Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste guia, analisamos os pré-requisitos, as considerações de arquitetura e os principais componentes para implantar e operar um cluster Apache Kafka altamente disponível no AKS (Serviço de Kubernetes do Azure) usando o Operador Strimzi.
Importante
O software de código aberto é mencionado em toda a documentação e amostras do AKS. O software que você implanta está excluído dos contratos de nível de serviço do AKS, garantia limitada e suporte do Azure. Ao usar tecnologia de código aberto junto com o AKS, consulte as opções de suporte disponíveis nas comunidades e mantenedores de projetos respectivos para desenvolver um plano.
Por exemplo, o repositório do Ray GitHub descreve várias plataformas que variam em tempo de resposta, finalidade e nível de suporte.
A Microsoft assume a responsabilidade por criar os pacotes de código aberto que implantamos no AKS. Essa responsabilidade inclui ter propriedade completa do processo de criação, verificação, sinalização, validação e hotfix, junto com o controle sobre os binários em imagens de contêiner. Para obter mais informações, confira Gerenciamento de vulnerabilidades para o AKS e Cobertura de suporte do AKS.
O que é Strimzi?
Strimzi é um projeto de software livre que simplifica a implantação, o gerenciamento e a operação do Apache Kafka no Kubernetes. Ele fornece um conjunto de operadores kubernetes e imagens de contêiner que automatizam tarefas operacionais complexas do Kafka por meio da configuração declarativa.
Os operadores Strimzi seguem o padrão de operador do Kubernetes para automatizar as operações do Kafka. Ele reconcilia continuamente o estado declarado dos componentes kafka com seu estado real, tratando tarefas operacionais complexas automaticamente.
Para saber mais sobre Strimzi, examine a documentação do Strimzi.
Componentes
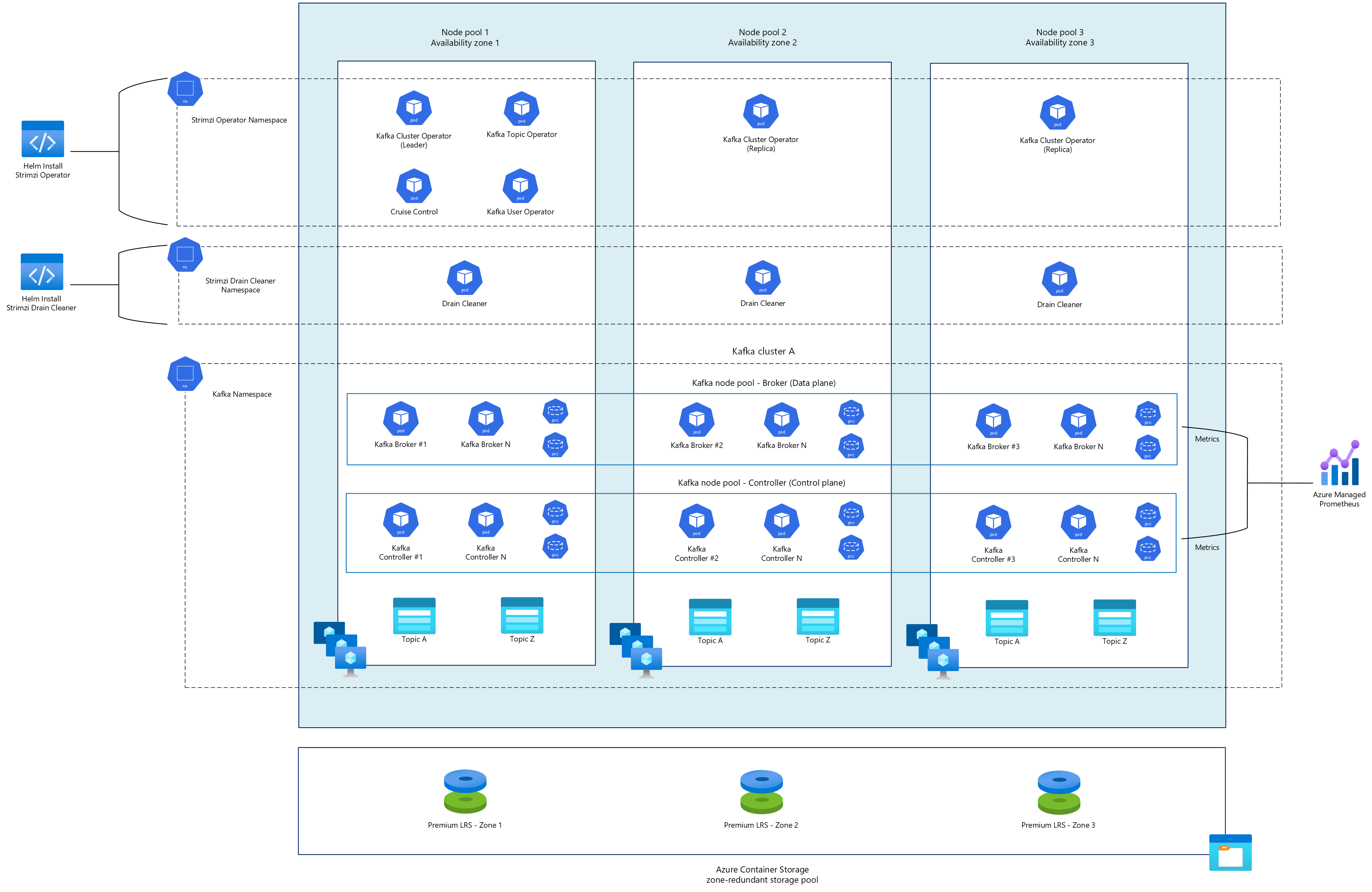
Operador de cluster Strimzi
O Operador de Cluster Strimzi é o componente central que gerencia todo o ecossistema kafka. Quando implantado, ele também pode provisionar o Operador de Entidade, que consiste em:
- Operador de tópico: automatiza a criação, modificação e exclusão de tópicos do Kafka com base em
KafkaTopicrecursos personalizados. - Operador de usuário: gerencia os usuários do Kafka e suas ACLs (Listas de Controle de Acesso) por meio
KafkaUserde recursos personalizados.
Juntos, esses operadores criam um sistema de gerenciamento totalmente declarativo em que sua infraestrutura do Kafka é definida como recursos do Kubernetes que você pode controlar, auditar e implantar consistentemente entre ambientes.
Cluster Kafka
O Operador de Cluster Strimzi gerencia clusters Kafka por meio de recursos personalizados especializados:
- KafkaNodePools: definir grupos de nós Kafka com funções específicas (broker, controlador ou ambos).
- Kafka: o principal recurso personalizado que une tudo, definindo configurações em todo o cluster.
Uma implantação típica de KafkaNodePools e Kafka inclui:
- Nós de agente dedicados que lidam com o tráfego do cliente e o armazenamento de dados.
- Nós de controlador dedicados que gerenciam coordenação e metadados de cluster.
- Várias réplicas de cada componente distribuídas entre zonas de disponibilidade.
Cruise Control
Cruise Control é um componente avançado que fornece balanceamento e monitoramento automatizados de carga de trabalho de clusters Kafka. Quando implantado como parte de um cluster Kafka gerenciado pelo Strimzi, o Cruise Control oferece:
- Rebalanceamento de partição automatizado: redistribui partições entre agentes para otimizar a utilização de recursos.
- Detecção de anomalias: identifica e alertas sobre o comportamento anormal do cluster.
- Recursos de auto-recuperação: resolve automaticamente problemas comuns de desequilíbrio de cluster.
- Análise de carga de trabalho: fornece insights sobre o desempenho do cluster e o uso de recursos.
O Cruise Control ajuda a manter o desempenho ideal à medida que sua carga de trabalho muda ao longo do tempo, reduzindo a necessidade de intervenção manual durante eventos de dimensionamento ou após falhas do agente.
Limpador de Esgoto
Strimzi Drain Cleaner é um utilitário projetado para ajudar a gerenciar pods de agente Kafka implantados pela Strimzi durante o esvaziamento de nós do Kubernetes. O Strimzi Drain Cleaner intercepta operações de esvaziamento de nós do Kubernetes, por meio de seu webhook de admissão, para coordenar a manutenção normal dos clusters Kafka. Quando uma solicitação de remoção é feita para pods de agente do Kafka, a solicitação é detectada e o Drain Cleaner anota os pods para sinalizar para o Strimzi Cluster Operator lidar com a reinicialização, garantindo que o cluster do Kafka permaneça em um estado íntegro. Esse processo mantém a integridade do cluster e a confiabilidade dos dados durante operações de manutenção de rotina ou falhas inesperadas de nó.
Principais considerações para Kafka no AKS
Armazenamento de Contêineres do Azure
O Armazenamento de Contêineres do Azure é uma solução de armazenamento do Kubernetes gerenciado que provisiona dinamicamente volumes persistentes para aplicativos com estado, como o Kafka. Com base no projeto de software livre do OpenEBS, ele fornece recursos de armazenamento de nível empresarial especificamente otimizados para cargas de trabalho em contêineres.
Para implantações do Kafka, o Strimzi utiliza a configuração Just a Bunch of Disks (JBOD) para gerenciar a persistência de dados. Para garantir alta disponibilidade em falhas de infraestrutura, um pool de armazenamento com redundância de zona com o Armazenamento de Contêineres do Azure deve ser configurado para distribuir os discos subjacentes em todas as zonas de disponibilidade. Cada zona usará O LRS (Armazenamento Com Redundância Local) com discos SSD Premium v2. ZRS (Armazenamento com Redundância de Zona) é desnecessário, pois o Kafka fornece replicação interna de dados no nível do aplicativo. O SSD Premium v2 pode fornecer a latência, IOPS alta e a taxa de transferência consistente exigidas por cargas de trabalho Kafka intensivas em IO, em uma estrutura de custo otimizada.
Observação
O armazenamento efêmero não é recomendado para clusters Kafka de produção. Ao usar o armazenamento efêmero, as reinicializações do agente disparam a replicação completa de dados em todo o cluster, o que pode afetar significativamente o tempo de desempenho e de recuperação.
A tabela a seguir fornece pontos de partida para configurações de disco SSD Premium v2 em diferentes tamanhos de cluster Kafka:
| Tamanho do cluster Kafka | Tamanho do disco | IOPS | Largura de banda |
|---|---|---|---|
| Pequeno (3 a 9 corretores) |
1 TB | 5.000 | 250 MB/s |
| Médio (10 a 19 corretores) |
2 TB | 10.000 | 500 MB/s |
| Grande (mais de 20 agentes) |
4 TB | 20.000 | 1\.000 MB/s |
A IOPS, a largura de banda e o tamanho do disco necessários reais variam de acordo com suas características específicas de carga de trabalho do Kafka. Essas propriedades podem evoluir ao longo do tempo à medida que a taxa de transferência e os requisitos de retenção do aplicativo são alterados.
Pools de nós
Selecionar os pools de nós apropriados para sua implantação do Kafka no AKS é uma decisão de arquitetura crítica que afeta diretamente o desempenho, a disponibilidade e a eficiência de custo. As cargas de trabalho do Kafka têm padrões exclusivos de utilização de recursos , caracterizados por demandas de alta taxa de transferência, intensidade de E/S de armazenamento e a necessidade de desempenho consistente em cargas variadas. O Kafka normalmente é mais intensivo em memória do que o uso intensivo de CPU. No entanto, os requisitos de CPU podem aumentar significativamente com compactação/descompactação de mensagens, criptografia SSL/TLS ou cenários de alta taxa de transferência com muitas mensagens pequenas.
Considerando a arquitetura nativa do Kubernetes da Strimzi, em que cada agente do Kafka é executado como um pod individual, sua estratégia de seleção de nós do AKS deve otimizar para dimensionamento horizontal, em vez de dimensionamento vertical de um único nó. A configuração adequada do pool de nós no AKS garante uma utilização eficiente de recursos, mantendo o isolamento de desempenho necessário para que os componentes do Kafka operem de forma confiável.
O Kafka é executado usando uma JVM (Máquinas Virtuais Java). O ajuste da JVM é fundamental para o desempenho ideal do Kafka, especialmente em ambientes de produção. O LinkedIn, os criadores do Kafka, compartilhou os argumentos típicos para executar o Kafka no Java para um dos clusters mais movimentados do LinkedIn: a Configuração java do Kafka.
Para este guia, um heap de memória de 6 GB será usado como linha de base para agentes, com 2 GB adicionais alocados para acomodar o uso de memória fora do heap. Para controladores, um heap de memória de 3 GB será usado como linha de base, com 1 GB adicional como sobrecarga.
Ao dimensionar VMs para sua implantação do Kafka, considere estes fatores específicos da carga de trabalho:
| Fator de carga de trabalho | Impacto no dimensionamento | Considerações |
|---|---|---|
| Taxa de transferência de mensagem | Uma taxa de transferência mais alta requer mais capacidade de CPU, memória e rede. | – Monitorar o tráfego de dados de entrada e saída por segundo. - Considere o pico versus a taxa de transferência média. – Contabiliza projeções futuras de crescimento. |
| Tamanho da mensagem | O dimensionamento de mensagens afeta os requisitos de CPU, rede e disco. | - Mensagens pequenas (≤1KB) são mais associadas à CPU. - Mensagens grandes (>1 MB) são mais associadas à rede. – Mensagens muito grandes podem exigir ajuste especializado. |
| Período de retenção | A retenção mais longa aumenta os requisitos de armazenamento. | – Calcule as necessidades totais de armazenamento com base na taxa de transferência × retenção. |
| Contagem de consumidores | Mais consumidores aumentam a CPU e a carga de rede. | - Cada grupo de consumidores adiciona sobrecarga. – Os padrões de alta expansão exigem recursos adicionais. |
| Particionamento de tópicos | A quantidade de partições impacta a utilização da memória. | - Cada partição consome recursos de memória. - O excesso de particionamento pode prejudicar o desempenho. |
| Sobrecarga de infraestrutura | Componentes adicionais do sistema afetam os recursos disponíveis para o Kafka. | – O armazenamento de contêineres do Azure requer no mínimo 1 vCPU por nó. – Agentes de monitoramento, componentes de log, políticas de rede e ferramentas de segurança adicionam sobrecarga extra. – Reserve uma sobrecarga para componentes do sistema. |
Importante
As recomendações a seguir servem apenas como diretrizes iniciais. Sua seleção de SKU de VM ideal deve ser adaptada às características específicas da carga de trabalho do Kafka, aos padrões de dados e aos requisitos de desempenho. Estima-se que cada pod do agente tenha ~8 GB de memória reservada. Estima-se que cada pod do controlador tenha aproximadamente 4 GB de memória reservada. Seus requisitos de memória JVM e heap podem ser maiores ou menores.
Clusters Kafka pequenos a médios
| SKU da VM | vCPUs | RAM | Rede | Densidade do agente (estimativas) | Principais benefícios |
|---|---|---|---|---|---|
| Standard_D8ds | 8 | 32 GB | 12.500 Mbps | 1 a 3 por nó | – Econômico para dimensionamento horizontal, mas pode exigir mais nós à medida que a escala aumenta. |
| Standard_D16ds | 16 | 64 GB | 12.500 Mbps | 3 a 6 por nó | – Utilização de recursos mais eficiente com vCPU e RAM adicionais, exigindo menos nós do AKS. |
Clusters grandes do Kafka
| SKU da VM | vCPUs | RAM | Rede | Densidade do agente (estimativas) | Principais benefícios |
|---|---|---|---|---|---|
| Standard_E16ds | 16 | 128 GB | 12.500 Mbps | acima de 6 por nó | – Melhor desempenho para operações com uso intensivo de dados, em grande escala, com altas taxas de memória para núcleo. É capaz de ter heaps de memória maiores ou dimensionamento horizontal |
Antes de finalizar seu ambiente de produção, recomendamos executar as seguintes etapas:
- Execute testes de carga com volumes e padrões de dados representativos.
- Monitore a CPU, a memória, o disco e a utilização da rede durante as cargas de pico.
- Ajuste SKUs do pool de nós do AKS com base nos gargalos observados.
- Revisar o custo de SKUs do pool de nós
Alta disponibilidade e resiliência
Para garantir a alta disponibilidade da implantação do Kafka:
- Implante entre várias zonas de disponibilidade.
- Configurar as restrições corretas de distribuição de réplicas.
- Implemente orçamentos apropriados de interrupção do pod.
- Configure o Cruise Control para o reequilibrar partições de tópicos.
- Use o Strimzi Drain Cleaner para executar operações de esvaziamento e manutenção de nós.
Monitoramento e operações
O monitoramento efetivo de clusters Kafka inclui:
- Configuração da coleção de métricas JMX.
- Monitoramento do atraso do consumidor com o Kafka Exporter.
- Integração ao Prometheus gerenciado pelo Azure e o Espaço Gerenciado do Azure para Grafana.
- Alertas sobre os principais indicadores de desempenho e métricas de saúde.
Quando usar o Kafka no AKS
Considere executar o Kafka no AKS quando:
- Você precisa de controle total sobre a configuração e as operações do Kafka.
- Seu caso de uso requer recursos específicos do Kafka não disponíveis em ofertas gerenciadas.
- Você deseja integrar o Kafka a outros aplicativos em contêineres em execução no AKS.
- Você precisa implantar em regiões em que os serviços Kafka gerenciados não estão disponíveis.
- Sua organização tem experiência existente em Kubernetes e orquestração de contêineres.
Para casos de uso mais simples ou quando a sobrecarga operacional for uma preocupação, considere serviços totalmente gerenciados, como Os Hubs de Eventos do Azure.
Próxima etapa
Contribuidores
A Microsoft mantém este artigo. Os seguintes colaboradores o escreveram originalmente:
- Sergio Navar | Engenheiro sênior de clientes
- Erin Schaffer | Desenvolvedora de Conteúdo 2
Colaborar conosco no GitHub
A fonte deste conteúdo pode ser encontrada no GitHub, onde você também pode criar e revisar problemas e solicitações de pull. Para obter mais informações, confira o nosso guia para colaboradores.

Azure Kubernetes Service