Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
O Azure Cosmos DB para PostgreSQL não tem mais suporte para novos projetos. Não use esse serviço para novos projetos. Em vez disso, use um destes dois serviços:
Use o Azure Cosmos DB para NoSQL para uma solução de banco de dados distribuída projetada para cenários de alta escala com um SLA (contrato de nível de serviço de disponibilidade) de 99,999%, dimensionamento automático instantâneo e failover automático em várias regiões.
Use o recurso Clusters Elásticos do Banco de Dados do Azure para PostgreSQL no PostgreSQL compartilhado usando a extensão de código aberto Citus.
Este artigo mostra como usar a extensão pg_azure_storage do PostgreSQL para manipular e carregar dados no seu Azure Cosmos DB for PostgreSQL diretamente do ABS (Armazenamento de Blobs do Azure). O ABS é um serviço de armazenamento nativo de nuvem escalonável, durável e seguro. Essas características o tornam uma boa opção para armazenar e mover dados existentes para a nuvem.
Preparar o banco de dados e o armazenamento de blobs
Para carregar dados de Armazenamento de Blobs do Azure, instale a extensão PostgreSQL pg_azure_storage em seu banco de dados:
SELECT * FROM create_extension('azure_storage');
Importante
A extensão pg_azure_storage só está disponível em clusters do Azure Cosmos DB for PostgreSQL que executam o PostgreSQL 13 e superior.
Preparamos um conjunto de dados de demonstração pública para este artigo. Para usar seu próprio conjunto de dados, siga as instruções em migrar seus dados locais para o armazenamento em nuvem para aprender como transferir seus conjuntos de dados com eficiência para o Azure Blob Storage.
Observação
Selecionar "Contêiner (acesso de leitura anônimo para contêineres e blobs)" permitirá ingerir arquivos de Armazenamento de Blobs do Azure usando suas URLs públicas e enumerar o conteúdo do contêiner sem a necessidade de configurar uma chave de conta no pg_azure_storage. Contêineres definidos como nível de acesso "Privado (sem acesso anônimo)" ou "Blob (acesso de leitura anônimo para blobs apenas)" exigirão uma chave de acesso.
Listar conteúdo do contêiner
Há uma conta de demonstração do Armazenamento de Blobs do Azure e um contêiner pré-criado para essas instruções. O nome do contêiner é github, e está na conta pgquickstart. Podemos ver facilmente quais arquivos estão presentes no contêiner usando a função azure_storage.blob_list(account, container).
SELECT path, bytes, pg_size_pretty(bytes), content_type
FROM azure_storage.blob_list('pgquickstart','github');
-[ RECORD 1 ]--+-------------------
path | events.csv.gz
bytes | 41691786
pg_size_pretty | 40 MB
content_type | application/x-gzip
-[ RECORD 2 ]--+-------------------
path | users.csv.gz
bytes | 5382831
pg_size_pretty | 5257 kB
content_type | application/x-gzip
Você pode filtrar a saída usando uma cláusula WHERE SQL regular ou usando o parâmetro prefix da UDF blob_list. Esse último filtra as linhas retornadas no lado do Armazenamento de Blobs do Azure.
Observação
A listagem de conteúdo do contêiner requer uma conta e uma chave de acesso ou um contêiner com acesso anônimo habilitado.
SELECT * FROM azure_storage.blob_list('pgquickstart','github','e');
-[ RECORD 1 ]----+---------------------------------
path | events.csv.gz
bytes | 41691786
last_modified | 2022-10-12 18:49:51+00
etag | 0x8DAAC828B970928
content_type | application/x-gzip
content_encoding |
content_hash | 473b6ad25b7c88ff6e0a628889466aed
SELECT *
FROM azure_storage.blob_list('pgquickstart','github')
WHERE path LIKE 'e%';
-[ RECORD 1 ]----+---------------------------------
path | events.csv.gz
bytes | 41691786
last_modified | 2022-10-12 18:49:51+00
etag | 0x8DAAC828B970928
content_type | application/x-gzip
content_encoding |
content_hash | 473b6ad25b7c88ff6e0a628889466aed
Carregar dados de ABS
Carregar dados usando o comando COPY
Comece criando um esquema de exemplo.
CREATE TABLE github_users
(
user_id bigint,
url text,
login text,
avatar_url text,
gravatar_id text,
display_login text
);
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
user_id bigint,
org jsonb,
created_at timestamp
);
CREATE INDEX event_type_index ON github_events (event_type);
CREATE INDEX payload_index ON github_events USING GIN (payload jsonb_path_ops);
SELECT create_distributed_table('github_users', 'user_id');
SELECT create_distributed_table('github_events', 'user_id');
Carregar dados nas tabelas torna-se tão simples quanto chamar o comando COPY.
-- download users and store in table
COPY github_users
FROM 'https://pgquickstart.blob.core.windows.net/github/users.csv.gz';
-- download events and store in table
COPY github_events
FROM 'https://pgquickstart.blob.core.windows.net/github/events.csv.gz';
Observe como a extensão reconheceu que as URLs fornecidas ao comando de cópia são do Armazenamento de Blobs do Azure, os arquivos que apontamos foram compactados com gzip, o que também foi tratado automaticamente para nós.
O comando COPY dá suporte a mais parâmetros e formatos. No exemplo acima, o formato e a compactação foram selecionados automaticamente com base nas extensões de arquivo. No entanto, você pode fornecer o formato diretamente semelhante ao comando COPY regular.
COPY github_users
FROM 'https://pgquickstart.blob.core.windows.net/github/users.csv.gz'
WITH (FORMAT 'csv');
Atualmente, a extensão dá suporte aos seguintes formatos de arquivo:
| formato | descrição |
|---|---|
| csv | Formato de valores separados por vírgula usado pelo PostgreSQL COPY |
| tsv | Valores separados por tabulação, o formato PostgreSQL COPY |
| binário | Formato PostgreSQL COPY binário |
| enviar SMS | Um arquivo que contém um único valor de texto (por exemplo, JSON ou XML grande) |
Carregar dados com blob_get()
O comando COPY é conveniente, mas limitado em flexibilidade. Internamente, o COPY usa a função blob_get, que você pode usar diretamente para manipular dados em cenários mais complexos.
SELECT *
FROM azure_storage.blob_get(
'pgquickstart', 'github',
'users.csv.gz', NULL::github_users
)
LIMIT 3;
-[ RECORD 1 ]-+--------------------------------------------
user_id | 21
url | https://api.github.com/users/technoweenie
login | technoweenie
avatar_url | https://avatars.githubusercontent.com/u/21?
gravatar_id |
display_login | technoweenie
-[ RECORD 2 ]-+--------------------------------------------
user_id | 22
url | https://api.github.com/users/macournoyer
login | macournoyer
avatar_url | https://avatars.githubusercontent.com/u/22?
gravatar_id |
display_login | macournoyer
-[ RECORD 3 ]-+--------------------------------------------
user_id | 38
url | https://api.github.com/users/atmos
login | atmos
avatar_url | https://avatars.githubusercontent.com/u/38?
gravatar_id |
display_login | atmos
Observação
Na consulta acima, o arquivo é totalmente buscado antes de LIMIT 3 ser aplicado.
Com essa função, você pode manipular dados em tempo real em consultas complexas e fazer importações como INSERT FROM SELECT.
INSERT INTO github_users
SELECT user_id, url, UPPER(login), avatar_url, gravatar_id, display_login
FROM azure_storage.blob_get('pgquickstart', 'github', 'users.csv.gz', NULL::github_users)
WHERE gravatar_id IS NOT NULL;
INSERT 0 264308
No comando acima, filtramos os dados para contas com um gravatar_id presente e colocamos em maiúsculas seus logons em tempo real.
Opções para blob_get()
Em algumas situações, talvez seja necessário controlar exatamente o que blob_get tenta fazer usando os parâmetros decoder, compression e options.
O decodificador pode ser definido como auto (padrão) ou qualquer um dos seguintes valores:
| formato | descrição |
|---|---|
| csv | Formato de valores separados por vírgula usado pelo PostgreSQL COPY |
| tsv | Valores separados por tabulação, o formato PostgreSQL COPY |
| binário | Formato PostgreSQL COPY binário |
| enviar SMS | Um arquivo que contém um único valor de texto (por exemplo, JSON ou XML grande) |
compression pode ser auto (o padrão), none ou gzip.
Por fim, o parâmetro options é do tipo jsonb. Há quatro funções utilitárias que ajudam a criar valores para isso.
Cada função utilitária é designada para o decodificador correspondente ao seu nome.
| decodificador | função de opções |
|---|---|
| csv | options_csv_get |
| tsv | options_tsv |
| binário | options_binary |
| enviar SMS | options_copy |
Examinando as definições de função, você pode ver quais parâmetros têm suporte para o decodificador.
options_csv_get – delimiter, null_string, header, quote, escape, force_not_null, force_null, content_encoding options_tsv – delimiter, null_string, content_encoding options_copy – delimiter, null_string, header, quote, escape, force_quote, force_not_null, force_null, content_encoding.
options_binary - codificação_de_conteúdo
Sabendo disso, podemos descartar gravações com gravatar_id nulo durante a análise.
INSERT INTO github_users
SELECT user_id, url, UPPER(login), avatar_url, gravatar_id, display_login
FROM azure_storage.blob_get('pgquickstart', 'github', 'users.csv.gz', NULL::github_users,
options := azure_storage.options_csv_get(force_not_null := ARRAY['gravatar_id']));
INSERT 0 264308
Acessar o armazenamento privado
Obter o nome da conta e a chave de acesso
Sem uma chave de acesso, não teremos permissão para listar contêineres definidos como níveis de acesso privado ou blob.
SELECT * FROM azure_storage.blob_list('mystorageaccount','privdatasets');ERROR: azure_storage: missing account access key HINT: Use SELECT azure_storage.account_add('<account name>', '<access key>')Em sua conta de armazenamento, abra Chaves de acesso. Copie o nome da conta de armazenamento e copie a chave da seção key1 (você precisa selecionar Mostrar ao lado da chave primeiro).
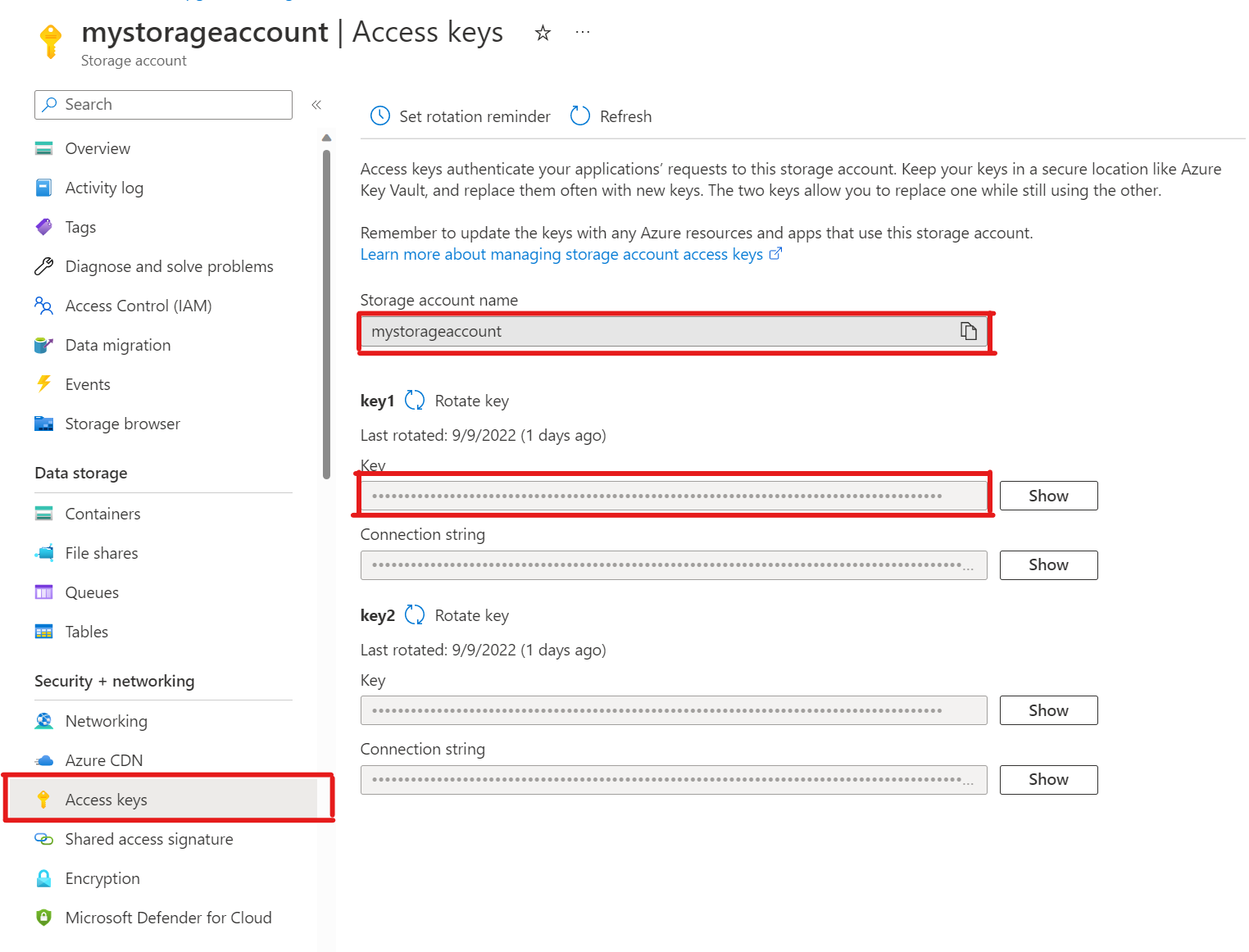
Adicionando uma conta ao pg_azure_storage
SELECT azure_storage.account_add('mystorageaccount', 'SECRET_ACCESS_KEY');Agora você pode listar contêineres definidos como níveis de acesso privado e blob para esse armazenamento, mas apenas como o usuário
citus, que tem a funçãoazure_storage_adminconcedida a ele. Se você criar um novo usuário chamadosupport, ele não poderá acessar o conteúdo do contêiner por padrão.SELECT * FROM azure_storage.blob_list('pgabs','dataverse');ERROR: azure_storage: current user support is not allowed to use storage account pgabsPermita que o usuário
supportuse uma conta Armazenamento de Blobs do Azure específicaConceder a permissão é tão simples quanto chamar
account_user_add.SELECT * FROM azure_storage.account_user_add('mystorageaccount', 'support');Podemos ver os usuários permitidos na saída de
account_list, que mostra todas as contas com chaves de acesso definidas.SELECT * FROM azure_storage.account_list();account_name | allowed_users ------------------+--------------- mystorageaccount | {support} (1 row)Se você decidir que o usuário não deve mais ter acesso. Basta chamar
account_user_remove.SELECT * FROM azure_storage.account_user_remove('mystorageaccount', 'support');
Próximas etapas
Parabéns, você acabou de aprender a carregar dados no Azure Cosmos DB para PostgreSQL diretamente do Armazenamento de Blobs do Azure.
- Saiba como criar um painel em tempo real com o Azure Cosmos DB for PostgreSQL.
- Saiba mais sobre o pg_azure_storage.
- Saiba mais sobre o suporte ao Postgres COPY.