Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este tutorial orientará você pela implantação de um aplicativo de chatbot baseado em Express.js integrado à extensão de sidecar Phi-4 no Serviço de Aplicativo do Azure. Seguindo as etapas, você aprenderá a configurar um aplicativo Web escalonável, adicionar um sidecar alimentado por IA para recursos de conversa aprimorados e testar a funcionalidade do chatbot.
Hospedar seu próprio modelo de linguagem pequeno (SLM) oferece várias vantagens:
- Controle total sobre seus dados. Informações confidenciais não são expostas a serviços externos, o que é fundamental para setores com requisitos de conformidade rigorosos.
- Modelos auto-hospedados podem ser ajustados para atender a casos de uso específicos ou requisitos específicos do domínio.
- Latência de rede minimizada e tempos de resposta mais rápidos para uma melhor experiência do usuário.
- Controle total sobre a alocação de recursos, garantindo o desempenho ideal para seu aplicativo.
Pré-requisitos
- Uma conta do Azure com uma assinatura ativa.
- Uma conta do GitHub.
Implantar o aplicativo de exemplo
No navegador, navegue até o repositório de aplicativos de exemplo.
Inicie um novo Codespace no repositório.
Faça logon com sua conta do Azure:
az loginAbra o terminal no Codespace e execute os seguintes comandos:
cd use_sidecar_extension/expressapp az webapp up --sku P3MV3
Esse comando de inicialização é uma configuração comum para implantar aplicativos Express.js no Serviço de Aplicativo do Azure. Para obter mais informações, consulte Implantar um aplicativo Web Node.js no Azure.
Adicionar a extensão de sidecar Phi-4
Nesta seção, você adiciona a extensão de sidecar Phi-4 ao seu aplicativo ASP.NET Core hospedado no Azure App Service.
- Navegue até o portal do Azure e acesse a página de gerenciamento do aplicativo.
- No menu à esquerda, selecione Implantação>Centro de Implantação.
- Na guia Contêineres, selecione Adicionar>extensão de sidecar.
- Nas opções de extensão sidecar, selecione IA: phi-4-q4-gguf (Experimental).
- Forneça um nome para a extensão de sidecar.
- Selecione Salvar para aplicar as alterações.
- Aguarde alguns minutos para que a extensão de sidecar seja implantada. Continue selecionando Atualizar até que a coluna Status mostre a execução.
Essa extensão de sidecar Phi-4 usa uma API de conclusão de chat, como o OpenAI, que pode responder à resposta de conclusão do chat em http://localhost:11434/v1/chat/completions. Para obter mais informações sobre como interagir com a API, consulte:
Testar o chatbot
Na página de gerenciamento do aplicativo, no menu à esquerda, selecione Visão geral.
No domínio Padrão, selecione a URL para abrir seu aplicativo Web em um navegador.
Verifique se o aplicativo chatbot está em execução e respondendo às entradas do usuário.
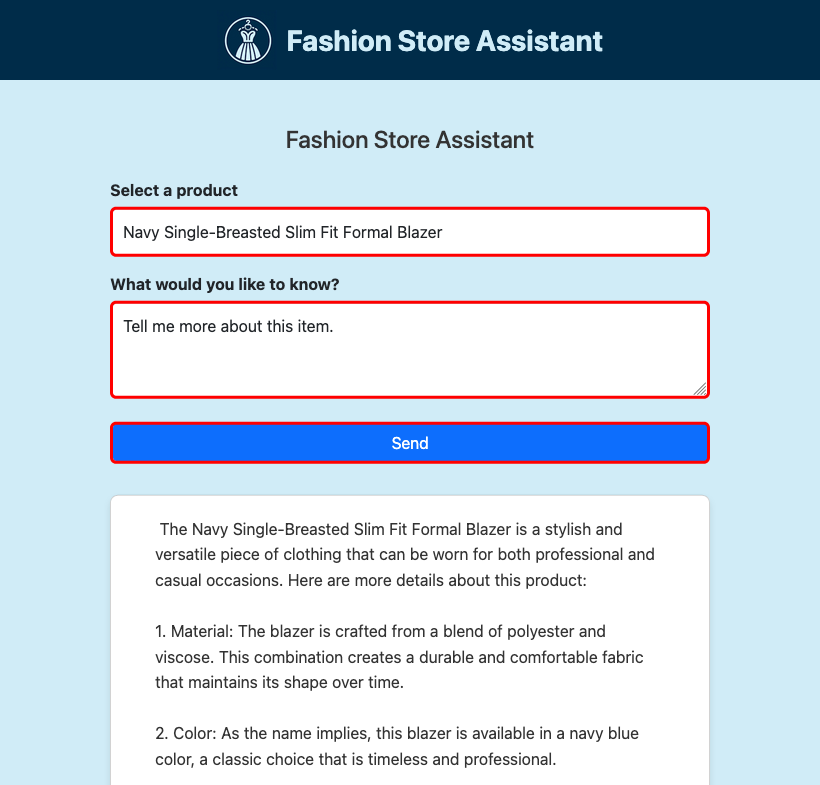
Como funciona o aplicativo de exemplo
O aplicativo de exemplo demonstra como integrar um serviço baseado em Express.js com a extensão de sidecar de SLM. A SLMService classe encapsula a lógica para enviar solicitações para a API SLM e processar as respostas transmitidas. Essa integração permite que o aplicativo gere respostas de conversa dinamicamente.
Examinando use_sidecar_extension/expressapp/src/services/slm_service.js, você verá que:
O serviço envia uma solicitação POST para o endpoint SLM
http://127.0.0.1:11434/v1/chat/completions.this.apiUrl = 'http://127.0.0.1:11434/v1/chat/completions';O conteúdo POST inclui a mensagem do sistema e o prompt criado a partir do produto selecionado e da consulta do usuário.
const requestPayload = { messages: [ { role: 'system', content: 'You are a helpful assistant.' }, { role: 'user', content: prompt } ], stream: true, cache_prompt: false, n_predict: 2048 // Increased token limit to allow longer responses };A solicitação POST transmite a resposta linha por linha. Cada linha é analisada para extrair o conteúdo gerado (ou token).
// Set up Server-Sent Events headers res.setHeader('Content-Type', 'text/event-stream'); res.setHeader('Cache-Control', 'no-cache'); res.setHeader('Connection', 'keep-alive'); res.flushHeaders(); const response = await axios.post(this.apiUrl, requestPayload, { headers: { 'Content-Type': 'application/json' }, responseType: 'stream' }); response.data.on('data', (chunk) => { const lines = chunk.toString().split('\n').filter(line => line.trim() !== ''); for (const line of lines) { let parsedLine = line; if (line.startsWith('data: ')) { parsedLine = line.replace('data: ', '').trim(); } if (parsedLine === '[DONE]') { return; } try { const jsonObj = JSON.parse(parsedLine); if (jsonObj.choices && jsonObj.choices.length > 0) { const delta = jsonObj.choices[0].delta || {}; const content = delta.content; if (content) { // Use non-breaking space to preserve formatting const formattedToken = content.replace(/ /g, '\u00A0'); res.write(`data: ${formattedToken}\n\n`); } } } catch (parseError) { console.warn(`Failed to parse JSON from line: ${parsedLine}`); } } });
Perguntas frequentes
Como o tipo de preço afeta o desempenho do sidecar de SLM?
Como os modelos de IA consomem recursos consideráveis, escolha o tipo de preço que fornece vCPUs e memória suficientes para executar seu modelo específico. Por esse motivo, as extensões de sidecar de IA internas só aparecem quando o aplicativo está em um tipo de preço adequado. Se você criar seu próprio contêiner sidecar de SLM, também deverá usar um modelo otimizado para CPU, já que as tipos de preços do Serviço de Aplicativo são tipos somente para CPU.
Por exemplo, o mini modelo Phi-3 com um comprimento de contexto de 4K do Hugging Face foi projetado para ser executado com recursos limitados e fornece um forte raciocínio matemático e lógico para muitos cenários comuns. Ele também vem com uma versão otimizada para CPU. No Serviço de Aplicativo, testamos o modelo em todas as camadas premium e descobrimos que ele teve um bom desempenho na camada P2mv3 ou superior. Se seus requisitos permitirem, você poderá executá-lo em uma camada inferior.
Como usar meu próprio sidecar de SLM?
O repositório de exemplo contém um contêiner SLM de exemplo que você pode usar como sidecar. Ele executa um aplicativo FastAPI que escuta na porta 8000, conforme especificado em seu Dockerfile. O aplicativo usa ONNX Runtime para carregar o modelo Phi-3, encaminha os dados HTTP POST para o modelo e transmite a resposta do modelo de volta para o cliente. Para obter mais informações, consulte model_api.py.
Para criar a imagem sidecar por conta própria, você precisa instalar o Docker Desktop localmente em seu computador.
Clone o repositório localmente.
git clone https://github.com/Azure-Samples/ai-slm-in-app-service-sidecar cd ai-slm-in-app-service-sidecarAltere para o diretório de origem da imagem Phi-3 e baixe o modelo localmente usando a CLI do Huggingface.
cd bring_your_own_slm/src/phi-3-sidecar huggingface-cli download microsoft/Phi-3-mini-4k-instruct-onnx --local-dir ./Phi-3-mini-4k-instruct-onnxO Dockerfile está configurado para copiar o modelo de ./Phi-3-mini-4k-instruct-onnx.
Cria a imagem do Docker. Por exemplo:
docker build --tag phi-3 .Carregue a imagem criada no Registro de Contêiner do Azure com Enviar sua primeira imagem para o Registro de Contêiner do Azure usando a CLI do Docker.
Na guia Contêineres do Centro de >(novo), selecione Adicionar>contêiner Personalizado e configure o novo contêiner da seguinte maneira:
- Nome: phi-3
- Fonte da imagem: Registro de Contêiner do Azure
- Registro: seu registro
- Imagem: a imagem carregada
- Marca: a marca de imagem desejada
- Porta: 8000
Selecione Aplicar.
Consulte bring_your_own_slm/src/webapp para obter um aplicativo de exemplo que interaja com esse contêiner de sidecar personalizado.