Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
O Azure Cosmos DB para PostgreSQL está em um caminho de desativação e não é mais recomendado para novos projetos. Em vez disso, use um destes dois serviços:
Para cargas de trabalho do PostgreSQL: use o recurso Clusters Elásticos do Banco de Dados do Azure para PostgreSQL para aproveitar o escalonamento horizontal e os recursos do PostgreSQL distribuídos, contidos na extensão Citus de software livre. Para obter diretrizes de migração, consulte migração para o Banco de Dados do Azure para PostgreSQL com Cluster Elástico.
Para cargas de trabalho NoSQL , use o Azure Cosmos DB para NoSQL para uma solução de banco de dados distribuído que inclui um SLA (contrato de nível de serviço de disponibilidade) de 99,999%, dimensionamento automático instantâneo e failover automático em várias regiões.
Neste tutorial, você usará o Azure Cosmos DB for PostgreSQL para saber como:
- Criar fragmentos distribuídos por hash
- Ver o local em que os fragmentos de tabela são colocados
- Identificar distribuição distorcida
- Criar restrições em tabelas distribuídas
- Executar consultas em dados distribuídos
Pré-requisitos
Este tutorial precisa de um cluster em execução com dois nós de trabalho. Se você não tiver um cluster em execução, siga o tutorial para criar cluster e volte para este.
Dados distribuídos por hash
A distribuição de linhas de tabela em vários servidores PostgreSQL é uma técnica fundamental para consultas escalonáveis no Azure Cosmos DB for PostgreSQL. Juntos, vários nós podem conter mais dados do que um banco de dados tradicional e, em muitos casos, podem usar CPUs de trabalho em paralelo para executar consultas. O conceito de tabelas distribuídas por hash também é conhecido como sharding baseado em linhas.
Na seção pré-requisitos, criamos um cluster com dois nós de trabalho.
As tabelas de metadados do nó coordenador controlam os trabalhos e os dados distribuídos. Podemos verificar os trabalhadores ativos na tabela pg_dist_node.
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
Observação
Os nomes de nó no Azure Cosmos DB for PostgreSQL são endereços IP internos em uma rede virtual e os endereços reais que você vê podem ser diferentes.
Linhas, fragmentos e posicionamentos
Para usar os recursos de CPU e de armazenamento dos nós de trabalho, precisamos distribuir dados de tabela em todo o cluster. A distribuição de uma tabela atribui cada linha a um grupo lógico chamado shard. Vamos criar uma tabela e distribuí-la:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
O Azure Cosmos DB for PostgreSQL atribui cada linha a um fragmento com base no valor da coluna de distribuição, que, em nosso caso, especificamos como email. Cada linha estará em exatamente um fragmento e cada fragmento pode conter várias linhas.
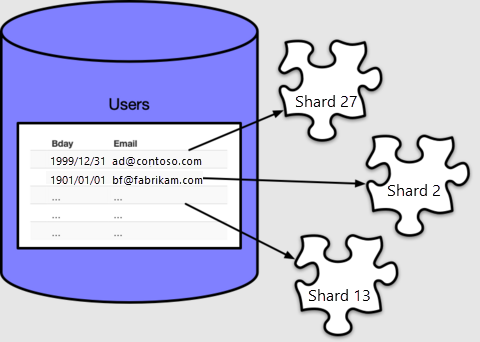
Por padrão create_distributed_table() faz 32 fragmentos, como podemos ver contando na tabela de metadados pg_dist_shard:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
O Azure Cosmos DB for PostgreSQL usa a tabela pg_dist_shard para atribuir linhas a fragmentos, com base em um hash do valor na coluna de distribuição. Os detalhes do hash não são importantes para este tutorial. O que importa é que podemos consultar para ver quais valores são mapeados para quais IDs de fragmentos:
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
O mapeamento de linhas para fragmentos é puramente lógico. Os fragmentos devem ser atribuídos a nós de trabalho específicos para armazenamento, o que o Azure Cosmos DB for PostgreSQL chama de posicionamento de fragmento.
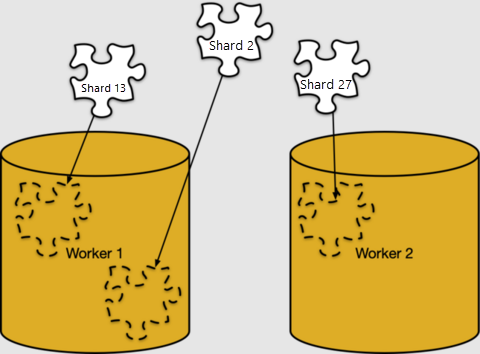
Podemos examinar os posicionamentos de fragmentos em pg_dist_placement. Unindo-a com as outras tabelas de metadados que vimos mostra onde cada fragmento reside.
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
Distorção de dados
Um cluster é executado com mais eficiência quando você coloca os dados uniformemente em nós de trabalho e quando coloca dados relacionados juntos nos mesmos trabalhos. Nesta seção, vamos nos concentrar na primeira parte: a uniformidade do posicionamento.
Para demonstrar, vamos criar dados de exemplo para nossa tabela users:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
Para ver os tamanhos de fragmentos, podemos executar funções de tamanho de tabela nos fragmentos.
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
Podemos ver que os fragmentos são de tamanho igual. Já vimos que os posicionamentos estão distribuídos uniformemente entre os trabalhadores, portanto, podemos inferir que os nós de trabalho contêm números de linhas aproximadamente iguais.
As linhas em nosso exemplo users estão distribuídas uniformemente devido às propriedades da coluna de distribuição, email.
- O número de endereços de email era superior ou igual ao número de fragmentos.
- O número de linhas por endereço de email era semelhante (em nosso caso, exatamente uma linha por endereço, porque declaramos o email como uma chave).
Qualquer opção de tabela e coluna de distribuição em que uma das propriedades falhar terminará com tamanho de dados irregular nos trabalhos, ou seja, distorção de dados.
Adicionar restrições a dados distribuídos
Usar o Azure Cosmos DB for PostgreSQL permite que você continue a desfrutar da segurança de um banco de dados relacional, incluindo as restrições de banco de dados. No entanto, há uma limitação. Por causa da natureza dos sistemas distribuídos, o Azure Cosmos DB for PostgreSQL não faz referência cruzada a restrições de exclusividade ou integridade referencial entre nós de trabalho.
Vamos considerar nosso exemplo de tabela users com uma tabela relacionada.
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
Por questão de eficiência, distribuímos books da mesma maneira que users: pelo endereço de email do proprietário. A distribuição por valores de coluna semelhantes é chamada de colocação.
Não tínhamos problema ao distribuir livros com uma chave estrangeira para os usuários, pois a chave estava em uma coluna de distribuição. No entanto, teríamos problemas para tornar isbn uma chave:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
Em uma tabela distribuída, o melhor que podemos fazer é tornar as colunas um módulo exclusivo da coluna de distribuição:
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
A restrição acima simplesmente torna o ISBN exclusivo por usuário. Outra opção é tornar os livros uma tabela de referência em vez de uma tabela distribuída e criar uma tabela distribuída separada associando livros a usuários.
Consultar tabelas distribuídas
Nas seções anteriores, vimos como as linhas da tabela distribuída são colocadas em fragmentos em nós de trabalho. Na maioria das vezes, você não precisa saber como ou onde os dados são armazenados em um cluster. O Azure Cosmos DB for PostgreSQL tem um executor de consulta distribuída que divide automaticamente consultas SQL regulares. Executa-os em paralelo em nós de trabalho que estão próximos aos dados.
Por exemplo, podemos executar uma consulta para encontrar a idade média dos usuários, tratando a tabela users distribuída como uma tabela normal no coordenador.
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
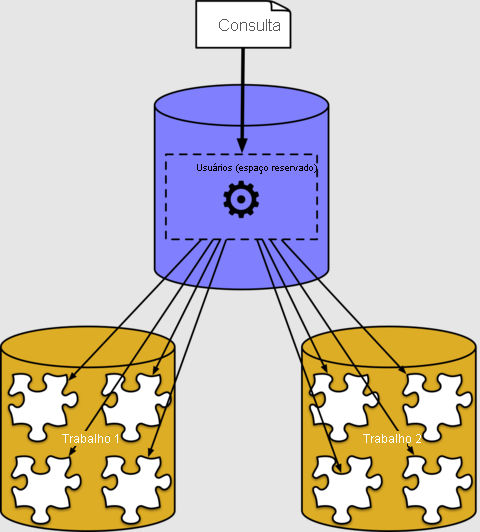
Nos bastidores, o executor do Azure Cosmos DB for PostgreSQL cria uma consulta separada para cada fragmento, executa essas consultas nos trabalhadores e combina o resultado. Veja isso usando o comando EXPLAIN do PostgreSQL:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
A saída mostra um exemplo de um plano de execução para um fragmento de consulta em execução no shard 102040 (a tabela users_102040 no trabalhador 10.0.0.21). Os outros fragmentos não são mostrados porque são semelhantes. Podemos ver que o nó de trabalho examina as tabelas de fragmentos e aplica a agregação. O nó coordenador combina as agregações para o resultado final.
Próximas etapas
Neste tutorial, criamos uma tabela distribuída e aprendemos sobre seus fragmentos e posicionamentos. Vimos um desafio de usar restrições de exclusividade e de chave estrangeira e, finalmente, vimos como as consultas distribuídas funcionam em um alto nível.
- Leia mais sobre os tipos de tabela do Azure Cosmos DB for PostgreSQL
- Obtenha mais dicas sobre como escolher uma coluna de distribuição
- Conheça os benefícios da colocação de tabela