Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Nesta visão geral, você aprenderá sobre os benefícios e os recursos do recurso de conversão de texto em fala do serviço de Fala, que faz parte dos serviços de IA do Azure.
A conversão de texto em fala permite que seus aplicativos, suas ferramentas ou seus dispositivos convertam um texto em uma fala sintetizada semelhante à humana. A funcionalidade de conversão de texto em fala também é conhecida como sintetização de voz. Use vozes humanas como padrão prontas para uso ou crie uma voz personalizada exclusiva para seu produto ou marca. Para obter uma lista completa de vozes, idiomas e localidades com suporte, confira Suporte de idiomas e vozes do serviço de Fala.
Principais recursos
A conversão de texto em fala inclui os seguintes recursos:
| Recurso | Resumo | Demonstração |
|---|---|---|
| Voz padrão (chamada neural na página de preços) | Vozes altamente naturais prontas para uso. Crie uma assinatura do Azure e um recurso de Fala e use o SDK de Fala ou visite o portal do Speech Studio e selecione vozes padrão para começar. Verifique os detalhes de preços. | Confira a Galeria de Voz e determine a voz certa para as suas necessidades comerciais. |
| Voz personalizada | Autoatendimento fácil de usar para criar uma voz de marca natural, com acesso limitado para uso responsável. Crie uma assinatura do Azure e um recurso do Azure AI Foundry e aplique-se para usar a voz personalizada. Depois que você receber acesso, acesse a documentação de ajuste de voz profissional para começar. Verifique os detalhes de preços. | Confira os exemplos de vozes. |
Saiba mais sobre os recursos da conversão de texto em fala neural
A conversão de texto em fala usa redes neurais profundas para tornar as vozes dos computadores quase indistinguíveis das gravações de pessoas. Com uma articulação clara das palavras, a conversão de texto em fala neural reduz consideravelmente a fadiga de escuta quando os usuários interagem com sistemas de IA.
Os padrões de ênfase e entonação na linguagem falada são chamados de prosódia. Os sistemas tradicionais de conversão de texto em fala dividem a prosódia em etapas separadas de análise linguística e previsão acústica que são governadas por modelos independentes. Isso pode resultar em uma voz sintética abafada e confusa.
Veja mais informações sobre os recursos de conversão de texto em fala neural no serviço de Fala e como eles superam os limites dos sistemas tradicionais de conversão de texto em fala:
Síntese de fala em tempo real: use o SDK de Fala ou a API REST para converter texto em fala usando vozes padrão ou vozes personalizadas.
Síntese assíncrona de áudio longo: use a API de síntese em lotes para sintetizar de maneira assíncrona arquivos de conversão de texto em fala com mais de 10 minutos (por exemplo, audiolivros ou palestras). Ao contrário da sintetização feita com o SDK de Fala ou a API REST de Conversão de fala em texto, as respostas não são retornadas em tempo real. A expectativa é que as solicitações sejam enviadas de maneira assíncrona, que as respostas sejam sondadas e que o áudio sintetizado seja baixado quando disponibilizado pelo serviço.
Vozes padrão: a Fala de IA do Azure usa redes neurais profundas para superar os limites da síntese de fala tradicional em relação ao estresse e à entonação na linguagem falada. A previsão de prosódia e a sintetização de voz ocorrem simultaneamente, o que produz resultados mais fluidos e naturais. Cada modelo de voz padrão está disponível a 24 kHz e 48 kHz de alta fidelidade. Você pode usar a sintetização de vozes para:
- Fazer interações mais naturais e interessantes com chatbots e assistentes de voz.
- Converter textos digitais, como livros eletrônicos, em audiolivros.
- Aprimorar sistemas de navegação no carro.
Para obter uma lista completa das vozes neurais padrão da Fala de IA do Azure, consulte Suporte a linguagem e voz para o serviço de Fala.
Aprimorar a saída de conversão de texto em fala com SSML: A Linguagem de Marcação de Sintetização de Voz (SSML) é uma linguagem de marcação baseada em XML usada para personalizar saídas de conversão de texto em fala. Com a SSML, é possível ajustar o timbre, adicionar pausas, aprimorar a pronúncia, alterar a velocidade da fala, ajustar o volume e atribuir várias vozes a um documento individual.
Você pode usar a SSML para definir léxicos próprios ou mudar para estilos de fala diferentes. Com as vozes multilíngues, você também pode ajustar os idiomas de fala por meio da SSML. Para aprimorar a saída de voz em seu cenário, confira Aprimorar a síntese com a Linguagem de Marcação de Síntese de Fala e Síntese de fala com a ferramenta Criação de Conteúdo de Áudio.
Visemas: visemas são poses básicas da fala observada, como a posição dos lábios, da mandíbula e da língua ao produzir um fonema específico. Os visemes têm uma forte correlação com vozes e fonemas.
Usando eventos de visema no SDK de Fala, você pode gerar dados de animação facial. Esses dados podem ser usados para animar rostos em comunicação, educação, entretenimento e serviço de atendimento ao cliente com leitura labial. Atualmente, só há suporte para visemas na
en-US(inglês dos EUA) .
Observação
Além das vozes neurais do Fala de IA do Azure (não HD), você também pode usar vozes em alta definição (HD) do Fala de IA do Azure e vozes neurais (HD e não HD) do OpenAI do Azure. As vozes HD fornecem uma qualidade mais alta para cenários mais versáteis.
Algumas vozes não dão suporte a todas as tags de Linguagem de Marcação de Síntese de Fala (SSML). Isso inclui vozes neurais HD de conversão de texto em fala, vozes pessoais e vozes incorporadas.
- Para as vozes em alta definição (HD) do Fala de IA do Azure, confira o suporte a SSML aqui.
- Para a voz pessoal, você pode encontrar o suporte a SSML aqui.
- Para as vozes incorporadas, confira o suporte a SSML aqui.
Introdução
Para começar a usar a conversão de texto em fala, confira o guia de início rápido. A conversão de texto em fala está disponível por meio do SDK de Fala, da API REST e da CLI de Fala.
Dica
Para converter texto em fala com uma abordagem sem código, experimente a ferramenta Criação de Conteúdo de Áudio no Speech Studio.
Código de exemplo
Há um código de exemplo disponível no GitHub para a conversão de texto em fala. Esses exemplos abordam a conversão de texto em fala nas linguagens de programação mais populares:
Voz personalizada
Além das vozes padrão, você pode criar vozes personalizadas exclusivas para seu produto ou marca. Voz personalizada é um termo abrangente que inclui ajuste fino de voz profissional e voz pessoal. Para começar, bastam alguns arquivos de áudio e as transcrições deles. Para obter mais informações, consulte a documentação de ajuste de voz profissional.
Observação sobre os preços
Caracteres faturáveis
Ao usar o recurso de conversão de texto em fala, você é cobrado por caractere convertido em fala, incluindo a pontuação. Embora o documento SSML em si não seja faturável, os elementos opcionais usados para ajustar a forma como o texto é convertido em fala, como fonemas e tom, são contados como caracteres faturáveis. Veja uma lista de itens faturáveis:
- Texto transmitido para o recurso de conversão de texto em fala no corpo SSML da solicitação
- Todas as marcações dentro do campo de texto do corpo da solicitação no formato SSML, exceto as marcas
<speak>e<voice> - Letras, pontuação, espaços, tabulações, marcação e todos os caracteres de espaço em branco
- Cada ponto de código definido no Unicode
Para obter informações detalhadas, confira Preços do serviço de Fala.
Importante
Cada caractere chinês é contado como dois caracteres para cobrança, incluindo o kanji usado no japonês, o hanja usado no coreano ou o hanzi usado em outros idiomas.
Tempo de treinamento e hospedagem do modelo para voz personalizada
O treinamento de voz personalizado e a hospedagem são calculados por hora e cobrados por segundo. Para obter o preço unitário da cobrança, confira Preços do serviço de Fala.
O tempo de ajuste de voz profissional é medido por "hora de computação" (uma unidade para medir o tempo de execução do computador). Normalmente, ao treinar um modelo de voz, duas tarefas de computação são executadas em paralelo. Portanto, as horas de computação calculadas serão maiores do que o tempo real de treinamento. Para ajuste de voz profissional, geralmente leva de 20 a 40 horas de processamento para treinar uma voz de estilo único, e cerca de 90 horas de processamento para treinar uma voz de vários estilos. O tempo de ajuste de voz profissional é cobrado com um limite de 96 horas de processamento. Portanto, no caso de um modelo de voz ser treinado em 98 horas de computação, você só será cobrado 96 horas de computação.
A hospedagem personalizada do ponto de extremidade de voz é medida pelo tempo real (hora). O tempo de hospedagem (horas) para cada ponto de extremidade é calculado às 00:00 UTC todos os dias nas 24 horas anteriores. Por exemplo, se o ponto de extremidade estiver ativo por 24 horas no primeiro dia, ele será cobrado por 24 horas às 00:00 UTC no segundo dia. Se o ponto de extremidade for criado recentemente ou suspenso durante o dia, ele será cobrado pelo tempo de execução acumulado até as 00:00 UTC do segundo dia. Se o ponto de extremidade não estiver hospedado no momento, ele não será cobrado. Além do cálculo diário às 00:00 UTC por dia, a cobrança também é disparada imediatamente quando um ponto de extremidade é excluído ou suspenso. Por exemplo, para um ponto de extremidade criado às 08:00 UTC em 1º de dezembro, a hora de hospedagem será calculada para 16 horas às 00:00 UTC em 2 de dezembro e 24 horas às 00:00 UTC em 3 de dezembro. Se o usuário suspender a hospedagem do ponto de extremidade às 16:30 UTC em 3 de dezembro, a duração (16,5 horas) de 00:00 às 16:30 UTC em 3 de dezembro será calculada para cobrança.
Voz pessoal
Quando você usa o recurso de voz pessoal, é cobrado pelo armazenamento de perfil e pela síntese.
- Armazenamento de perfil: depois que um perfil de voz pessoal for criado, ele será cobrado até que seja removido do sistema. A unidade de cobrança é por voz por dia. Se o armazenamento de voz durar menos de 24 horas, ele ainda será cobrado como um dia inteiro.
- Síntese: cobrado por caractere. Para obter detalhes sobre caracteres faturáveis, confira os caracteres faturáveis acima.
Avatar de conversão de texto em fala
Quando você usa o recurso de avatar da conversão de texto em fala, a cobrança é aplicada por segundo com base na duração do vídeo de saída. No entanto, para o avatar em tempo real, as cobranças são aplicadas por segundo com base no momento em que o avatar está ativo, independentemente de ele estar falando ou em silêncio. Para otimizar os custos para o uso de avatar em tempo real, confira as dicas "Usar Vídeo Local para Ocioso" fornecidas no código de exemplo de chat do avatar.
O treinamento do avatar personalizado da conversão de texto em fala é medido por "hora de computação" (tempo de execução do computador) e cobrado por segundo. A duração do treinamento varia dependendo da quantidade de dados que você usa. Normalmente, leva de 20 a 40 horas de computação em média para treinar um avatar personalizado. O tempo de treinamento do avatar é cobrado com um limite de 96 horas de computação. Portanto, no caso de um modelo de avatar ser treinado em 98 horas de computação, você será cobrado por 96 horas de computação apenas.
A hospedagem de avatar é cobrada por segundo por ponto de extremidade. Você pode suspender seu ponto de extremidade para economizar custos. Se você quiser suspender o ponto de extremidade, poderá excluí-lo diretamente. Para usá-lo novamente, reimplante o ponto de extremidade.
Monitorar as métricas de conversão de texto em fala
O monitoramento das principais métricas associadas aos serviços de conversão de texto em fala é crucial para gerenciar o uso de recursos e controlar os custos. Esta seção orienta você sobre como encontrar informações de uso no portal do Azure e fornece definições detalhadas sobre as principais métricas. Para obter mais informações sobre as métricas do Azure Monitor, confira visão geral das métricas do Azure Monitor.
Como encontrar informações de uso no portal do Azure
Para gerenciar efetivamente seus recursos do Azure, é essencial acessar e examinar as informações de uso regularmente. Veja a seguir como encontrar as informações de uso:
Vá para o portal do Azure e entre com sua conta do Azure.
Navegue até Recursos e selecione o recurso que deseja monitorar.
Selecione Métricas em Monitoramento no menu à esquerda.
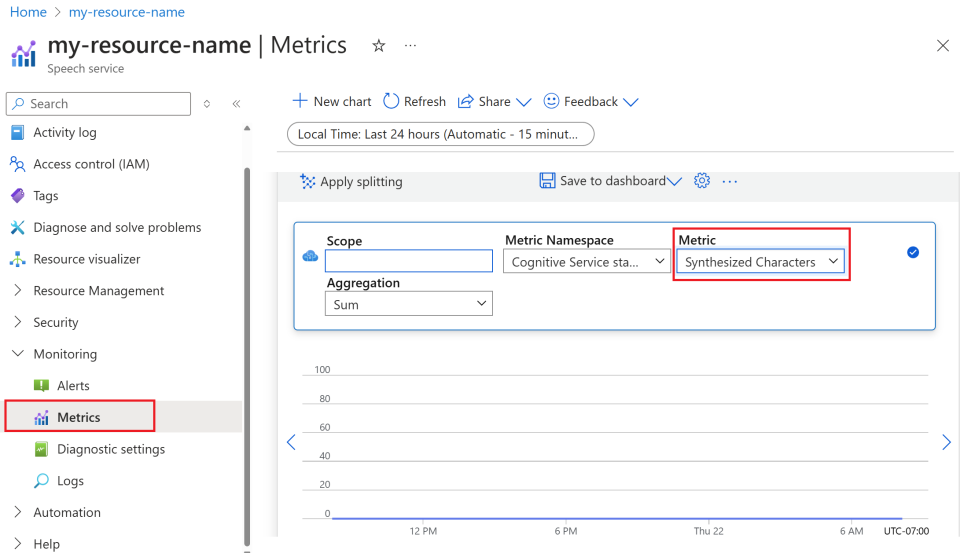
Personalizar as exibições de métricas.
Você pode filtrar dados por tipo de recurso, tipo de métrica, intervalo de tempo e outros parâmetros para criar exibições personalizadas que se alinhem às suas necessidades de monitoramento. Além disso, você pode salvar a exibição de métrica nos painéis selecionando Salvar no painel para facilitar o acesso às métricas usadas com frequência.
Configurar alertas.
Para gerenciar o uso com mais eficiência, configure alertas navegando até a guia Alertas em Monitoramento no menu à esquerda. Os alertas podem notificá-lo quando o uso atinge limites específicos, ajudando a evitar custos inesperados.
Definição de métricas
Aqui está uma tabela resumindo as principais métricas para conversão de texto em fala do Azure.
| Nome da métrica | Descrição |
|---|---|
| Caracteres Sintetizados | Controla o número de caracteres convertidos em fala, incluindo voz padrão e voz personalizada. Para obter detalhes sobre caracteres faturáveis, confira Caracteres faturáveis. |
| Segundos de Vídeo Sintetizados | Mede a duração total do vídeo sintetizado, incluindo síntese de avatar em lote, a síntese de avatar em tempo real e a síntese de avatar personalizado. |
| Segundos de Hosting do Modelo de Avatar | Rastreia o tempo total em segundos em que seu modelo de avatar personalizado está hospedado. |
| Horas de Hosting do modelo de voz | Controla o tempo total em horas em que seu modelo de voz personalizado está hospedado. |
| Minutos de treinamento do modelo de voz | Mede o tempo total em minutos para treinar seu modelo de voz personalizado. |
Documentos de Referência
IA responsável
Um sistema de IA inclui não apenas a tecnologia, mas também as pessoas que a usam, que serão afetadas por ela e o ambiente em que ela foi implantada. Leia as notas de transparência para saber mais sobre o uso e implantação de IA responsável em seus sistemas.
- Notas de transparência e casos de uso para voz personalizada
- Características e limitações para usar a voz personalizada
- Acesso limitado à voz personalizada
- Diretrizes para implantação responsável de tecnologias de voz sintética
- Divulgação para talentos de voz
- Diretrizes de design de divulgação
- Padrões de design de divulgação
- Código de Conduta para integrações de Conversão de texto em fala
- Dados, privacidade e segurança para voz personalizada