Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
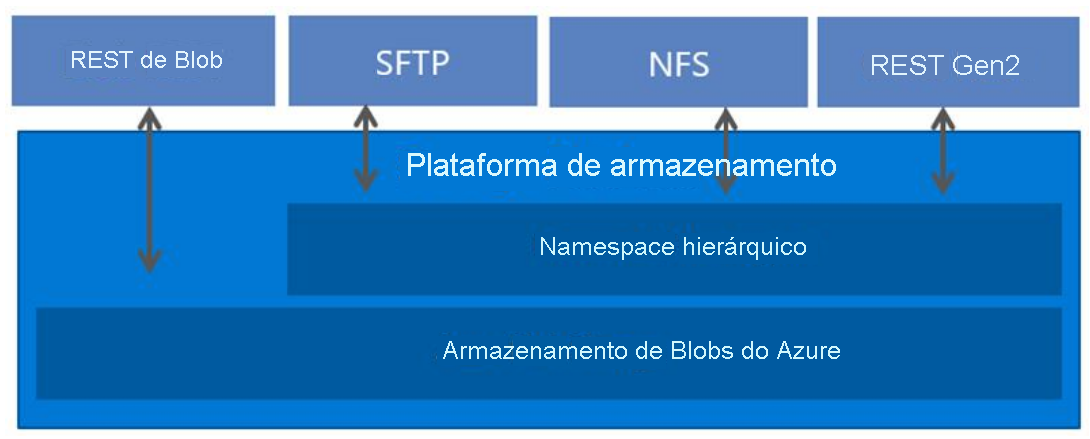
O Armazenamento de blobs agora dá suporte ao protocolo NFS (network file system) 3.0. Esse suporte fornece compatibilidade com o sistema de arquivos do Linux em escala de armazenamento de objetos e preços e permite que os clientes Linux montem um contêiner no Armazenamento de blobs de uma VM do Azure ou de um computador local.
Sempre foi um desafio executar cargas de trabalho herdadas em grande escala, como HPC (computação de alto desempenho) na nuvem. Um motivo é que os aplicativos geralmente usam protocolos de arquivo tradicionais, como NFS (sistema de arquivos de rede) para acessar dados. Além disso, os serviços de armazenamento em nuvem nativos se concentram no armazenamento de objetos que têm um namespace simples e metadados extensivos, em vez de sistemas de arquivos que fornecem um namespace hierárquico e operações de metadados eficientes.
O Armazenamento de blobs agora dá suporte a um namespace hierárquico e, quando combinado com o suporte do protocolo NFS 3.0, o Azure torna muito mais fácil executar aplicativos herdados no armazenamento em larga escala de objetos em nuvem.
Aplicativos e cargas de trabalho adequados para usar o NFS 3.0 com o Armazenamento de Blobs
O recurso de protocolo NFS 3.0 é otimizado para cargas de trabalho de alta taxa de transferência, de grande escala e de leitura pesada com E/S sequencial. É ideal para cenários que envolvem vários leitores e vários threads em que a taxa de transferência é mais crítica do que a baixa latência. Exemplos comuns incluem:
Computação de Alto Desempenho (HPC) – os trabalhos de HPC geralmente envolvem milhares de núcleos lendo os mesmos conjuntos de dados grandes simultaneamente. O recurso do protocolo NFS 3.0 usa a taxa de transferência do armazenamento de objetos para eliminar os gargalos tradicionais do servidor de arquivos. Exemplos:
Sequenciamento de genômica: processamento de conjuntos de dados de DNA maciços.
Modelagem de risco financeiro: simulações de Monte Carlo em dados históricos.
Análise sísmica: dados geológicos para exploração de petróleo e gás.
Previsão do tempo: Modelando dados atmosféricos para previsão de clima e tempestade.
Big Data &Analytics (Data Lakes) – muitas ferramentas de análise exigem diretórios hierárquicos. O BlobNFS (por meio do Azure Data Lake Storage Gen2) fornece essa estrutura enquanto dá suporte a protocolos de arquivo padrão. Exemplos:
Aprendizado de máquina: alimentação de dados de treinamento para clusters de GPU usando E/S de arquivo padrão.
Análise de logs: agregando logs de milhares de fontes.
Sistemas avançados de assistência ao driver (ADAS) – fluxos de trabalho do ADAS produzem petabytes de dados sequenciais do sensor, como nuvens de ponto LiDAR e feeds de câmera de alta resolução, que devem ser ingeridos com eficiência e analisados em escala para simulação e treinamento de modelo. Exemplo:
- Armazenamento de varreduras brutas de LiDAR e fluxos de vídeo de múltiplas câmeras provenientes de veículos de teste autônomos usando NFS 3.0, seguido pela execução de simulações de reprodução em larga escala em milhares de nós de computação para validar algoritmos de percepção.
Mídia & Entretenimento – As fazendas de renderização precisam de acesso eficiente a grandes bibliotecas de ativos. O NFS 3.0 sobre blob fornece uma interface de arquivo para ferramentas legadas de renderização que esperam caminhos de arquivo. Exemplos:
Renderização de vídeo: nós distribuídos processando recursos de origem.
Transcodificação: convertendo arquivos de vídeo brutos grandes em formatos de streaming.
Backup de Banco de Dados – Esse recurso oferece um destino NFS 3.0 econômico e de alta taxa de transferência sem conectores complexos ou instantâneos caros. Exemplos:
- O Oracle RMAN pode escrever peças de backup grandes diretamente para arquivamento de longo prazo e habilitar a restauração direta de qualquer VM linux montada em NFS.
Quando não usar o NFS 3.0 com o Armazenamento de Blobs
Evite compartilhamentos de arquivos de uso geral ou cargas de trabalho transacionais devido a características de armazenamento de objetos:
| Tipo de carga de trabalho | Motivo | Melhor alternativa |
|---|---|---|
| Bancos de dados transacionais | Requer bloqueio granular, latência de submissegundo e gravações aleatórias frequentes. | Discos Gerenciados ou Azure NetApp Files ou Azure Files |
| Edição de Arquivo no Local | A edição de arquivos força uma reescrita completa de blobs, o que torna as operações ineficientes. | Arquivos do Azure |
NFS 3.0 e o namespace hierárquico
O suporte do protocolo NFS 3.0 requer que os blobs sejam organizados em um namespace hierárquico. Ao criar uma conta de armazenamento, um namespace hierárquico poderá ser habilitado. A capacidade de usar esse namespace foi introduzida pelo Azure Data Lake Storage. Ele organiza os objetos (arquivos) em uma hierarquia de diretórios e subdiretórios da mesma forma que o sistema de arquivos no seu computador é organizado. O namespace hierárquico dimensiona linearmente e não prejudica a capacidade ou o desempenho dos dados. Protocolos diferentes se estendem do namespace hierárquico. O protocolo NFS 3.0 é um dos protocolos disponíveis.
Dados armazenados como blob de blocos
Quando o aplicativo faz uma solicitação usando o protocolo NFS 3.0, essa solicitação é convertida em uma combinação de operações de blob de blocos. Por exemplo, as solicitações de leitura RPC (chamada de procedimento remoto) do NFS 3.0 são convertidas em operação Get Blob. As solicitações RPC de gravação do NFS 3.0 são convertidas em uma combinação de Get Block List, Put Block e Put Block List.
Esses blobs são otimizados para processar com eficiência grandes quantidades de dados de leitura intensa. Eles são compostos de blocos e cada bloco é identificado por uma ID. Um blob de blocos pode incluir até 50.000 blocos. Cada bloco em um blob pode ter tamanho diferente, até o tamanho máximo permitido para a versão de serviço que sua conta usa.
Fluxo de trabalho geral: montar um contêiner de conta de armazenamento
Os clientes Linux podem montar um contêiner no Armazenamento de blobs de uma VM do Azure ou de um computador local. Para montar um contêiner de conta de armazenamento, você precisa fazer essas coisas.
Criar uma rede virtual (VNet) do Azure.
Configurar a segurança de rede.
Criar e configurar a conta de armazenamento que aceita tráfego somente da VNet.
Criar um contêiner na conta de armazenamento.
Montar o contêiner.
Para obter diretrizes passo a passo, consulte Montar o armazenamento de blobs usando o protocolo NFS 3.0.
Segurança de rede
O tráfego precisa ser originado de uma VNet. Essa rede virtual permite que os clientes se conectem com segurança à conta de armazenamento. A única maneira de proteger os dados na conta é usando uma VNet e outras configurações de segurança de rede. Qualquer outra ferramenta usada para proteger dados, incluindo autorização de chave de conta, segurança do Microsoft Entra e listas de controle de acesso (ACLs), não pode ser usada para autorizar uma solicitação NFS 3.0.
Para saber mais, consulte Recomendações de segurança de rede para o Armazenamento de blobs.
Conexões de rede com suporte
Um cliente pode se conectar por meio de um ponto de extremidade privado ou público e dos seguintes locais de rede:
A VNet configurada para a conta de armazenamento.
Neste artigo, vamos nos referir a essa VNet como a VNet primária. Para saber mais, consulte Permitir acesso em uma rede virtual.
Uma VNet emparelhada que esteja na mesma região que a VNet primária.
Será necessário configurar a conta de armazenamento para permitir o acesso a essa VNet emparelhada. Para saber mais, consulte Permitir acesso em uma rede virtual.
Uma rede local conectada à VNet primária usando o Gateway de VPN ou um Gateway de ExpressRoute.
Para saber mais, consulte Configurar o acesso em redes locais.
Uma rede local conectada a uma rede emparelhada.
Esse cenário pode ser feito usando-se o Gateway de VPN ou um Gateway de ExpressRoute junto com o Trânsito de gateway.
Importante
O protocolo NFS 3.0 usa as portas 111 e 2048. Se estiver se conectando de uma rede local, verifique se o cliente permite a comunicação de saída por essas portas. Se você concedeu acesso a VNets específicas, verifique se todos os grupos de segurança de rede associados a essas VNets não contêm regras de segurança que bloqueiam a comunicação de entrada nessas portas.
Limitações e problemas conhecidos
Consulte Problemas conhecidos para obter uma lista completa dos problemas e limitações da versão atual do suporte ao NFS 3.0.
Preços
Consulte o a página de preços do Armazenamento de Blobs do Azure para se informar sobre os custos de armazenamento de dados e de transações.
Confira também
- Montar o Armazenamento de Blobs usando o protocolo do Sistema de Arquivos de Rede (NFS) 3.0
- Considerações sobre o desempenho do NFS (sistema de arquivos de rede) 3.0 no Armazenamento de Blobs do Azure
- Comparar o acesso aos Arquivos do Azure, ao Armazenamento de Blobs e ao Azure NetApp Files com o NFS