Heaps (tables without clustered indexes)
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
A heap is a table without a clustered index. One or more nonclustered indexes can be created on tables stored as a heap. Data is stored in the heap without specifying an order. Usually data is initially stored in the order in which the rows are inserted. However, the Database Engine can move data around in the heap to store the rows efficiently. In query results, data order cannot be predicted. To guarantee the order of rows returned from a heap, use the ORDER BY clause. To specify a permanent logical order for storing the rows, create a clustered index on the table, so that the table is not a heap.
Note
There are sometimes good reasons to leave a table as a heap instead of creating a clustered index, but using heaps effectively is an advanced skill. Most tables should have a carefully chosen clustered index unless a good reason exists for leaving the table as a heap.
When to use a heap
A heap is ideal for tables that are frequently truncated and reloaded. The database engine optimizes space in a heap by filling the earliest available space.
Consider the following:
- Locating free space in a heap can be costly, especially if there have been many deletes or updates.
- Clustered indexes offer steady performance for tables that are not frequently truncated.
For tables that are regularly truncated or recreated, such as temporary or staging tables, using a heap is often more efficient.
The choice between using a heap and a clustered index can significantly affect your database's performance and efficiency.
When a table is stored as a heap, individual rows are identified by reference to an 8-byte row identifier (RID) consisting of the file number, data page number, and slot on the page (FileID:PageID:SlotID). The row ID is a small and efficient structure.
Heaps can be used as staging tables for large, unordered insert operations. Because data is inserted without enforcing a strict order, the insert operation is usually faster than the equivalent insert into a clustered index. If the heap's data will be read and processed into a final destination, it may be useful to create a narrow nonclustered index that covers the search predicate used by the query.
Note
Data is retrieved from a heap in order of data pages, but not necessarily the order in which data was inserted.
Sometimes data professionals also use heaps when data is always accessed through nonclustered indexes, and the RID is smaller than a clustered index key.
If a table is a heap and does not have any nonclustered indexes, then the entire table must be read (a table scan) to find any row. SQL Server cannot seek a RID directly on the heap. This behavior can be acceptable when the table is small.
When not to use a heap
Do not use a heap when the data is frequently returned in a sorted order. A clustered index on the sorting column could avoid the sorting operation.
Do not use a heap when the data is frequently grouped together. Data must be sorted before it is grouped, and a clustered index on the sorting column could avoid the sorting operation.
Do not use a heap when ranges of data are frequently queried from the table. A clustered index on the range column avoids sorting the entire heap.
Do not use a heap when there are no nonclustered indexes and the table is large. The only application for this design is to return the entire table content without any specified order. In a heap, Database Engine reads all rows to find any row.
Do not use a heap if the data is frequently updated. If you update a record and the update uses more space in the data pages than they are currently using, the record has to be moved to a data page that has enough free space. This creates a forwarded record pointing to the new location of the data, and forwarding pointer has to be written in the page that held that data previously, to indicate the new physical location. This introduces fragmentation in the heap. When Database Engine scans a heap, it follows these pointers. This action limits read-ahead performance, and can incur additional I/O which reduces scan performance.
Manage heaps
To create a heap, create a table without a clustered index. If a table already has a clustered index, drop the clustered index to return the table to a heap.
To remove a heap, create a clustered index on the heap.
To rebuild a heap to reclaim wasted space:
- Create a clustered index on the heap, and then drop that clustered index.
- Use the
ALTER TABLE ... REBUILDcommand to rebuild the heap.
Warning
Creating or dropping clustered indexes requires rewriting the entire table. If the table has nonclustered indexes, all the nonclustered indexes must all be recreated whenever the clustered index is changed. Therefore, changing from a heap to a clustered index structure or back can take a lot of time and require disk space for reordering data in tempdb.
Identify heaps
The following query returns a list of heaps from the current database. The list includes:
- Table names
- Schema names
- Number of rows
- Table size in KB
- Index size in KB
- Unused space
- A column to identify a heap
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Heap structures
A heap is a table without a clustered index. Heaps have one row in sys.partitions, with index_id = 0 for each partition used by the heap. By default, a heap has a single partition. When a heap has multiple partitions, each partition has a heap structure that contains the data for that specific partition. For example, if a heap has four partitions, there are four heap structures; one in each partition.
Depending on the data types in the heap, each heap structure will have one or more allocation units to store and manage the data for a specific partition. At a minimum, each heap will have one IN_ROW_DATA allocation unit per partition. The heap will also have one LOB_DATA allocation unit per partition, if it contains large object (LOB) columns. It will also have one ROW_OVERFLOW_DATA allocation unit per partition, if it contains variable length columns that exceed the 8,060 byte row size limit.
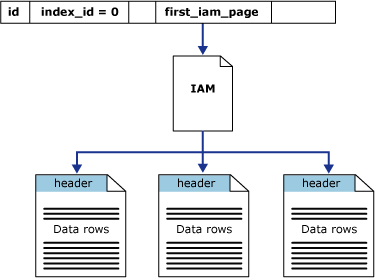
The column first_iam_page in the sys.system_internals_allocation_units system view points to the first IAM page in the chain of IAM pages that manage the space allocated to the heap in a specific partition. SQL Server uses the IAM pages to move through the heap. The data pages and the rows within them are not in any specific order and are not linked. The only logical connection between data pages is the information recorded in the IAM pages.
Important
The sys.system_internals_allocation_units system view is reserved for SQL Server internal use only. Future compatibility is not guaranteed.
Table scans or serial reads of a heap can be performed by scanning the IAM pages to find the extents that are holding pages for the heap. Because the IAM represents extents in the same order that they exist in the data files, this means that serial heap scans progress sequentially through each file. Using the IAM pages to set the scan sequence also means that rows from the heap are not typically returned in the order in which they were inserted.
The following illustration shows how the SQL Server Database Engine uses IAM pages to retrieve data rows in a single partition heap.
Related Content
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Clustered and Nonclustered Indexes Described