Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste artigo, você aprenderá a medir quantitativamente e melhorar a precisão do modelo básico de conversão de fala em texto ou de seus próprios modelos personalizados. Áudio + dados de transcrição literal são necessários para testar a precisão. É preciso fornecer de 30 minutos a 5 horas de áudio representativo.
Importante
Durante o teste, o sistema realizará uma transcrição. É importante ter isso em mente, pois o preço varia de acordo com a oferta de serviço e o nível de assinatura. Sempre consulte os preços oficiais dos Serviços Cognitivos de IA do Azure para obter os detalhes mais recentes.
Criar um teste
É possível testar a precisão do modelo personalizado criando um teste. Um teste requer uma coleção de arquivos de áudio e suas transcrições correspondentes. Você pode comparar a precisão de um modelo personalizado com um modelo básico de conversão de fala em texto ou outro modelo personalizado. Depois de obter os resultados do teste, avalie a WER (taxa de erros de palavra) em comparação com os resultados do reconhecimento de fala.
Depois de carregar conjuntos de dados de treinamento e teste, você pode criar um teste.
Para testar seu modelo de fala personalizado ajustado, siga estas etapas:
Entre no portal da Fábrica de IA do Azure.
Selecione Ajuste fino no painel esquerdo e selecione Ajuste fino do Serviço de IA.
Selecione a tarefa de ajuste fino de fala personalizada (por nome do modelo) que você iniciou conforme descrito no artigo sobre como iniciar o ajuste fino de fala personalizada.
Selecione Testar modelos>+ Criar teste.
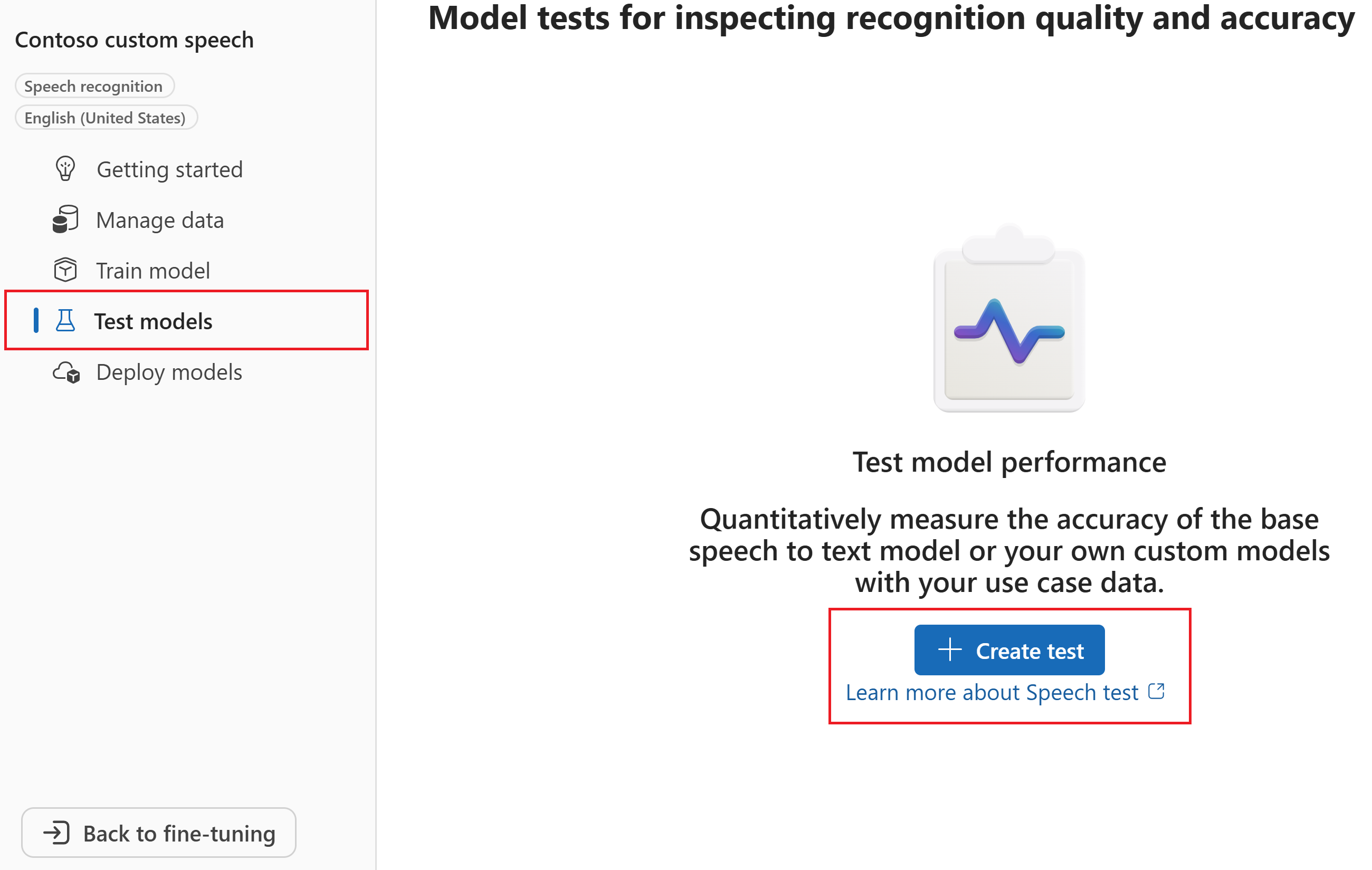
No assistente Criar um novo teste, selecione o tipo de teste. Para um teste de precisão (quantitativo), selecione Avaliar precisão (Áudio + dados de transcrição). Em seguida, selecione Avançar.
Selecione os dados que você deseja usar para teste. Em seguida, selecione Avançar.
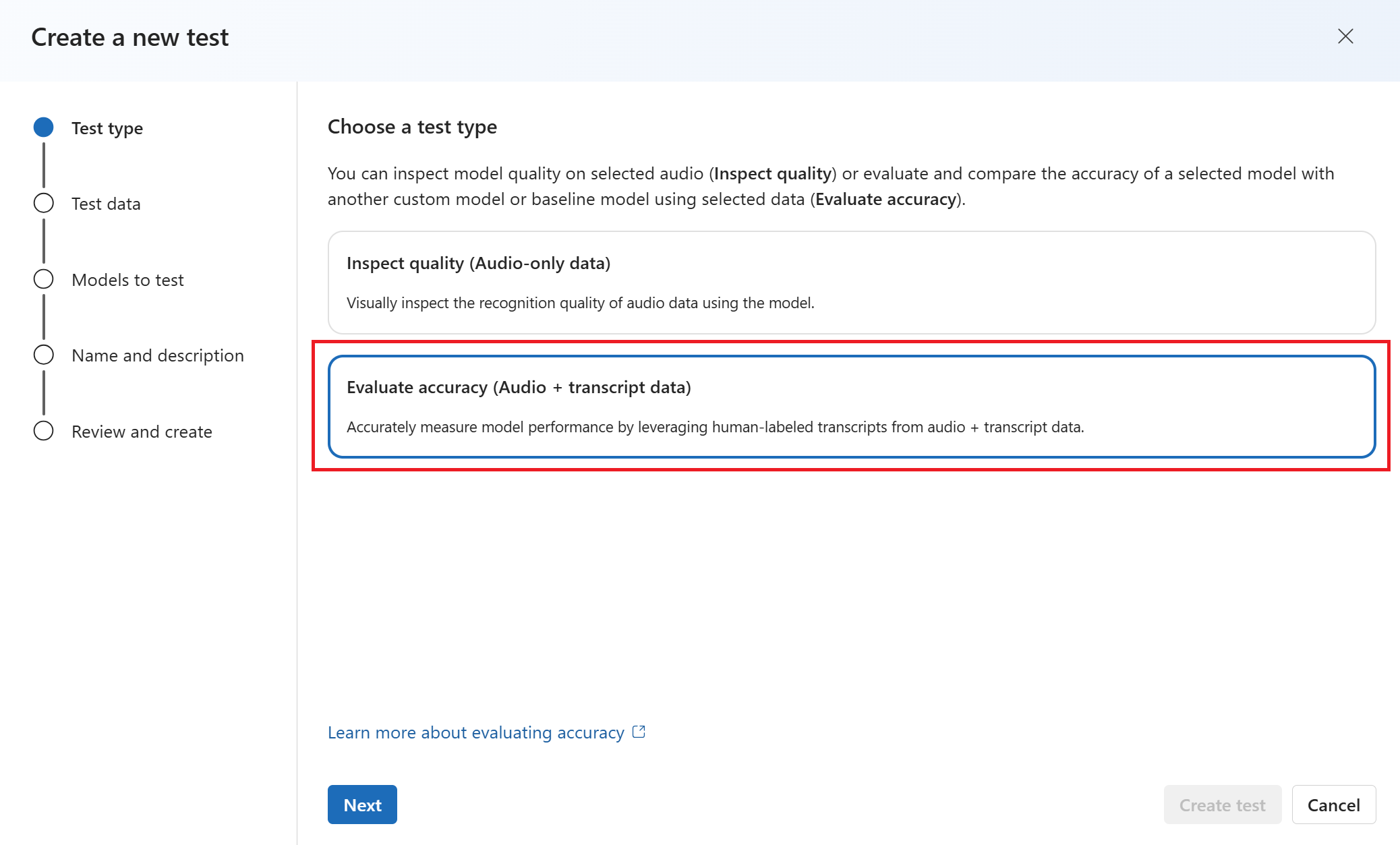
Selecione até dois modelos para avaliar e comparar a precisão. Neste exemplo, selecionamos o modelo que treinamos e o modelo base. Em seguida, selecione Avançar.
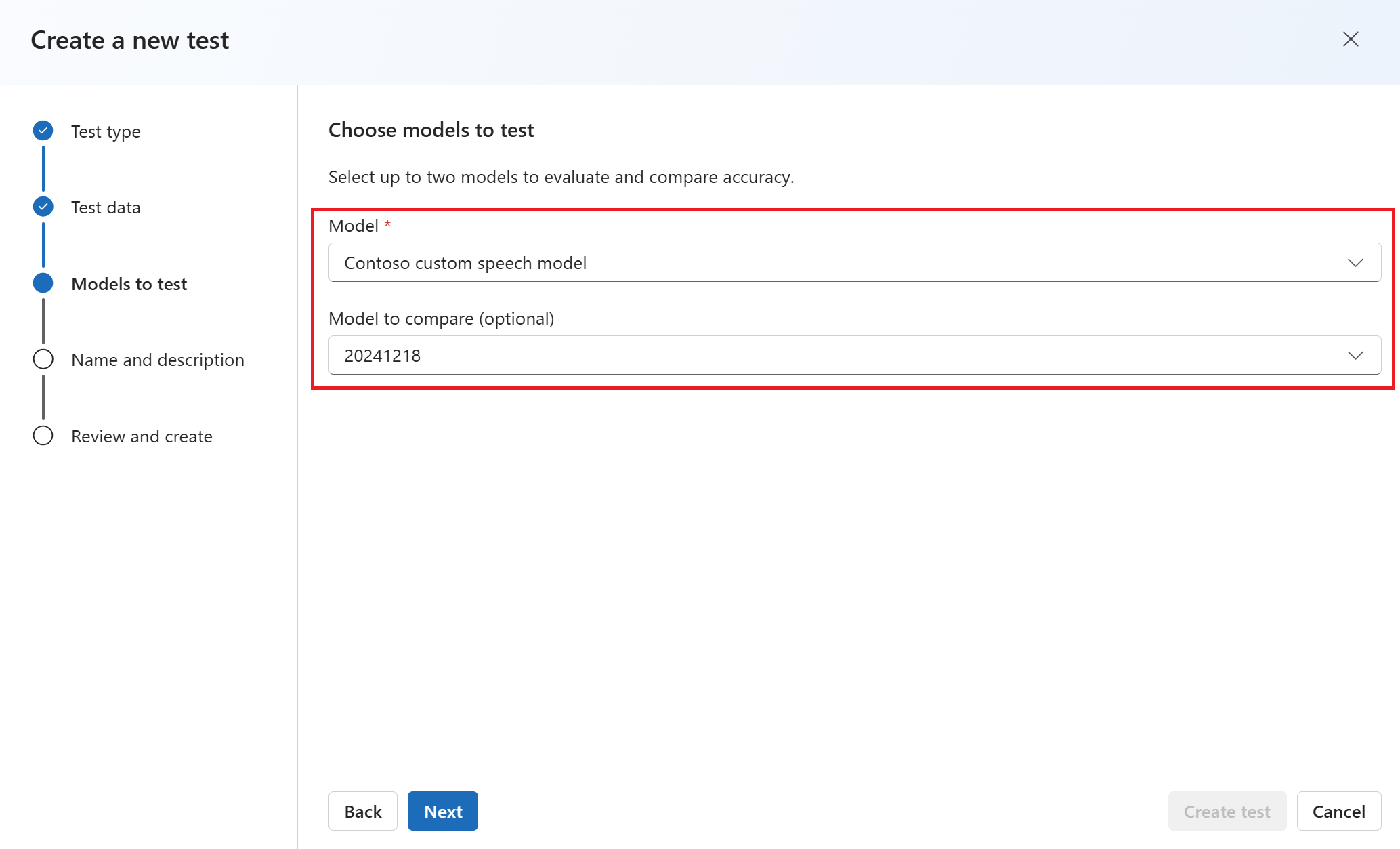
Insira um nome e uma descrição para o teste. Em seguida, selecione Avançar.
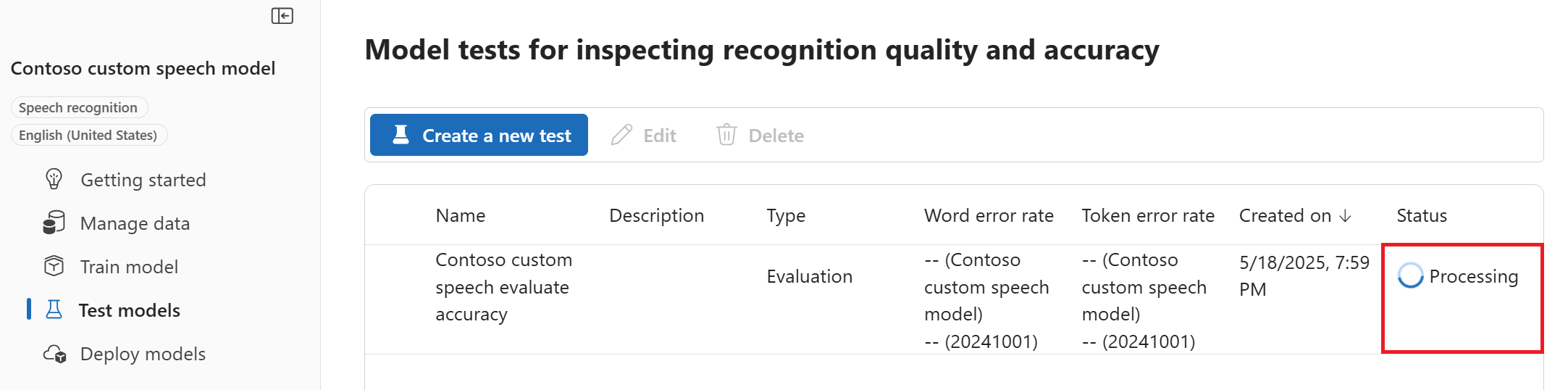
Examine as configurações e selecione Criar teste. Você será levado de volta à página Testar modelos. O status dos dados é Processamento.




Siga estas etapas para criar um teste de precisão:
Entre no Speech Studio.
Selecione Fala personalizada> Nome do projeto >Testar modelos.
Selecione Criar novo teste.
Selecione Avaliar a precisão>Avançar.
Selecione um áudio + conjunto de dados de transcrição literal e selecione Avançar. Se não houver conjuntos de dados disponíveis, cancele a instalação e vá para o menu Conjuntos de dados de fala para carregar conjuntos de dados.
Observação
É importante selecionar um conjunto de dados acústico que seja diferente do que você usou com o seu modelo. Essa abordagem pode fornecer uma noção mais realista do desempenho do modelo.
Selecione até dois modelos para avaliar e selecione Avançar.
Insira o nome do teste e a descrição e, em seguida, selecione Avançar.
Examine os detalhes do teste e depois selecione Salvar e fechar.
Para criar um teste, use o comando spx csr evaluation create. Construa os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina a
projectpropriedade como a ID de um projeto existente. Essa propriedade é recomendada para que você também possa exibir o teste no portal do Azure AI Foundry. Você pode executar o comandospx csr project listpara obter projetos disponíveis. - Defina a propriedade necessária
model1para a ID de um modelo que você deseja testar. - Defina a propriedade necessária
model2para a ID de outro modelo que você deseja testar. Se você não quiser comparar dois modelos, use o mesmo modelo para ambosmodel1emodel2. - Defina a propriedade necessária
datasetpara a ID de um conjunto de dados que você deseja usar para o teste. - Caso não defina a propriedade
language, a CLI de Fala definirá "en-US" por padrão. Esse parâmetro deve ser a localidade dos conteúdos do conjunto de dados. Ela não poderá ser alterada posteriormente. A propriedadelanguageda CLI de Fala corresponde à propriedadelocalena solicitação e na resposta JSON. - Defina a propriedade
nameobrigatória. Esse parâmetro é o nome exibido no portal do Azure AI Foundry. A propriedadenameda CLI de Fala corresponde à propriedadedisplayNamena solicitação e na resposta JSON.
Veja um exemplo de comando da CLI de Fala que cria um teste:
spx csr evaluation create --api-version v3.2 --project aaaabbbb-0000-cccc-1111-dddd2222eeee --dataset bbbbcccc-1111-dddd-2222-eeee3333ffff --model1 ccccdddd-2222-eeee-3333-ffff4444aaaa --model2 ddddeeee-3333-ffff-4444-aaaa5555bbbb --name "My Evaluation" --description "My Evaluation Description"
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
A propriedade self de nível superior no corpo da resposta é o URI da avaliação. Use esse URI para obter detalhes sobre o projeto e os resultados do teste. Você também usa esse URI para atualizar ou excluir a avaliação.
Para a ajuda da CLI de Fala com avaliações, execute o seguinte comando:
spx help csr evaluation
Para criar um teste, use a operação Evaluations_Create da API REST de Conversão de fala em texto . Crie o corpo da solicitação de acordo com as seguintes instruções:
- Defina a propriedade
projectcomo o URI de um projeto existente. Essa propriedade é recomendada para que você também possa exibir o teste no portal do Azure AI Foundry. É possível fazer uma solicitação Projects_List para obter os projetos disponíveis. - Defina a propriedade
testingKindcomoEvaluationdentro decustomProperties. Se você não especificarEvaluation, o teste será tratado como um teste de inspeção de qualidade. Mesmo que a propriedadetestingKindesteja configurada paraEvaluation,Inspectionou não configurada, você pode acessar os escores de precisão por meio da API, mas não no portal do Azure AI Foundry. - Defina a propriedade
model1necessária para o URI de um modelo que você deseja testar. - Defina a propriedade
model2necessária para o URI de outro modelo que você deseja testar. Se você não quiser comparar dois modelos, use o mesmo modelo para ambosmodel1emodel2. - Defina o propriedade
datasetnecessário para o URI de um conjunto de dados que você deseja usar para o teste. - Defina a propriedade
localeobrigatória. Essa propriedade deve ser a localidade dos conteúdos do conjunto de dados. Ela não poderá ser alterada posteriormente. - Defina a propriedade
displayNameobrigatória. Essa propriedade é o nome exibido no portal do Azure AI Foundry.
Faça uma solicitação HTTP POST usando o URI, conforme mostrado no exemplo a seguir. Substitua YourSpeechResoureKey pela chave de recurso de Fala, YourServiceRegion pela região do recurso de Fala e defina as propriedades do corpo da solicitação, conforme descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
A propriedade self de nível superior no corpo da resposta é o URI da avaliação. Use esse URI para obter detalhes sobre o projeto de avaliação e os resultados do teste. Você também usa esse URI para atualizar ou excluir a avaliação.
Obter resultados do teste
É preciso obter os resultados do teste e avalie a WER (taxa de erros de palavra) em comparação com os resultados do reconhecimento de fala.
Quando o status do teste for Bem-sucedido, você poderá exibir os resultados. Selecione o teste para exibir os resultados.
Siga estas etapas para obter resultados de teste:
- Entre no Speech Studio.
- Selecione Fala personalizada> Nome do projeto >Testar modelos.
- Selecione o link pelo nome do teste.
- Depois que o teste for concluído, conforme indicado pelo conjunto de status como Bem-sucedido, você deverá ver os resultados que incluem o número WER para cada modelo testado.
Essa página lista todos os enunciados no conjunto de dados e os resultados de reconhecimento, junto com a transcrição do conjunto de dados enviado. É possível alternar entre vários tipos de erro, incluindo inserção, exclusão e substituição. Ao ouvir o áudio e comparar os resultados de reconhecimento em cada coluna, decida qual modelo atende às suas necessidades e determine se são necessários mais aprimoramentos e treinamento.
Para obter resultados de teste, use o comando spx csr evaluation status. Construa os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina a propriedade
evaluationnecessária como o ID da avaliação da qual você deseja obter resultados de teste.
Veja um exemplo de comando da CLI de Fala que obtém os resultados do teste:
spx csr evaluation status --api-version v3.2 --evaluation aaaabbbb-6666-cccc-7777-dddd8888eeee
As taxas de erro da palavra e mais detalhes são retornados no corpo da resposta.
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Para a ajuda da CLI de Fala com avaliações, execute o seguinte comando:
spx help csr evaluation
Para obter os resultados do teste, comece usando a operação Evaluations_Get da API REST de Conversão de fala em texto.
Faça uma solicitação HTTP GET usando o URI, conforme mostrado no exemplo a seguir. Substitua YourEvaluationId por sua ID de avaliação, substitua YourSpeechResoureKey pela sua chave de recurso de Fala e substitua YourServiceRegion pela sua região de recurso de Fala.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
As taxas de erro da palavra e mais detalhes são retornados no corpo da resposta.
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Avaliar a taxa de erros de palavras (WER)
O padrão do setor para medir a precisão do modelo é o WER (taxa de erros de palavras). O WER conta o número de palavras incorretas identificadas durante o reconhecimento e divide a soma pelo número total de palavras fornecidas na transcrição literal (N).
As palavras incorretamente identificadas se enquadram em três categorias:
- I (inserção): palavras que são adicionadas incorretamente na transcrição de hipótese
- D (exclusão): palavras que não são detectadas na transcrição de hipótese
- S (substituição): palavras que foram substituídas entre a referência e a hipótese
No portal do Azure AI Foundry e no Speech Studio, o quociente é multiplicado por 100 e mostrado como uma porcentagem. Os resultados da CLI de Fala e da API REST não são multiplicados por 100.
$$ WER = {{I+D+S}\over N} \times 100 $$
Aqui está um exemplo que mostra palavras identificadas incorretamente, quando comparadas com a transcrição literal:

O resultado do reconhecimento de fala errou da seguinte maneira:
- Inserção (I): adicionada a palavra "a"
- Exclusão (D): excluído a palavra "are"
- Substituição (S): substituiu a palavra "Jones" por "John"
A taxa de erro da palavra do exemplo anterior é de 60%.
Se você quiser replicar as medidas do WER localmente, poderá usar a ferramenta sclite do SCTK (Conjunto de Ferramentas de Pontuação da NIST).
Resolver erros e aprimorar o WER
Você pode usar o cálculo do WER nos resultados de reconhecimento do computador para avaliar a qualidade do modelo que você está usando com seu aplicativo, ferramenta ou produto. Um WER de 5% a 10% é considerado uma boa qualidade e está pronto para uso. Um WER de 20% é aceitável, mas talvez você queira considerar mais treinamento. Um WER de 30% ou mais sinaliza baixa qualidade e requer personalização e treinamento.
O modo como os erros são distribuídos é importante. Quando muitos erros de exclusão são encontrados, isso geralmente ocorre devido à intensidade do sinal de áudio fraco. Para resolver esse problema, você precisará coletar dados de áudio mais perto da origem. Erros de inserção significam que o áudio foi registrado em um ambiente barulhento e com muitas conversas, causando problemas de reconhecimento. Erros de substituição geralmente são encontrados quando uma amostra insuficiente de termos específicos do domínio é fornecida como transcrições literais ou texto relacionado.
Ao analisar os arquivos, você pode determinar quais tipos de erros existem e quais erros são exclusivos para um arquivo específico. Entender os problemas no nível de arquivo ajuda você a direcionar os aprimoramentos.
Avaliar a taxa de erro de token (TER)
Além da taxa de erros de palavra, você também pode usar a medida estendida da Taxa de Erro de Token (TER) para avaliar a qualidade no formato de exibição de ponta a ponta final. Além do formato léxico (That will cost $900. em vez de that will cost nine hundred dollars), o TER leva em conta os aspectos de formato de exibição, como pontuação, capitalização e ITN. Saiba mais sobre a Formatação de texto de exibição com a conversão de fala em texto.
O WER conta o número de palavras incorretas identificadas durante o reconhecimento e divide a soma pelo número total de palavras fornecidas na transcrição literal (N).
$$ TER = {{I+D+S}\over N} \times 100 $$
A fórmula de cálculo do TER também é semelhante ao WER. A única diferença é que o TER é calculado com base no nível do token em vez do nível de palavra.
- Inserção (I): palavras que são adicionadas incorretamente na transcrição de hipótese
- Exclusão (D): palavras que não são detectadas na transcrição de hipótese
- Substituição (S): palavras que foram substituídas entre a referência e a hipótese
Em um caso real, é possível analisar os resultados de WER e TER para obter as melhorias desejadas.
Observação
Para medir o TER, você precisa verificar se os dados de teste de áudio + transcrição incluem transcrições com formatação de exibição, como pontuação, uso de maiúsculas e ITN.
Resultados do cenário de exemplo
Os cenários de reconhecimento de fala variam de acordo com a qualidade e a linguagem de áudio (vocabulário e estilo de fala). A seguinte tabela examina quatro cenários comuns:
| Cenário | Qualidade de áudio | Vocabulário | Estilo de fala |
|---|---|---|---|
| Central de atendimento | Baixa, 8 kHz, poderia ser duas pessoas em um canal de áudio, poderia ser compactada | Estreito, exclusivo para domínio e produtos | De conversação, estruturada sem rigidez |
| Assistente de voz, como a Cortana ou uma janela de drive-thru | Alta, 16 kHz | Entidade pesada (títulos de música, produtos, locais) | Palavras e frases claramente enunciadas |
| Ditado (mensagem instantânea, notas, pesquisa) | Alta, 16 kHz | Variado | Anotações |
| Legendagem oculta de vídeo | Variada, incluindo uso variado de microfone, música adicionada | Variado, desde reuniões, fala recitada, letra de música | Lido, preparado ou estruturado de modo flexível |
Diferentes cenários produzem resultados de qualidade diferentes. A tabela a seguir examina como o conteúdo desses quatro cenários está classificado no WER. A tabela mostra quais tipos de erro são mais comuns em cada cenário. As taxas de erro de inserção, substituição e exclusão ajudam você a determinar que tipo de dados adicionar para melhorar o modelo.
| Cenário | Qualidade do reconhecimento de fala | Erros de inserção | Erros de exclusão | Erros de substituição |
|---|---|---|---|---|
| Central de atendimento | Médio (< 30% WER) |
Baixo, exceto quando outras pessoas falam em segundo plano | Pode ser alto. Os call centers podem ser ruidosos e as falas sobrepostas podem confundir o modelo | Média: Os nomes de pessoas e produtos podem causar esses erros |
| Assistente de voz | Alto (pode ser < 10% WER) |
Baixo | Baixo | Médio, devido a títulos de música, nomes de produtos ou locais |
| Ditado | Alto (pode ser < 10% WER) |
Baixo | Baixo | Alto |
| Legendagem oculta de vídeo | Depende do tipo de vídeo (o WER pode ser < 50%) | Baixo | Pode ser alto devido a música, ruídos, qualidade do microfone | Jargão pode causar esses erros |