Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Microsoft Fabric
Fábrica de dados do Azure
Normalmente, as organizações precisam coletar dados de várias fontes em vários formatos e movê-los para um ou mais armazenamentos de dados. O destino pode não ser o mesmo tipo de armazenamento de dados que a origem, e os dados geralmente precisam ser moldados, limpos ou transformados antes do carregamento.
Várias ferramentas, serviços e processos ajudam a resolver esses desafios. Independentemente da abordagem, você precisa coordenar o trabalho e aplicar transformações de dados no pipeline de dados. As seções a seguir destacam os métodos e práticas comuns para essas tarefas.
Processo de ETL (extração, transformação e carregamento)
Extrair, transformar, carregar (ETL) é um processo de integração de dados que consolida dados de diversas fontes em um armazenamento de dados unificado. Durante a fase de transformação, os dados são modificados de acordo com as regras de negócios usando um mecanismo especializado. Isso geralmente envolve tabelas de preparo que contêm temporariamente os dados à medida que são processados e, por fim, carregados em seu destino.
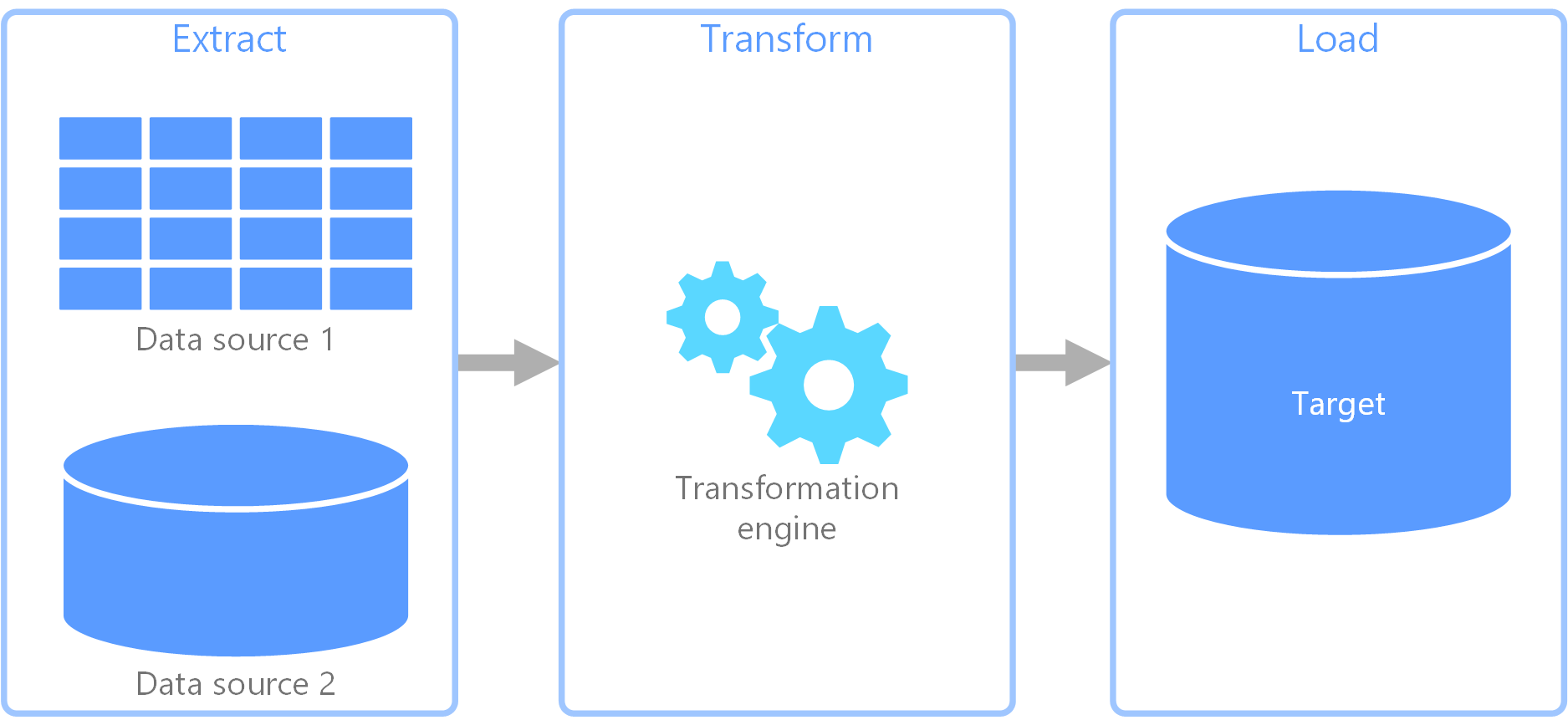
A transformação de dados ocorrida geralmente envolve diversas operações, como filtragem, classificação, agregação, junção de dados, limpeza de dados, eliminação de duplicação e validação de dados.
Geralmente, as três fases de ETL são executadas em paralelo para economizar tempo. Por exemplo, enquanto os dados estão sendo extraídos, um processo de transformação pode funcionar em dados já recebidos e prepará-los para carregamento, e um processo de carregamento pode começar a trabalhar nos dados preparados, em vez de esperar que todo o processo de extração seja concluído. Normalmente, você projeta paralelização em torno de limites de partição de dados (data, locatário, chave de fragmento) para evitar contenção de gravação e habilitar novas tentativas idempotentes.
Serviço relevante:
Outras ferramentas:
ELT (extração, carregamento e transformação)
O ELT (extração, carregamento e transformação) difere do ETL somente no local em que ocorre a transformação. No pipeline de ELT, a transformação ocorre no armazenamento de dados de destino. Em vez de usar um mecanismo de transformação separado, as funcionalidades de processamento do armazenamento de dados de destino são usadas para transformar os dados. Isso simplifica a arquitetura pela remoção do mecanismo de transformação do pipeline. Outro benefício dessa abordagem é que o dimensionamento do armazenamento de dados de destino também dimensiona o desempenho do pipeline ELT. No entanto, o ELT só funciona bem quando o sistema de destino é poderoso o suficiente para transformar os dados com eficiência.
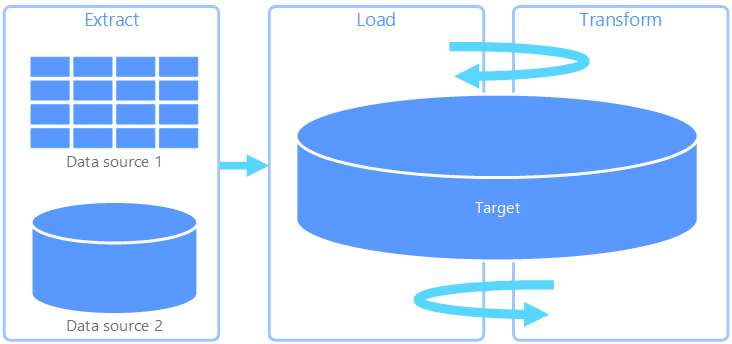
Os casos típicos de uso do ELT se enquadram no âmbito do Big Data. Por exemplo, você pode começar extraindo dados de origem para arquivos simples no armazenamento escalonável, como um HDFS (Sistema de Arquivos Distribuído hadoop), armazenamento de blobs do Azure ou Azure Data Lake Storage Gen2. Tecnologias como Spark, Hive ou PolyBase podem ser usadas para consultar os dados de origem. O ponto-chave do ELT é que o armazenamento de dados usado para executar a transformação é o mesmo armazenamento de dados no qual os dados são, em última análise, consumidos. Esse armazenamento de dados lê diretamente do armazenamento escalonável, em vez de carregar os dados em seu próprio armazenamento separado. Essa abordagem ignora as etapas de cópia de dados presentes no ETL, que geralmente podem ser demoradas para grandes conjuntos de dados. Algumas cargas de trabalho materializam tabelas ou exibições transformadas para melhorar o desempenho da consulta ou impor regras de governança; O ELT nem sempre implica transformações puramente virtualizadas.
A fase final do pipeline ELT normalmente transforma os dados de origem em um formato mais eficiente para os tipos de consultas que precisam ter suporte. Por exemplo, os dados podem ser particionados por chaves normalmente filtradas. O ELT também pode usar formatos de armazenamento otimizados, como Parquet, que é um formato de armazenamento colunar que organiza dados por coluna para habilitar a compactação, predicado pushdown e verificações analíticas eficientes.
Serviço Relevante da Microsoft:
- Microsoft Fabric Data Warehouse
- Lakehouse do Microsoft Fabric
- Pipelines de dados do Microsoft Fabric
Escolhendo ETL ou ELT
A escolha entre essas abordagens depende de seus requisitos.
Escolha ETL quando:
- Você precisa descarregar transformações pesadas de um sistema de destino restrito
- Regras de negócios complexas exigem mecanismos de transformação especializados
- Requisitos regulatórios ou de conformidade exigem auditorias de preparo selecionadas antes de carregar
Escolha ELT quando:
- Seu sistema de destino é um data warehouse moderno ou lakehouse com dimensionamento de computação elástica
- Você precisa preservar dados brutos para análise exploratória ou evolução futura do esquema
- A lógica de transformação se beneficia dos recursos nativos do sistema de destino
Fluxo de dados e fluxo de controle
No contexto dos pipelines de dados, o fluxo de controle garante o processamento ordenado de um conjunto de tarefas. Para impor a ordem de processamento correta dessas tarefas, restrições de precedência são usadas. Você pode pensar nessas restrições como conectores em um diagrama de fluxo de trabalho, conforme mostrado na imagem a seguir. Cada tarefa tem um resultado, como êxito, falha ou conclusão. Qualquer tarefa subsequente não inicia o processamento até que seu antecessor seja concluído com um desses resultados.
Os fluxos de controle executam fluxos de dados como uma tarefa. Em uma tarefa de fluxo de dados, os dados são extraídos de uma fonte, transformados ou carregados em um armazenamento de dados. A saída de uma tarefa de fluxo de dados pode ser a entrada para a próxima tarefa de fluxo de dados e os fluxos de dados podem ser executados em paralelo. Ao contrário dos fluxos de controle, você não pode adicionar restrições entre tarefas em um fluxo de dados. No entanto, é possível adicionar um visualizador de dados para observar os dados conforme eles são processados por cada tarefa.
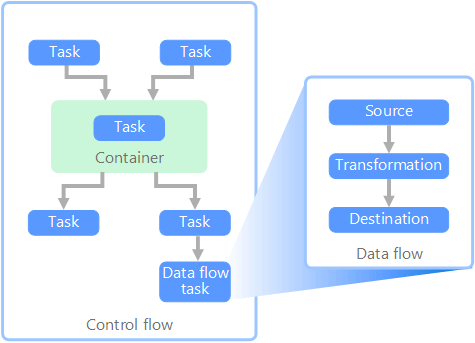
No diagrama, há várias tarefas dentro do fluxo de controle, uma das quais é uma tarefa de fluxo de dados. Uma das tarefas é aninhada em um contêiner. Os contêineres podem ser usados para fornecer estrutura às tarefas, fornecendo uma unidade de trabalho. Um exemplo disso são elementos de repetição em uma coleção, como arquivos em uma pasta ou instruções de banco de dados.
Serviço relevante:
ETL reverso
O ETL reverso é o processo de mover dados transformados e modelados de sistemas analíticos em ferramentas operacionais e aplicativos. Ao contrário do ETL tradicional, que flui dados de sistemas operacionais para análise, o ETL reverso ativa insights enviando dados coletados de volta para onde os usuários empresariais podem agir sobre ele. Em um pipeline de ETL reverso, os dados fluem de data warehouses, lakehouses ou outros repositórios analíticos para sistemas operacionais como:
- Plataformas de CRM (gerenciamento de relacionamento com o cliente)
- Ferramentas de automação de marketing
- Sistemas de suporte ao cliente
- Bancos de dados de carga de trabalho
A abordagem ainda segue um processo de extração, transformação e carregamento. A etapa de transformação é onde você converte do formato específico usado por seu data warehouse ou outro sistema de análise para se alinhar ao sistema de destino.
Consulte o ETL (extrair, transformar e carregar) reverso com o Azure Cosmos DB para NoSQL para obter um exemplo.
Streaming de dados e arquiteturas de caminho quente
Quando você precisa de arquiteturas lambda hot path ou Kappa, você pode assinar fontes de dados à medida que os dados são gerados. Ao contrário de ETL ou ELT, que operam em conjuntos de dados em lotes agendados, o streaming em tempo real processa dados à medida que chegam, permitindo insights e ações imediatos.
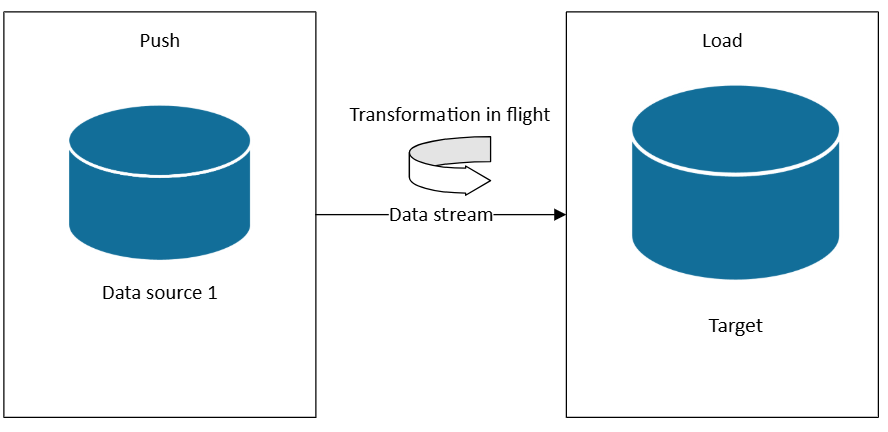
Em uma arquitetura de streaming, os dados são ingeridos de fontes de eventos em um agente de mensagens ou hub de eventos (como Hubs de Eventos do Azure ou Kafka) e processados por um processador de fluxo (como Fabric Real-Time Intelligence, Azure Stream Analytics ou Apache Flink). O processador aplica transformações como filtragem, agregação, enriquecimento ou junção com dados de referência, tudo em movimento, antes de rotear resultados para sistemas downstream, como dashboards, alertas ou bancos de dados.
Essa abordagem é ideal para cenários em que a baixa latência e as atualizações contínuas são críticas, como:
- Monitoramento de equipamentos de fabricação para anomalias
- Detectando fraudes em transações financeiras
- Alimentando painéis em tempo real para logística ou operações
- Disparando alertas com base nos limites do sensor
Considerações de confiabilidade para streaming
- Usar o ponto de verificação para garantir o processamento pelo menos uma vez e recuperar-se de falhas
- Transformações de design a serem idempotentes para lidar com o processamento duplicado potencial
- Implementar marca d'água para eventos de chegada tardia e processamento fora de ordem
- Usar filas de mensagens mortas para mensagens que não podem ser processadas
Opções de tecnologia
Armazenamentos de dados:
- Armazenamentos de dados OLTP (Processamento de Transações Online)
- Armazenamentos de dados OLAP (processamento analítico online)
- Data warehouses
Pipeline e orquestração:
- Orquestração de pipeline
- Microsoft Fabric Data Factory (orquestração moderna)
- Azure Data Factory (cenários híbridos e não fabric)
Lakehouse e análise moderna: