeigen query. Voor de beste prestaties maakt u een aggregatietabel als een importtabel die is gemaakt in Power Query. Vervolgens gebruikt u het dialoogvenster Aggregaties beheren in Power BI Desktop om aggregaties te definiëren voor aggregatiekolommen met samenvattings-, detailtabel- en detailkolomeigenschappen.
Dimensionale gegevensbronnen, zoals datawarehouses en datamarts, kunnen op relaties gebaseerde aggregaties gebruiken. Op Hadoop gebaseerde big data-bronnen baseren vaak aggregaties op GroupBy-kolommen. In dit artikel worden typische verschillen in Power BI-gegevensmodellering beschreven voor elk type gegevensbron.
Aggregaties beheren
Klik in het deelvenster Gegevens van een Power BI Desktop-weergave met de rechtermuisknop op de aggregatietabel en selecteer Aggregaties beheren.
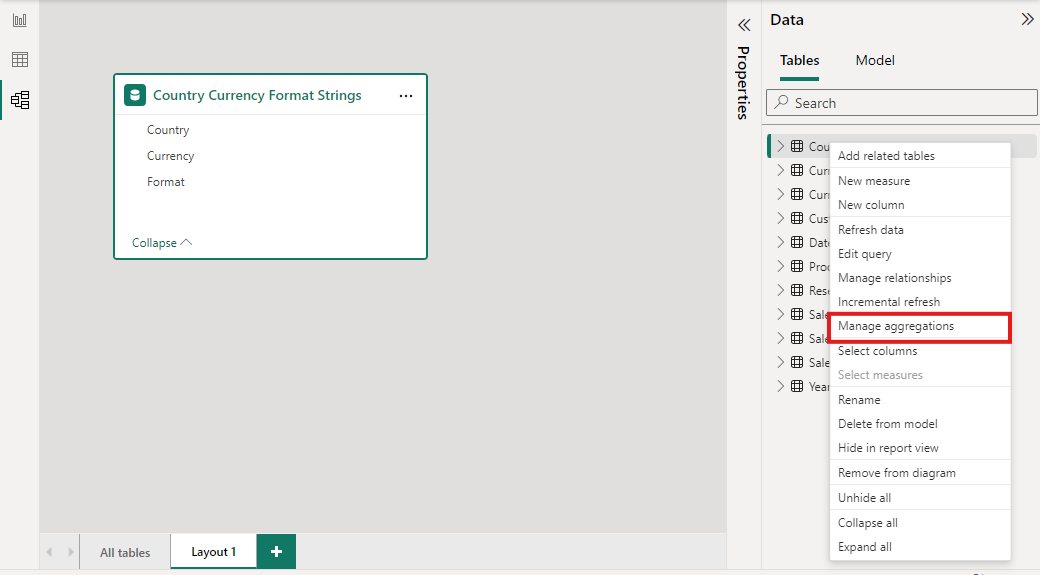
In het dialoogvenster Aggregaties beheren ziet u een rij voor elke kolom in de tabel, waar u het aggregatiegedrag kunt opgeven. In het volgende voorbeeld worden query's naar de tabel Verkoopdetail intern omgeleid naar de aggregatietabel Sales Agg .

In dit op relaties gebaseerde aggregatievoorbeeld zijn de GroupBy-vermeldingen optioneel. Met uitzondering van DISTINCTCOUNT hebben ze geen invloed op het aggregatiegedrag en zijn ze voornamelijk geschikt voor leesbaarheid. Zonder de GroupBy-vermeldingen worden de aggregaties nog steeds geraakt op basis van de relaties. Dit verschilt van het big data-voorbeeld verderop in dit artikel, waarbij de GroupBy-vermeldingen vereist zijn.
Validaties
Het dialoogvenster Aggregaties beheren dwingt validaties af:
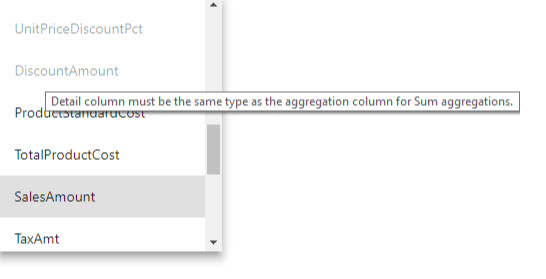
- De detailkolom moet hetzelfde gegevenstype hebben als de aggregatiekolom, met uitzondering van de tabelrijen Aantal en Aantal, samenvattingsfuncties. Tabelrijen tellen en tellen zijn alleen beschikbaar voor kolommen met gehele getallen en vereisen geen overeenkomend gegevenstype.
- Gekoppelde aggregaties voor drie of meer tabellen zijn niet toegestaan. Aggregaties in tabel A kunnen bijvoorbeeld niet verwijzen naar een tabel B met aggregaties die verwijzen naar een tabel C.
- Dubbele aggregaties, waarbij twee vermeldingen dezelfde samenvattingsfunctie gebruiken en verwijzen naar dezelfde detailtabel en detailkolom, zijn niet toegestaan.
- De detailtabel moet de DirectQuery-opslagmodus gebruiken, niet importeren.
- Groeperen op een refererende-sleutelkolom die wordt gebruikt door een inactieve relatie en afhankelijk zijn van de functie USERELATIONSHIP voor aggregatietreffers, wordt niet ondersteund.
- Aggregaties op basis van GroupBy-kolommen kunnen relaties tussen aggregatietabellen gebruiken, maar het ontwerpen van relaties tussen aggregatietabellen wordt niet ondersteund in Power BI Desktop. Indien nodig kunt u relaties tussen aggregatietabellen maken met behulp van een hulpprogramma van derden of een scriptoplossing via XML for Analysis-eindpunten (XMLA).
De meeste validaties worden afgedwongen door vervolgkeuzelijstwaarden uit te schakelen en verklarende tekst in de knopinfo weer te geven.
Aggregatietabellen zijn verborgen
Gebruikers met alleen-lezentoegang tot het model kunnen geen query's uitvoeren op aggregatietabellen. Alleen-lezentoegang voorkomt beveiligingsproblemen bij gebruik met beveiliging op rijniveau (RLS). Consumenten en query's verwijzen naar de detailtabel, niet naar de aggregatietabel en hoeven niet te weten wat de aggregatietabel is.
Daarom zijn aggregatietabellen verborgen in de rapportweergave . Als de tabel nog niet is verborgen, wordt deze in het dialoogvenster Aggregaties beheren ingesteld op verborgen wanneer u Alles toepassen selecteert.
Opslagmodi
De aggregatiefunctie communiceert met opslagmodi op tabelniveau. Power BI-tabellen kunnen gebruikmaken van DirectQuery-, Import- of Dual-opslagmodi . DirectQuery voert rechtstreeks query's uit op de back-end, terwijl Gegevens in het geheugen worden opgeslagen in de cache en query's worden verzonden naar de gegevens in de cache. Alle Power BI-import- en niet-multidimensionale DirectQuery-gegevensbronnen kunnen werken met aggregaties.
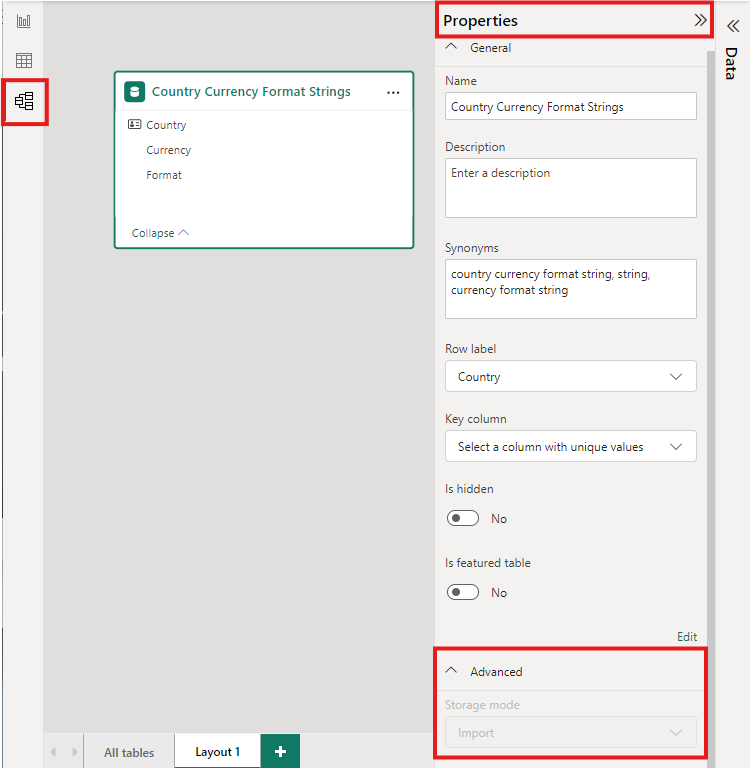
Als u de opslagmodus van een geaggregeerde tabel wilt instellen op Importeren om query's sneller te maken, selecteert u de samengevoegde tabel in de modelweergave van Power BI Desktop. Vouw Geavanceerd uit in het deelvenster Eigenschappen, selecteer de selectie onder Opslagmodus en selecteer Importeren. Het wijzigen van importeren kan niet ongedaan worden.
Zie Opslagmodus beheren in Power BI Desktop voor meer informatie over tabelopslagmodi.
Beveiliging op rijniveau voor aggregaties
Om correct te kunnen werken voor aggregaties, moeten RLS-expressies de aggregatietabel en de detailtabel filteren.
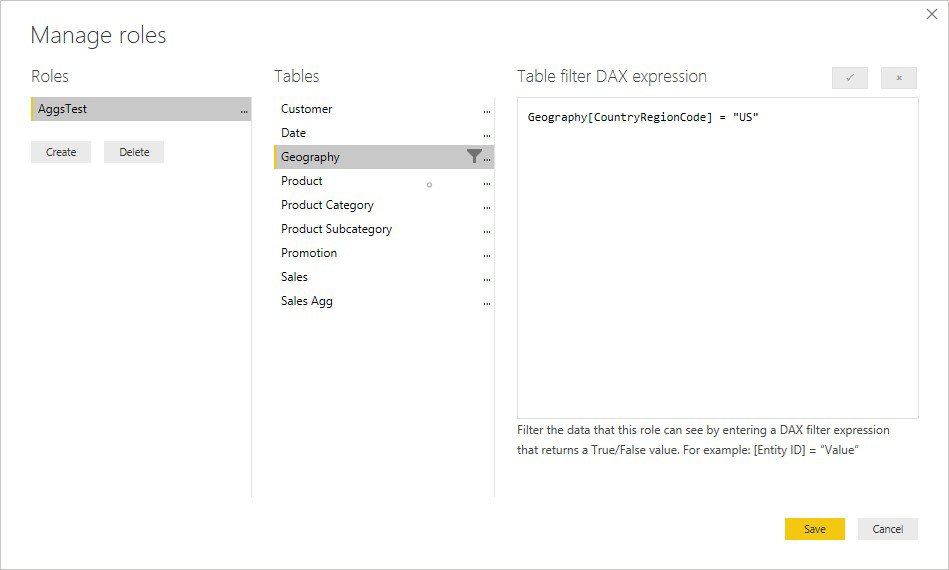
In het volgende voorbeeld werkt de RLS-expressie in de tabel Geografie voor aggregaties, omdat Geografie zich aan de filterzijde van relaties met de tabel Sales en de tabel Sales Agg bevindt. Query's die de aggregatietabel en query's hebben bereikt waarop geen RLS is toegepast.
Een RLS-expressie in de tabel Product filtert alleen de detailtabel Sales , niet de geaggregeerde tabel Sales Agg . Omdat de aggregatietabel een andere weergave is van de gegevens in de detailtabel, is het onveilig om query's uit de aggregatietabel te beantwoorden als het RLS-filter niet kan worden toegepast. Het is niet raadzaam om alleen de detailtabel te filteren, omdat gebruikersquery's uit deze rol geen baat hebben bij aggregatietreffers.
Een RLS-expressie die alleen de aggregatietabel Sales Agg filtert en niet de detailtabel Sales is niet toegestaan.
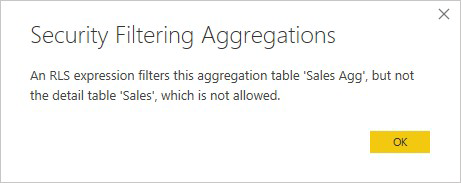
Voor aggregaties op basis van GroupBy-kolommen kan een RLS-expressie die op de detailtabel wordt toegepast, worden gebruikt om de aggregatietabel te filteren, omdat alle GroupBy-kolommen in de aggregatietabel worden gedekt door de detailtabel. Aan de andere kant kan een RLS-filter op de aggregatietabel niet worden toegepast op de detailtabel, dus is dit niet toegestaan.
Aggregatie op basis van relaties
Dimensionale modellen maken doorgaans gebruik van aggregaties op basis van relaties. Power BI-modellen van datawarehouses en datamarts lijken op ster-/sneeuwvlokschema's, met relaties tussen dimensietabellen en feitentabellen.
In het volgende voorbeeld haalt het model gegevens op uit één gegevensbron. Tabellen maken gebruik van de DirectQuery-opslagmodus. De feitentabel Sales bevat miljarden rijen. Als u de opslagmodus van Verkoop instelt op Importeren voor opslaan in cache, verbruikt dit aanzienlijke geheugen- en resourcesoverhead.
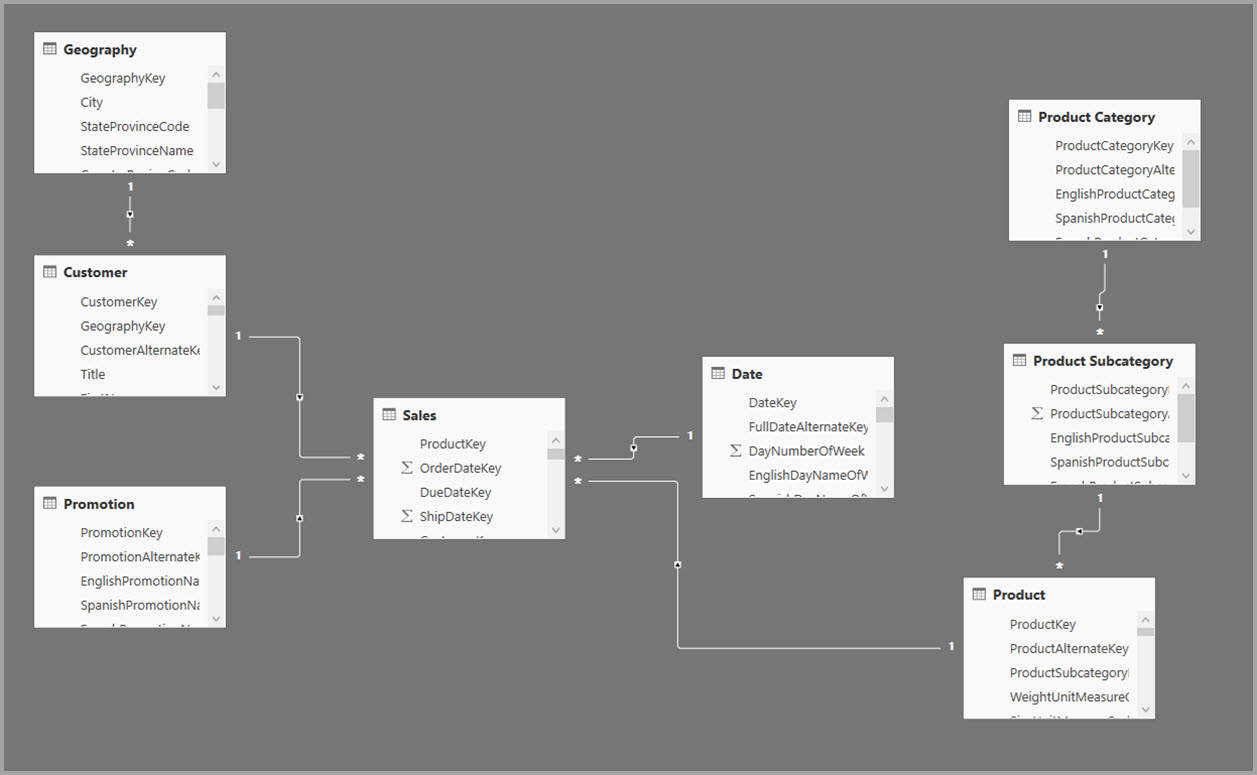
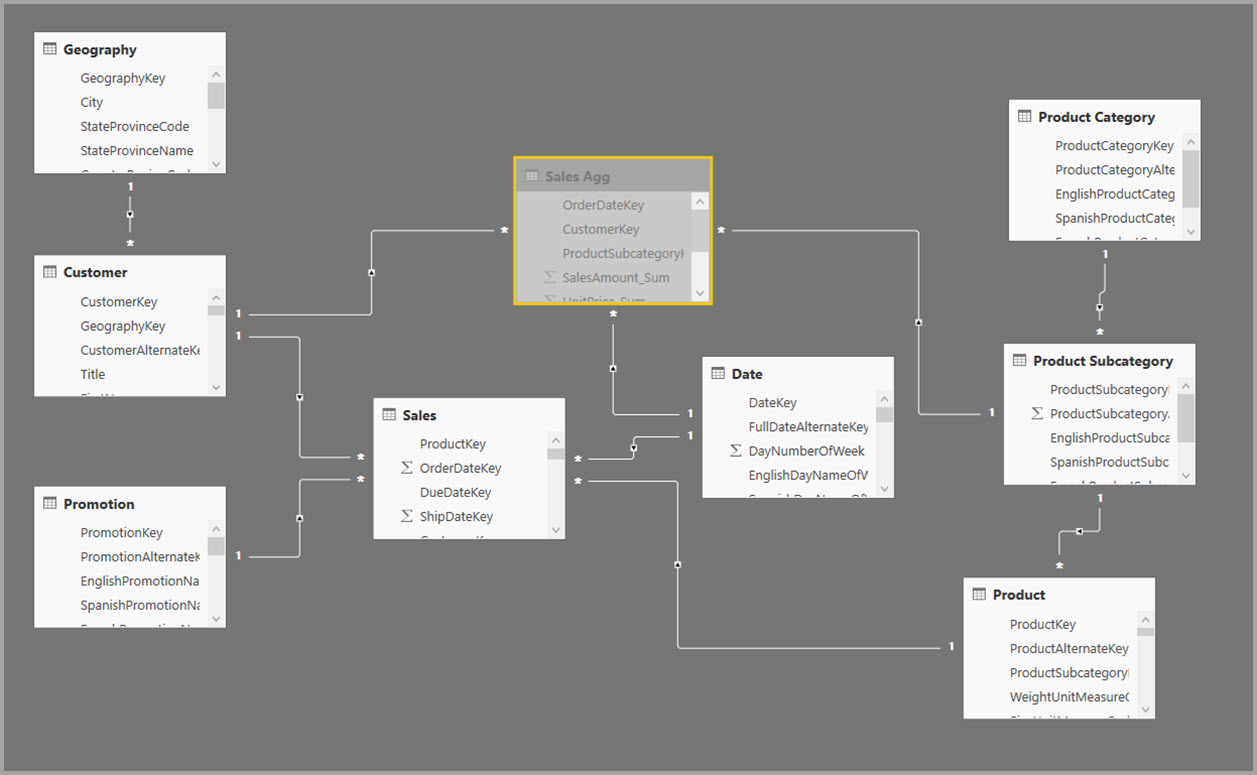
Maak in plaats daarvan de aggregatietabel Sales Agg . In de tabel Sales Agg is het aantal rijen gelijk aan de som van SalesAmount gegroepeerd op CustomerKey, DateKey en ProductSubcategoryKey. De tabel Sales Agg heeft een hogere granulariteit dan Sales, dus in plaats van miljarden kan deze miljoenen rijen bevatten, die gemakkelijker te beheren zijn.
Als de volgende dimensietabellen het meest worden gebruikt voor de query's met een hoge bedrijfswaarde, kunnen ze Sales Agg filteren met behulp van een-op-veel- of veel-op-een-relaties.
- Geografie
- Customer
- Datum
- Productsubcategorie
- Productcategorie
In de volgende afbeelding ziet u dit model.
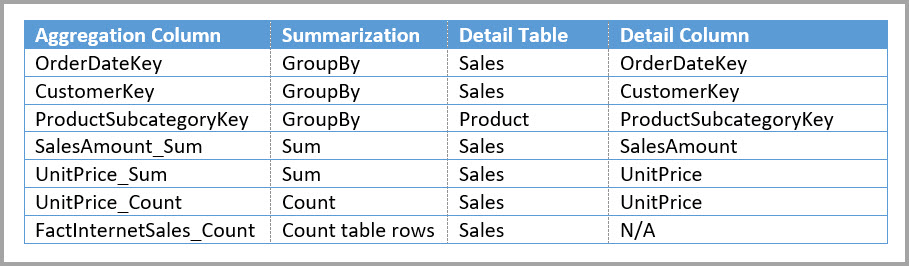
In de volgende tabel ziet u de aggregaties voor de tabel Sales Agg .
Notitie
De tabel Sales Agg , zoals elke tabel, heeft de flexibiliteit om op verschillende manieren te worden geladen. De aggregatie kan worden uitgevoerd in de brondatabase met ETL/ELT-processen of met de M-expressie voor de tabel. De samengevoegde tabel kan de opslagmodus Importeren gebruiken, met of zonder incrementeel vernieuwen voor semantische modellen, of kan DirectQuery gebruiken en worden geoptimaliseerd voor snelle query's met columnstore-indexen. Dankzij deze flexibiliteit kunnen architecturen met gelijke taakverdeling querybelastingen verspreiden om knelpunten te voorkomen.
Als u de opslagmodus van de geaggregeerde tabel Sales Agg wijzigt in Import , wordt een dialoogvenster geopend waarin staat dat de gerelateerde dimensietabellen kunnen worden ingesteld op opslagmodus Dual.
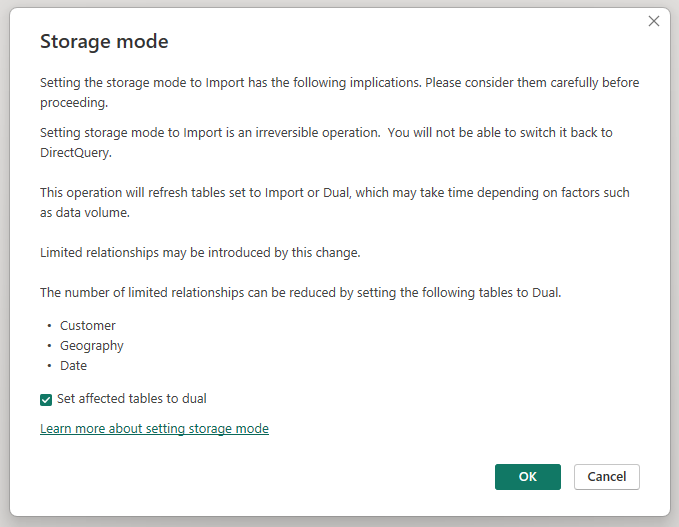
Als u de gerelateerde dimensietabellen instelt op Dual, kunnen ze fungeren als Importeren of DirectQuery, afhankelijk van de subquery. In het voorbeeld:
- Query's die metrische gegevens uit de tabel Sales Agg in de importmodus aggregeren en groeperen op kenmerk(en) uit de gerelateerde Dual-tabellen, kunnen worden geretourneerd vanuit de cache in het geheugen.
- Query's die metrische gegevens uit de tabel DirectQuery Sales aggregeren en groeperen op kenmerk(en) uit de gerelateerde Dual-tabellen, kunnen worden geretourneerd in de DirectQuery-modus. De querylogica, inclusief de GroupBy-bewerking, wordt doorgegeven aan de brondatabase.
Zie Opslagmodus beheren in Power BI Desktop voor meer informatie over de dual-opslagmodus.
Reguliere versus beperkte relaties
Aggregatietreffers op basis van relaties vereisen reguliere relaties.
Reguliere relaties omvatten de volgende combinaties van opslagmodus, waarbij beide tabellen afkomstig zijn van één bron:
| Tabel aan de vele zijden | Tabel aan de 1 kant |
|---|---|
| Dual | Dual |
| Importeren | Importeren of dual |
| DirectQuery | DirectQuery of Dual |
Het enige geval waarin een cross-source-relatie wordt beschouwd als normaal, is als beide tabellen zijn ingesteld op Importeren. Veel-op-veel-relaties worden altijd als beperkt beschouwd.
Zie Aggregaties op basis van GroupBy-kolommen voor aggregatietreffers die niet afhankelijk zijn van relaties.
Voorbeelden van aggregatiequery's op basis van relaties
De volgende query raakt de aggregatie, omdat kolommen in de tabel Date de granulariteit hebben die de aggregatie kan raken. De kolom SalesAmount maakt gebruik van de aggregatie Sum .

De volgende query raakt de aggregatie niet. Ondanks het aanvragen van de som van SalesAmount, voert de query een GroupBy-bewerking uit op een kolom in de tabel Product , die niet bij de granulariteit ligt die de aggregatie kan raken. Als u de relaties in het model bekijkt, kan een productsubcategorie meerdere productrijen hebben. De query zou niet kunnen bepalen welk product moet worden samengevoegd. In dit geval wordt de query teruggezet naar DirectQuery en wordt een SQL-query naar de gegevensbron verzonden.

Aggregaties zijn niet alleen bedoeld voor eenvoudige berekeningen die een eenvoudige som uitvoeren. Complexe berekeningen kunnen ook voordeel hebben. Conceptueel wordt een complexe berekening onderverdeeld in subquery's voor elke SOM, MIN, MAX en COUNT. Elke subquery wordt geëvalueerd om te bepalen of deze de aggregatie kan raken. Deze logica geldt niet in alle gevallen vanwege optimalisatie van queryplannen, maar in het algemeen moet deze van toepassing zijn. In het volgende voorbeeld wordt de aggregatie bereikt:

De functie COUNTROWS kan profiteren van aggregaties. De volgende query raakt de aggregatie omdat er een aggregatie aantal tabelrijen is gedefinieerd voor de tabel Sales .

De functie AVERAGE kan profiteren van aggregaties. De volgende query raakt de aggregatie omdat AVERAGE intern wordt gevouwen tot een SOM gedeeld door een COUNT. Omdat de kolom Prijs per eenheid aggregaties heeft gedefinieerd voor zowel SUM als COUNT, wordt de aggregatie bereikt.

In sommige gevallen kan de functie DISTINCTCOUNT profiteren van aggregaties. De volgende query raakt de aggregatie omdat er een GroupBy-vermelding is voor CustomerKey, die de uniekheid van CustomerKey in de aggregatietabel behoudt. Deze techniek bereikt mogelijk nog steeds de prestatiedrempel, waarbij meer dan twee tot vijf miljoen afzonderlijke waarden van invloed kunnen zijn op de queryprestaties. Het kan echter handig zijn in scenario's waarin er miljarden rijen in de detailtabel staan, maar twee tot vijf miljoen afzonderlijke waarden in de kolom. In dit geval kan DISTINCTCOUNT sneller presteren dan het scannen van de tabel met miljarden rijen, zelfs als deze in het cachegeheugen zijn opgeslagen.

Time intelligence-functies (Data Analysis Expressions) (DAX) zijn aggregatiebewust. De volgende query raakt de aggregatie omdat de functie DATESYTD een tabel met CalendarDay-waarden genereert en de aggregatietabel een granulariteit heeft die wordt gedekt door kolommen in de tabel Datum . Dit is een voorbeeld van een tabelwaardefilter voor de functie CALCULATE, die kan werken met aggregaties.

Aggregatie op basis van GroupBy-kolommen
Op Hadoop gebaseerde big data-modellen hebben verschillende kenmerken dan dimensionale modellen. Om samenvoegingen tussen grote tabellen te voorkomen, gebruiken big data-modellen vaak geen relaties, maar denormaliseren dimensiekenmerken voor feitentabellen. U kunt dergelijke big data-modellen ontgrendelen voor interactieve analyse met behulp van aggregaties op basis van GroupBy-kolommen.
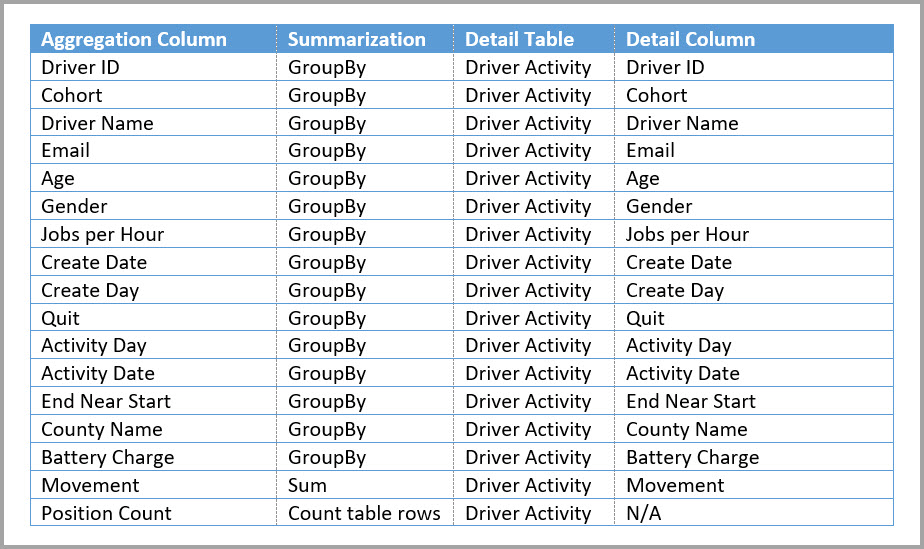
De volgende tabel bevat de numerieke kolom Movement die moet worden samengevoegd. Alle andere kolommen zijn kenmerken om op te groeperen. De tabel bevat IoT-gegevens en een groot aantal rijen. De opslagmodus is DirectQuery. Query's op de gegevensbron die worden geaggregeerd in het hele model is traag vanwege het enorme volume.
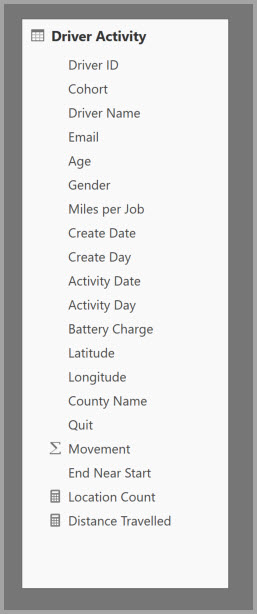
Als u interactieve analyses voor dit model wilt inschakelen, kunt u een aggregatietabel toevoegen die wordt gegroepeerd op de meeste kenmerken, maar de kenmerken met een hoge kardinaliteit, zoals lengtegraad en breedtegraad, uitsluiten. Dit vermindert het aantal rijen aanzienlijk en is klein genoeg om comfortabel in een in-memory cache te passen.
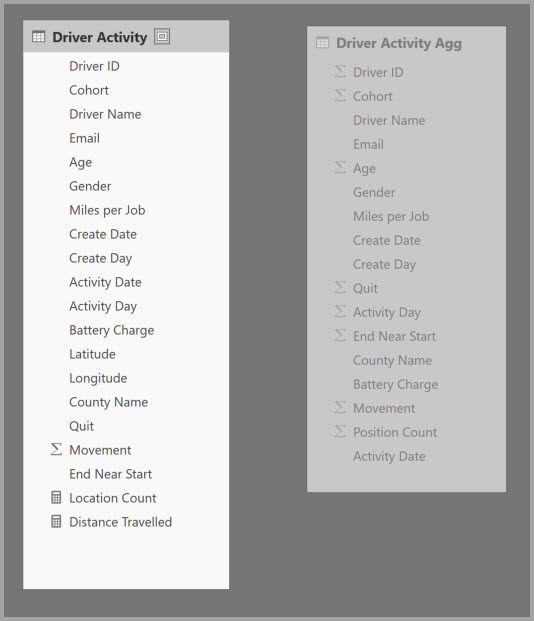
U definieert de aggregatietoewijzingen voor de tabel Driver Activity Agg in het dialoogvenster Aggregaties beheren.
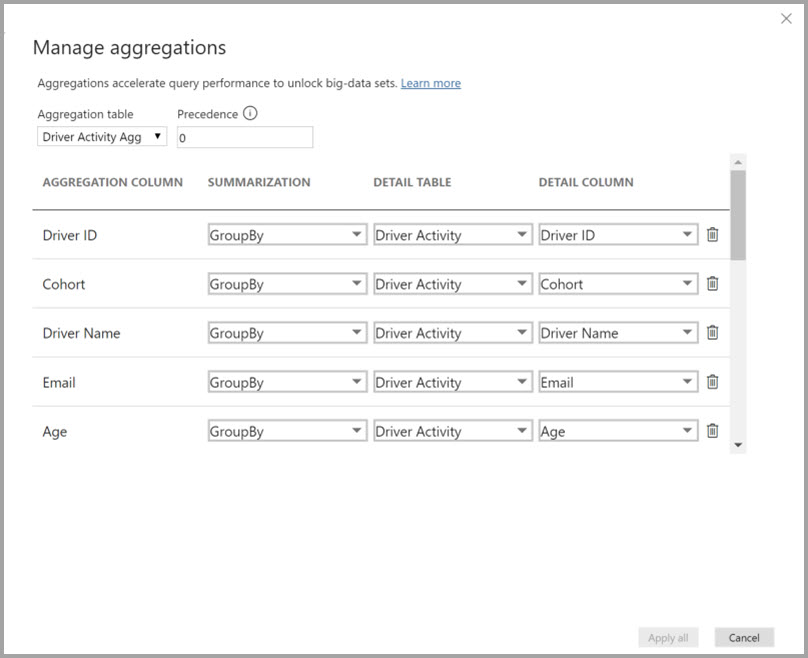
In aggregaties op basis van GroupBy-kolommen zijn de GroupBy-vermeldingen niet optioneel. Zonder deze worden de aggregaties niet geraakt. Dit verschilt van het gebruik van aggregaties op basis van relaties, waarbij de GroupBy-vermeldingen optioneel zijn.
In de volgende tabel ziet u de aggregaties voor de tabel Driver Activity Agg .
U kunt de opslagmodus van de geaggregeerde tabel Driver Activity Agg instellen op Importeren.
Voorbeeld van aggregatiequery GroupBy
De volgende query raakt de aggregatie, omdat de kolom Activiteitsdatum wordt gedekt door de aggregatietabel. De functie COUNTROWS maakt gebruik van de aggregatie van tabelrijen geteld.

Met name voor modellen die filterkenmerken in feitentabellen bevatten, is het een goed idee om aggregaties voor tabelrijen tellen te gebruiken. Power BI kan query's verzenden naar het model met behulp van COUNTROWS in gevallen waarin dit niet expliciet door de gebruiker wordt aangevraagd. In het filterdialoogvenster ziet u bijvoorbeeld het aantal rijen voor elke waarde.
Gecombineerde aggregatietechnieken
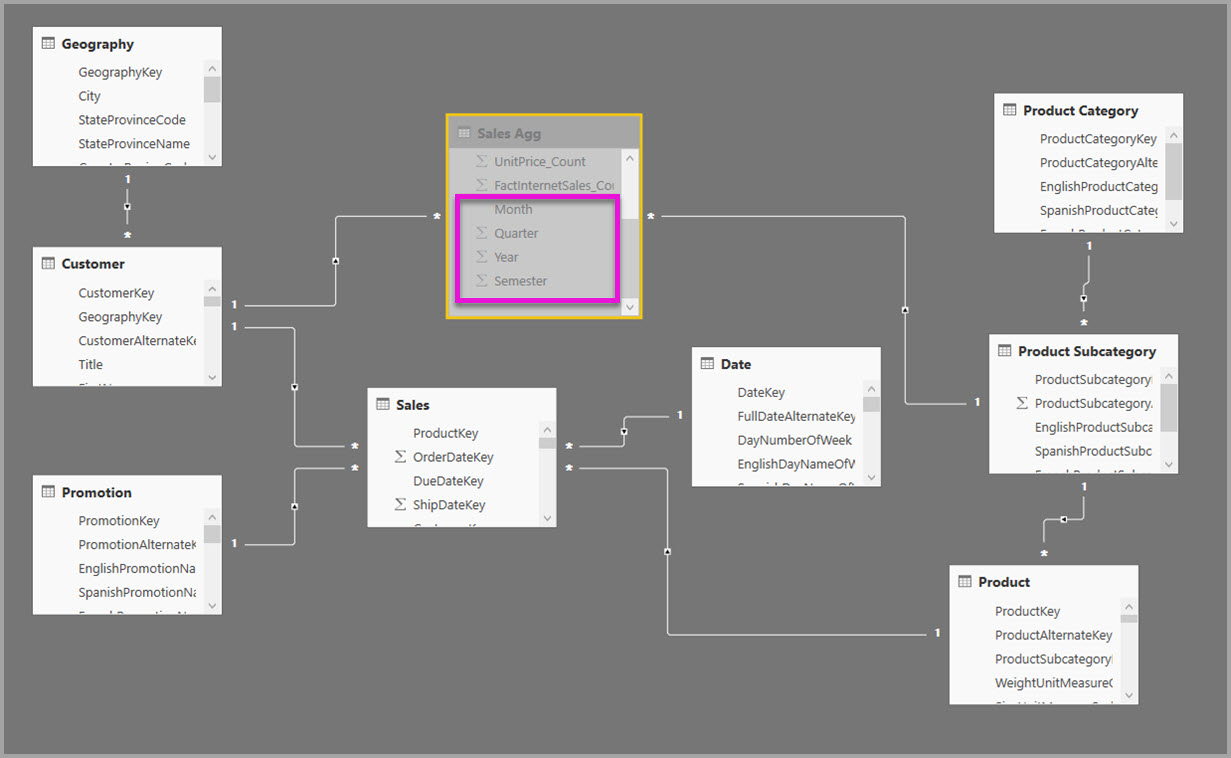
U kunt de relaties en groupBy-kolomtechnieken voor aggregaties combineren. Aggregaties op basis van relaties kunnen vereisen dat de gedenormaliseerde dimensietabellen worden gesplitst in meerdere tabellen. Als dit kostbaar of onpraktisch is voor bepaalde dimensietabellen, kunt u de benodigde kenmerken in de aggregatietabel repliceren voor deze dimensies en relaties voor anderen gebruiken.
Het volgende model repliceert bijvoorbeeld Month, Quarter, Semester en Year in de tabel Sales Agg . Er is geen relatie tussen Sales Agg en de tabel Date , maar er zijn relaties met klant - en productsubcategorie. De opslagmodus van Sales Agg is Importeren.
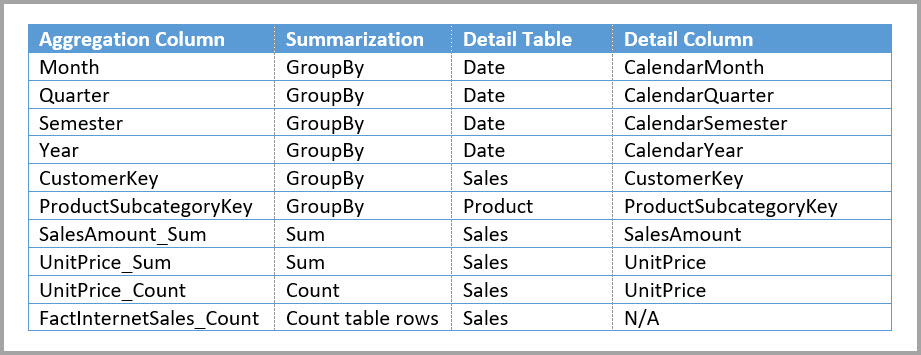
In de volgende tabel ziet u de vermeldingen die zijn ingesteld in het dialoogvenster Aggregaties beheren voor de tabel Sales Agg . De GroupBy-vermeldingen waarbij Datum de detailtabel is, zijn verplicht om aggregaties te bereiken voor query's die worden gegroepeerd op de datumkenmerken . Net als in het vorige voorbeeld hebben de GroupBy-vermeldingen voor CustomerKey en ProductSubcategoryKey geen invloed op aggregatietreffers, met uitzondering van DISTINCTCOUNT, vanwege de aanwezigheid van relaties.
Voorbeelden van gecombineerde aggregatiequery's
De volgende query raakt de aggregatie, omdat de aggregatietabel CalendarMonth omvat en CategoryName toegankelijk is via een-op-veel-relaties. SalesAmount maakt gebruik van de SOM-aggregatie .

De volgende query raakt de aggregatie niet, omdat de aggregatietabel geen betrekking heeft op CalendarDay.

De volgende time intelligence-query raakt de aggregatie niet, omdat de functie DATESYTD een tabel met CalendarDay-waarden genereert en de aggregatietabel geen betrekking heeft op CalendarDay.

Aggregatieprioriteit
Met aggregatieprioriteit kunnen meerdere aggregatietabellen worden overwogen door één subquery.
Het volgende voorbeeld is een samengesteld model met meerdere bronnen:
- De DirectQuery-tabel Driver Activity bevat meer dan een biljoen rijen ioT-gegevens die afkomstig zijn van een big data-systeem. Het biedt drillthrough-query's om afzonderlijke IoT-metingen weer te geven in gecontroleerde filtercontexten.
- De tabel Driver Activity Agg is een tussenliggende aggregatietabel in de DirectQuery-modus. Het bevat meer dan een miljard rijen in Azure Synapse Analytics (voorheen SQL Data Warehouse) en is geoptimaliseerd voor de bron met behulp van columnstore-indexen.
- De tabel Driver Activity Agg2 Import heeft een hoge granulariteit, omdat de group-by-kenmerken weinig en lage kardinaliteit zijn. Het aantal rijen kan zo laag zijn als duizenden, zodat het gemakkelijk in een cache in het geheugen past. Deze kenmerken worden gebruikt door een leidinggevend dashboard met een hoog profiel, zodat query's die ernaar verwijzen, zo snel mogelijk moeten zijn.
Notitie
DirectQuery-aggregatietabellen die gebruikmaken van een andere gegevensbron uit de detailtabel, worden alleen ondersteund als de aggregatietabel afkomstig is van een SQL Server-, Azure SQL- of Azure Synapse Analytics-bron (voorheen SQL Data Warehouse).
De geheugenvoetafdruk van dit model is relatief klein, maar het ontgrendelt een enorm model. Het vertegenwoordigt een evenwichtige architectuur omdat de querybelasting wordt verdeeld over onderdelen van de architectuur, waarbij deze worden gebruikt op basis van hun sterke punten.
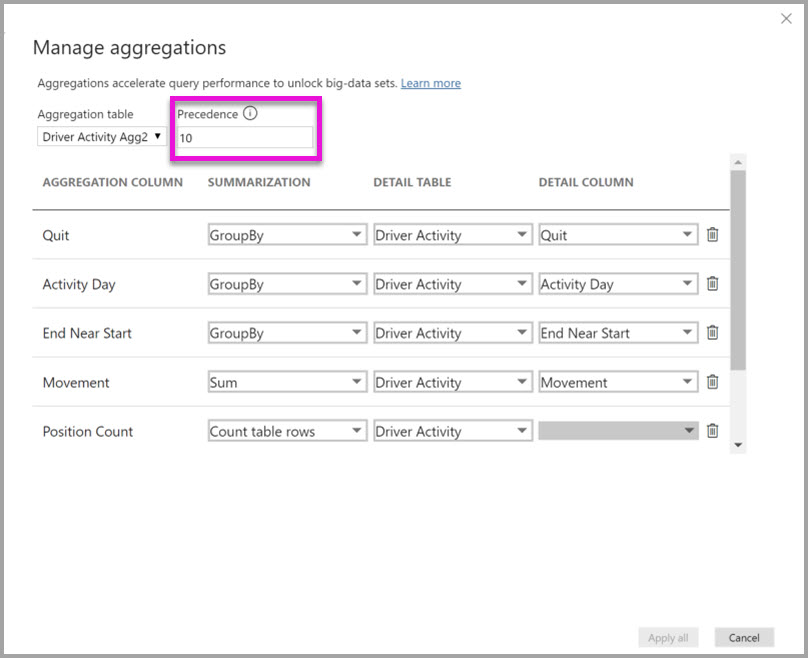
Het dialoogvenster Beheerde aggregaties voor Driver Activity Agg2 stelt het veld Prioriteit in op 10, wat hoger is dan voor Driver Activity Agg. De hogere prioriteitsinstelling betekent dat query's die gebruikmaken van aggregaties eerst Driver Activity Agg2 overwegen. Subquery's die niet de granulariteit hebben die kunnen worden beantwoord door Driver Activity Agg2, kunnen in plaats daarvan Driver Activity Agg overwegen. Detailquery's die niet kunnen worden beantwoord door een van beide aggregatietabellen, kunnen rechtstreeks naar Driver Activity worden verzonden.
De tabel die is opgegeven in de kolom Detailtabel is Driver Activity, niet Driver Activity Agg, omdat gekoppelde aggregaties niet zijn toegestaan.
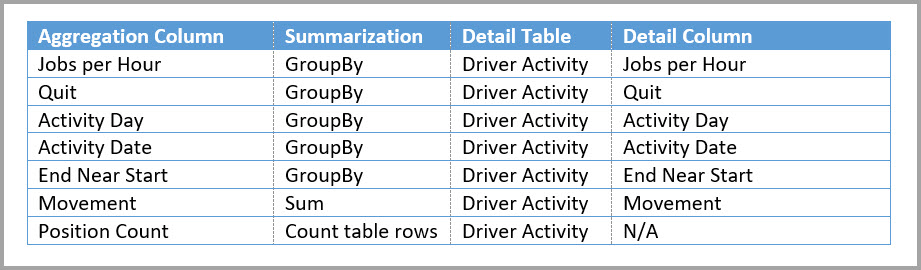
In de volgende tabel ziet u de aggregaties voor de tabel Driver Activity Agg2 .
Detecteren of query's aggregaties raken of missen
SQL Profiler kan detecteren of query's worden geretourneerd vanuit de cacheopslagengine in het geheugen of worden gepusht naar de gegevensbron door DirectQuery. U kunt hetzelfde proces gebruiken om te detecteren of aggregaties worden geraakt. Zie Query's die de cache raken of missen voor meer informatie.
SQL Profiler biedt ook de Query Processing\Aggregate Table Rewrite Query uitgebreide gebeurtenis.
In het volgende JSON-fragment ziet u een voorbeeld van de uitvoer van de gebeurtenis wanneer een aggregatie wordt gebruikt.
- matchingResult laat zien dat de subquery een aggregatie heeft gebruikt.
- dataRequest toont de GroupBy-kolom(en) en geaggregeerde kolom(en) die door de subquery worden gebruikt.
- toewijzing toont de kolommen in de aggregatietabel waaraan is toegewezen.

Caches gesynchroniseerd houden
Aggregaties die DirectQuery-, Import- en/of Dual-opslagmodi combineren, kunnen verschillende gegevens retourneren, tenzij de cache in het geheugen synchroon blijft met de brongegevens. Query-uitvoering probeert bijvoorbeeld geen gegevensproblemen te maskeren door DirectQuery-resultaten te filteren op overeenkomende waarden in de cache. Er zijn vastgestelde technieken voor het afhandelen van dergelijke problemen bij de bron, indien nodig. Prestatieoptimalisaties moeten alleen worden gebruikt op manieren die uw vermogen om te voldoen aan bedrijfsvereisten niet in gevaar kunnen komen. Het is uw verantwoordelijkheid om uw gegevensstromen te kennen en dienovereenkomstig te ontwerpen.
Overwegingen en beperkingen
Aggregaties bieden geen ondersteuning voor dynamische M-queryparameters.
Vanaf augustus 2022 negeert Power BI aggregatietabellen in de importmodus met gegevensbronnen met eenmalige aanmelding (SSO) vanwege mogelijke beveiligingsrisico's. Om optimale queryprestaties met aggregaties te garanderen, is het raadzaam eenmalige aanmelding voor deze gegevensbronnen uit te schakelen.
Community
Power BI heeft een levendige community waar MVP's, BI-professionals en peers expertise delen in discussiegroepen, video's, blogs en meer. Als u meer wilt weten over aggregaties, bekijkt u deze aanvullende resources:
Gerelateerde inhoud
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor