Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Recomendamos essas práticas recomendadas para usar a análise em escala de nuvem no Microsoft Azure para operacionalizar projetos de ciência de dados.
Desenvolver um modelo
Desenvolva um modelo que agrupa um conjunto de serviços para seus projetos de ciência de dados. Use um modelo que agrupa um conjunto de serviços para ajudar a fornecer consistência nos casos de uso de várias equipes de ciência de dados. Recomendamos que você desenvolva um blueprint consistente na forma de um repositório de modelos. Você pode usar esse repositório para vários projetos de ciência de dados em sua empresa para ajudar a reduzir os tempos de implantação.
Diretrizes para modelos de ciência de dados
Desenvolva um modelo de ciência de dados para sua organização com as seguintes diretrizes:
Desenvolva um conjunto de modelos de IaC (infraestrutura como código) para implantar um workspace do Azure Machine Learning. Inclua recursos como um cofre de chaves, uma conta de armazenamento, um registro de contêiner e o Application Insights.
Inclua a instalação de armazenamentos de dados e destinos de computação nesses modelos, como instâncias de computação, clusters de computação e Azure Databricks.
Melhores práticas de implantação
Tempo real
- Inclua uma implantação do Azure Data Factory ou do Azure Synapse em modelos e serviços de IA do Azure.
- Os modelos devem fornecer todas as ferramentas necessárias para executar a fase de exploração da ciência de dados e a operacionalização inicial do modelo.
Considerações sobre uma configuração inicial
Em alguns casos, os cientistas de dados em sua organização podem exigir um ambiente para análise rápida conforme necessário. Essa situação é comum quando um projeto de ciência de dados não é configurado formalmente. Por exemplo, um gerenciador de projetos, código de custo ou centro de custo que pode ser necessário para cobrança cruzada dentro do Azure pode estar ausente porque o elemento ausente precisa de aprovação. Os usuários em sua organização ou equipe podem precisar acessar um ambiente de ciência de dados para entender os dados e possivelmente avaliar a viabilidade de um projeto. Além disso, alguns projetos podem não exigir um ambiente completo de ciência de dados devido ao pequeno número de produtos de dados.
Em outros casos, um projeto completo de ciência de dados pode ser necessário, completo com um ambiente dedicado, gerenciamento de projetos, código de custo e centro de custo. Projetos completos de ciência de dados são úteis para vários membros da equipe que desejam colaborar, compartilhar resultados e precisam operacionalizar modelos após o sucesso da fase de exploração.
O processo de instalação
Os modelos devem ser implantados por projeto depois de configurados. Cada projeto deve receber pelo menos duas instâncias para que os ambientes de desenvolvimento e produção sejam separados. No ambiente de produção, nenhum indivíduo deve ter acesso, e tudo deve ser implantado por meio de pipelines de integração contínua ou desenvolvimento contínuo e uma entidade de serviço. Esses princípios de ambiente de produção são importantes porque o Azure Machine Learning não fornece um modelo de controle de acesso baseado em função granular em um workspace. Não é possível limitar o acesso do usuário a um conjunto específico de experimentos, pontos de extremidade ou pipelines.
Os mesmos direitos de acesso normalmente se aplicam a diferentes tipos de artefatos. É importante separar o desenvolvimento da produção para evitar a exclusão de pipelines ou pontos de extremidade de produção em um espaço de trabalho. Junto com o modelo, um processo precisa ser criado para dar às equipes de produtos de dados a opção de solicitar novos ambientes.
Recomendamos configurar diferentes serviços de IA, como serviços de IA do Azure por projeto. Ao configurar diferentes serviços de IA por projeto, as implantações ocorrem para cada grupo de recursos do produto de dados. Essa política cria uma separação clara do ponto de vista de acesso a dados e reduz o risco de acesso a dados não autorizados pelas equipes erradas.
Cenário de streaming
Para casos de uso em tempo real e de streaming, as implantações devem ser testadas em um Serviço de Kubernetes do Azure (AKS) reduzido. O teste pode estar no ambiente de desenvolvimento para economizar custos antes de implantar no AKS de produção ou no Serviço de Aplicativo do Azure para contêineres. Você deve executar testes simples de entrada e saída para garantir que os serviços respondam conforme o esperado.
Em seguida, você pode implantar modelos no serviço desejado. Esse destino de computação de implantação é o único que está em disponibilidade geral e é recomendado para cargas de trabalho de produção em um cluster do AKS. Essa etapa é mais necessária se o suporte à GPU (unidade de processamento gráfico) ou à matriz de portas programável em campo for necessário. Outras opções de implantação nativa que dão suporte a esses requisitos de hardware não estão disponíveis atualmente no Azure Machine Learning.
O Azure Machine Learning requer um mapeamento um-para-um para clusters do AKS. Cada nova conexão com um workspace do Azure Machine Learning interrompe a conexão anterior entre o AKS e o Azure Machine Learning. Depois que essa limitação for atenuada, recomendamos implantar clusters centrais do AKS como recursos compartilhados e anexá-los aos respectivos workspaces.
Outra instância central do AKS de teste deve ser hospedada se os testes de estresse precisarem ser realizados antes de mover um modelo para o AKS de produção. O ambiente de teste deve fornecer o mesmo recurso de computação que o ambiente de produção para garantir que os resultados sejam os mais semelhantes possíveis ao ambiente de produção.
Cenário de lote
Nem todos os casos de uso precisam de implantações de cluster do AKS. Um caso de uso não precisa de uma implantação de cluster do AKS se grandes quantidades de dados só precisarem de pontuação regularmente ou se forem baseadas em um evento. Por exemplo, grandes quantidades de dados podem ser baseadas no momento em que os dados são inseridos em uma conta de armazenamento específica. Os pipelines do Azure Machine Learning e os clusters de computação do Azure Machine Learning devem ser usados para implantação durante esses tipos de cenários. Esses pipelines devem ser orquestrados e executados no Data Factory.
Identificar os recursos de computação corretos
Antes de implantar um modelo no Azure Machine Learning em um AKS, o usuário precisa especificar os recursos como CPU, RAM e GPU que devem ser alocados para o respectivo modelo. Definir esses parâmetros pode ser um processo complexo e entediante. Você precisa fazer testes de estresse com configurações diferentes para identificar um bom conjunto de parâmetros. Você pode simplificar esse processo com o recurso Model Profiling no Azure Machine Learning, que é um trabalho de longa execução que testa diferentes combinações de alocação de recursos e usa uma latência identificada e rtt (tempo de viagem de ida e volta) para recomendar uma combinação ideal. Essas informações podem ajudar na implantação real do modelo no AKS.
Para atualizar com segurança os modelos no Azure Machine Learning, as equipes devem usar o recurso de distribuição controlado (versão prévia) para minimizar o tempo de inatividade e manter o ponto de extremidade REST do modelo consistente.
Práticas recomendadas e o fluxo de trabalho para MLOps
Incluir código de exemplo em repositórios de ciência de dados
Você pode simplificar e acelerar projetos de ciência de dados se suas equipes tiverem determinados artefatos e práticas recomendadas. Recomendamos a criação de artefatos que todas as equipes de ciência de dados podem usar enquanto trabalham com o Azure Machine Learning e as respectivas ferramentas do ambiente do produto de dados. Os engenheiros de aprendizado de máquina e dados devem criar e fornecer os artefatos.
Esses artefatos devem incluir:
Blocos de anotações de exemplo que mostram como:
- Carregar, montar e trabalhar com produtos de dados.
- Métricas e parâmetros de log.
- Envie trabalhos de treinamento para clusters de computação.
Artefatos necessários para a operacionalização:
- Exemplo de pipelines do Azure Machine Learning
- Exemplo do Azure Pipelines
- São necessários mais scripts para executar pipelines
Documentação
Use artefatos bem projetados para operacionalizar pipelines
Os artefatos podem acelerar as fases de exploração e operacionalização de projetos de ciência de dados. Uma estratégia de bifurcação do DevOps pode ajudar a dimensionar esses artefatos em todos os projetos. Como essa configuração promove o uso do Git, os usuários e o processo geral de automação podem se beneficiar dos artefatos fornecidos.
Dica
Os pipelines de exemplo do Azure Machine Learning devem ser criados com o SDK (software developer kit) do Python ou com base na linguagem YAML. A nova experiência yaml será mais à prova de futuro, pois a equipe de produtos do Azure Machine Learning está trabalhando atualmente em um novo SDK e CLI (interface de linha de comando). A equipe de produtos do Azure Machine Learning está confiante de que o YAML servirá como a linguagem de definição para todos os artefatos no Azure Machine Learning.
Os pipelines de exemplo não funcionam imediatamente para cada projeto, mas podem ser usados como linha de base. Você pode ajustar os pipelines de exemplo para projetos. Um fluxo de trabalho deve incluir os aspectos mais relevantes de cada projeto. Por exemplo, um pipeline pode referenciar um destino de computação, fazer referência a produtos de dados, definir parâmetros, definir entradas e definir as etapas de execução. O mesmo processo deve ser feito para o Azure Pipelines. O Azure Pipelines também deve usar o SDK ou a CLI do Azure Machine Learning.
Os pipelines devem demonstrar como:
- Conectar-se a um espaço de trabalho de dentro de um pipeline do DevOps.
- Verifique se a computação necessária está disponível.
- Enviar um trabalho.
- Registre e implante um modelo.
Artefatos não são adequados para todos os projetos o tempo todo e podem exigir personalização, mas ter uma base pode acelerar a operacionalização e a implantação de um projeto.
Estruturar o repositório MLOps
Você pode ter situações em que os usuários perdem o controle de onde podem encontrar e armazenar artefatos. Para evitar essas situações, você deve solicitar mais tempo para se comunicar e construir uma estrutura de pasta de nível superior para o repositório padrão. Todos os projetos devem seguir a estrutura da pasta.
Observação
Os conceitos mencionados nesta seção podem ser usados em ambientes locais, Amazon Web Services, Palantir e Azure.
A estrutura de pastas de nível superior proposta para um repositório MLOps (operações de machine learning) é ilustrada no seguinte diagrama:
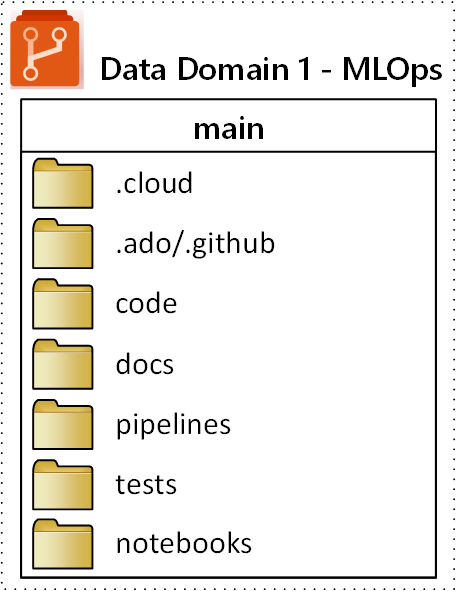
As seguintes finalidades se aplicam a cada pasta no repositório:
| Pasta | Propósito |
|---|---|
.cloud |
Armazene o código e artefatos específicos da nuvem nesta pasta. Os artefatos incluem arquivos de configuração para o espaço de trabalho do Azure Machine Learning, incluindo definições de alvos de computação, trabalhos, modelos registrados e endpoints. |
.ado/.github |
Armazene artefatos do Azure DevOps ou GitHub, como pipelines YAML ou proprietários de código, nesta pasta. |
code |
Inclua o código real desenvolvido como parte do projeto nesta pasta. Essa pasta pode conter pacotes python e alguns scripts que são usados para as respectivas etapas do pipeline de machine learning. É recomendável separar etapas individuais que precisam ser feitas nesta pasta. As etapas comuns são pré-processamento, treinamento de modelo, e registro de modelo. Defina dependências como dependências do Conda, imagens do Docker ou outras para cada pasta. |
docs |
Use esta pasta para fins de documentação. Essa pasta armazena arquivos e imagens do Markdown para descrever o projeto. |
pipelines |
Armazene definições de pipelines do Azure Machine Learning no YAML ou python nesta pasta. |
tests |
Escreva testes de unidade e integração que precisam ser executados para descobrir bugs e problemas no início durante o projeto nesta pasta. |
notebooks |
Separe os notebooks do Jupyter do projeto Python propriamente dito usando esta pasta. Dentro da pasta, cada indivíduo deve ter uma subpasta para fazer o check-in de seus notebooks e evitar conflitos de mesclagem do Git. |