Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: Analysis Services do SQL Server 2019 e posterior Azure Analysis Services Fabric/Power BI Premium
Analysis Services do SQL Server 2019 e posterior Azure Analysis Services Fabric/Power BI Premium
Os grupos de cálculo podem reduzir significativamente o número de medidas redundantes tendo padrões comuns de expressão de medida como itens de cálculo. Os grupos de cálculo têm suporte em modelos tabulares no nível de compatibilidade 1500 e superior. Isso inclui todos os modelos semânticos do Power BI.
Por exemplo, se você tiver 5 medidas e quiser criar uma versão do ano anterior para cada uma, use o mesmo padrão para cada uma com as mesmas funções DAX.
[Measure 1 Prior Year] = CALCULATE([Measure 1], PARALLELPERIOD('Date'[Date], -1, YEAR))
[Measure 2 Prior Year] = CALCULATE([Measure 2], PARALLELPERIOD('Date'[Date], -1, YEAR))
[Measure 3 Prior Year] = CALCULATE([Measure 3], PARALLELPERIOD('Date'[Date], -1, YEAR))
[Measure 4 Prior Year] = CALCULATE([Measure 4], PARALLELPERIOD('Date'[Date], -1, YEAR))
[Measure 5 Prior Year] = CALCULATE([Measure 5], PARALLELPERIOD('Date'[Date], -1, YEAR))
Em vez de criar cinco medidas adicionais, você pode usar o padrão em um item de cálculo com um espaço reservado, SELECTEDMEASURE aplicando a expressão a qualquer medida.
CALCULATE(SELECTEDMEASURE(), PARALLELPERIOD('Date'[Date], -1, YEAR))
O item de cálculo é aplicado quando você seleciona o item de cálculo em um filtro ou segmento de dados, ou o usa para agrupar os valores visualmente.
Criar um grupo de cálculo
Grupos de cálculo podem ser criados de várias maneiras.
Para criar um grupo de cálculo usando o modo de exibição de modelo do Power BI
Você pode criar um grupo de cálculo na exibição de modelo do Power BI Desktop ou ao editar um modelo semântico do Power BI no navegador.
- Editar o modelo semântico
- Selecione o botão na faixa de opções Grupo de Cálculo.
- O primeiro item de cálculo é criado para você.
- Renomeie e ajuste a expressão.
Você pode solicitar e criar mais itens de cálculo selecionando o nó Itens de Cálculo e usando o painel Propriedades. O menu de contexto do grupo de cálculo ou nó de itens de cálculo pode ser usado para criar novos grupos de cálculo. O menu de contexto de cada item de cálculo também tem opções para solicitá-los novamente.
Para obter mais informações, consulte Criar grupos de cálculo no Power BI.
Para criar um grupo de cálculo usando o modo de exibição TMDL do Power BI
Você pode criar um grupo de cálculo na linguagem de definição de modelo tabular ou no modo de exibição TMDL do Power BI Desktop. Edite o modelo semântico e use este script TMDL.
createOrReplace
table 'Calculation group'
calculationGroup
precedence: 1
calculationItem 'Calculation item' = SELECTEDMEASURE()
column 'Calculation group column'
dataType: string
summarizeBy: none
sourceColumn: Name
sortByColumn: Ordinal
annotation SummarizationSetBy = Automatic
column Ordinal
dataType: int64
formatString: 0
summarizeBy: sum
sourceColumn: Ordinal
annotation SummarizationSetBy = Automatic
Para criar um grupo de cálculo usando o Visual Studio
Há suporte para grupos de cálculo no Visual Studio com o Analysis Services Projects VSIX atualização 2.9.2 e posterior. Os grupos de cálculo também podem ser criados usando a TMSL (Tabular Model Scripting Language) ou o Editor tabular de software livre.
No Gerenciador de Modelos Tabular, clique com o botão direito do mouse em Grupos de Cálculo e clique em Novo Grupo de Cálculo. Por padrão, um novo grupo de cálculo tem uma única coluna e um único item de cálculo.
Use Propriedades para alterar o nome e insira uma descrição para o grupo de cálculo, coluna e item de cálculo padrão.
Para inserir uma expressão de fórmula DAX para o item de cálculo padrão, clique com o botão direito do mouse e clique em Editar Fórmula para abrir o Editor da DAX. Insira uma expressão válida.
Para adicionar mais itens de cálculo, clique com o botão direito do mouse em Itens de Cálculo e clique em Novo Item de Cálculo.
Para ordenar itens de cálculo
No Gerenciador de Modelos Tabular, clique com o botão direito do mouse em um grupo de cálculo e clique em Adicionar coluna.
Nomeie a coluna Ordinal (ou algo semelhante), insira uma descrição e defina a propriedade Hidden como True.
Para cada item de cálculo que você deseja ordenar, defina a propriedade Ordinal como um número positivo. Cada número é sequencial, por exemplo, um item de cálculo com uma propriedade Ordinal de 1 aparece primeiro, uma propriedade de 2 aparece em segundo e assim por diante. Os itens de cálculo com o -1 padrão não são incluídos na ordenação, mas aparecem antes dos itens ordenados em um relatório.
Benefícios
Os grupos de cálculo abordam um problema em modelos complexos em que pode haver uma proliferação de medidas redundantes usando os mesmos cálculos – mais comuns com cálculos de inteligência de tempo. Por exemplo, um analista de vendas deseja ver os totais de vendas e pedidos desde o início do mês (MTD), desde o início do trimestre (QTD), desde o início do ano (YTD), pedidos desde o início do ano anterior (PY) e assim por diante. O modelador de dados precisa criar medidas separadas para cada cálculo, o que pode levar a dezenas de medidas. Para o usuário, o resultado é ter que classificar o número de medidas e aplicá-las individualmente ao relatório.
Vamos primeiro examinar como os grupos de cálculo aparecem para os usuários em uma ferramenta de relatório como o Power BI. Em seguida, examinaremos o que compõe um grupo de cálculo e como eles são criados em um modelo.
Os grupos de cálculo são mostrados no relatório de clientes como uma tabela com uma única coluna. A coluna não é como uma coluna ou dimensão típica, em vez disso, representa um ou mais cálculos reutilizáveis ou itens de cálculo que podem ser aplicados a qualquer medida já adicionada ao filtro Valores para uma visualização.
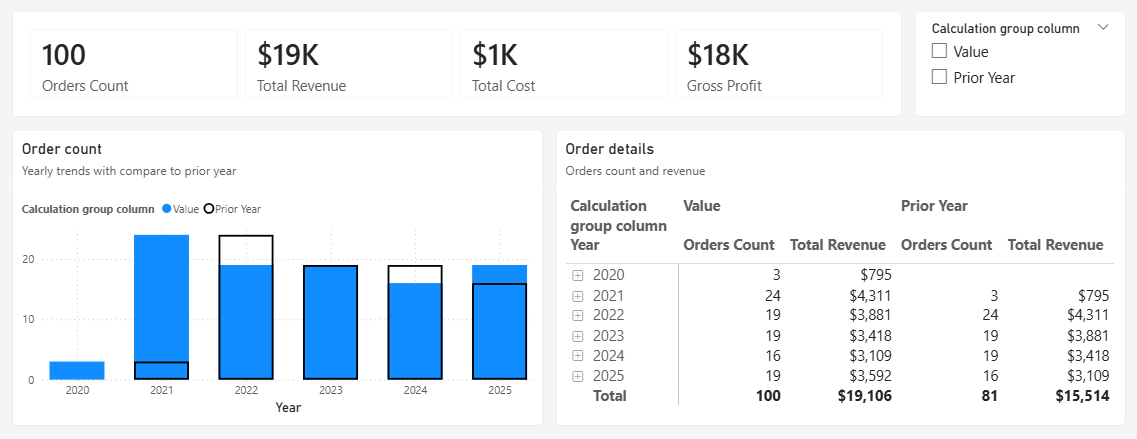
Na animação a seguir, um usuário está analisando dados de vendas para os anos de 2012 e 2013. Antes de aplicar um grupo de cálculo, a medida base comum Vendas calcula uma soma do total de vendas para cada mês. Em seguida, o usuário deseja aplicar cálculos de inteligência de tempo para obter totais de vendas de mês a data, trimestre a data, ano a ano e assim por diante. Sem grupos de cálculo, o usuário teria que selecionar medidas de inteligência de tempo individuais.
Com um grupo de cálculo, neste exemplo chamado Inteligência de Tempo, quando o usuário arrasta o item de Cálculo de Tempo para a área de filtro Colunas , cada item de cálculo aparece como uma coluna separada. Os valores de cada linha são calculados a partir da medida base, Sales.
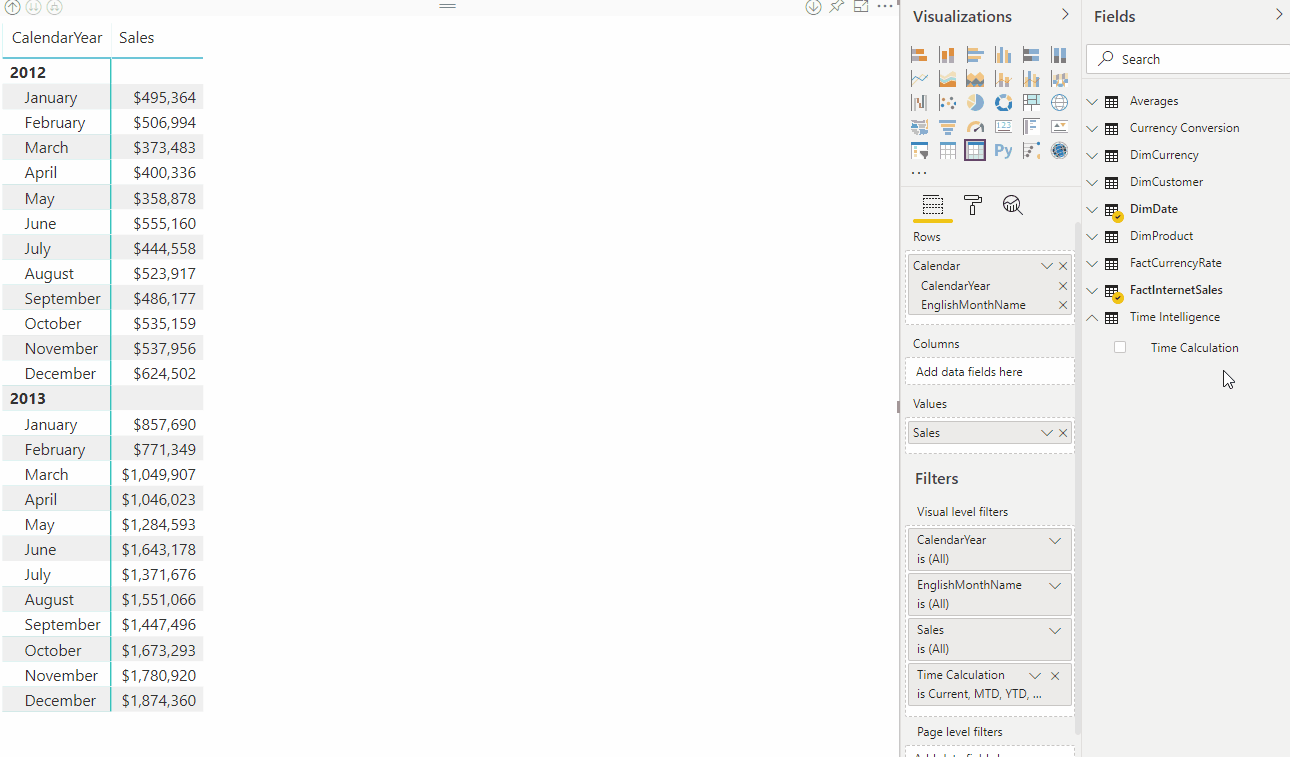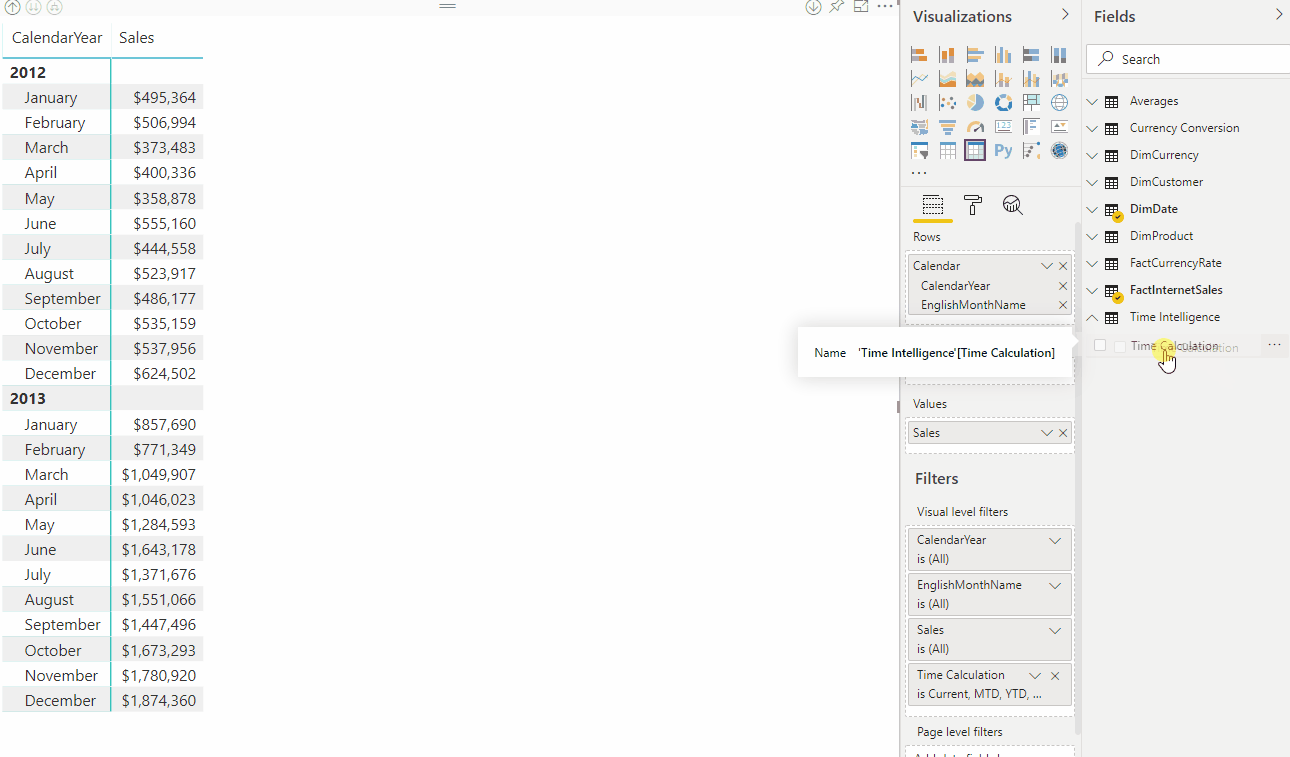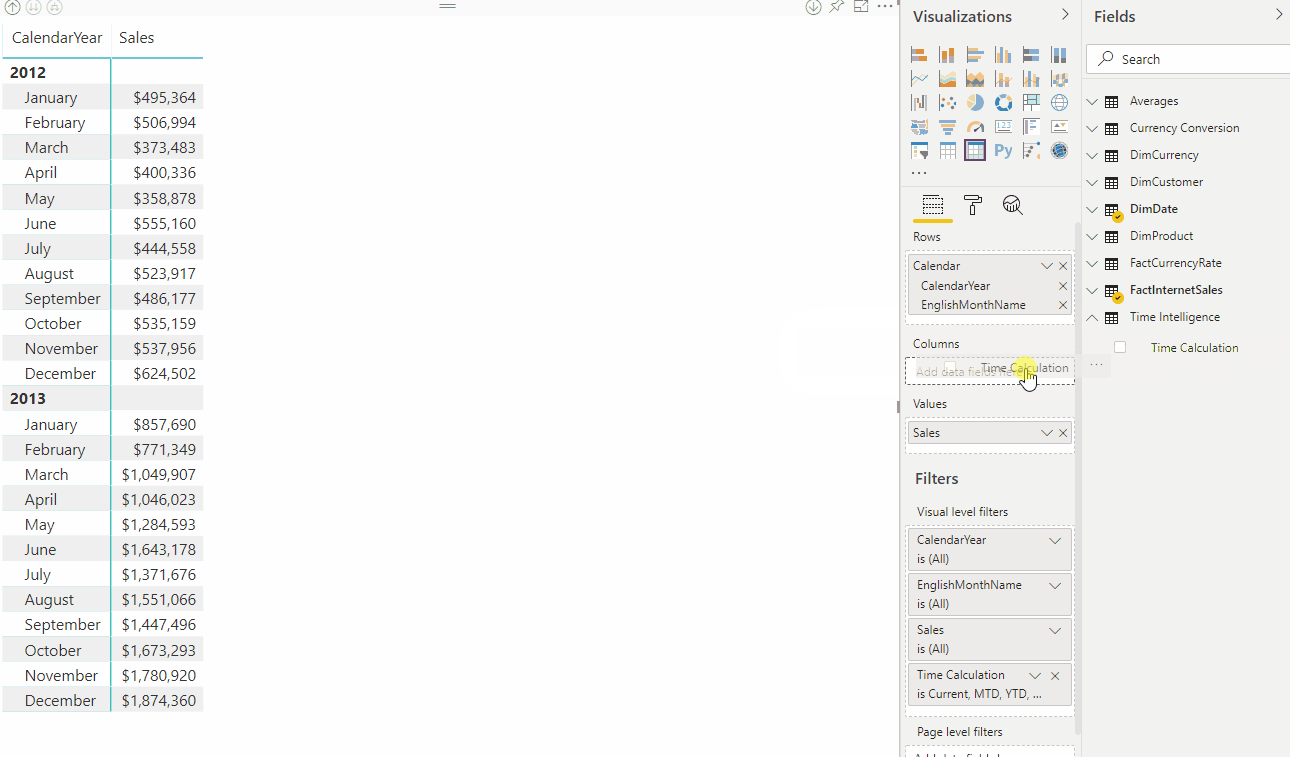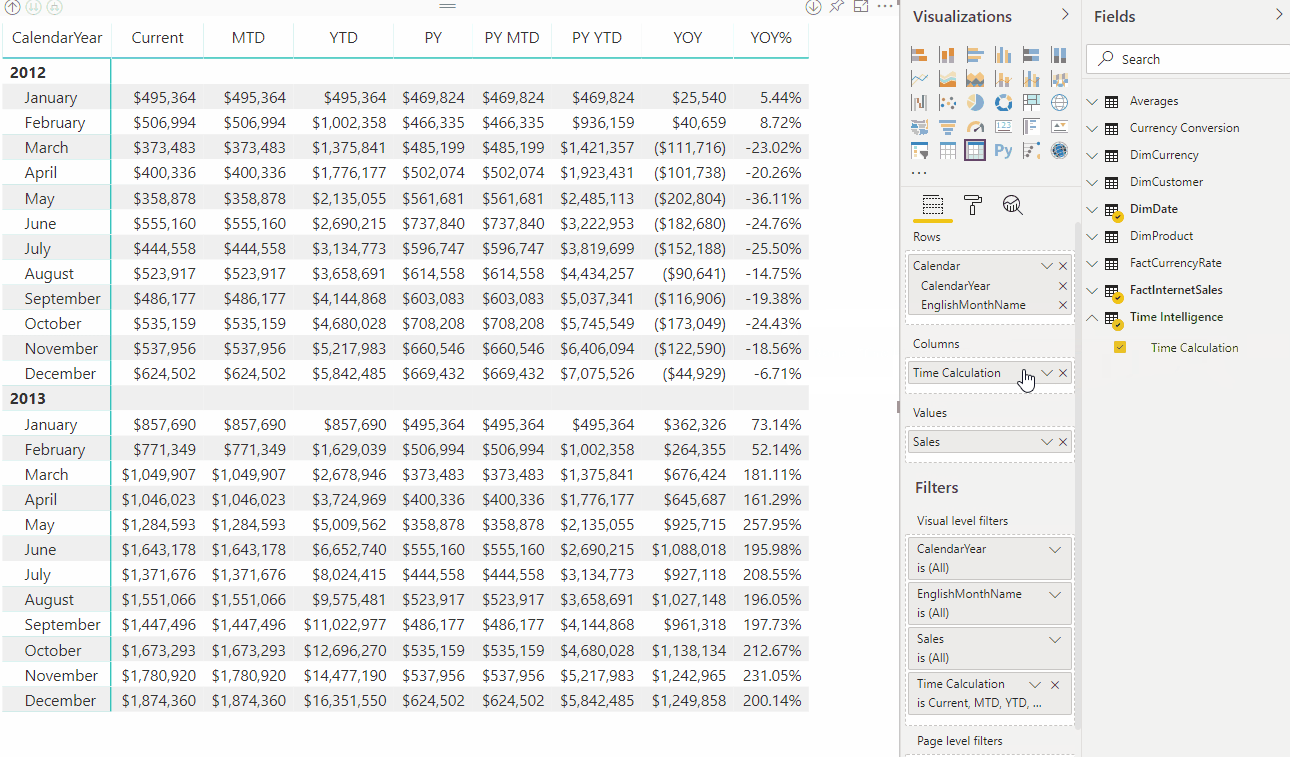
Os grupos de cálculo funcionam com medidas DAX explícitas. Neste exemplo, Sales é uma medida explícita já criada no modelo. Os grupos de cálculo não funcionam com medidas DAX implícitas. Por exemplo, nas medidas implícitas do Power BI são criadas quando um usuário arrasta colunas para visuais para exibir valores agregados, sem criar uma medida explícita. Neste momento, o Power BI gera DAX para medidas implícitas escritas como cálculos DAX embutidos , o que significa que medidas implícitas não podem funcionar com grupos de cálculo. Uma nova propriedade de modelo visível no TOM (Modelo de Objeto Tabular) foi introduzida, DiscourageImplicitMeasures. Atualmente, para criar grupos de cálculo, essa propriedade deve ser definida como true. Quando definido como true, o Power BI Desktop no modo Live Connect desabilita a criação de medidas implícitas.
Os grupos de cálculo também dão suporte a consultas MDX (Expressões de Dados Multidimensionais). Isso significa que os usuários do Microsoft Excel, que consultam modelos de dados tabulares usando MDX, podem aproveitar ao máximo os grupos de cálculo em tabelas dinâmicas e gráficos da planilha.
Como eles funcionam
Agora que você viu como os grupos de cálculo beneficiam os usuários, vamos examinar como o exemplo de grupo de cálculo do Time Intelligence mostrado é criado.
Antes de entrarmos em detalhes, vamos introduzir algumas novas funções DAX especificamente para grupos de cálculo:
SELECTEDMEASURE – Usado por expressões em itens de cálculo para fazer referência à medida que está atualmente em contexto. Neste exemplo, temos a medida Vendas.
SELECTEDMEASURENAME - Usado por expressões em itens de cálculo para determinar a medida que está no contexto pelo nome.
ISSELECTEDMEASURE – Usado em expressões de itens de cálculo para determinar qual medida especificada está no contexto de uma lista de medidas.
SELECTEDMEASUREFORMATSTRING - Usado por expressões para itens de cálculo para recuperar a cadeia de caracteres de formato da medida que está no contexto.
Exemplo de Inteligência de Tempo
Nome da tabela – Inteligência de Tempo
Nome da coluna – Cálculo de hora
Precedência – 20
Itens de cálculo do Time Intelligence
Atual
SELECTEDMEASURE()
MTD
CALCULATE(SELECTEDMEASURE(), DATESMTD(DimDate[Date]))
QTD
CALCULATE(SELECTEDMEASURE(), DATESQTD(DimDate[Date]))
YTD
CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date]))
PY
CALCULATE(SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date]))
PY MTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "MTD"
)
PY QTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "QTD"
)
PY YTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
YOY
SELECTEDMEASURE() -
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation] = "PY"
)
YOY%
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
Consulta de Inteligência Temporal
Para testar esse grupo de cálculo, execute a consulta DAX a seguir. Observação: MTD, YOY e YOY% são omitidos deste exemplo de consulta. No Power BI, use o modo de exibição de consulta DAX para executar a consulta.
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
DimDate[CalendarYear],
DimDate[EnglishMonthName],
"Current", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "Current" ),
"QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "QTD" ),
"YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "YTD" ),
"PY", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY" ),
"PY QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY QTD" ),
"PY YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY YTD" )
),
DimDate[CalendarYear] IN { 2012, 2013 }
)
Retorno da consulta do Time Intelligence
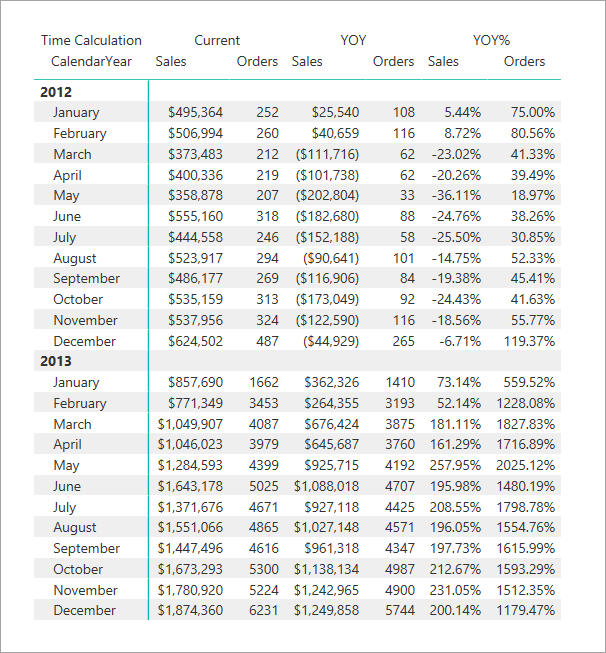
A tabela de retorno mostra cálculos para cada item de cálculo aplicado. Por exemplo, veja a QTD para março de 2012 é a soma de janeiro, fevereiro e março de 2012.

Cadeias de caracteres de formato dinâmico
Cadeias de caracteres de formato dinâmico com grupos de cálculo permitem a aplicação condicional de cadeias de caracteres de formato para medidas sem forçá-las a retornar cadeias de caracteres.
Os modelos de tabela dão suporte à formatação dinâmica de medidas usando a função FORMAT do DAX. No entanto, a função FORMAT tem a desvantagem de retornar uma cadeia de caracteres, forçando medidas que, de outra forma, seriam numéricas a serem retornadas como uma cadeia de caracteres. Isso pode ter algumas limitações, como não funcionar com a maioria dos visuais do Power BI dependendo de valores numéricos, como gráficos.
No Power BI, as cadeias de caracteres de formato dinâmico para medidas também permitem a aplicação condicional de cadeias de caracteres de formato a uma medida específica sem forçá-las a retornar uma cadeia de caracteres e sem o uso de grupos de cálculo. Para saber mais, confira cadeias de caracteres de formato dinâmico para obter medidas.
Cadeias de caracteres de formato dinâmico para inteligência de tempo
Se examinarmos o exemplo de Inteligência de Tempo mostrado acima, todos os itens de cálculo, exceto YOY% devem usar o formato da medida atual no contexto. Por exemplo, o YTD calculado na medida base de vendas deve ser moeda. Se esse fosse um grupo de cálculo para algo como uma medida base orders, o formato seria numérico. YOY%, no entanto, deve ser um percentual independentemente do formato da medida base.
Para YOY%, podemos substituir a cadeia de caracteres de formato definindo a propriedade de expressão de cadeia de caracteres de formato como 0,00%;-0,00%;0,00%. Para saber mais sobre as propriedades de expressão de cadeia de caracteres de formato, consulte Propriedades da célula MDX – FORMAT STRING Contents.
Neste visual de matriz no Power BI, você verá Sales Current/YOY e Orders Current/YOY manterem suas respectivas cadeias de caracteres de formato de medida base. Vendas YOY% e pedidos YOY%, no entanto, substitui a cadeia de caracteres de formato para usar o formato de porcentagem .
Cadeias de caracteres de formato dinâmico para conversão de moeda
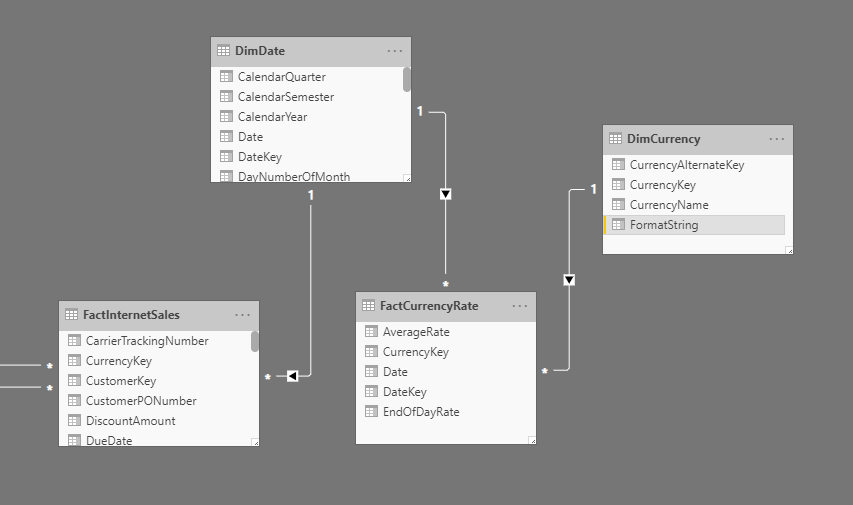
Cadeias de caracteres de formato dinâmico fornecem conversão de moeda fácil. Considere o seguinte modelo de dados do Adventure Works. Isso é modelado para conversão de moeda um-para-muitos, como definido pelos tipos de conversão.
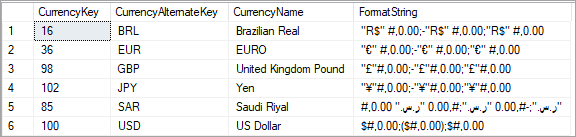
Uma coluna FormatString é adicionada à tabela DimCurrency e preenchida com cadeias de caracteres de formato para as respectivas moedas.
Para este exemplo, o seguinte grupo de cálculo é definido como:
Exemplo de conversão de moeda
Nome da tabela – Conversão de moeda
Nome da coluna – Cálculo de conversão
Precedência – 5
Itens de cálculo para conversão de moeda
Sem conversão
SELECTEDMEASURE()
Moeda Convertida
IF(
//Check one currency in context & not US Dollar, which is the pivot currency:
SELECTEDVALUE( DimCurrency[CurrencyName], "US Dollar" ) = "US Dollar",
SELECTEDMEASURE(),
SUMX(
VALUES(DimDate[Date]),
CALCULATE( DIVIDE( SELECTEDMEASURE(), MAX(FactCurrencyRate[EndOfDayRate]) ) )
)
)
Formatar expressão de cadeia de caracteres
SELECTEDVALUE(
DimCurrency[FormatString],
SELECTEDMEASUREFORMATSTRING()
)
Observação
Expressões de seleção para grupos de cálculo podem ser usadas para implementar a conversão automática de moeda em grupos de cálculo, removendo a necessidade de ter dois itens de cálculo separados.
A expressão de string de formato deve retornar uma string escalar. Ele usa a nova função SELECTEDMEASUREFORMATSTRING para reverter para a cadeia de caracteres de formato de medida base se houver várias moedas no contexto de filtro.
A animação a seguir mostra a conversão de moeda de formato dinâmico da medida Vendas em um relatório.
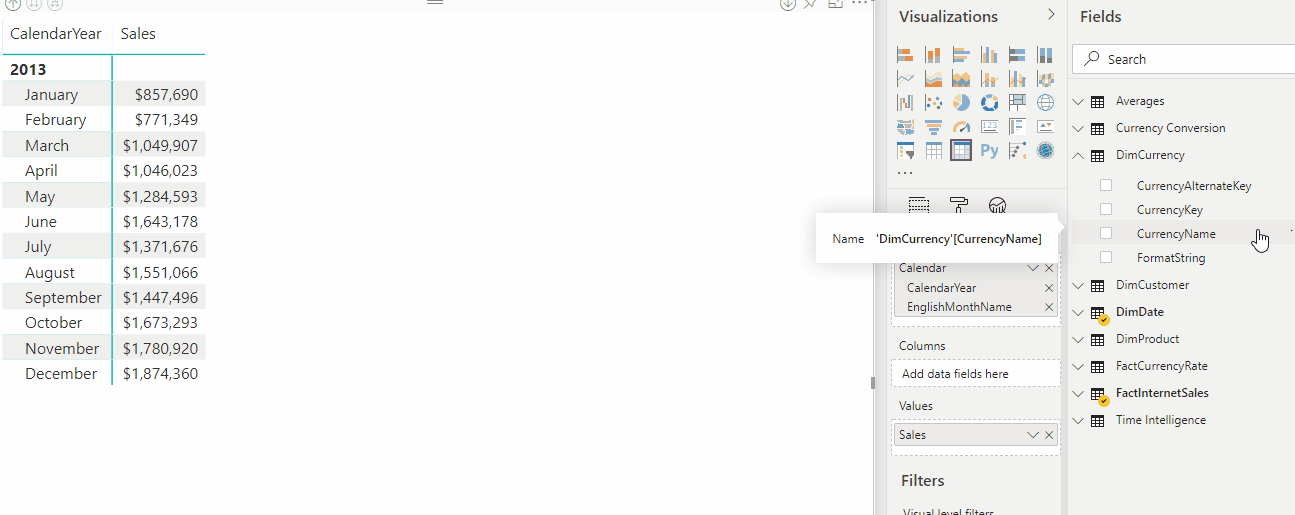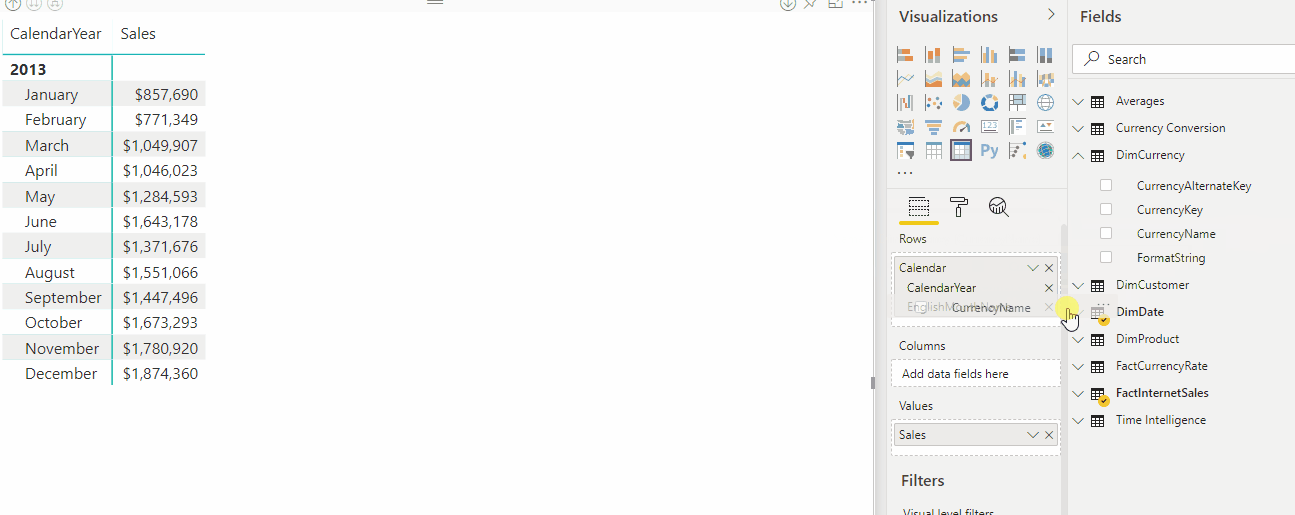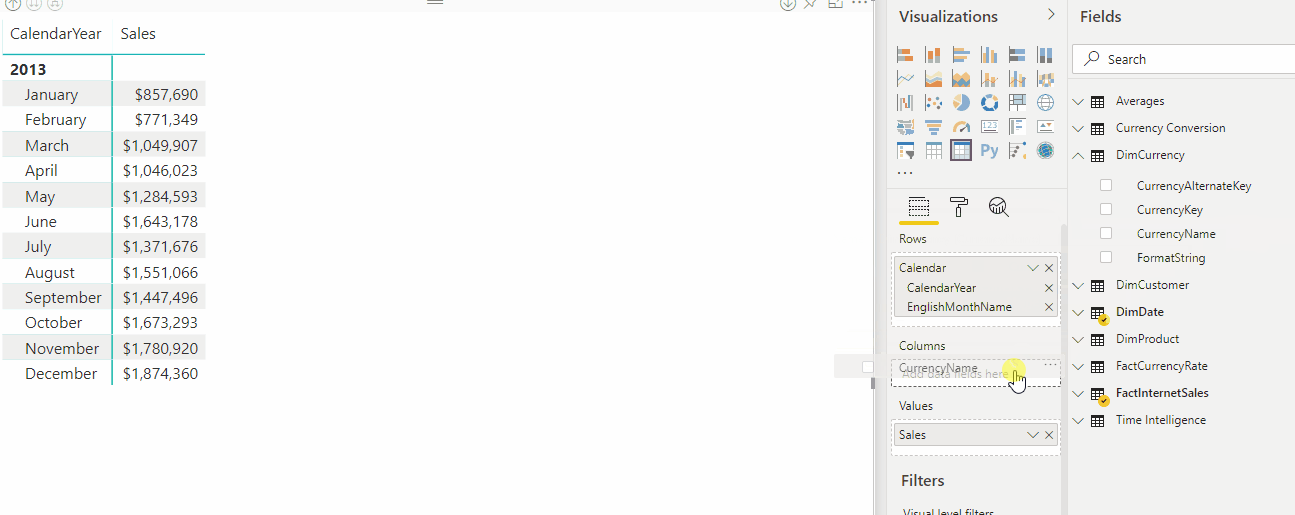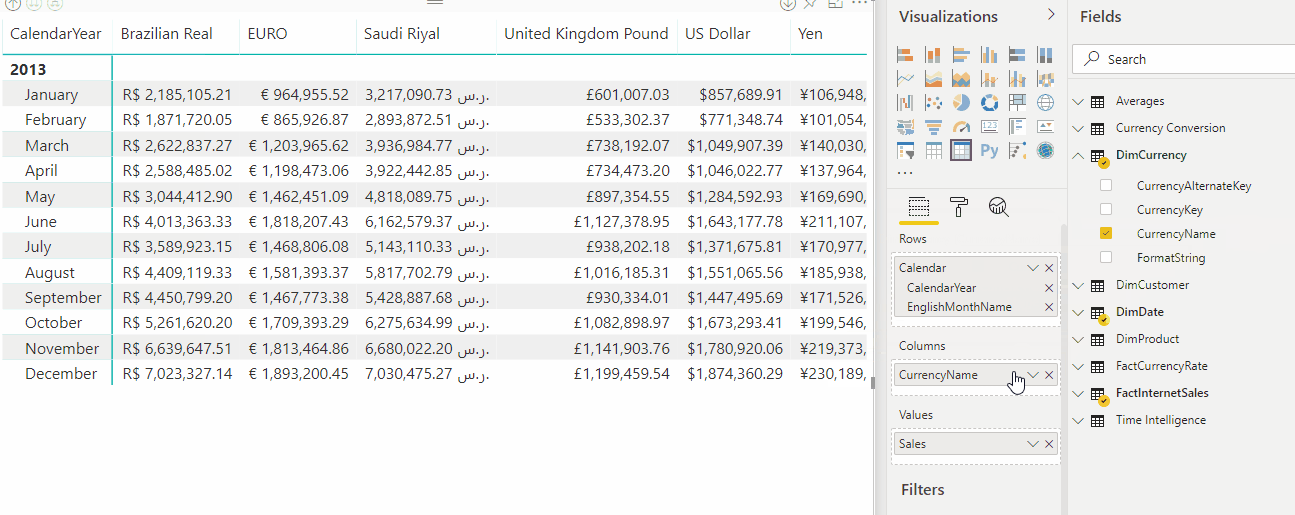
Expressões de seleção
As expressões de seleção são propriedades opcionais definidas para um grupo de cálculo. Há dois tipos de expressões de seleção:
-
multipleOrEmptySelectionExpression. Essa expressão de seleção é aplicada quando:
- vários itens de cálculo foram selecionados,
- um item de cálculo não existente foi selecionado ou
- uma seleção conflitante foi feita.
- noSelectionExpression. Essa expressão de seleção é aplicada quando o grupo de cálculo não é filtrado.
Ambas as expressões de seleção também possuem uma expressão de cadeia de caracteres de formato dinâmico formatStringDefinition.
Em resumo, em um grupo de cálculo, o seguinte pode ser definido, por exemplo, usando TMDL:
...
table Scenarios
calculationGroup
...
multipleOrEmptySelectionExpression = "replace with the DAX formula"
formatStringDefinition = "replace with the DAX formula"
noSelectionExpression= "replace with the DAX formula"
formatStringDefinition = "replace with the DAX formula"
...
Observação
Essas expressões, se especificadas, só são aplicadas às situações específicas mencionadas. As seleções de um único item de cálculo não são afetadas por essas expressões.
Aqui está uma visão geral dessas expressões e seu comportamento padrão, se não for especificado:
| Tipo de seleção | Expressão de seleção não definida (padrão) | Expressão de seleção definida |
|---|---|---|
| Seleção única | A seleção é aplicada | A seleção é aplicada |
| Seleção múltipla | O grupo de cálculo não é filtrado | Retornar resultado da avaliação de multipleOrEmptySelectionExpression |
| Seleção vazia | O grupo de cálculo não é filtrado | Retornar resultado da avaliação de multipleOrEmptySelectionExpression |
| Nenhuma seleção | O grupo de cálculo não é filtrado | Resultado de retorno da avaliação de noSelectionExpression |
Observação
Use a configuração selectionExpressionBehavior do modelo para influenciar ainda mais o que um grupo de cálculo retorna quando as expressões de seleção não são definidas.
Configuração do modelo SelectionExpressionBehavior
Os modelos têm uma configuração selectionExpressionBehavior que permite um controle adicional sobre como os grupos de cálculo nesse modelo se comportam. Essa configuração aceita os três valores a seguir:
- Automático. Esse é o valor padrão e é igual ao nãovisual. Isso garante que seus modelos existentes não alterem o comportamento. Modelos que ultrapassarem um nível futuro de compatibilidade definido como automático usarão visual para substituir. Haverá um anúncio nesse momento.
-
Não visual. Se o grupo de cálculo não definir uma expressão multipleOrEmptySelection , o grupo de cálculo retornará
SELECTEDMEASURE()e quando a medida for agrupada pelo grupo de cálculo, os valores subtotais serão ocultos. -
Visual. Se o grupo de cálculo não definir uma expressão multipleOrEmptySelection , o grupo de cálculo retornará
BLANK(). Ao agrupar pelo grupo de cálculo, os valores de subtotal são determinados avaliando a medida selecionada no contexto do grupo de cálculo.
Use o TMDL para definir a propriedade em seu modelo:
createOrReplace
model Model
...
selectionExpressionBehavior: automatic | nonvisual | visual
...
Seleção múltipla ou vazia
Se várias seleções no mesmo grupo de cálculo forem feitas, o grupo de cálculo avaliará e retornará o resultado de multipleOrEmptySelectionExpression, se definido. Se essa expressão não tiver sido definida, o grupo de cálculo retornará o seguinte resultado se a configuração selectionExpressionBehavior do modelo estiver definida como automática ou nãovisual:
SELECTEDMEASURE()
Se a configuração selectionExpressionBehavior do modelo estiver definida como visual, o grupo de cálculo retornará:
BLANK()
Por exemplo, vamos examinar um grupo de cálculo chamado MyCalcGroup que tem um multipleOrEmptySelectionExpression configurado da seguinte maneira:
IF (
ISFILTERED ( 'MyCalcGroup' ),
"Filters: "
& CONCATENATEX (
FILTERS ( 'MyCalcGroup'[Name] ),
'MyCalcGroup'[Name],
", "
)
)
Agora, imagine a seguinte seleção no grupo de cálculo:
EVALUATE
{
CALCULATE (
[MyMeasure],
'MyCalcGroup'[Name] = "item1" || 'MyCalcGroup'[Name] = "item2"
)
}
Aqui, selecionamos dois itens no grupo de cálculo, "item1" e "item2". São várias seleções e, portanto, multipleOrEmptySelectionExpression é avaliado e retorna o seguinte resultado: "Filtros: item1, item2".
Em seguida, faça a seguinte seleção no grupo de cálculo:
EVALUATE
{
CALCULATE (
[MyMeasure],
'MyCalcGroup'[Name] = "item4" -- item4 does not exists
)
}
Este é um exemplo de uma seleção vazia, pois "item4" não existe nesse grupo de cálculo. Portanto, multipleOrEmptySelectionExpression é avaliado e retorna o seguinte resultado: "Filtros: ".
Nenhuma seleção
O noSelectionExpression em um grupo de cálculo será aplicado se o grupo de cálculo não tiver sido filtrado. Isso é usado principalmente para executar ações padrão sem a necessidade de o usuário tomar medidas enquanto ainda oferece flexibilidade ao usuário para substituir a ação padrão. Por exemplo, vamos examinar a conversão automática de moeda com Dólar americano como a moeda dinâmica central.
Podemos configurar um grupo de cálculo com o seguinte "noSelectionExpression":
IF (
//Check one currency in context & not US Dollar, which is the pivot currency:
SELECTEDVALUE (
DimCurrency[CurrencyName],
"US Dollar"
) = "US Dollar",
SELECTEDMEASURE (),
SUMX (
VALUES ( DimDate[DateKey] ),
CALCULATE (
DIVIDE ( SELECTEDMEASURE (), MAX ( FactCurrencyRate[EndOfDayRate] ) )
)
)
)
Também definiremos um formatStringDefinition para esta expressão:
SELECTEDVALUE(
DimCurrency[FormatString],
SELECTEDMEASUREFORMATSTRING()
)
Agora, se nenhuma moeda for selecionada, todas as moedas serão convertidas automaticamente na moeda dinâmica (Dólar americano), conforme necessário. Além disso, você ainda pode escolher outra moeda para converter nessa moeda sem precisar alternar itens de cálculo, como teria que fazer sem o noSelectionExpression.
Precedência
Precedência é uma propriedade definida para um grupo de cálculo. Ele especifica a ordem em que os grupos de cálculo são combinados com a medida subjacente ao usar SELECTEDMEASURE() no item de cálculo.
Exemplo de precedência
Vamos examinar um exemplo simples. Esse modelo tem uma medida com um valor especificado de 10 e dois grupos de cálculo, cada um com um único item de cálculo. Vamos aplicar os itens de cálculo de ambos os grupos de cálculo à medida. É assim que o configuramos:
'Measure group'[Measure] = 10
O primeiro grupo de cálculo é 'Calc Group 1 (Precedence 100)' e o item de cálculo é 'Calc item (Plus 2)':
'Calc Group 1 (Precedence 100)'[Calc item (Plus 2)] = SELECTEDMEASURE() + 2
O segundo grupo de cálculo é 'Calc Group 2 (Precedence 200)' e o item de cálculo é 'Calc item (Times 2)':
'Calc Group 2 (Precedence 200)'[Calc item (Times 2)] = SELECTEDMEASURE() * 2
Você pode ver que o grupo de cálculo 1 tem um valor de precedência de 100 e o grupo de cálculo 2 tem um valor de precedência de 200.
Usando o SSMS (SQL Server Management Studio) ou uma ferramenta externa com recursos de leitura/gravação XMLA , como o Editor de Tabela de software livre, você pode usar scripts XMLA para criar grupos de cálculo e definir os valores de precedência. Aqui, adicionamos "Calc group 1 (Precedence 100)":
{
"createOrReplace": {
"object": {
"database": "CHANGE TO YOUR DATASET NAME",
"table": "Calc group 1 (Precedence 100)"
},
"table": {
"name": "Calc group 1 (Precedence 100)",
"calculationGroup": {
"precedence": 100,
"calculationItems": [
{
"name": "Calc item (Plus 2)",
"expression": "SELECTEDMEASURE() + 2",
}
]
},
"columns": [
{
"name": "Calc group 1 (Precedence 100)",
"dataType": "string",
"sourceColumn": "Name",
"sortByColumn": "Ordinal",
"summarizeBy": "none",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
},
{
"name": "Ordinal",
"dataType": "int64",
"isHidden": true,
"sourceColumn": "Ordinal",
"summarizeBy": "sum",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
}
],
"partitions": [
{
"name": "Partition",
"mode": "import",
"source": {
"type": "calculationGroup"
}
}
]
}
}
}
E este script adiciona "Calc group 2 (Precedence 200)":
{
"createOrReplace": {
"object": {
"database": "CHANGE TO YOUR DATASET NAME",
"table": "Calc group 2 (Precedence 200)"
},
"table": {
"name": "Calc group 2 (Precedence 200)",
"calculationGroup": {
"precedence": 200,
"calculationItems": [
{
"name": "Calc item (Times 2)",
"expression": "SELECTEDMEASURE() * 2"
}
]
},
"columns": [
{
"name": "Calc group 2 (Precedence 200)",
"dataType": "string",
"sourceColumn": "Name",
"sortByColumn": "Ordinal",
"summarizeBy": "none",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
},
{
"name": "Ordinal",
"dataType": "int64",
"isHidden": true,
"sourceColumn": "Ordinal",
"summarizeBy": "sum",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
}
],
"partitions": [
{
"name": "Partition",
"mode": "import",
"source": {
"type": "calculationGroup"
}
}
]
}
}
}
No Power BI Desktop, temos um visual de cartão mostrando a medida e uma segmentação de dados para cada um dos grupos de cálculo na exibição do relatório:
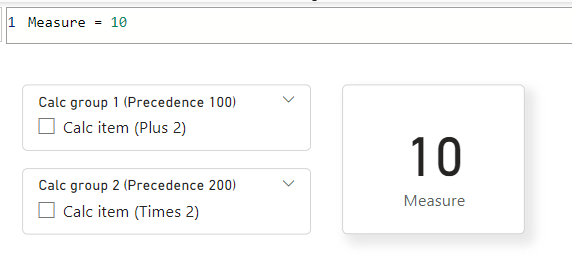
Quando ambas as segmentações são selecionadas, precisamos combinar as expressões DAX. Para fazer isso, começamos com o item de cálculo de precedência mais alto, 200, e, em seguida, substituímos o argumento SELECTEDMEASURE() pelo próximo mais alto, 100.
Portanto, nossa expressão DAX do item de cálculo de precedência mais alta é:
SELECTEDMEASURE() * 2
E nossa segunda expressão DAX do item de cálculo de precedência mais alta é:
SELECTEDMEASURE() + 2
Agora eles são combinados substituindo a parte SELECTEDMEASURE() do item de cálculo de precedência mais alta pelo próximo item de cálculo de precedência mais alta, assim:
( SELECTEDMEASURE() + 2 ) * 2
Em seguida, se houver mais itens de cálculo, continuaremos até chegarmos à medida subjacente. Há apenas dois grupos de cálculo nesse modelo, portanto, agora substituímos SELECTEDMEASURE() pela própria medida, desta forma:
( ( [Measure] ) + 2 ) * 2
Como a medida é Measure = 10, isso é o mesmo que:
( ( 10 ) + 2 ) * 2
Quando não há mais argumentos SELECTEDMEASURE(), a expressão DAX combinada é avaliada:
( ( 10 ) + 2 ) * 2 = 24
No Power BI Desktop, quando ambos os grupos de cálculo são aplicados com um filtro, a saída da medida fica assim:
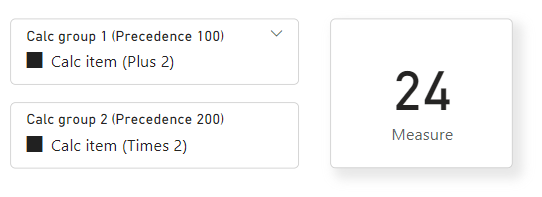
Mas tenha em mente que a combinação está aninhada de maneira que a saída não será 10 + 2 * 2 = 14, como você vê aqui:
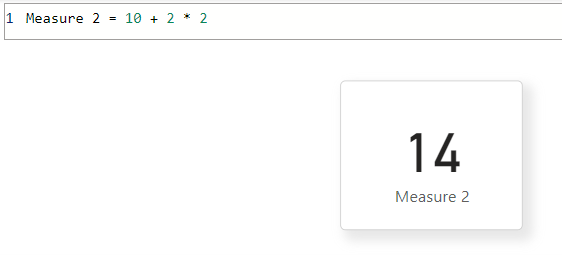
Para transformações simples, a avaliação é de precedência inferior a superior. Por exemplo, 10 tem 2 adicionados e, em seguida, é multiplicado por 2. No DAX, há funções como CALCULATE que aplicam filtros ou alterações de contexto a expressões internas. Nesse caso, a precedência superior altera uma expressão de precedência inferior.
A precedência também determina qual cadeia de caracteres de formato dinâmico é aplicada à expressão DAX combinada para cada medida. A cadeia de caracteres de formato dinâmico do grupo de cálculo de precedência mais alta é a única aplicada. Se uma medida em si tiver uma cadeia de caracteres de formato dinâmico, ela será considerada como uma precedência inferior a qualquer grupo de cálculo no modelo.
Exemplo de precedência com médias
Vamos examinar outro exemplo usando o mesmo modelo, como mostrado no exemplo de inteligência temporal descrito anteriormente neste artigo. Mas, desta vez, vamos também adicionar um grupo de cálculo Médias . O grupo de cálculo de Médias inclui cálculos médios que são independentes das funções tradicionais de inteligência temporal, pois não alteram o contexto do filtro de data – apenas aplicam cálculos de média dentro desse contexto.
Neste exemplo, um cálculo médio diário é definido. Cálculos como barris médios de petróleo por dia são comuns em aplicações de petróleo e gás. Outros exemplos de negócios comuns incluem a média de vendas da loja no varejo.
Embora esses cálculos sejam calculados independentemente dos cálculos de inteligência temporal, pode muito bem haver um requisito para combiná-los. Por exemplo, um usuário pode querer ver barris de petróleo por dia YTD para exibir a taxa diária de petróleo do início do ano até a data atual. Nesse cenário, a precedência deve ser definida para itens de cálculo.
Nossas suposições são:
O nome da tabela é Médias.
O nome da coluna é Cálculo Médio.
A precedência é 10.
Itens de cálculo para médias
Sem Média
SELECTEDMEASURE()
Média Diária
DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate))
Aqui está um exemplo de uma tabela de consulta e retorno da DAX:
Consulta de médias
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
DimDate[CalendarYear],
DimDate[EnglishMonthName],
"Sales", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "Current",
'Averages'[Average Calculation] = "No Average"
),
"YTD", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "YTD",
'Averages'[Average Calculation] = "No Average"
),
"Daily Average", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "Current",
'Averages'[Average Calculation] = "Daily Average"
),
"YTD Daily Average", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "YTD",
'Averages'[Average Calculation] = "Daily Average"
)
),
DimDate[CalendarYear] = 2012
)
Médias de retorno de consulta
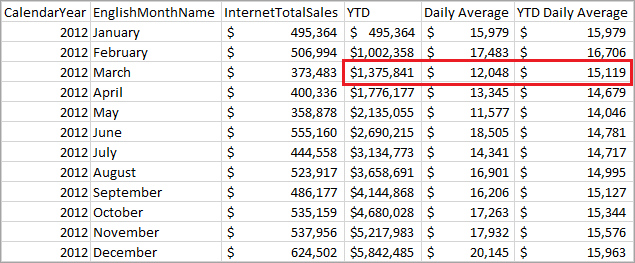
A tabela a seguir mostra como os valores de março de 2012 são calculados.
| Nome da coluna | Cálculo |
|---|---|
| Até a presente data | Soma das Vendas para Jan, Feb, Mar 2012 = 495.364 + 506.994 + 373.483 |
| Média Diária | Vendas para Mar 2012 divididas por # de dias em março = 373.483 / 31 |
| Média diária de YTD | YTD para Mar 2012 dividido por # de dias em janeiro, fevereiro e mar = 1.375.841 / (31 + 29 + 31) |
Aqui está a definição do item de cálculo YTD, aplicado com precedência de 20.
CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date]))
Aqui está a Média Diária, aplicada com uma precedência de 10.
DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate))
Como a precedência do grupo de cálculo Time Intelligence é maior que a do grupo de cálculo de Médias, ele é aplicado da forma mais ampla possível. O cálculo YTD Daily Average aplica YTD ao numerador e ao denominador (contagem de dias) do cálculo médio diário.
Isso é equivalente à seguinte expressão:
CALCULATE(DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate)), DATESYTD(DimDate[Date]))
Não essa expressão:
DIVIDE(CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date])), COUNTROWS(DimDate)))
Recursão lateral
No exemplo de Inteligência de Tempo acima, alguns dos itens de cálculo referem-se a outros no mesmo grupo de cálculo. Isso é chamado de recursão lateral. Por exemplo, o YOY% faz referência ao YOY e ao PY.
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
Nesse caso, ambas as expressões são avaliadas separadamente porque estão usando instruções de cálculo diferentes. Não há suporte para outros tipos de recursão.
Item de cálculo único no contexto de filtro
Em nosso exemplo do Time Intelligence, o item de cálculo do PY YTD tem uma única expressão de cálculo:
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
O argumento YTD para a função CALCULATE substitui o contexto de filtro para reutilizar a lógica já definida no item de cálculo YTD. Não é possível aplicar PY e YTD em uma única avaliação. Os grupos de cálculo só serão aplicados se um único item de cálculo do grupo de cálculo estiver no contexto de filtro.
Pedido
Por padrão, quando uma coluna de um grupo de cálculo é colocada em um relatório, os itens de cálculo são ordenados em ordem alfabética por nome. A ordem na qual os itens de cálculo aparecem em um relatório pode ser alterada especificando a propriedade Ordinal. Especificar a ordem do item de cálculo com a propriedade Ordinal não altera a precedência, a ordem na qual os itens de cálculo são avaliados. Ele também não altera a ordem na qual os itens de cálculo aparecem no Gerenciador de Modelos Tabulares.
Para especificar a propriedade ordinal para itens de cálculo, você deve adicionar uma segunda coluna ao grupo de cálculo. Ao contrário da coluna padrão em que o Tipo de Dados é Texto, uma segunda coluna usada para ordenar itens de cálculo tem um tipo de dados Número Inteiro. A única finalidade dessa coluna é especificar a ordem numérica na qual os itens de cálculo no grupo de cálculo são exibidos. Como essa coluna não fornece nenhum valor em um relatório, é melhor definir a propriedade Hidden como True.
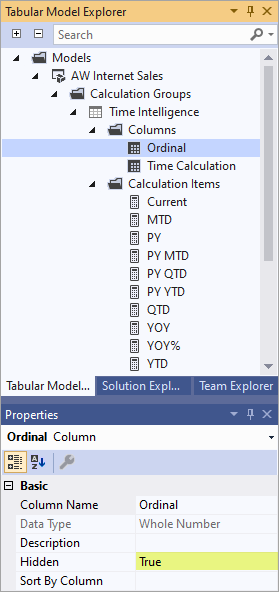
Depois que uma segunda coluna for adicionada ao grupo de cálculo, você poderá especificar o valor da propriedade Ordinal para os itens de cálculo que deseja solicitar.
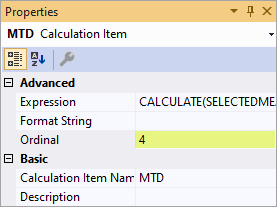
Para saber mais, confira Para ordenar itens de cálculo.
Considerações
As medidas do modelo são alteradas para o tipo de dados variant
Assim que um grupo de cálculo for adicionado a um modelo semântico, os relatórios do Power BI usarão o tipo de dados variant para todas as medidas. Se posteriormente, todos os grupos de cálculo forem removidos do modelo, as medidas serão retornadas para seus tipos de dados originais novamente.
Isso pode causar cadeias de caracteres de formato dinâmico para medidas ao usar uma medida para reutilização, mostrando um erro. Use a função FORMAT DAX para forçar a medida do tipo variant a ser reconhecida como um tipo de dado texto novamente.
FORMAT([Dynamic format string], "")
Como alternativa, você pode reutilizar sua expressão para strings de formato dinâmico com uma função definida pelo usuário do DAX.
Erro visual quando um item de cálculo aplica uma operação matemática em uma medida não numérica
Medidas não numéricas são comumente usadas para títulos dinâmicos em visuais e em cadeias de caracteres de formato dinâmico para medidas. O erro Não é possível converter valor... do tipo 'Texto' para o tipo 'Numérico' nos visuais afetados. A expressão do item de cálculo pode evitar isso adicionando uma verificação para ver se a medida é numérica antes de aplicar a operação matemática. Use o ISNUMERIC no item de cálculo.
Calculation item safe =
IF (
// Check the measure is numeric
ISNUMERIC( SELECTEDMEASURE() ),
SELECTEDMEASURE() * 2,
// Don't apply the calculation on a non-numeric measure
SELECTEDMEASURE()
)
Limitações
Não há suporte para o OLS (segurança no nível do objeto) definido nas tabelas de grupo de cálculo. No entanto, o OLS pode ser definido em outras tabelas no mesmo modelo. Se um item de cálculo se referir a um objeto protegido do OLS, um erro genérico será retornado.
Não há suporte para RLS (segurança em nível de linha). Defina RLS em tabelas no mesmo modelo, mas não nos grupos de cálculo em si, direta ou indiretamente.
Não há suporte para expressões de linhas de detalhes com grupos de cálculo.
No Power BI, visualizações de narrativa inteligente não têm suporte com grupos de cálculo.
Não há suporte para agregações de coluna implícitas no Power BI para modelos com grupos de cálculo. Atualmente, se a propriedade DiscourageImplicitMeasures estiver definida como false (padrão), as opções de agregação aparecerão, no entanto, elas não poderão ser aplicadas. Se DiscourageImplicitMeasures for definido como true, as opções de agregação não aparecerão.
Ao criar relatórios do Power BI usando o Live Connection, as cadeias de caracteres de formato dinâmico não são aplicadas a medidas de nível de relatório.
Consulte também
Criar grupos de cálculo no Power BIExibição de consulta DAXExibição TMDLCadeias de caracteres de formato dinâmico para medidasExplorador de modelos na exibição de modelo do Power BIDAX em modelos tabulares
Referência do DAX