Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A migração do bancos de dados Exadata de alto desempenho para a nuvem está se tornando cada vez mais imperativo para os clientes da Microsoft. Os pacotes de software da cadeia de suprimentos normalmente definem o alto padrão devido às intensas demandas de E/S de armazenamento com uma carga de trabalho de leitura e gravação mista impulsionada por um único nó de computação. A infraestrutura do Azure em combinação com o Azure NetApp Files é capaz de atender às necessidades dessa carga de trabalho altamente exigente. Este artigo apresenta um exemplo de como essa demanda foi atendida para um cliente e como o Azure pode atender às demandas de suas cargas de trabalho críticas do Oracle.
Desempenho do Oracle de escala empresarial
Ao explorar os limites superiores do desempenho, é importante reconhecer e reduzir quaisquer restrições que possam distorcer falsamente os resultados. Por exemplo, se a intenção for provar os recursos de desempenho de um sistema de armazenamento, o cliente deverá ser configurado de forma ideal para que a CPU não se torne um fator atenuante antes que os limites de desempenho de armazenamento sejam atingidos. Para esse fim, o teste começou com o tipo de instância E104ids_v5, pois essa VM vem equipada não apenas com um adaptador de rede de 100 Gbps, mas com um limite de saída igualmente grande (100 Gbps).
O teste ocorreu em duas fases:
- A primeira fase se concentrou no teste usando a ferramenta SLOB2 padrão do setor de Kevin Closson (Silly Little Oracle Benchmark) – versão 2.5.4. A meta é direcionar o máximo possível de E/S do Oracle de uma VM (máquina virtual) para vários volumes do Azure NetApp Files e, em seguida, escalar horizontalmente usando mais bancos de dados para demonstrar o dimensionamento linear.
- Depois de testar os limites de dimensionamento, nossos testes foram dinâmicos para os E96ds_v5 menos caros, mas quase tão capazes quanto para uma fase de teste do cliente usando uma verdadeira carga de trabalho de aplicativo da cadeia de suprimentos e dados do mundo real.
Desempenho de expansão SLOB2
Os gráficos a seguir capturam o perfil de desempenho de uma única E104ids_v5 VM do Azure executando um único banco de dados Oracle 19c em oito volumes do Azure NetApp Files com oito pontos de extremidade de armazenamento. Os volumes são distribuídos em três grupos de discos ASM: dados, log e arquivo morto. Cinco volumes foram alocados para o grupo de discos de dados, dois volumes para o grupo de discos de log e um volume para o grupo de discos de arquivos. Todos os resultados capturados ao longo deste artigo foram coletados usando regiões do Azure de produção e serviços ativos do Azure de produção.
Para implantar o Oracle em máquinas virtuais do Azure usando vários volumes do Azure NetApp Files em vários pontos de extremidade de armazenamento, use o grupo de volumes de aplicativos para o Oracle.
Arquitetura de host único
O diagrama a seguir ilustra a arquitetura na qual o teste foi concluído; observe que o banco de dados Oracle se espalhou por vários volumes e pontos de extremidade do Azure NetApp Files.

E/S de armazenamento de host único
O diagrama a seguir mostra uma carga de trabalho de 100% selecionada aleatoriamente com uma taxa de ocorrência de buffer de banco de dados de cerca de 8%. O SLOB2 foi capaz de conduzir aproximadamente 850.000 solicitações de E/S por segundo, mantendo uma latência sequencial de evento de leitura sequencial de arquivo de banco de dados de submilissegundo. Com um tamanho de bloco de banco de dados de 8K que equivale a aproximadamente 6.800 MiB/s de taxa de transferência de armazenamento.

Taxa de transferência de host único
O diagrama a seguir demonstra que, para cargas de trabalho sequenciais de E/S com uso intensivo de largura de banda, como verificações de tabela completas ou atividades do RMAN, o Azure NetApp Files pode fornecer os recursos completos de largura de banda da própria VM E104ids_v5.

Observação
Como a instância de computação está no máximo teórico de sua largura de banda, a adição de simultaneidade de aplicativo adicional resulta apenas no aumento da latência do lado do cliente. Isso resulta em cargas de trabalho SLOB2 que excedem o período de conclusão direcionado, portanto, a contagem de threads foi limitada a seis.
Desempenho de expansão SLOB2
Os gráficos a seguir capturam o perfil de desempenho de três VMs do Azure E104ids_v5 cada uma executando um único banco de dados Oracle 19c e cada uma com seu próprio conjunto de volumes do Azure NetApp Files e um layout de grupo de disco ASM idêntico, conforme descrito na seção Escalar desempenho. Os gráficos mostram que, com vários volumes/vários pontos de extremidade do Azure NetApp Files, o desempenho é facilmente dimensionado com consistência e previsibilidade.
Arquitetura multi-host
O diagrama a seguir ilustra a arquitetura na qual o teste foi concluído; observe os três bancos de dados Oracle espalhados por vários volumes e pontos de extremidade do Azure NetApp Files. Os pontos de extremidade podem ser dedicados a um único host, conforme mostrado com a VM Oracle 1 ou compartilhado entre hosts, conforme mostrado com o Oracle VM2 e a VM3 do Oracle.

E/S de armazenamento multi-host
O diagrama a seguir mostra uma carga de trabalho de 100% selecionada aleatoriamente com uma taxa de ocorrência de buffer de banco de dados de cerca de 8%. O SLOB2 conseguiu conduzir aproximadamente 850.000 solicitações de E/S por segundo em todos os três hosts individualmente. O SLOB2 conseguiu fazer isso durante a execução em paralelo a um total coletivo de cerca de 2.500.000 solicitações de E/S por segundo, com cada host ainda mantendo uma latência de evento de leitura sequencial de arquivo submilisegundos do banco de dados. Com um tamanho de bloco de banco de dados de 8K, isso equivale a aproximadamente 20.000 MiB/s entre os três hosts.

Taxa de transferência de multi-host
O diagrama a seguir demonstra que, para cargas de trabalho sequenciais, o Azure NetApp Files ainda pode fornecer os recursos de largura de banda completos da própria VM E104ids_v5, mesmo quando ela é dimensionada para fora. O SLOB2 foi capaz de conduzir e/S totalizando mais de 30.000 MiB/s entre os três hosts enquanto estava em execução em paralelo.

Desempenho no mundo real
Depois que os limites de dimensionamento foram testados com SLOB2, testes foram realizados com um pacote de aplicativos da cadeia de suprimentos de palavras reais em relação ao Oracle nos arquivos do Azure NetApp com excelentes resultados. Os dados a seguir do relatório AWR (Repositório de Carga de Trabalho Automática) da Oracle são um viés realçado sobre como um trabalho crítico específico foi executado.
Esse banco de dados tem uma E/S extra significativa acontecendo além da carga de trabalho do aplicativo devido ao flashback estar habilitado e ter um tamanho de bloco de banco de dados de 16k. Na seção de perfil de E/S do relatório AWR, é evidente que há uma taxa pesada de gravações em comparação com leituras.
| - | Leitura e gravação por segundo | Leitura por segundo | Gravação por segundo |
|---|---|---|---|
| Total (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Apesar do evento de espera de leitura sequencial do arquivo do banco de dados mostrar uma latência maior em 2,2 ms do que no teste SLOB2, esse cliente viu uma redução de quinze minutos no tempo de execução do trabalho proveniente de um banco de dados RAC no Exadata para um banco de dados de instância única no Azure.
Restrições de recursos do Azure
Todos os sistemas eventualmente atingem restrições de recursos, tradicionalmente conhecidas como pontos de obstrução. As cargas de trabalho de banco de dados, especialmente as altamente exigentes, como pacotes de aplicativos da cadeia de suprimentos, são entidades com uso intensivo de recursos. Encontrar essas restrições de recursos e trabalhar com elas é vital para qualquer implantação bem-sucedida. Esta seção ilustra várias restrições que você pode esperar encontrar em tal ambiente e como trabalhar com elas. Em cada subseção, espere aprender as práticas recomendadas e a lógica por trás delas.
Máquinas virtuais
Esta seção detalha os critérios a serem considerados na seleção VMs para melhor desempenho e a lógica por trás das seleções feitas para teste. O Azure NetApp Files é um serviço NAS (Armazenamento Anexado à Rede), portanto, o dimensionamento de largura de banda de rede apropriado é fundamental para o desempenho ideal.
Chipsets
O primeiro tópico de interesse é a seleção de chipset. Verifique se qualquer SKU de VM selecionada é criada em um único chipset por motivos de consistência. A variante Intel de E_v5 VMs é executada em uma configuração intel Xeon Platinum 8370C (Ice Lake) de terceira geração. Todas as VMs dessa família vêm equipadas com um único adaptador de rede de 100 Gbps. Por outro lado, a série E_v3, mencionada por exemplo, é criada em quatro chipsets separados, com várias larguras de banda de rede físicas. Os quatro chipsets usados na família E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) têm velocidades de processador diferentes, que afetam as características de desempenho do computador.
Leia a documentação da Computação do Azure prestando atenção nas opções de chipset. Consulte também práticas recomendadas de SKUs de VM do Azure para o Azure NetApp Files. Selecionar uma VM com um único chipset é preferível para obter a melhor consistência.
Largura de banda da rede disponível
É importante entender a diferença entre a largura de banda disponível da interface de rede da VM e a largura de banda limitada aplicada na mesma. Quando a documentação da Computação do Azure fala dos limites de largura de banda de rede, esses limites são aplicados somente na saída (gravação). O tráfego de entrada (leitura) não é medido e, como tal, é limitado apenas pela largura de banda física da própria NIC (placa de adaptador de rede). A largura de banda de rede da maioria das VMs supera o limite de saída aplicado no computador.
Como os volumes do Azure NetApp Files são anexados à rede, o limite de saída pode ser entendido como sendo aplicado em gravações especificamente, enquanto a entrada é definida como cargas de trabalho de leitura e leitura. Embora o limite de saída da maioria dos computadores seja maior que a largura de banda de rede da NIC, o mesmo não pode ser dito para o E104_v5 usado no teste deste artigo. O E104_v5 tem uma NIC de 100 Gbps com o limite de saída definido como 100 Gbps também. Em comparação, o E96_v5, com sua NIC de 100 Gbps tem um limite de saída de 35 Gbps com entrada irrestrita a 100 Gbps. À medida que as VMs diminuem de tamanho, os limites de saída diminuem, mas a entrada permanece irrestrita por limites logicamente impostos.
Os limites de saída são de toda a VM e são aplicados como tal em todas as cargas de trabalho baseadas em rede. Ao usar o Oracle Data Guard, todas as gravações são dobradas para logs de arquivo morto e devem ser fatoradas para considerações de limite de saída. Isso também vale para o log de arquivos com vários destinos e RMAN, se usado. Ao selecionar VMs, familiarize-se com ferramentas de linha de comando como ethtool, que expõem a configuração da NIC, pois o Azure não documenta configurações de interface de rede.
Simultaneidade de rede
As VMs do Azure e volumes do Azure NetApp Files vêm equipados com quantidades específicas de largura de banda. Conforme mostrado anteriormente, desde que uma VM tenha espaço suficiente para a reserva dinâmica da CPU, uma carga de trabalho pode, em teoria, consumir a largura de banda disponibilizada a ela, que está dentro dos limites do cartão de rede e ou do limite de saída aplicado. Na prática, no entanto, a quantidade de produtividade alcançável é baseada na simultaneidade da carga de trabalho na rede, que é o número de fluxos de rede e pontos de extremidade de rede.
Leia a seção do documento de largura de banda de rede da VM limites de fluxo de rede para maior compreensão. Resumo: quanto mais a rede flui conectando o cliente ao armazenamento, mais avançado será o desempenho potencial.
O Oracle dá suporte a dois clientes NFS separados, Kernel NFS e dNFS (Direct NFS). O Kernel NFS, até recentemente, suportava um único fluxo de rede entre dois pontos de extremidade (armazenamento de computação – ). O NFS direto, o maior desempenho dos dois, dá suporte a um número variável de testes de fluxos – de rede que mostraram centenas de conexões exclusivas por ponto de extremidade – aumentando ou diminuindo à medida que as demandas de carga. Devido ao dimensionamento de fluxos de rede entre dois pontos de extremidade, o Direct NFS é muito preferencial em relação ao Kernel NFS e, como tal, a configuração recomendada. O grupo de produtos do Azure NetApp Files não recomenda o uso do Kernel NFS com cargas de trabalho Oracle. Para obter mais informações, consulte os benefícios de usar o Azure NetApp Files com o Oracle Database.
Simultaneidade de execução
Usar o Direct NFS, um único chipset para consistência e entender as restrições de largura de banda de rede só leva você até um certo ponto. No final, o aplicativo impulsiona o desempenho. As provas de conceito usando o SLOB2 e as provas de conceito usando um pacote de aplicativos da cadeia de suprimentos do mundo real em relação aos dados reais do cliente foram capazes de gerar quantidades significativas de taxa de transferência apenas porque os aplicativos eram executados em alto grau de simultaneidade; o primeiro usando um número significativo de threads por esquema, este último usando várias conexões de vários servidores de aplicativos. Resumindo, a simultaneidade impulsiona a carga de trabalho, baixa simultaneidade – baixa taxa de transferência, alta simultaneidade – alta taxa de transferência, desde que a infraestrutura esteja em vigor para dar suporte ao mesmo.
Redes aceleradas
Rede acelerada permite SR-IOV (virtualização de E/S de raiz única) para uma VM, melhorando muito seu desempenho de rede. Esse caminho de alto desempenho ignora o host do caminho de dados, o que reduz a latência, a tremulação e a utilização da CPU para as cargas de trabalho de rede mais exigentes nos tipos de VM compatíveis. Ao implantar VMs por meio de utilitários de gerenciamento de configuração, como terraform ou linha de comando, lembre-se de que a rede acelerada não está habilitada por padrão. Para obter um desempenho ideal, habilite a rede acelerada. Observe que a rede acelerada está habilitada ou desabilitada em um adaptador de rede por meio da interface de rede. O recurso de rede acelerada é aquele que pode ser habilitado ou desabilitado dinamicamente.
Observação
Este artigo contém referências ao termo SLAVE, um termo que a Microsoft não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
Uma abordagem autoritativa para a rede acelerada subsequente está habilitada para uma NIC é por meio do terminal do Linux. Se a rede acelerada estiver habilitada para uma NIC, uma segunda NIC virtual estará presente associada à primeira NIC. Esta segunda NIC é configurada pelo sistema com o sinalizador de SLAVE habilitado. Se nenhuma NIC estiver presente com o sinalizador SLAVE, a rede acelerada não estará habilitada para essa interface.
No cenário em que várias NICs estão configuradas, você precisa determinar qual interface de SLAVE está associada à NIC usada para montar o volume NFS. A adição de cartões de interface de rede à VM não tem efeito sobre o desempenho.
Use o processo a seguir para identificar o mapeamento entre a interface de rede configurada e sua interface virtual associada. Esse processo valida que a rede acelerada está habilitada para uma NIC específica em seu computador Linux e exibe a velocidade de entrada física que a NIC pode potencialmente alcançar.
- Execute o comando
ip a: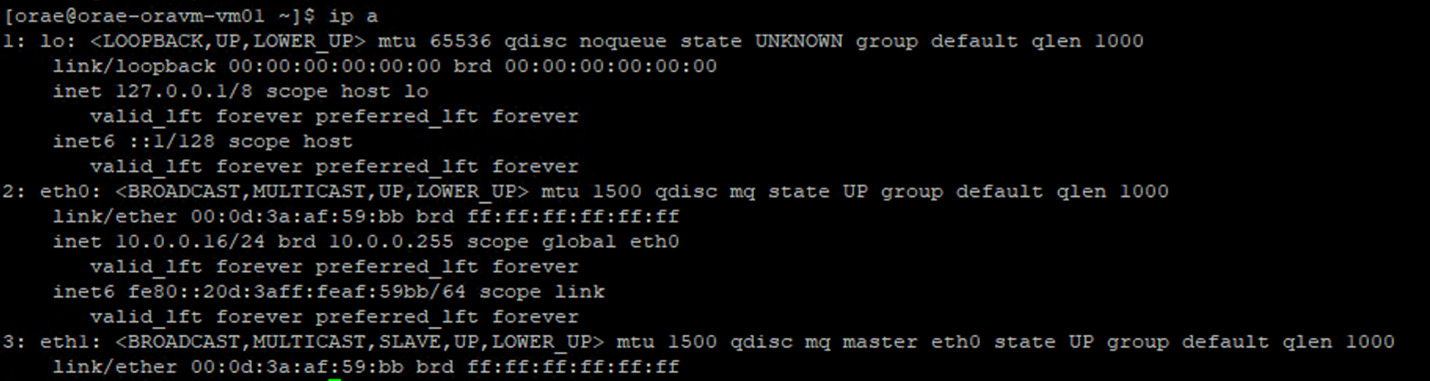
- Liste o diretório
/sys/class/net/da ID NIC que você está verificando (eth0no exemplo) egreppara a palavra inferior:ls /sys/class/net/eth0 | grep lower lower_eth1 - Execute o comando
ethtoolno dispositivo ethernet identificado como o dispositivo inferior na etapa anterior.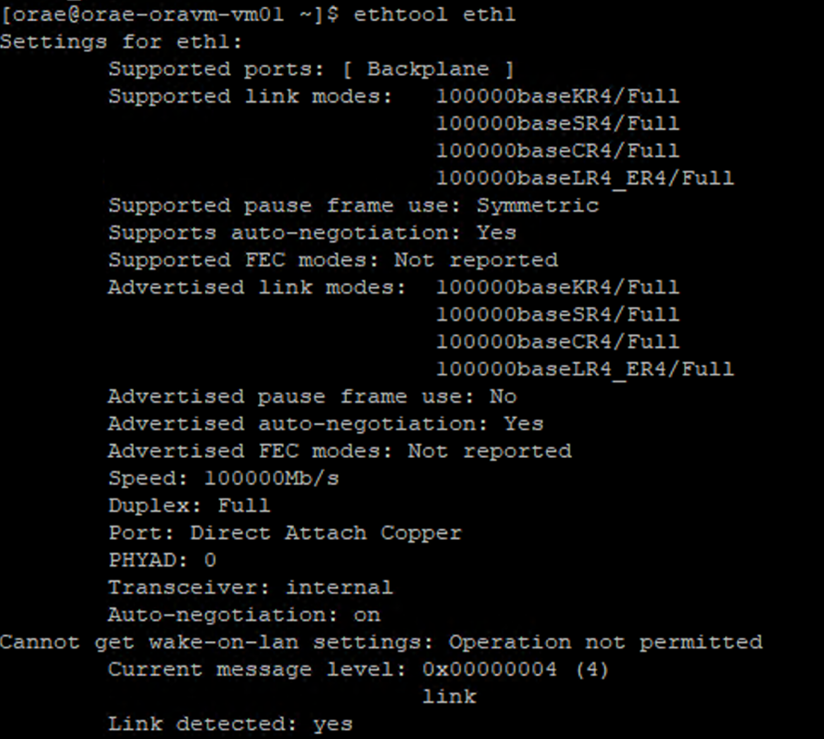
VM do Azure: limites de largura de banda de rede versus disco
Um nível de experiência é necessário ao ler a documentação de limites de desempenho da VM do Azure. Lembre-se:
- A taxa de transferência de armazenamento temporário e os números de IOPS referem-se aos recursos de desempenho do armazenamento efêmero na caixa diretamente anexado à VM.
- A taxa de transferência de disco não armazenado e os números de E/S referem-se especificamente ao Azure Disk (Premium, Premium v2 e Ultra) e não têm qualquer influência no armazenamento anexado à rede, como o Azure NetApp Files.
- Anexar NICs adicionais à VM não afeta os limites de desempenho ou os recursos de desempenho da VM (documentados e testados como verdadeiros).
- A largura de banda de rede máxima refere-se aos limites de saída (ou seja, gravações quando o Azure NetApp Files está envolvido) aplicados à largura de banda de rede da VM. Nenhum limite de entrada (ou seja, leituras quando o Azure NetApp Files está envolvido) é aplicado. Considerando CPU suficiente, simultaneidade de rede suficiente e pontos de extremidade avançados o suficiente, uma VM poderia teoricamente levar o tráfego de entrada aos limites da NIC. Conforme mencionado na seção de largura de banda de rede disponível do , use ferramentas como
ethtoolpara ver a largura de banda da NIC.
Um gráfico de exemplo é mostrado para referência:
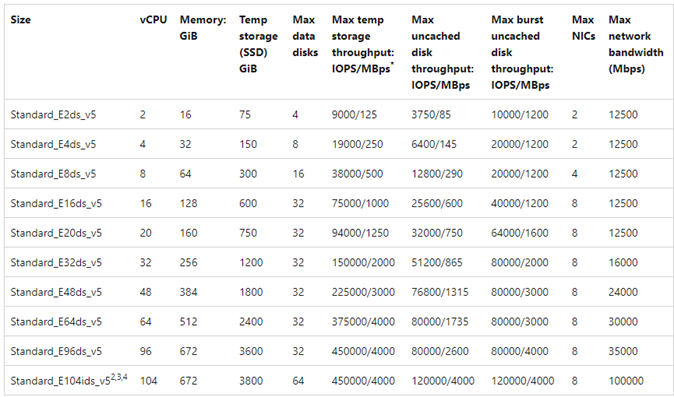
Azure NetApp Files
O serviço de armazenamento de primeira parte do Azure, o Azure NetApp Files, fornece uma solução de armazenamento totalmente gerenciada altamente disponível capaz de dar suporte às cargas de trabalho Oracle exigentes introduzidas anteriormente.
Como os limites de desempenho de armazenamento vertical em um banco de dados Oracle são bem entendidos, este artigo se concentra intencionalmente no desempenho de armazenamento de expansão. O dimensionamento do desempenho de armazenamento implica em dar a uma única instância Oracle acesso a muitos volumes do Azure NetApp Files em que esses volumes são distribuídos em vários pontos de extremidade de armazenamento.
Ao dimensionar uma carga de trabalho de banco de dados em vários volumes de tal forma, o desempenho do banco de dados é desvinculado dos limites superiores de volume e ponto de extremidade. Com o armazenamento não impondo mais limitações de desempenho, a arquitetura da VM (limites de saída de CPU, NIC e VM) torna-se o ponto de obstrução a ser enfrentado. Conforme observado na seção da VM, a seleção das instâncias E104ids_v5 e E96ds_v5 foi feita tendo isso em mente.
Se um banco de dados é colocado em um único volume de capacidade grande ou distribuído em vários volumes menores, o custo financeiro total é o mesmo. A vantagem de distribuir E/S em vários volumes e ponto de extremidade em contraste com um único volume e ponto de extremidade é evitar limites de largura de banda– você pode usar inteiramente o que paga.
Importante
Para implantar usando o Azure NetApp Files em uma configuraçãomultiple volume:multiple endpoint, entre em contato com o especialista do Azure NetApp Files ou o Arquiteto de Soluções de Nuvem para obter assistência.
Backup de banco de dados
O banco de dados do Oracle versão 19c é a versão atual de longo prazo da Oracle versão e a usada para produzir todos os resultados de teste discutidos neste artigo.
Para obter o melhor desempenho, todos os volumes de banco de dados foram montados usando o Direct NFS, o Kernel NFS é recomendado devido a restrições de desempenho. Para obter uma comparação de desempenho entre os dois clientes, consulte desempenho do banco de dados Oracle em volumes únicos do Azure NetApp Files. Observe que todos os patches dNFS relevantes (1495104 de ID de Suporte do Oracle) foram aplicados, assim como as práticas recomendadas descritas no relatório Bancos de Dados Oracle no Microsoft Azure usando o relatório do Azure NetApp Files.
Embora o Oracle e o Azure NetApp Files ofereçam suporte ao NFSv3 e ao NFSv4.1, como o NFSv3 é o protocolo mais maduro, ele geralmente é visto como tendo mais estabilidade e é a opção mais confiável para ambientes altamente sensíveis à interrupção. O teste descrito neste artigo foi concluído por meio do NFSv3.
Importante
Alguns dos patches recomendados que a Oracle documenta na ID de Suporte 1495104 são essenciais para manter a integridade dos dados ao usar dNFS. A aplicação desses patches é altamente recomendável para ambientes de produção.
O ASM (Gerenciamento Automático de Armazenamento) tem suporte para volumes NFS. Embora normalmente esteja associado ao armazenamento baseado em bloco em que o ASM substitui o LVM (gerenciamento de volume lógico) e o sistema de arquivos, o ASM desempenha um papel valioso em cenários NFS de vários volumes e é digno de forte consideração. Uma dessas vantagens do ASM, a adição dinâmica online e o reequilíbrio em volumes e pontos de extremidade NFS recém-adicionados, simplifica o gerenciamento, permitindo a expansão do desempenho e da capacidade à vontade. Embora o ASM não aumente por si só o desempenho de um banco de dados, seu uso evita arquivos frequentes e a necessidade de manter manualmente a distribuição de arquivos, um benefício fácil de ver.
Uma configuração ASM sobre dNFS foi usada para produzir todos os resultados de teste discutidos neste artigo. O diagrama a seguir ilustra o layout do arquivo ASM nos volumes do Azure NetApp Files e a alocação de arquivo para os grupos de disco ASM.

Há algumas limitações com o uso do ASM em volumes montados do NFS do Azure NetApp Files quando se trata de instantâneos de armazenamento que podem ser superados com determinadas considerações arquitetônicas. Entre em contato com seu especialista do Azure NetApp Files ou arquiteto de soluções de nuvem para uma análise detalhada dessas considerações.
Ferramentas de teste sintéticas e ajustáveis
Esta seção descreve a arquitetura de teste, as tabelas de ajuste e os detalhes de configuração em específicos. Embora a seção anterior esteja focada nos motivos pelos quais as decisões de configuração são tomadas, esta seção se concentra especificamente no "o quê" das decisões de configuração.
Implantação automatizada
- As VMs de banco de dados são implantadas usando scripts bash disponíveis no GitHub.
- O layout e a alocação de vários volumes e pontos de extremidade do Azure NetApp Files são concluídos manualmente. Você precisa trabalhar com o especialista do Azure NetApp Files ou o Arquiteto de Soluções na Nuvem para obter assistência.
- A instalação da grade, a configuração do ASM, a criação e a configuração do banco de dados e o ambiente SLOB2 em cada computador são configurados usando o Ansible para consistência.
- Execuções de teste paralelas do SLOB2 em vários hosts também são concluídas usando o Ansible para consistência e execução simultânea.
Configuração da VM
| Configuração | Valor |
|---|---|
| região do Azure | Oeste da Europa |
| SKU da VM | E104ids_v5 |
| Contagem de NIC | OBSERVAÇÃO 1: a adição de vNICs não tem efeito na contagem do sistema |
| Largura de banda máxima de rede de saída (Mbps) | 100.000 |
| Armazenamento temporário (SSD) GiB | 3.800 |
Configuração do sistema
Todas as configurações de sistema necessárias do Oracle para a versão 19c foram implementadas de acordo com a documentação da Oracle.
Os seguintes parâmetros foram adicionados ao arquivo do sistema Linux /etc/sysctl.conf :
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Todos os volumes do Azure NetApp Files foram montados com as seguintes opções de montagem do NFS.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parâmetros de banco de dados
| Parâmetros | Valor |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Configuração do SLOB2
Toda a geração de carga de trabalho para teste foi concluída usando a ferramenta SLOB2 versão 2.5.4.
Quatorze esquemas SLOB2 foram carregados em um espaço de tabela padrão do Oracle e executados, que, em combinação com as configurações de arquivo de configuração SLOB listadas, colocaram o conjunto de dados SLOB2 em 7 TiB. As configurações a seguir refletem uma execução de leitura aleatória para SLOB2. O parâmetro de configuração SCAN_PCT=0 foi alterado para SCAN_PCT=100 durante o teste sequencial.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
Para testes de leitura aleatórios, nove execuções SLOB2 foram executadas. A contagem de threads foi aumentada em seis com cada iteração de teste começando de uma.
Para testes sequenciais, sete execuções SLOB2 foram executadas. A contagem de threads foi aumentada em seis com cada iteração de teste começando de uma. A contagem de threads foi limitada a seis devido ao alcance dos limites máximos de largura de banda da rede.
Métricas de AWR
Todas as métricas de desempenho foram relatadas por meio do AWR (Repositório de Carga de Trabalho Automática) do Oracle. Veja a seguir as métricas apresentadas nos resultados:
- Taxa de transferência: a soma da taxa de transferência de leitura média e da taxa de transferência de gravação da seção AWR Load Profile
- Média de solicitações de E/S de leitura da seção Perfil de Carga AWR
- Tempo médio de espera de evento de espera de leitura sequencial do arquivo de banco de dados da seção Eventos de Espera de Primeiro Plano do AWR
Migrando de sistemas projetados e criados com finalidade para a nuvem
O Oracle Exadata é um sistema projetado, uma combinação de hardware e software que é considerada a solução mais otimizada para executar cargas de trabalho do Oracle. Embora a nuvem tenha vantagens significativas no esquema geral do mundo técnico, esses sistemas especializados podem parecer incrivelmente atraentes para aqueles que leram e visualizaram as otimizações que o Oracle criou em torno de suas cargas de trabalho específicas.
Quando se trata de executar o Oracle no Exadata, há alguns motivos comuns pelos quais o Exadata é escolhido:
- 1 a 2 cargas de trabalho de E/S altas que são adequadas para os recursos do Exadata e, como essas cargas de trabalho exigem recursos significativos projetados do Exadata, o restante dos bancos de dados em execução junto com eles foi consolidado para o Exadata.
- Cargas de trabalho OLTP complicadas ou difíceis que exigem RAC para dimensionar e são difíceis de arquitetar com hardware proprietário sem conhecimento profundo da otimização do Oracle ou podem ser dívidas técnicas que não podem ser otimizadas.
- Exadata existente subutilizado com várias cargas de trabalho: isso existe devido a migrações anteriores, fim da vida útil em um Exadata anterior ou devido ao desejo de trabalhar/testar um Exadata internamente.
É essencial que qualquer migração de um sistema Exadata seja compreendida da perspectiva das cargas de trabalho e quão simples ou complexa a migração pode ser. Uma necessidade secundária é entender o motivo da compra do Exadata de uma perspectiva de status. As habilidades de Exadata e RAC estão em maior demanda e podem ter impulsionado a recomendação de compra por parte dos stakeholders técnicos.
Importante
Não importa o cenário, a retirada geral deve ser, para qualquer carga de trabalho de banco de dados proveniente de um Exadata, quanto mais recursos proprietários do Exadata forem usados, mais complexo será a migração e o planejamento. Ambientes que não utilizam fortemente recursos proprietários do Exadata têm oportunidades para um processo de migração e planejamento mais simples.
Há várias ferramentas que podem ser usadas para avaliar essas oportunidades de carga de trabalho:
- O Repositório automático de carga de trabalho (AWR):
- Todos os bancos de dados Exadata são licenciados para usar relatórios AWR e recursos de desempenho e diagnóstico conectados.
- Está sempre ativado e coleta dados que podem ser usados para exibir informações históricas da carga de trabalho e avaliar o uso. Os valores de pico podem avaliar o alto uso no sistema,
- Relatórios AWR de janela maior podem avaliar a carga de trabalho geral, fornecendo informações valiosas sobre o uso de recursos e como migrar a carga de trabalho para não Exadata efetivamente. Os relatórios AWR de pico, em contraste, são melhores para otimização de desempenho e solução de problemas.
- O relatório AWR global (RAC-Aware) para Exadata também inclui uma seção específica do Exadata, que detalha o uso de recursos específicos do Exadata e fornece informações valiosas de cache flash, registro em log flash, E/S e outros recursos de uso por banco de dados e nó de célula.
Desacoplamento do Exadata
Ao identificar cargas de trabalho do Oracle Exadata para migrar para a nuvem, considere as seguintes perguntas e pontos de dados:
- A carga de trabalho está consumindo vários recursos do Exadata, fora dos benefícios de hardware?
- Verificações inteligentes
- Índices de armazenamento
- Cache flash
- Registro em log flash
- Compactação da coluna híbrida
- A carga de trabalho está usando o descarregamento do Exadata com eficiência? Nos principais eventos de primeiro plano de tempo, qual é a taxa (mais de 10% do tempo de BD) da carga de trabalho usando:
- Verificação de tabela inteligente de célula (ideal)
- Leitura física de multibloco de célula (menos ideal)
- Leitura física de bloco único da célula (menos ideal)
- Compactação da coluna híbrida (HCC/EHCC): quais são as taxas compactadas versus não compactadas:
- O banco de dados está gastando mais de 10% do tempo do banco de dados para compactar e descompactar dados?
- Inspecione os ganhos de desempenho para predicados usando a compactação em consultas: o valor ganho vale a pena em comparação com a quantidade salva com compactação?
- E/S física da célula: inspecione as economias fornecidas de:
- o valor direcionado para o nó do banco de dados para equilibrar a CPU.
- identificando o número de bytes retornados pela verificação inteligente. Esses valores podem ser subtraídos em E/S para o percentual de leituras físicas de bloco único de célula depois que ele migrar do Exadata.
- Observe o número de leituras lógicas do cache. Determine se o cache flash será necessário em uma solução IaaS de nuvem para a carga de trabalho.
- Compare o total de bytes de leitura e gravação física com o total executado no cache. A memória pode ser gerada para eliminar os requisitos de leitura física (é comum que alguns reduzam a SGA para forçar o descarregamento para Exadata)?
- Em Estatísticas do sistema, identifique quais objetos são afetados por qual estatística. Se estiver ajustando o SQL, a indexação adicional, o particionamento ou outro ajuste físico poderão otimizar drasticamente a carga de trabalho.
- Inspecione os parâmetros de inicialização para parâmetros sublinhados (_) ou preteridos, que devem ser justificados devido ao impacto no nível do banco de dados que podem estar causando no desempenho.
Configuração do servidor do Exadata
No Oracle versão 12.2 e superior, uma adição específica do Exadata será incluída no relatório global do AWR. Este relatório tem seções que fornecem um valor excepcional para uma migração do Exadata.
Detalhes da versão e do sistema do Exadata
Detalhes dos alertas de nó de célula
Discos não online do Exadata
Dados de exceção para estatísticas do sistema operacional do Exadata
Amarelo/Rosa: preocupante. O Exadata não está sendo executado de forma ideal.
Vermelho: o desempenho do Exadata é afetado significativamente.
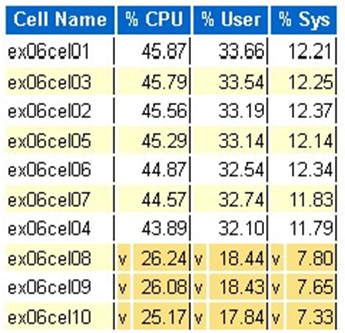
Estatística da CPU do Exadata: células superiores
- Essas estatísticas são coletadas pelo sistema operacional nas células e não são restritas a esse banco de dados ou instâncias
- Um
ve um plano de fundo amarelo escuro indicam um valor de exceção abaixo do intervalo baixo - Um
^e um plano de fundo amarelo claro indicam um valor de exceção acima do intervalo alto - As células superiores por porcentagem da CPU são exibidas e estão em ordem decrescente da CPU percentual
- Média: 39,34% de CPU, 28,57% de usuário, 10,77% do sistema
Leituras de bloco físico de célula única
Uso de cache flash
E/S temporária
Eficiência do cache de coluna
Principal banco de dados por taxa de transferência de E/S
Embora as avaliações de dimensionamento possam ser executadas, há algumas perguntas sobre as médias e os picos simulados que são incorporados a esses valores para cargas de trabalho grandes. Esta seção, encontrada no final de um relatório AWR, é excepcionalmente valiosa, pois mostra o uso médio de flash e disco dos 10 principais bancos de dados no Exadata. Embora muitos possam supor que desejam dimensionar bancos de dados para o desempenho de pico na nuvem, isso não faz sentido para a maioria das implantações (mais de 95% está no intervalo médio; com um pico simulado calculado, o intervalo médio é maior que 98%). É importante pagar pelo que é necessário, mesmo para a mais alta das cargas de trabalho de demanda do Oracle e inspecionar os bancos de dados principais por taxa de transferência de E/S pode ser esclarecedor para entender as necessidades de recursos para o banco de dados.
Oracle de tamanho certo usando o AWR no Exadata
Ao executar o planejamento de capacidade para sistemas locais, é natural ter uma sobrecarga significativa interna no hardware. O hardware superprovisionado precisa atender à carga de trabalho do Oracle por vários anos, independentemente das adições de carga de trabalho devido ao crescimento de dados, alterações de código ou atualizações.
Um dos benefícios da nuvem é o dimensionamento de recursos em um host de VM e o armazenamento pode ser executado à medida que as demandas aumentam. Isso ajuda a conservar custos de nuvem e custos de licenciamento anexados ao uso do processador (pertinente com o Oracle).
O dimensionamento correto envolve a remoção do hardware da migração tradicional de lift and shift e o uso das informações de carga de trabalho fornecidas pelo AWR (Repositório de Carga de Trabalho Automática) do Oracle para levantar e deslocar a carga de trabalho para computação e armazenamento especialmente projetado para dar suporte a ele na nuvem de escolha do cliente. O processo de dimensionamento correto garante que a arquitetura daqui para frente remova a dívida técnica de infraestrutura, a redundância de arquitetura que ocorreria se a duplicação do sistema local fosse replicada para a nuvem e implementasse os serviços de nuvem sempre que possível.
Especialistas em assuntos da Microsoft Oracle estimaram que mais de 80% dos bancos de dados Oracle estão superprovisionados e experimentam o mesmo custo ou economia indo para a nuvem se eles tiverem tempo para dimensionar corretamente a carga de trabalho do banco de dados Oracle antes de migrar para a nuvem. Essa avaliação exige que os especialistas de banco de dados da equipe mudem sua mentalidade sobre como eles podem ter executado o planejamento de capacidade no passado, mas vale a pena o investimento do stakeholder na nuvem e na estratégia de nuvem da empresa.
Próximas etapas
- Execute suas cargas de trabalho do Oracle mais exigentes no Azure sem sacrificar desempenho ou escalabilidade
- Arquiteturas de solução usando o Azure NetApp Files - Oracle
- Projete e implemente um banco de dados Oracle no Azure
- Ferramenta de estimativa do dimensionamento de cargas de trabalho do Oracle para VMs da IaaS do Azure
- Arquiteturas de referência para o Oracle Database Enterprise Edition no Azure
- Entenda os grupos de volumes de aplicativos do Azure NetApp Files para o SAP HANA