Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Machine Learning é uma plataforma integrada para gerenciar o ciclo de vida do machine learning do início ao fim, incluindo ajuda com a criação, operação e consumo de modelos e fluxos de trabalho de machine learning. Alguns benefícios do serviço incluem:
Os recursos dão suporte aos criadores para aumentar sua produtividade, ajudando-os a gerenciar experimentos, acessar dados, acompanhar trabalhos, ajustar hiperparâmetros e automatizar fluxos de trabalho.
A capacidade do modelo a ser explicada, reproduzida, auditada e integrada ao DevOps, além de um modelo de controle de segurança avançado, pode dar suporte aos operadores para atender aos requisitos de governança e conformidade.
Os recursos de inferência gerenciada e a integração robusta com os serviços de computação e dados do Azure podem ajudar a simplificar a maneira como o serviço é consumido.
O Azure Machine Learning aborda todos os aspectos do ciclo de vida da ciência de dados. Ele abrange o armazenamento de dados e o registro do conjunto de dados para a implantação do modelo. Ele pode ser usado para qualquer tipo de aprendizado de máquina, desde o aprendizado de máquina clássico até o aprendizado profundo. Ele inclui aprendizado supervisionado e não supervisionado. Se você preferir escrever código Python, R ou usar opções de código zero ou de baixo código, como o designer, você pode criar, treinar e acompanhar modelos precisos de aprendizado de máquina e aprendizado profundo em um workspace do Azure Machine Learning.
O Azure Machine Learning, a plataforma do Azure e os serviços de IA do Azure podem trabalhar juntos para gerenciar o ciclo de vida do machine learning. Um profissional de machine learning pode usar o Azure Synapse Analytics, o Banco de Dados SQL do Azure ou o Microsoft Power BI para começar a analisar dados e fazer a transição para o Azure Machine Learning para protótipos, gerenciamento de experimentação e operacionalização. Nas zonas de destino do Azure, o Azure Machine Learning pode ser considerado um produto de dados.
Azure Machine Learning na análise em escala de nuvem
Uma fundação de zona de destino do Framework de Adoção da Nuvem (CAF), zonas de destino de dados analíticos em escala de nuvem e a configuração do Azure Machine Learning estabelecem para os profissionais de machine learning um ambiente pré-configurado, no qual eles podem implantar repetidamente novas cargas de trabalho de machine learning ou migrar cargas existentes. Esses recursos podem ajudar os profissionais de machine learning a obter mais agilidade e valor para seu tempo.
Os seguintes princípios de design podem orientar a implementação das landing zones do Azure Machine Learning:
Acesso acelerado a dados: Pré-configure componentes de armazenamento da zona de destino como armazenamentos de dados no espaço de trabalho do Azure Machine Learning.
Colaboração habilitada: Organize os espaços de trabalho por projeto e centralize o gerenciamento de acesso aos recursos da zona de aterrissagem para apoiar profissionais de engenharia de dados, ciência de dados e aprendizado de máquina a trabalharem juntos.
Implementação segura: Como padrão para cada implantação, siga as práticas recomendadas e use o isolamento de rede, a identidade e o gerenciamento de acesso para proteger ativos de dados.
Auto-serviço: Os profissionais de machine learning podem obter mais agilidade e organização explorando opções para implantar novos recursos de projeto.
Separação de preocupações entre o gerenciamento de dados e o consumo de dados: A passagem de identidade é o tipo de autenticação padrão para o Azure Machine Learning e o armazenamento.
Aplicativo de dados mais rápido (alinhado à origem): As zonas de destino do Azure Data Factory, do Azure Synapse Analytics e do Databricks podem ser pré-configuradas para vincular ao Azure Machine Learning.
Observabilidade: Configurações centrais de registro centralizado e referência podem ajudar a monitorar o ambiente.
Visão geral da implementação
Observação
Esta seção recomenda configurações específicas para análise em escala de nuvem. Ele complementa a documentação do Azure Machine Learning e as práticas recomendadas do Cloud Adoption Framework.
Organização e configuração do workspace
Você pode implementar a quantidade de workspaces de machine learning que suas cargas de trabalho exigem e para cada zona de destino ou "landing zone" que você implementar. As seguintes recomendações podem ajudar na configuração:
Implante pelo menos um workspace de machine learning por projeto.
Dependendo do ciclo de vida do seu projeto de machine learning, implante um ambiente de trabalho de desenvolvimento para prototipar casos de uso e explorar dados no início. Para um trabalho que requer experimentação contínua, teste e implantação, implante um ambiente de homologação e produção.
Quando vários ambientes são necessários para workspaces de desenvolvimento, teste e produção em uma zona de destino de dados, recomendamos evitar a duplicação de dados, fazendo com que cada ambiente aterrisse na mesma zona de destino de dados de produção.
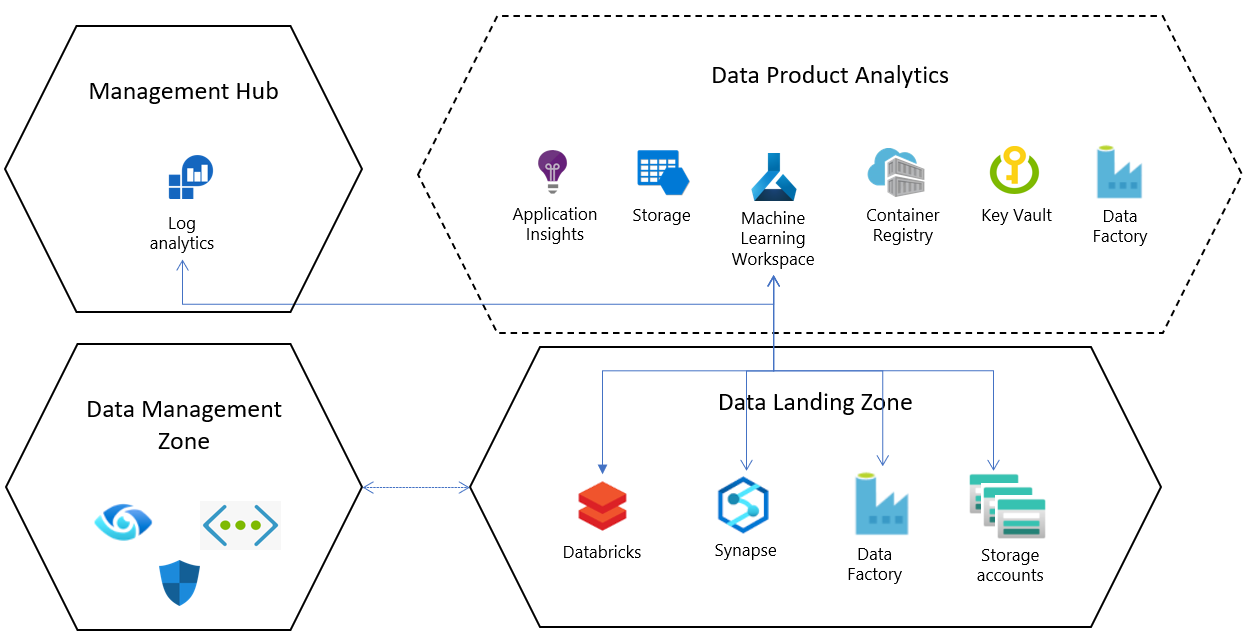
Para cada configuração de recurso padrão em uma zona de destino de dados, um serviço do Azure Machine Learning é implantado em um grupo de recursos dedicado com as seguintes configurações e recursos dependentes:
- Azure Key Vault
- Insights de aplicativos
- Registro de Contêiner do Azure
- Use o Azure Machine Learning para se conectar a uma conta de Armazenamento do Azure e à autenticação baseada em identidade do Microsoft Entra para ajudar os usuários a se conectarem à conta.
- O log de diagnóstico é configurado para cada workspace e direcionado a um recurso central do Log Analytics em escala empresarial; isso pode ajudar a integridade dos trabalhos e os status de recursos do Azure Machine Learning a serem analisados centralmente, dentro e entre as landing zones.
- Veja o que é um workspace do Azure Machine Learning? Para saber mais sobre os recursos e dependências do Azure Machine Learning.
Integração com os serviços principais da zona de destino de dados
A zona de destino de dados vem com um conjunto padrão de serviços que são implantados na camada de serviços de plataforma. Esses serviços principais podem ser configurados quando o Azure Machine Learning é implantado na zona de destino de dados.
Conecte os workspaces do Azure Synapse Analytics ou do Databricks como serviços vinculados para integrar dados e processar Big Data.
Por padrão, os serviços data lake são provisionados na zona de destino de dados e as implantações de produtos do Azure Machine Learning vêm com conexões (armazenamentos de dados) pré-configuradas para essas contas de armazenamento.
Conectividade de rede
A rede para implementar o Azure Machine Learning nas zonas de aterrissagem do Azure é configurada com as práticas recomendadas de segurança para o Azure Machine Learning e com as práticas recomendadas de rede do CAF. Essas práticas recomendadas incluem as seguintes configurações:
- O Azure Machine Learning e os recursos dependentes estão configurados para usar endpoints de Link Privado.
- Os recursos de computação gerenciada são implantados apenas com endereços IP privados.
- A conectividade de rede com o repositório de imagem base pública do Azure Machine Learning e os serviços de parceiro, como o Azure Artifacts, pode ser configurada em um nível de rede.
Gerenciamento de identidade e acesso
Considere as seguintes recomendações para gerenciar identidades de usuário e acesso com o Azure Azure Machine Learning:
Os armazenamentos de dados no Azure Machine Learning podem ser configurados para usar a autenticação baseada em credenciais ou identidades. Ao usar o controle de acesso e as configurações do data lake no Azure Data Lake Storage Gen2, configure armazenamentos de dados para usar a autenticação baseada em identidade; isso permite que o Azure Machine Learning otimize as permissões de acesso do usuário para armazenamento.
Use grupos do Microsoft Entra para gerenciar permissões de usuário para recursos de armazenamento e machine learning.
O Azure Machine Learning pode usar identidades gerenciadas atribuídas pelo usuário para controle de acesso e limitar o intervalo de acesso ao Registro de Contêiner do Azure, ao Key Vault, ao Armazenamento do Azure e ao Application Insights.
Crie identidades gerenciadas atribuídas pelo usuário para clusters de computação gerenciados criados no Azure Machine Learning.
Provisionar a infraestrutura por meio do autoatendimento
O autoatendimento pode ser habilitado e regido com políticas para o Azure Machine Learning. A tabela a seguir lista um conjunto de políticas padrão ao implantar o Azure Machine Learning. Para obter mais informações, consulte as definições de política internas do Azure Policy para o Azure Machine Learning.
| Política | Tipo | Referência |
|---|---|---|
| Os workspaces do Azure Machine Learning devem usar o Link Privado do Azure. | Interno | Exibir no portal do Azure |
| Os workspaces do Azure Machine Learning devem usar identidades gerenciadas atribuídas pelo usuário. | Interno | Exibir no portal do Azure |
| [Versão prévia]: configurar registros permitidos para cálculos especificados do Azure Machine Learning. | Interno | Exibir no portal do Azure |
| Configurar workspaces de Azure Machine Learning com pontos de extremidade privados. | Interno | Exibir no portal do Azure |
| Configure cálculos de machine learning para desabilitar métodos de autenticação local. | Interno | Exibir no portal do Azure |
| Anexar-scripts de configuração de preparo de machine learning | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Deny-machinelearning-hbiworkspace | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Negar acesso público ao aprendizado de máquina quando atrás da vnet | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Deny-machinelearning-AKS | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Deny-computaçãoaprendizagemmáquina-subnetid | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Deny-machinelearningcompute-vmsize | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Negar-acesso-público-à-porta-de-login-remoto-do-cluster-de-computação-do-aprendizado-de-máquina | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
| Impedir escala de cluster computacional de aprendizado de máquina (Deny-machinelearningcomputecluster-scale) | Personalizado (zonas de destino do CAF) | Exibir no GitHub |
Recomendações para gerenciar seu ambiente
As zonas de destino de dados de análise em escala de nuvem descrevem a implementação de referência para implantações repetíveis, o que pode ajudá-lo a configurar ambientes gerenciáveis e governáveis. Considere as seguintes recomendações para usar o Azure Machine Learning para gerenciar seu ambiente:
Use grupos do Microsoft Entra para gerenciar o acesso aos recursos de machine learning.
Publique um painel de monitoramento central para monitorar a integridade do pipeline, a utilização de computação e o gerenciamento de cotas para aprendizado de máquina.
Se você tradicionalmente usa políticas internas do Azure e precisa atender a requisitos de conformidade adicionais, crie políticas personalizadas do Azure para aprimorar a governança e o autoatendimento.
Para acompanhar os custos de pesquisa e desenvolvimento, implante um workspace de machine learning na zona de destino como um recurso compartilhado durante os estágios iniciais da exploração do caso de uso.
Importante
Use os clusters do Azure Machine Learning para treinamento de modelos em ambiente de produção e o AKS (Serviço de Kubernetes do Azure) para implantações em ambiente de produção.
Dica
Use o Azure Machine Learning para projetos de ciência de dados. Ele abrange o fluxo de trabalho de ponta a ponta com subsserviços e recursos e permite que o processo seja totalmente automatizado.
Próximas etapas
Use o modelo de Análise de Produtos de Dados e as diretrizes para implantar o Azure Machine Learning e referencie a documentação e os tutoriais do Azure Machine Learning para começar a criar suas soluções.