Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Muitos ISVs (fornecedores de software independentes) pensam em mudar da entrega de software local para um modelo de entrega baseado em nuvem e baseado em software como serviço (SaaS). Na Microsoft, passamos por essa jornada com muitos de nossos produtos, e somos convidados a compartilhar nossas experiências reais e as principais lições que aprendemos ao longo do caminho.
Nosso objetivo com este artigo é dar uma visão geral de como essa jornada foi executada quando criamos o Microsoft Dynamics 365. Descrevemos o processo de pensamento que passamos e os principais fatores para cada uma das principais decisões que tomamos. Esperamos que este documento forneça uma noção da evolução do nosso produto à medida que passamos do fornecimento de software local para um produto SaaS de hiperescala usado por milhões de usuários em milhares de organizações. Esperamos que, lendo este documento, você possa aprender com nossas experiências e planejar sua própria jornada para SaaS. Embora o percurso da Microsoft com o Dynamics 365 possa ser exclusivo, acreditamos que as lições e os princípios que aprendemos ainda podem fornecer insights valiosos para organizações de qualquer tamanho que estejam planejando sua própria transição para um modelo de SaaS.
Uma breve história de nossa jornada
O Microsoft Dynamics tem um histórico profundo como um conjunto de produtos locais. Adotamos a nuvem para todos os muitos benefícios oferecidos, e sabíamos que nosso modelo de tecnologia e negócios precisaria se adaptar à medida que avançamos para fornecer SaaS.
A primeira decisão que confrontamos foi a escolha entre criar algo novo ou evoluir nossos aplicativos locais em serviços de nuvem. Para o Dynamics 365, acreditamos em duas coisas. Primeiro, havia valor suficiente nos modelos de dados e na lógica de negócios que criamos e validamos com milhares de clientes que valia a pena evoluir nossas soluções existentes. Em segundo lugar, a arquitetura em camadas e a estrutura de plataforma de nossos produtos locais forneceram as alavancas certas para nos permitir adotar uma ótima arquitetura de nuvem mais rapidamente do que começar do zero. A combinação de valor e velocidade, juntamente com a compreensão de que poderíamos adotar princípios nativos de nuvem, tornou a mudança para SaaS baseada em nuvem e o aprimoramento contínuo a escolha certa para o Dynamics 365. Outras organizações podem ter prioridades diferentes e chegar a uma estratégia diferente.
No início, decidimos nos concentrar na criação do melhor produto que poderíamos criar na plataforma do Microsoft Azure. As plataformas de nuvem melhoram rapidamente e queríamos aproveitar a riqueza de uma plataforma, em vez de espalhar nossos recursos entre várias nuvens. Outros fornecedores de SaaS podem tomar decisões diferentes com base em suas próprias situações. Por exemplo, um provedor de plataforma horizontal pode criar software para os clientes usarem em várias nuvens, portanto, faz sentido que eles tenham uma presença em cada uma dessas plataformas de nuvem. Mas um desenvolvedor de aplicativos SaaS pode fazer uma escolha para se concentrar em uma nuvem e obter os benefícios de se concentrar nesse provedor de nuvem e em sua evolução. Para o Dynamics 365, sabíamos que fazer tudo no Microsoft Azure nos daria uma experiência mais integrada e perfeita, mantendo a segurança robusta e o alto desempenho.
Quando começamos a explorar profundamente a plataforma do Azure e planejar nossa jornada de SaaS, aprendemos a operar e dimensionar uma plataforma de ERP (planejamento de recursos corporativos) maciça na nuvem. Ao mesmo tempo, o Azure tornou-se mais rico e mais capaz e introduziu novos recursos que não poderíamos imaginar. Sabíamos que a constante evolução da nuvem significava que nossa migração não seria uma coisa única. Em vez disso, pensamos em melhoria contínua em cada etapa de nossa jornada. A melhoria contínua afeta tudo o que fazemos e, nos estágios iniciais de nossa jornada, tivemos que fazer alterações significativas, desde nossa arquitetura geral até como lidamos com consultas de banco de dados. Estamos constantemente evoluindo nossa solução para aproveitar ao máximo o que a nuvem permite. Adotamos a arquitetura de microsserviço e usamos a IA generativa como parte de nossa evolução contínua. Essas abordagens e tecnologias são mais fáceis de criar, implantar e operar quando você usa uma plataforma de nuvem poderosa como o Microsoft Azure.
Um ingrediente essencial da melhoria contínua na nuvem é a telemetria. Com uma telemetria eficaz, você pode entender como o aplicativo é usado e como ele é executado, até mesmo até o nível de recursos individuais. A telemetria fornece insights que permitem resolver problemas sabendo o que aconteceu em vez de seguir abordagens locais tradicionais, como reproduzir o problema e depurar. A telemetria também permite que você tome decisões de engenharia com base em dados reais e confirme as hipóteses do produto por meio de experimentos e dados. A criação de uma infraestrutura de telemetria junto com as políticas certas em torno de quais dados são retidos e por quanto tempo e como eles são gerenciados é algo que deve ser feito o mais cedo possível.
Entender as políticas de retenção e classificação de dados para os dados gerenciados pelo aplicativo também requer atenção extra como parte do percurso para SaaS. Como um provedor de SaaS, suas responsabilidades sob as leis de privacidade de dados atuais e emergentes são diferentes de quando você forneceu software que os clientes implantaram e executaram sozinhos. É essencial que você entenda os regulamentos de privacidade de dados que se aplicam a você como um provedor de SaaS. Você também precisa colocar seus processos de retenção e classificação de dados em vigor no início de seu percurso na nuvem.
Como nos preparamos para a viagem
Definindo o escopo de um MVP
Nossa estratégia se concentrou na criação de um MVP (produto mínimo viável) para que pudéssemos obter a solução aos clientes o mais rápido possível e começar a aprender sobre os desafios e oportunidades exclusivos do SaaS. Esse foco foi uma escolha estratégica. Acreditamos que o aprendizado rápido e a iteração são essenciais na nuvem e definir o MVP é um lugar para começar.
O termo produto mínimo viável geralmente é mal compreendido. É importante considerar que ambos os atributos do MVP são igualmente importantes:
- Mínimo: Encontre a maneira mais rápida de começar a gerar valor para seus clientes. Quanto mais cedo seus clientes usarem sua solução, mais cedo você começará a aprender como eles a usam e como você pode continuar a melhorá-la.
- Viável: é fundamental que você defina o escopo do seu produto para que ele seja completo o suficiente para que alguém obtenha valor real com ele. Inicialmente, você escolhe um subconjunto das funcionalidades gerais que espera criar. Escolher o subconjunto certo é importante — se o produto for muito mínimo para ser viável, os clientes não o usarão, e você não obterá os comentários de que precisa para evoluí-lo.
Para o Dynamics 365, nos concentramos em criar um produto que estava pronto para os clientes usarem desde seu lançamento. Em seguida, descobrimos como os clientes obtiveram valor com isso e obtivemos uma grande quantidade de comentários e telemetria. Usamos esses dados para informar nosso percurso do produto, iterando e tornando-os melhores e melhores à medida que progredimos.
Nossa estratégia era criar um produto que os novos clientes adorariam. Embora tenhamos sido intencionais em facilitar as migrações de clientes locais existentes, a migração era um foco secundário em comparação com a criação de um ótimo produto moderno. Essa estratégia significava que nossos novos clientes teriam uma experiência completa no Dynamics 365 desde o início. Eles também nos forneceram feedback valioso, e fizeram isso com o benefício de uma nova perspectiva. Eles ainda não foram fortemente investidos nos produtos locais do Dynamics, então eles nos ajudaram a construir um produto que realmente era nativo de nuvem e uma oferta completa de SaaS. À medida que continuamos a melhorar e expandir nossas funcionalidades, finalmente chegamos ao ponto em que o conjunto de recursos era um superconjunto dos produtos locais. Nesse ponto, poderíamos começar a dar suporte à transição de nossos clientes existentes da versão local para o Dynamics 365 mais avançado.
Escolhemos conscientemente essa estratégia porque sabíamos que ela funcionaria bem para um sistema ERP. Em outros produtos, pode ser possível escolher um subconjunto dos recursos do produto para mover primeiro e, em seguida, adicionar mais recursos ao longo do tempo. Mas em um ERP, os componentes são fortemente interconectados. O produto não é útil até que haja uma integração de funcionalidades em todos esses componentes, proporcionando uma experiência completa de ponta a ponta aos clientes. O escopo do MVP é uma abordagem horizontal de funcionalidades em cada componente. Decidimos selecionar um conjunto de funcionalidades transversais que dariam suporte aos casos de uso de novos clientes.
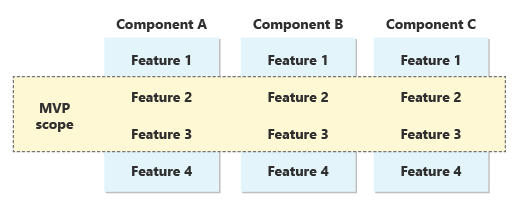
Para outras soluções, pode fazer sentido definir o escopo de um MVP como um componente inteiro. É importante tomar uma decisão consciente sobre a estratégia que você segue quando embarca em sua própria jornada para SaaS. A chave é que a entrega inicial para o mercado deve ser o menor possível, mas ainda completa o suficiente para ser utilizada de forma real.
À medida que planejamos e melhoramos, mantivemos em mente que as expectativas dos clientes também estavam evoluindo continuamente. Em vez de migrar nosso produto em seu estado atual exato, planejamos o que os clientes precisariam quando tivéssemos um produto pronto para eles usarem. Uma viagem para SaaS juntamente com uma migração de nuvem geralmente é um esforço de longo prazo, levando meses ou até anos. É importante não perder de vista as mudanças na demanda do cliente durante esse tempo. Caso contrário, você pode gastar esforços significativos criando algo que não atende totalmente às necessidades do cliente quando ele finalmente chegar.
Uso, satisfação do cliente e custos
A receita de software local normalmente é reconhecida no ponto em que a transação de vendas ocorre e a responsabilidade pela implantação e adoção bem-sucedidas cabe ao cliente. Com um modelo de assinatura SaaS na nuvem, os clientes geralmente começam licenciando alguns assentos e só expandem sua assinatura depois que a solução for comprovada. Todos os assentos que compram, mas não usam, são um risco porque podem ser cancelados no próximo aniversário de assinatura. Como resultado, com a transição para SaaS, alteramos as principais métricas que usamos para impulsionar nossos negócios.
No mundo local do software licenciado, o foco principal era a receita. Na nuvem, o foco era o uso e a satisfação do cliente. Essas métricas se tornaram os indicadores avançados de receita e crescimento da receita. Investimos esforços para minimizar o tempo para implantação bem-sucedida, fornecendo visibilidade das licenças compradas, mas não utilizadas, e mantendo alta satisfação em todas as funções de usuário e de negócios. Desde o início, nosso foco tem sido a criação de produtos que os clientes adoram usar. Sabemos por experiência própria que, quando os clientes obtêm valor usando o produto, a receita segue. Priorizando a experiência e o uso do cliente, definimos as bases para uma estratégia de negócios bem-sucedida.
Quando você cria SaaS, o custo das mercadorias vendidas (COGS) importa muito, especialmente à medida que você dimensiona e seus custos também aumentam. Mas é melhor priorizar a satisfação e o uso primeiro. Se você fornecer uma boa experiência ao cliente, poderá otimizar os custos da entrega do serviço fazendo uso mais eficiente de seus recursos e aproveitando os novos recursos da plataforma. Se a experiência não for boa o suficiente, o uso será menor e você terá menos clientes para atender. Portanto, quando revisamos nosso progresso, nos concentramos em três indicadores principais de desempenho, em ordem de importância:
- satisfação do cliente: nossos clientes gostam da experiência de usar o produto? Quais são os comentários deles?
- Uso: Quantos usuários temos? Quantas assinaturas temos? Nosso uso está acelerando? Qual é o tempo entre compra e uso? Como podemos incentivar os clientes a usar todas as assinaturas que compram?
- COGS: quanto custa atender nossos clientes?
Também é importante pensar em como qualquer produto SaaS gera receita. Os clientes precisam entender como pagam pelo serviço e o modelo de preços precisa fazer sentido para eles. Em muitas soluções SaaS entre empresas, o número de usuários que o cliente tem é um ótimo indicador dos recursos consumidos quando os usuários usam o sistema. Quanto mais usuários usarem ativamente o sistema, mais recursos do sistema serão necessários para dar a eles uma boa experiência. O custo para o cliente reflete esse fato. Os clientes têm uma compreensão intuitiva de uma estrutura de preços baseada no usuário.
No entanto, há algumas situações em que as contagens de usuários não dão uma boa indicação dos recursos que o cliente consome. Por exemplo, quando a equipe de marketing de um cliente envia um grande número de mensagens para uma campanha de email, pode haver apenas um usuário enviando milhões de mensagens de email. Da mesma forma, um processo em segundo plano, não um usuário, importa os detalhes do pedido. É importante que os clientes entendam as métricas pelas quais são cobrados e possam prever suas faturas. Você pode optar por usar medidores como o número de contatos para os quais eles enviam mensagens de email ou o número de linhas de pedido que processam todos os meses.
A arquitetura do Dynamics 365
Identidade, autenticação e autorização
Aplicativos de negócios como o Dynamics 365 gerenciam dados de negócios de alto valor e automatizam atividades comerciais críticas. É essencial garantir que somente usuários autorizados tenham acesso aos dados e às ações do sistema. Usando a ID do Microsoft Entra, as empresas podem gerenciar o acesso ao Dynamics 365 com as mesmas ferramentas e plataformas que já usam em sua propriedade de TI. Os clientes podem aproveitar os recursos de segurança avançados, como o Acesso Condicional, sem mais trabalho de nossa parte. Os recursos para proteger seu sistema Dynamics continuam evoluindo com o investimento contínuo da Microsoft na plataforma Entra.
O Dynamics 365 atribui usuários a funções e atribui permissões para dados e ações específicos a essas funções. Essa abordagem segue um padrão comum para gerenciar a autorização além da autenticação de usuário fornecida pela Entra. Essa abordagem também fornece a capacidade do Dynamics 365 de impor requisitos de negócios de práticas recomendadas, como a separação de tarefas.
Modelo de locação
Cada organização que usa o Dynamics 365 espera que seus dados sejam mantidos seguros e isolados do acesso por outras organizações. Modelamos cada organização como um locatário e cada locatário tem muitos usuários que podem usar os produtos e trabalhar com os dados da organização. O compartilhamento de recursos reduz os componentes de custo da execução dos serviços, mas o compartilhamento deve ser equilibrado em relação aos requisitos para garantir os níveis esperados de isolamento de locatário. Felizmente, a plataforma do Azure fornece recursos avançados para permitir que os provedores de aplicativos balanceiem o custo à medida que fornecem o isolamento necessário.
Por exemplo, achamos importante manter os dados comerciais de cada locatário em um banco de dados SQL separado. Essa separação nos permite, entre outros recursos, implementar a TDE (criptografia de dados transparente) do SQL do Azure com chaves gerenciadas pelo cliente, um componente importante de nossas promessas de confiança corporativa em relação aos dados. O SQL do Azure, incluindo especificamente pools elásticos, nos dá eficiência de custo, permitindo ainda um banco de dados separado por cliente. Além de aumentar os custos de infraestrutura, a decisão de manter um banco de dados separado por locatário aumenta a complexidade de gerenciamento. Não há administradores de banco de dados (DBAs) suficientes para gerenciar bancos de dados manualmente na escala do serviço Dynamics e isso levou a um investimento significativo na automação de tarefas de gerenciamento. Para obter mais informações sobre como o Dynamics 365 funciona com bancos de dados em escala, consulte Executando bancos de dados 1M no SQL do Azure para um grande provedor de SaaS: Microsoft Dynamics 365 e Power Platform.
Para cada camada de nossa solução, nossa estratégia tem sido usar recursos nativos da plataforma do Azure para impor o isolamento de inquilinos e fornecer escala e resiliência, ao mesmo tempo em que obtenhamos eficiências de custo onde pudermos. Estamos sempre olhando para locais onde podemos otimizar nosso sistema, priorizando a segurança do locatário e fornecendo uma excelente experiência do cliente.
Selos de implantação
O Dynamics 365 opera na hiperescala. Há centenas de milhares de clientes, com milhões de usuários, cada um dependendo de nossos produtos. Esses números continuam a crescer ao longo do tempo. As soluções SaaS normalmente precisam ser projetadas para escalar e suportar clientes em todo o planeta.
Na nuvem, é fundamental passar da escala vertical para a escala horizontal sempre que possível. Se a demanda adicional puder ser atendida com a adição de mais nós (escala horizontal) em vez de tornar os nós existentes mais potentes (escala vertical), e essa relação for próxima da linear, uma abordagem baseada em expansão fornece o potencial de impulsionar uma escala ainda maior. O Dynamics 365 usa um modelo de expansão na camada de aplicativo. O monitoramento integrado detecta aumentos de carga para locatários específicos e adiciona mais nós para atender à demanda.
Em conjunto com o modelo de locatário e a arquitetura de expansão, você pode seguir o padrão Carimbos de Implantação, com cada carimbo dando suporte a um conjunto de clientes. Quando um selo se aproxima de sua capacidade máxima, você pode provisionar um novo selo e começar a implantar novos clientes lá. Usando selos, você pode dar suporte ao crescimento contínuo do cliente e expandir sua presença regional para novas geografias.
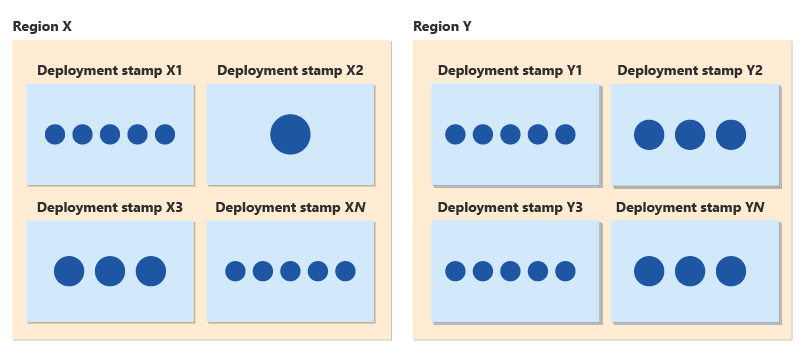
Usando selos de implantação, você também obtém benefícios de confiabilidade. Você pode distribuir nossas atualizações progressivamente e processos de implantação seguros ajudam você a implantar gradualmente as alterações em uma frota global. Cada carimbo é independente de outros, portanto, se um carimbo apresentar um problema, somente o subconjunto de clientes alocados para esse carimbo será afetado. Os carimbos ajudam você a reduzir o raio de explosão de um problema ou falha e contribuem para uma estratégia abrangente de recuperação de desastres.
Como em toda decisão de arquitetura, baseie o uso de carimbos de implantação em suas necessidades de negócios. Implantar um carimbo requer a implantação de um conjunto de infraestrutura para dar suporte a ele. Se o tamanho mínimo de um selo for muito grande, é difícil justificar a implantação de um novo selo em um novo mercado porque você precisa alcançar uma massa crítica de clientes primeiro. Também é importante entender como o crescimento dos clientes afeta o uso do produto porque, à medida que eles crescem, eles usam mais recursos do selo. Essas considerações são tão importantes para um ISV pequeno quanto para uma plataforma de hiperescala como o Dynamics 365.
Planos de controle e configuração
Quando um ISV passa para um modelo de entrega saaS baseado em nuvem, uma das alterações mais dramáticas é que eles assumem a responsabilidade pela operação do serviço. Na maioria dos softwares locais, os departamentos de TI dos clientes são responsáveis por implantar, configurar e gerenciar os sistemas. Os próprios clientes cuidam dos sistemas de monitoramento e tomam decisões sobre quando implantar atualizações. Eles também são responsáveis por executar todas as etapas envolvidas. Geralmente, parceiros de integração de serviços especializados ajudam os clientes a operar produtos complexos em seu ambiente. O provedor de software torna-se responsável por todas essas atividades em todos os seus clientes movendo-se para um modelo de nuvem e SaaS. Com a transição para SaaS, é necessário criar o serviço do ISV e também um plano de gerenciamento para automatizar o trabalho de incorporação e gerenciamento de clientes. Planos de controle e automação são importantes, mesmo com um número relativamente pequeno de clientes.
É uma boa prática projetar um plano de controle resiliente, confiável e altamente disponível. Muitas vezes, os planos de controle são tratados como uma consideração posterior na construção de um produto SaaS. Mas se um plano de controle não for projetado com o mesmo cuidado que o resto do produto, corre-se o risco de que ele se torne um único ponto de falha. Sem a devida atenção à resiliência do plano de controle, uma falha no plano de controle pode afetar todos os clientes.
No Dynamics 365, temos um plano de controle de nível de serviço, que lida com operações como integração de novos locatários. Também temos um plano de controle no nível do locatário, que permite que a equipe de administração de um cliente inicie atividades de manutenção e altere as configurações por conta própria, pois eles podem executar essas operações por meio do serviço.
Personalização e extensibilidade
Uma proposta de valor principal do modelo SaaS é que todos os clientes executam uma versão do código de serviço. Quando os clientes executam uma versão do código de serviço, os problemas são identificados e corrigidos uma vez e todos os clientes obtêm o benefício dessas soluções rapidamente. A meta é poder evoluir continuamente a única versão do serviço sem que os clientes precisem planejar testes e implantação de atualizações.
Para obter esse benefício, há muitas alterações necessárias em comparação com a execução de software no mundo local. Por exemplo, você precisa planejar processos e procedimentos para reduzir a probabilidade de regressões.
Na transformação Dynamics 365, uma área na qual investimos foi o desenvolvimento de extensibilidade avançada orientada por modelos. Os aplicativos ERP exigem extensibilidade para dar suporte à integração com outros sistemas de negócios críticos e atender às necessidades funcionais exclusivas de clientes específicos. Em vez de personalizar em um nível de código-fonte, que era típico com aplicativos locais, introduzimos funcionalidades para estender modelos de dados por meio de metadados específicos do locatário e disparar a lógica estendida com base em eventos que ocorrem no sistema.
Adicionamos recursos de isolamento e governança para proteger o serviço e outros locatários contra problemas na lógica estendida de outro locatário. Nossa abordagem deu aos clientes o nível necessário de extensibilidade, mas permitiu que todos eles ainda pudessem ser executados com a mesma versão do produto. Além disso, as atualizações podem ser entregues ao produto sem que os clientes precisem mesclar nossas alterações e recompilar o código para que suas extensões funcionem com versões mais recentes do produto.
A personalização pode não ser um requisito para cada produto, mas se um produto exigir, a personalização se tornará um fator de design crítico. Você deve atender ao requisito sem comprometer os principais benefícios do modelo SaaS. Esse requisito era um foco significativo para o Dynamics 365. A extensibilidade orientada por modelo preservou a proposta de valor saaS e melhorou a capacidade dos clientes de criar e manter suas extensões.
Como projetamos o Dynamics 365 para resiliência
Como você considera seu modelo de implantação no Azure, um componente crítico a ser considerado é sua resiliência se houver problemas em um serviço dependente, por exemplo, um problema de rede, um problema de energia ou a manutenção de uma máquina virtual. No mundo local, onde a infraestrutura atende a um único locatário do cliente, muitos clientes dependem de estratégias de alta disponibilidade para cada componente de infraestrutura. Mas quando você considera a resiliência em escala de nuvem, a alta disponibilidade geralmente é necessária, mas não suficiente. Com escala suficiente, ocorrem falhas.
Uma área de foco principal do Dynamics 365 atualmente está direcionando a redundância em zonas de disponibilidade do Azure para permitir que os serviços críticos do Dynamics continuem operando perfeitamente, mesmo que uma interrupção afete um datacenter ou uma zona de disponibilidade inteira.
Para aplicar essa mentalidade à sua própria solução, há algumas práticas importantes a seguir.
- Invista em ferramentas de monitoramento para identificar rapidamente os problemas. Com o SaaS, seus clientes esperam que você saiba sobre interrupções e se envolva rapidamente para restaurar o serviço.
- Use recursos de plataforma, como zonas de disponibilidade e redundância de zona, se forem apropriados para seu serviço.
- Projete seus aplicativos para resiliência em cada camada. Por exemplo, é importante considerar também outras práticas recomendadas de nuvem, como o uso de repetições, disjuntores e bulkheads, bem como a adoção de práticas de comunicação assíncrona. Essas práticas podem manter seu serviço íntegro mesmo quando outros serviços dos quais você depende estão sob estresse.
- Considere a disponibilidade do plano de controle, especialmente porque ele tem uma função na recuperação da solução quando os ativos de infraestrutura são afetados.
- Quando você tiver implementado recursos de resiliência, execute testes. Você nunca sabe se seus planos e recursos estão concluídos até tentar usá-los. Pode ser útil exercitar seus processos de failover como parte de suas atividades normais de manutenção, proporcionando tanto uma abordagem de manutenção sem tempo de inatividade quanto uma validação de seus mecanismos de failover.
O pilar de confiabilidade do Azure Well-Architected Framework fornece ótimas diretrizes sobre esses tópicos.
Como nos adaptamos a um ambiente de nuvem
O Dynamics 365 evoluiu para uma arquitetura nativa da nuvem sofisticada, mas é comum que os ISVs façam transições lift-and-shift mais limitadas de ambientes locais para a nuvem. Discutimos o modelo de definindo um MVP para colocar seu serviço SaaS nas mãos dos clientes rapidamente, o que dá início ao ciclo de aprendizado e aperfeiçoamento contínuo. Mas há um equilíbrio. Lift-and-shift deve realmente ser levantar, deslocar e adaptar.
No início deste artigo, abordamos o design para resiliência com zonas de disponibilidade e outras práticas recomendadas de nuvem. Há outras áreas em que padrões comuns de design local levam a desafios ou custos mais altos na nuvem também. Por exemplo, em aplicativos locais, é comum armazenar objetos binários grandes em um banco de dados relacional. Por exemplo, você pode armazenar um documento PDF relacionado a um pedido de vendas como parte da ordem de vendas em um banco de dados SQL. No mundo local, essa abordagem simplifica a consistência entre backups e funções de restauração pontual. No entanto, na nuvem, objetos grandes armazenados no banco de dados podem ser caros. Além disso, os blobs do Armazenamento do Azure simplificam o armazenamento de objetos binários grandes, com lógica simples necessária para preservar backups consistentes.
É importante pensar nas coisas que você precisa fazer como parte de uma transformação de nuvem. Você deve fazer essas coisas que produzem um produto de nuvem mais forte. Mas você também deve usar isso como uma oportunidade para chegar ao mercado rapidamente e começar o ciclo virtuoso de aprendizado e melhoria contínua.
A nuvem também pode tornar soluções totalmente novas práticas que não eram uma opção em um ambiente local. Um dos processos mais intensivos em desempenho em um sistema ERP é o planejamento de recursos de fabricação, ou MRP II. O MRP II analisa o inventário em mãos, os pedidos de entrada e saída esperados e os requisitos de fabricação. Em seguida, determina o que uma empresa deve comprar ou fazer para atender aos pedidos esperados. Na versão local do Dynamics, essa funcionalidade foi implementada no código da aplicação que funcionava diretamente no repositório relacional. A função de planejamento consumiu muita capacidade do sistema e foi executada por um tempo estendido. Nas primeiras versões de nuvem, a funcionalidade local foi apresentada inalterada– funcionou, mas com os mesmos desafios de escala e desempenho. Então, há alguns anos, introduzimos um novo microsserviço na memória que poderia concluir a mesma execução de planejamento em uma fração do tempo e sem o impacto no desempenho. É importante ressaltar que, como o microsserviço é um núcleo crítico de um sistema de fabricação, introduzimos-o como uma funcionalidade que os clientes poderiam aceitar depois de verificar em seus ambientes de área restrita que ele produziu os resultados corretos. À medida que mais clientes migraram para o novo microsserviço, implementamos medidas para que todos os clientes usassem o microsserviço, permitindo que a funcionalidade antiga fosse descontinuada. Com o MRP II podendo ser executado em questão de minutos a qualquer momento, as organizações poderiam ser mais ágeis. A nuvem tornou a criação e a conexão de um microsserviço na memória prática e bons princípios de engenharia SaaS permitiram que até mesmo essa parte mais crítica do serviço evoluísse sem interromper os clientes.
Como migramos clientes existentes para a nuvem
A migração de uma base de clientes existente pode ser a maneira mais rápida de expandir um serviço de nuvem para dimensionar. No entanto, quando trouxemos o Dynamics 365 para a nuvem, nos concentramos inicialmente em novos clientes. Havia dois motivos principais:
- Essa abordagem nos deu uma maneira de avaliar se entregamos uma solução SaaS que ganhou por seus próprios méritos e não apenas uma que atraiu clientes locais que procuram uma migração de nuvem simples.
- Poderíamos nos concentrar no MVP e adiar tarefas como criar ferramentas para migrar clientes existentes.
Depois que vimos tração com novos clientes, conseguimos nos concentrar na migração de clientes locais existentes.
Descobrimos que os clientes geralmente têm medo do custo e da complexidade da mudança. Era importante fornecermos ferramentas que reduzam o custo e removem os fatores desconhecidos. Desenvolvemos ferramentas para ajudar a analisar o esforço envolvido na migração de seus dados para novos esquemas que evoluíram em nosso produto de nuvem e para entender o impacto da migração nas extensões e integrações do cliente. Também descobrimos que era útil criar outras ferramentas e programas que colocassem limites em torno do tempo e do custo para migrar.
Mover para a nuvem sozinho beneficia os clientes removendo grande parte da carga de gerenciamento de sistemas que eles enfrentam com produtos locais, mas destacar os benefícios da sua versão de nuvem também é um motivador importante.
Como aprendemos a operar o Dynamics 365 como SaaS
Depois de definir um MVP e fazer a engenharia levantar, deslocar e adaptar, você precisa se concentrar em operar o serviço SaaS em nome de seus clientes. Essa transformação é enorme. No mundo local, os provedores de software criam e enviam o software, os integradores do sistema o implantam e a organização de TI ou provedor terceirizado do cliente o executa. Com o SaaS, não só o provedor saaS é principalmente responsável por operar o serviço, mas também é responsável por operá-lo para centenas a milhares de clientes ao mesmo tempo.
Aprendemos muito operando o Dynamics 365 na nuvem para um grande e crescente número de clientes.
Monitorar: como um provedor de serviços, os clientes esperam que você detecte problemas de integridade do serviço antes deles, assim como esperam que você trabalhe imediatamente para solucioná-los. Um problema de integridade não se resume apenas à inatividade do serviço. A visão de um cliente sobre um serviço problemático inclui o serviço funcionando lentamente ou comportando-se incorretamente. É essencial que você desenvolva ferramentas de monitoramento adequadas– esse desenvolvimento faz parte do seu serviço, não um acessório opcional.
Comunicar: no mundo local, o cliente pode ver sua equipe de TI trabalhando em um problema. Na nuvem, eles não podem. É essencial comunicar quando você detectar um problema de integridade do serviço, continuar comunicando o andamento da resolução e confirmar quando tudo estiver resolvido. A natureza das comunicações varia com a gravidade do problema. O pipeline de comunicações também é uma parte central do seu serviço SaaS e você precisa garantir que as comunicações possam ser bem-sucedidas mesmo quando partes principais da infraestrutura do serviço SaaS estiverem comprometidas.
Exibir a pilha inteira: no mundo local, o provedor de aplicativos geralmente é responsável pelo componente do aplicativo e o cliente é o proprietário da infraestrutura subjacente. Na nuvem, você é responsável por todas as camadas. Se o serviço tiver um problema de integridade, o cliente procurará você para detectar, comunicar e reparar se o problema está no aplicativo ou na plataforma de nuvem em que ele é executado.
Automatizar: se os humanos forem obrigados a executar etapas manuais na operação do serviço, os erros serão inevitavelmente cometidos. Todas as ações possíveis devem ser automatizadas e registradas. Se uma ação for necessária em nós de serviço suficientes, a automação será a única opção. Um ótimo exemplo é a administração do banco de dados para o Dynamics 365. Com nossa decisão de manter os dados de cada locatário em um banco de dados SQL do Azure separado, precisávamos desenvolver a automação para lidar com todas as tarefas normalmente executadas por um DBA, por exemplo, manutenção de índice e otimização de consulta. Para obter mais informações sobre como gerenciamos bancos de dados em escala, consulte Executando bancos de dados 1M no SQL do Azure para um provedor SaaS grande.
implantação segura: sempre que possível, as alterações devem seguir um processo de implantação seguro. Primeiro, as alterações são introduzidas em ambientes de baixo risco, por exemplo, uma região de nuvem com apenas clientes menores ou cargas de trabalho menos críticas. Em seguida, eles progridem para um grupo de clientes ligeiramente maiores e mais complexos, e assim por diante, até que todos os clientes tenham sido atualizados. Em cada etapa, é necessário monitorar para avaliar se a alteração foi bem-sucedida. Se houver um problema, o processo deve interromper a distribuição da alteração e atenuar os problemas, ou revertê-la onde já tiver sido implantada. As práticas de implantação seguras se aplicam a alterações de código e de configuração. Para obter mais informações, consulte Avanço das práticas de implantação segura.
Gerenciamento de incidentes no site ativo: para nós, um incidente no site ativo significa que um cliente está tendo um problema com nosso serviço na produção que requer envolvimento de engenharia. Pode ser um problema de integridade que detectamos ou um problema relatado pelo cliente que nossas equipes de suporte não são capazes de resolver por conta própria. A excelência em sites ao vivo é fundamental para o sucesso de SaaS. Aqui estão alguns pontos importantes de nossa experiência:
- A equipe de engenharia deve lidar com incidentes no ambiente de produção. No passado, muitas empresas tinham operações separadas ou equipes de engenharia de suporte. Fizemos uma escolha explícita para que nossas principais equipes de engenharia cobrissem incidentes ao vivo. Eles têm a melhor experiência, e ver questões em primeira mão inspira a criatividade e a energia certas para impulsionar melhorias reais, rápidas e melhores projetos futuros. É algo que precisa ser considerado ao planejar agendas de desenvolvimento, mas gera ótimos resultados.
- A liderança de incidentes no site ativo é uma habilidade, além de ser um trabalho árduo – reconheça-a, prepare-se para ela, aprenda para contratar quem a domina e recompense por ela.
- A prioridade deve ser detecção, isolamento e mitigação. Torne o cliente saudável novamente, e depois preocupe-se com melhorias de longo prazo.
Aprenda e melhore: Alguém disse uma vez: "Nunca desperdice uma boa crise". Cada incidente no site ativo é uma oportunidade de melhorar. Após a conclusão da mitigação, pergunte como detectar problemas semelhantes mais rapidamente, como corrigir o problema subjacente para curá-lo completamente, como minimizar o impacto de problemas semelhantes, se outros problemas semelhantes podem existir em outros lugares do serviço e como evitar toda a classe de problemas. Priorizar essas ações corretivas melhora a qualidade do serviço e reduz a demanda por futuros incidentes ao vivo. A qualidade do serviço deve melhorar ao longo do tempo, caso contrário, à medida que você cresce, o impacto de cada problema também aumenta.
Shift-left: problemas que exigem o engajamento da equipe no site ativo são caros. Leva tempo para que os problemas cheguem até eles, e a equipe do site ativo é um recurso escasso que precisa estar disponível para os problemas mais sérios de integridade do serviço e tarefas de gerenciamento.
Sempre que possível, a melhor solução é eliminar um problema completamente, seguido rapidamente pela detecção automatizada e mitigação automatizada. Quando isso não é possível, a metodologia shift-left ajuda a capacitar a equipe de suporte de linha de frente para detectar e corrigir o problema ou executar a tarefa, ou ainda melhor, capacitar o cliente a se autoatender e executar a tarefa por conta própria. O diagrama a seguir mostra como os casos de suporte começam com um cliente, vão para uma equipe de suporte de linha de frente e, em seguida, para a equipe de engenharia. Uma seta indica que deslocamos a ação de resolução para a esquerda para reduzir o impacto dos incidentes.

Manter as coisas padrão: pode ser tentador atenuar um problema fazendo arranjos especiais para um cliente. Em escala, tudo o que é especial se torna um caso secundário que causa alguma outra falha. Procure manter o uso de código, definições e configurações padrão em todos os locatários.
Inovação contínua
Ao longo deste artigo, falamos sobre a necessidade de levar seu produto para a nuvem e iniciar o ciclo virtuoso de aprendizado contínuo e melhoria contínua. A inovação contínua é uma expectativa para a maioria dos produtos SaaS. Mas quando um produto SaaS é o sucessor de um produto local de longa data, provavelmente é preciso um gerenciamento de mudanças significativo para preparar os clientes para inovação contínua.
Aqui estão três áreas de foco principais da nossa transformação do Dynamics 365:
Manutenção de tempo de inatividade quase zero: à medida que o número de clientes em várias empresas e locais aumenta, torna-se impossível encontrar janelas de manutenção universalmente aceitáveis. Você precisa criar maturidade de engenharia para que as atividades de manutenção possam acontecer enquanto o sistema estiver online. Em particular, a implantação de atualizações de serviço precisa acontecer com o tempo de inatividade o mais próximo possível de zero.
Eliminar regressões: é preciso confiança do cliente para depender de um serviço crítico com uma política de inovação contínua. Essa confiança é conquistada aos poucos com o êxito das operações diárias e a cada atualização de serviço realizada sem percalços. Infelizmente, perdê-la é mais fácil; ela se vai rapidamente e de uma vez, com qualquer regressão, não importa quão pequena seja. Vale a pena fazer tudo o que você pode fazer que elimina regressões no processo de engenharia, especialmente usando processos de implantação seguros.
Sinalizadores de recursos: a equipe do Dynamics 365 investiu extensivamente em uma estrutura de sinalizadores de recursos. Um sinalizador de recurso pode ser habilitado ou desabilitado para todo o serviço, para subconjuntos de locatários ou até mesmo para um único locatário. Usando sinalizadores de recursos, habilitamos a introdução de novos recursos sem interromper a operação dos processos de negócios críticos aos quais o Dynamics 365 dá suporte.
Veja como as feature flags podem ajudar:
- Uma correção de segurança ou desempenho simples pode ser introduzida com o sinalizador habilitado por padrão. Todos devem obter o benefício da mudança imediatamente.
- Algo que altera a experiência de um usuário, um processo de negócios ou o comportamento de uma API visível externamente é introduzido com o sinalizador desativado por padrão.
- Alterar um sinalizador de recurso é efetivamente alterar o código que é executado, portanto, as alterações no sinalizador de recurso também devem ser gerenciadas por meio da implantação segura. Por exemplo, suponha que você introduza uma correção para um problema e desative o sinalizador de recurso para a correção por padrão. Você pode habilitar o sinalizador para clientes que relataram o bug original. Em seguida, você pode avançar lentamente habilitando o sinalizador em círculos de clientes cada vez maiores até que ele seja ativado para todos.
- Se uma correção for introduzida quando o sinalizador estiver ativado por padrão e a correção tiver um problema, ela poderá ser revertida logicamente instantaneamente, desativando o sinalizador.
- Os sinalizadores de recursos também podem ser usados para divulgar seletivamente os recursos em versão prévia ou para ocultar seletivamente recursos de novos clientes como parte de um processo de substituição.
- Você pode fornecer visibilidade de novos sinalizadores de recursos e configurações de sinalizadores de recursos específicas de locatário para equipes de suporte de linha de frente e de site ativo. Essas informações ajudam as equipes a incluir ou excluir rapidamente uma nova mudança de funcionalidade quando investigam um problema. Se necessário, as equipes também podem ajustar as configurações dos feature flags para atenuar o problema.
- Por fim, você precisa gerenciar o ciclo de vida dos sinalizadores de recursos para evitar que a base de código seja insuportável. Estabeleça um processo para remover sinalizadores de recursos do código depois que eles forem totalmente implantados e comprovados.
Conclusão
A transição de um produto local para SaaS requer alterações significativas em cada parte de como você fornece software aos clientes e em todas as partes da sua empresa. As mudanças culturais são tão significativas quanto as mudanças técnicas: passar de uma cadência de lançamento local ocasional para uma cadência de lançamento regular é uma grande mudança, assim como adotar processos e uma cultura de site ativo exige esforço. Você precisa garantir que sua equipe esteja bem preparada para a jornada e que você expanda seu pool de talentos além dos engenheiros para garantir que você tenha pessoas que saibam como operar SaaS em escala.
Muitas organizações não sobrevivem a transições dessa magnitude, especialmente se um novo concorrente aparecer que já está nativamente na nuvem. Para se preparar para o sucesso, você deve definir cuidadosamente o escopo de um MVP, levá-lo à produção o mais rápido possível e, em seguida, iterar e aprimorá-lo rapidamente. O processo de transição geralmente é o momento mais difícil, portanto, é bom fazer a transição para a nuvem o mais rápido possível.
Aqui estão as principais considerações que esperamos que você tire de nossas experiências e algumas das decisões que você precisa tomar para sua própria jornada.
- Decida sobre seu próprio caminho. Se você tiver um aplicativo existente com funcionalidade avançada e uma base de clientes local estabelecida, poderá fazer sentido mudar para um modelo SaaS baseado em nuvem. O percurso de cada produto é diferente e você precisa considerar as decisões e perguntas separadamente, com base em suas próprias necessidades. Inspire-se em outras jornadas, mas forja seu próprio caminho.
- Determine uma estratégia. Ter um produto com clientes estabelecidos significa que você precisa decidir como criar suas prioridades. Você pode se concentrar na criação de um produto que funcione bem para novos clientes imediatamente. Você pode se concentrar em migrar sua base de clientes existente para seu novo serviço o mais rápido possível. O motivo pelo qual você está se movendo e sua capacidade de fazer mudanças significativas influencia a direção que você toma.
- Decida se você usará uma única nuvem ou multinuvem. Avalie se faz mais sentido concentrar seus esforços em uma única nuvem ou distribuir seus recursos de engenharia em várias nuvens. Se você estiver criando um componente de plataforma, uma estratégia multinuvem pode fazer sentido. Se você estiver criando um aplicativo, uma estratégia de nuvem única poderá fornecer benefícios ao usar uma plataforma consistente e integrada.
- Planeje de forma específica para a nuvem. Uma abordagem lift-and-shift para migrar para a nuvem não é suficiente. Você precisa planejar como aproveitar a elasticidade da nuvem e como operar um serviço em um ambiente de nuvem. Automação, resiliência, escala, segurança, desempenho e observabilidade são considerações importantes. Você não precisa fazer tudo antecipadamente, mas precisa saber o destino para que possa planejar um roteiro.
- Planeje especificamente para SaaS. Um modelo de negócios saaS tem uma aparência diferente em comparação com uma abordagem de entrega de software local. Os clientes esperam contas de avaliação, modelos de cobrança compreensíveis, um serviço totalmente gerenciado e escala dinâmica com base em suas necessidades.
- Aterrisse, aprenda e itere. Planeje um escopo de MVP, identifique os resultados iniciais que você pode alcançar e, em seguida, alcance-os rapidamente. Quando você estiver lá, confirme a melhoria contínua.
- Quando você estiver na nuvem, aproveite-a. A nuvem fornece muitos recursos que as soluções locais não têm. As capacidades incluem escala maciça, elasticidade e a capacidade de usar componentes de plataforma de nuvem para criar e iterar rapidamente suas ideias. Considere como você pode usar tecnologias como IA generativa, microsserviços e outras abordagens difíceis de usar fora de um ambiente de nuvem.
- Torne-se o departamento de TI do cliente. As expectativas do cliente mudam quando você está fornecendo um serviço de ponta a ponta. Planeje-se para poder usar a abordagem shift-left. Verifique se você tem uma funcionalidade abrangente de monitoramento e auto-recuperação.
- Aprenda com o uso do cliente. Ao executar um serviço, você coleta uma grande quantidade de dados úteis sobre como os clientes usam seu produto. Adote uma cultura de dados. Saiba mais sobre seus clientes, o que eles fazem e como eles fazem isso. Experimente e seja ágil o suficiente para alterar sua abordagem quando os dados indicarem que algo não é o esperado.
- Forneça valor contínuo por meio de atualizações. Pense em quando e como implantar atualizações. Planeje corrigir problemas rapidamente ou fazer fallback para versões anteriores. Decida como lidar com as mudanças radicais. Evite alterações pontuais para clientes específicos, pois cada ponto de diferença é uma oportunidade para algo dar errado.
A maior lição que aprendemos é que a jornada para SaaS nunca termina. Um roteiro de produto é um documento vivo que está em constante evolução. Você sempre tem muitos itens na lista de pendências para melhorar seu produto, tanto para adicionar novos recursos quanto para melhorar a forma como você opera e entrega o produto. A entrega de SaaS requer melhoria contínua em seus processos, investimento em qualidade e vigilância para garantir que você forneça um serviço confiável, seguro, de desempenho e confiável para seus clientes. Os avanços em tecnologias, como a IA generativa, trazem uma tremenda oportunidade para você fornecer recursos que eram inimagináveis antes.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos colaboradores a seguir.
- Mike Ehrenberg - Brasil | Diretor de tecnologia, Microsoft Dynamics
- John Downs | Engenheiro de software principal
- Arsen Vladimirsky | Engenheiro de cliente principal