Padrão de eleição de líder
Coordene as ações executadas por uma coleção de instâncias de colaboração em um aplicativo distribuído elegendo uma instância como o líder que assume a responsabilidade de gerenciar as demais. Isso pode ajudar a garantir que as instâncias não entrem em conflito com outras, causar contenção de recursos compartilhados ou interferir inadvertidamente no trabalho que outras instâncias estão executando.
Contexto e problema
Um aplicativo de nuvem típico tem muitas tarefas que funcionam de maneira coordenada. Essas tarefas poderiam ser instâncias que executam o mesmo código e precisam de acessar aos mesmos recursos ou podem estar trabalhando juntas em paralelo para executar as partes individuais de um cálculo complexo.
As instâncias de tarefa poderão ser executadas separadamente pela maior parte do tempo, mas também pode ser necessário coordenar as ações de cada instância para garantir que não entrem em conflito, causem contenção dos recursos compartilhados ou interfiram acidentalmente no trabalho que outras instâncias de tarefa estão executando.
Por exemplo:
- Em um sistema baseado em nuvem que implementa o dimensionamento horizontal, várias instâncias da mesma tarefa podem estar em execução ao mesmo tempo com cada instância atendendo a um usuário diferente. Se essas instâncias gravarem em um recurso compartilhado, será necessário coordenar suas ações para impedir que cada instância substitua as alterações feitas por outras.
- Se as tarefas estão executando elementos individuais de um cálculo complexo em paralelo, os resultados precisam ser agregados quando todos forem concluídos.
Todas as instâncias de tarefa são pares, portanto não há um líder natural que possa atuar como o coordenador ou agregador.
Solução
Uma única instância de tarefa deve ser eleita para atuar como líder e essa instância deve coordenar as ações de outras instâncias de tarefa subordinada. Se todas as instâncias de tarefa executarem o mesmo código, qualquer uma delas poderá atuar como o líder. Portanto, o processo de eleição deve ser gerenciado com cuidado para evitar que duas ou mais instâncias assumam a posição de líder ao mesmo tempo.
O sistema deve fornecer um mecanismo robusto para selecionar o líder. Esse método precisa lidar com eventos como interrupções da rede ou falhas de processo. Em muitas soluções, as instâncias de tarefa subordinadas monitoram o líder por meio de algum tipo de método de pulsação ou por meio de sondagem. Se o líder designado terminar inesperadamente ou se uma falha de rede deixar o líder indisponível para as instâncias de tarefa subordinadas, será necessário eleger um novo líder.
Há várias estratégias para eleger o líder entre um conjunto de tarefas em um ambiente distribuído, incluindo:
- Corrida para adquirir um mutex compartilhado e distribuído. A primeira instância de tarefa que adquirir o mutex é o líder. No entanto, o sistema deve garantir que, se o líder for encerrado ou desconectado do restante do sistema, o mutex será liberado para permitir que outra instância de tarefa torne-se o líder. Essa estratégia é demonstrada no exemplo abaixo.
- Implementação de um dos algoritmos comuns de eleição de líder, como o Bully Algorithm, o Raft Consensus Algorithm, ou o Ring Algorithm. Esses algoritmos presumem que cada candidato na eleição tem uma ID exclusiva e que ele pode se comunicar com os outros candidatos de maneira confiável.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão:
- O processo de eleger um líder deve ser resistente a falhas transitórias e persistentes.
- Deve ser possível detectar quando o líder falhou ou ficou indisponível (por exemplo, devido a uma falha de comunicação). A rapidez de detecção necessária depende do sistema. Alguns sistemas podem funcionar por um curto período sem um líder, durante o qual uma falha temporária pode ser corrigida. Em outros casos, pode ser necessário detectar a falha do líder imediatamente e disparar uma nova eleição.
- Em um sistema que implementa o dimensionamento automático horizontal, o líder poderia ser terminado se o sistema for reduzido e desligar alguns dos recursos de computação.
- Usar um mutex compartilhado e distribuído apresenta uma dependência do serviço externo que fornece o mutex. O serviço constitui um ponto único de falha. Se ele ficar indisponível por qualquer motivo, o sistema não poderá eleger um líder.
- Usar um único processo dedicado como o líder é uma abordagem simples. No entanto, se o processo falhar, poderá ocorrer um atraso significativo enquanto ele é reiniciado. A latência resultante pode afetar o desempenho e os tempos de resposta de outros processos se eles estiverem esperando o líder coordenar uma operação.
- Implementar um dos algoritmos de eleição de líder manualmente oferece a maior flexibilidade possível para ajustar e otimizar o código.
- Evite transformar o líder em um gargalo no sistema. É a finalidade do líder coordenar o trabalho das tarefas subordinadas, e ele não precisa necessariamente participar desse trabalho em si — embora deva ser capaz de fazer isso se a tarefa não for eleita como o líder.
Quando usar esse padrão
Use esse padrão quando as tarefas em um aplicativo distribuído, como uma solução hospedada na nuvem, precisarem de coordenação cuidadosa e não houver nenhum líder natural.
Esse padrão pode não ser útil se:
- Há um líder natural ou processo dedicado que sempre pode atuar como o líder. Por exemplo, seria possível implementar um processo de singleton que coordena as instâncias de tarefa. Se esse processo falhar ou se tornar não íntegro, o sistema poderá desligá-lo e reiniciá-lo.
- A coordenação entre as tarefas pode ser alcançada usando um método mais simples. Por exemplo, se várias instâncias de tarefa precisam simplesmente de acesso coordenado a um recurso compartilhado, uma solução melhor é usar o bloqueio otimista ou pessimista para controlar o acesso.
- Uma solução de terceiros, como o Apache Zookeeper , pode ser uma solução mais eficiente.
Design de carga de trabalho
Um arquiteto deve avaliar como o padrão de Eleição de Líder pode ser usado no design das suas cargas de trabalho para abordar os objetivos e princípios dos pilares da estrutura bem arquitetada do Azure. Por exemplo:
| Pilar | Como esse padrão apoia os objetivos do pilar |
|---|---|
| As decisões de design de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Esse padrão atenua o efeito de mau funcionamento do nó redirecionando o trabalho de forma confiável. Ele também implementa failover por meio de algoritmos de consenso quando um líder funciona mal. - RE:05 Redundância - RE:07 Autorrecuperação |
Tal como acontece com qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com este padrão.
Exemplo
O exemplo de Eleição de Líder no GitHub mostra como usar uma concessão em um blob de Armazenamento do Azure para fornecer um mecanismo para implementar um mutex compartilhado e distribuído. Esse mutex pode ser usado para eleger um líder entre um grupo de instâncias de trabalho disponíveis. A primeira instância a adquirir a concessão é eleita como líder e permanece dessa forma até liberar a concessão ou não for capaz de renová-la. Outras instâncias de trabalhador podem continuar a monitorar a concessão de blob caso o líder não esteja mais disponível.
Uma concessão de blob é um bloqueio de gravação exclusivo em um blob. Um único blob pode estar sujeito a apenas uma concessão ao mesmo tempo. Uma instância de trabalhador pode solicitar uma concessão em um blob especificado e ele receberá a concessão se nenhuma outra instância de trabalhador mantém uma concessão no mesmo blob. Caso contrário, a solicitação gerará uma exceção.
Para evitar que uma instância de líder com falha retenha a concessão indefinidamente, especifique um tempo de vida para a concessão. Quando ele expirar, a concessão ficará disponível. No entanto, enquanto uma instância contém a concessão, ela pode solicitar a renovação da concessão e ela será concedida por um período adicional. A instância de líder pode repetir continuamente esse processo se desejar manter a concessão. Para obter mais informações sobre como conceder um blob, consulte Blob de concessão (API REST).
A classe BlobDistributedMutex no exemplo de C# a seguir contém o método RunTaskWhenMutexAcquired que permite que uma instância de trabalhador tente adquirir uma concessão em um blob especificado. Os detalhes do blob (o nome, contêiner e conta de armazenamento) são passados para o construtor em um objeto BlobSettings quando o objeto BlobDistributedMutex é criado (esse objeto é uma struct simples incluído no código de exemplo). O construtor também aceita um Task que referencia o código que a instância de trabalhador deve executar se adquirir a concessão do blob com êxito e for eleito como líder. Observe que o código que manipula os detalhes de nível baixo da aquisição da concessão é implementado em uma classe auxiliar separada chamada BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
O método RunTaskWhenMutexAcquired no exemplo de código acima invoca o método RunTaskWhenBlobLeaseAcquired mostrado no exemplo de código a seguir para, na verdade, adquirir a concessão. O método RunTaskWhenBlobLeaseAcquired é executado de forma assíncrona. Se a concessão for adquirida com êxito, a instância de trabalhador foi eleita como o líder. A finalidade do delegado taskToRunWhenLeaseAcquired é executar o trabalho que coordena as outras instâncias de trabalhador. Se a concessão não for adquirida, outra instância de trabalhador foi eleita como o líder e a instância de trabalhador atual permanece sendo uma subordinada. Observe que o TryAcquireLeaseOrWait é um método auxiliar que usa o objeto BlobLeaseManager para adquirir a concessão.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
A tarefa iniciada pelo líder também é executada assincronamente. Enquanto essa tarefa está em execução, o método RunTaskWhenBlobLeaseAcquired mostrado no exemplo de código a seguir tenta periodicamente renovar a concessão. Isso ajuda a garantir que a instância de trabalhador permaneça sendo o líder. Na solução de exemplo, o atraso entre as solicitações de renovação é menor que o tempo especificado para a duração da concessão a fim de impedir que outra instância de trabalhador seja eleita como o líder. Se a renovação falhar por algum motivo, a tarefa específica de líder será cancelada.
Se a concessão não puder ser renovada ou a tarefa for cancelada (provavelmente devido ao desligamento da instância de trabalhador), a concessão será liberada. Neste ponto, essa ou outra instância de trabalhador pode ser eleita como líder. A extração de código abaixo mostra essa parte do processo.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
O KeepRenewingLease é outro método auxiliar que usa o objeto BlobLeaseManager para renovar a concessão. O método CancelAllWhenAnyCompletes cancela as tarefas especificadas como os dois primeiros parâmetros. O diagrama a seguir ilustra o uso da classe BlobDistributedMutex para eleger o líder e executar uma tarefa que coordena as operações.
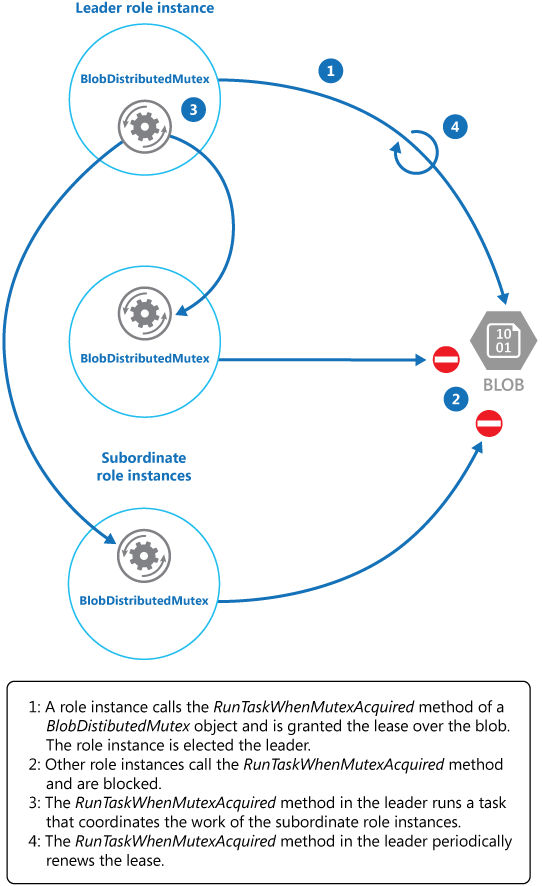 A Figura 1 ilustra as funções da classe BlobDistributedMutex
A Figura 1 ilustra as funções da classe BlobDistributedMutex
O exemplo de código a seguir mostra como usar a classe BlobDistributedMutex em uma instância de trabalhador. Esse código adquire uma concessão em um blob denominado MyLeaderCoordinatorTask no contêiner do Azure Blob Storage da concessão no armazenamento de desenvolvimento e especifica que o código definido no método MyLeaderCoordinatorTask deve ser executado se a instância de trabalhador for eleita como líder.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Observe os pontos a seguir sobre a solução de exemplo:
- O blob é um ponto único de falha em potencial. Se o serviço Blob ficar indisponível ou estiver inacessível, o líder não poderá renovar a concessão e nenhuma outra instância de trabalhador poderá adquiri-la. Nesse caso, nenhuma instância de trabalhador será capaz de atuar como o líder. No entanto, o serviço Blob é projetado para ser resiliente, por isso uma falha completa do serviço Blob é considerada extremamente improvável.
- Se a tarefa que está sendo executada pelo líder parar, ele poderá continuar a renovar a concessão, impedindo que qualquer outra instância de trabalhador adquira a concessão e assuma a posição de líder para coordenar tarefas. No mundo real, a integridade do líder deve ser verificada em intervalos frequentes.
- O processo de eleição é não determinístico. Você não pode fazer suposições sobre qual instância de trabalhador obterá a concessão de blob e se tornará o líder.
- O blob usado como o destino da concessão de blob não deve ser usado para nenhuma outra finalidade. Se uma instância de trabalhador tentar armazenar dados nesse blob, tais dados não poderão ser acessados, a menos que a instância de trabalhador seja o líder e possua a concessão de blob.
Próximas etapas
As diretrizes a seguir também podem ser relevantes ao implementar esse padrão:
- Esse padrão tem um aplicativos de exemplo baixável.
- Diretrizes de dimensionamento automático. É possível iniciar e parar instâncias dos hosts de tarefa à medida que a carga do aplicativo varia. O dimensionamento automático pode ajudar a manter a taxa de transferência e o desempenho durante horários de pico de processamento.
- O Padrão assíncrono baseado em tarefa.
- Um exemplo que ilustra o Algoritmo Bully.
- Um exemplo que ilustra o Algoritmo Ring.
- O Apache Curator é uma biblioteca de cliente para o Apache ZooKeeper.
- O artigo Blob de Concessão (API REST) no MSDN.