Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE AO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() Tabela
Tabela
Viver em uma sociedade amplamente interconectada significa que, em determinado momento da vida, você acaba se tornando parte de uma rede social. Você usa redes sociais para manter contato com amigos, colegas, família ou, às vezes, para compartilhar seu entusiasmo com pessoas que têm os mesmos interesses.
Como engenheiros ou desenvolvedores, talvez você queira saber como essas redes armazenam e interconectam seus dados. Ou você pode até mesmo ter sido designado para criar ou estruturar uma nova rede social para determinado nicho de mercado. É nesse momento que surge a importante pergunta: como todos esses dados são armazenados?
Vamos supor que você esteja criando uma nova rede social, na qual seus usuários possam postar artigos com mídia relacionada como imagens, vídeos ou até mesmo música. Os usuários podem fazer comentários sobre as postagens e fornecer pontos para classificações. Haverá um feed de postagens que os usuários verão e interagirão com uma das principais páginas de aterrissagem do site. Esse método não soa complexo em primeiro lugar, mas para simplificar, vamos parar por aqui. (você pode se aprofundar em feeds do usuário personalizados afetados por relacionamentos, mas eles ultrapassem o objetivo deste artigo.)
Então, como e onde você armazena tudo isso?
É provável que você conheça a fundo os bancos de dados SQL ou, pelo menos, tenha uma noção de modelagem relacional de dados. Você pode começar a desenhar algo da seguinte maneira:
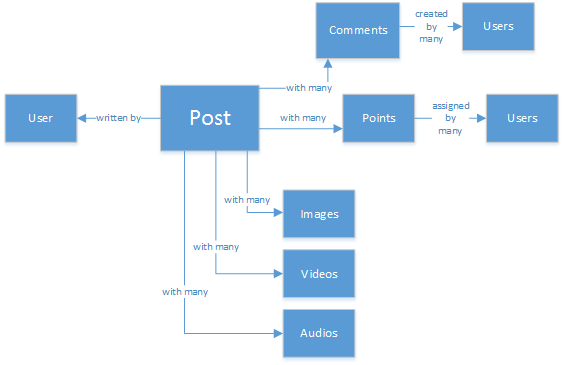
Uma bela estrutura de dados perfeitamente normalizada...que não pode ser escalonada.
Não me entenda mal, eu trabalhei com bancos de dados SQL todas as minha vida. Eles são ótimos, mas, como todas as plataformas padrão, prática e software, não são perfeitos para todos os cenários.
Por que o SQL não é a melhor opção nesse cenário? Vamos examinar a estrutura de uma única postagem. Se eu quisesse mostrar essa postagem em um site ou aplicativo, teria que fazer uma consulta com...oito junções de tabela (!) só para mostra uma única postagem. Agora, imagine uma transmissão de postagens carregadas dinamicamente e exibidas na tela e você poderá entender a que estou me referindo.
Para atender às necessidades de seu conteúdo, você poderia usar uma instância SQL gigantesca com capacidade suficiente para resolver milhares de consultas com várias junções. Mas, por que faria isso quando há uma solução mais simples?
O caminho NoSQL
Este artigo orienta você na modelagem de dados de sua plataforma social com o banco de dados NoSQL Azure do Azure Cosmos DB de maneira econômica. Ele também explica como usar outros recursos do Azure Cosmos DB, como a API para Gremlin. Usando uma abordagem NoSQL, armazenando os dados no formato JSON e aplicando a desnormalização, sua postagem anteriormente complicada pode ser transformada em um único Documento:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
E isso pode ser obtido com uma única consulta, sem junções. Essa consulta é muito simples e econômico, além de exigir menos recursos para alcançar um resultado melhor.
O Azure Cosmos DB garante que todas as propriedades sejam indexadas com sua indexação automática. A indexação automática pode até mesmo ser personalizada. A abordagem sem esquemas nos permite armazenar documentos com estruturas diferentes e dinâmicas. Talvez no futuro você queira que as postagens tenham uma lista de categorias ou hashtags associadas a elas? O Azure Cosmos DB manipula os novos Documentos com os atributos adicionados sem trabalho extra exigido por nós.
Os comentários em uma postagem podem ser tratados da mesma forma como outras postagens com uma propriedade pai. (isso simplifica seu mapeamento de objeto.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Além disso, todas as interações sociais podem ser armazenadas em um objeto separado como contadores:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
A criação de feeds resume-se à criação de documentos que podem reter uma lista de IDs da postagem com determinada ordem de relevância:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Você poderia ter um fluxo "mais recente" com as postagens ordenadas por data de criação. Ou você poderia ter um fluxo "mais popular" com as postagens com mais curtidas nas últimas 24 horas. Você pode até mesmo implementar um fluxo personalizado para cada usuário com base em lógica como seguidores e interesses. Ainda seria uma lista de postagens. É uma questão de como criar essas listas, mas fazer com que o desempenho de leitura permaneça ilimitado. Depois de adquirir uma dessas listas, você emitirá apenas uma consulta para o Azure Cosmos DB usando a palavra-chave IN para obter páginas de postagens de uma só vez.
As transmissões de feed podem ser criadas usando processos em segundo plano dos Serviços de Aplicativos do Azure: Webjobs. Depois que uma postagem é criada, o processamento em segundo plano pode ser acionado usando Armazenamento do Microsoft AzureQueues e Webjobs acionados usando o Azure Webjobs SDK, implementando a pós-propagação dentro de fluxos com base em sua própria lógica personalizada.
Os pontos e as curtidas de uma postagem podem ser processados de forma adiada usando essa mesma técnica, a fim de criar um ambiente que, no final das contas, seja consistente.
Os seguidores são mais complicados. O Azure Cosmos DB tem um limite de tamanho para documentos e ler/gravar documentos grandes pode afetar a escalabilidade do aplicativo. Portanto, pense em armazenar seguidores como um documento com esta estrutura:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Essa estrutura pode funcionar para um usuário com alguns milhares de seguidores. Se alguma celebridade ingressar nas fileiras, no entanto, essa abordagem leva a um grande tamanho de documento, e pode eventualmente atingir o limite de tamanho do documento.
Para resolver isso, você pode usar uma abordagem mista. Como parte do documento de Estatísticas do Usuário, você pode armazenar o número de seguidores:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Você pode armazenar o grafo real de seguidores usando a API para Gremlin do Azure Cosmos DB para criar vértices para cada usuário e bordas que mantêm as relações "A-segue-B". Com a API para Gremlin, você pode obter os seguidores de um determinado usuário e criar consultas mais complexas para sugerir pessoas em comum. Se adicionar ao grafo as Categorias de Conteúdo que as pessoas curtem, é possível começar a combinar experiências que incluem a descoberta de conteúdo inteligente, sugestão de conteúdo curtido pelas pessoas que você segue ou localização das pessoas com quem pode ter muito em comum.
O documento Estatísticas do Usuário ainda pode ser usado para criar cartões na interface do usuário ou visualizações rápidas de perfil.
O padrão de “Escada” e a duplicação de dados
Como você deve ter observado no documento JSON que faz referência a uma postagem, há várias ocorrências de um usuário. E deve ter acertado: isso significa que as informações que descrevem um usuário, considerando essa desnormalização, podem estar presentes em mais de um local.
Para possibilitar consultas mais rápidas, você fica sujeito à duplicação de dados. O problema com esse efeito colateral é que, se por alguma ação, ocorrerem alterações aos dados de um usuário, será preciso encontrar todas as atividades já realizadas por ele e atualizá-las. Não parece prático, certo?
Você resolverá isso identificando os principais atributos de um usuário mostrados em seu aplicativo para cada atividade. Se você mostra visualmente uma postagem em seu aplicativo e apenas o nome e a imagem do criador, para que armazenar todos os dados do usuário no atributo “createdBy”? Se, para cada comentário, mostrar apenas a imagem do usuário, realmente, você não precisa do restante das informações dele. É nesse momento que entra em cena o que chamo de “padrão de Escada”.
Vamos usar as informações do usuário como exemplo:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Examinando essas informações, é possível detectar rapidamente quais informações são críticas e quais não são, criando, assim, uma “Escada”:

A menor etapa é chamada de UserChunk, a informação mínima que identifica um usuário e que é usada para a duplicação de dados. Ao reduzir o tamanho dos dados duplicados somente às informações que serão “mostradas”, você reduz a possibilidade de atualizações em massa.
A etapa intermediária é chamada de usuário. São os dados completos usados na maioria das consultas dependentes de desempenho no Azure Cosmos DB, os mais acessados e críticos. Ela inclui as informações representadas por um UserChunk.
A maior etapa é Extended User. Ele inclui as informações críticas de usuário e outros dados que não precisam ser lidos rapidamente ou tem eventual uso, como o processo de logon. Esses dados podem ser armazenados fora do Azure Cosmos DB, no Banco de Dados SQL do Azure ou nas Tabelas de Armazenamento do Azure.
Por que você dividiria o usuário e, até mesmo, armazenaríamos essas informações em locais diferentes? Porque, da perspectiva de desempenho, quanto maiores os documentos, mais caras as consultas. Mantenha os documentos simples, com as informações certas para fazer todas as suas consultas dependentes de desempenho para sua rede social. Armazene informações extras para eventuais cenários como edições de perfil completo, logons e mineração de dados para análise de uso e iniciativas de Big Data. Você realmente não se importa se a coleta de dados para mineração de dados é mais lenta, pois ele está em execução no Banco de Dados SQL do Azure. Você tem a preocupação de que seus usuários tenham uma experiência rápida e descomplicada. Um usuário armazenado no Azure Cosmos DB teria este código:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
E um Post teria a seguinte aparência:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Quando surgir uma edição em que um atributo de parte é afetado, você pode encontrar facilmente os documentos afetados. Basta usar consultas que apontam para os atributos indexados, como SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id"e, em seguida, atualize as partes.
A caixa de pesquisa
Os usuários geram, felizmente, muito conteúdo. Além disso, você deve ser capaz de fornecer os meios pelos quais seja possível pesquisar e encontrar o conteúdo que, talvez, não esteja disponível diretamente em seus fluxos de conteúdo, provavelmente, porque não segue os criadores ou porque está apenas tentando encontrar aquela mensagem antiga que postou há seis meses.
Como você está usando o Azure Cosmos DB, é possível implementar facilmente um mecanismo de pesquisa com a Pesquisa de IA do Azure em poucos minutos sem digitar qualquer código que não a interface do usuário e o processo de pesquisa.
Por que esse processo é tão fácil?
Pesquisa de IA do Azure implementa o que é chamado de Indexadores, processos em segundo plano que se anexam aos repositórios de dados e adicionam, atualizam ou removem automaticamente os objetos nos índices. Eles dão suporte a indexadores do Banco de Dados SQL do Azure, indexadores dos Blobs do Azure e, ainda bem, indexadores do Azure Cosmos DB. A transição de informações do Azure Cosmos DB para a Pesquisa de IA do Azure é simples. Ambas as tecnologias armazenam informações no formato JSON, portanto, você precisa apenas criar seu índice e mapear os atributos de seus documentos que você deseja indexar. É isso! Dependendo do tamanho dos dados, todo o conteúdo está disponível para ser pesquisado em minutos pela melhor solução de Pesquisa como Serviço na infraestrutura de nuvem.
Para obter mais informações sobre a Pesquisa de IA do Azure, visite o Hitchhiker’s Guide to Search.
O conhecimento subjacente
Depois de armazenar todo esse conteúdo que aumenta a cada dia, talvez você comece a pensar: o que posso fazer com todo esse fluxo de informações de meus usuários?
A resposta é simples: colocá-lo em prática e aprender com ele.
Mas o que você pode aprender? Alguns exemplos simples incluem a análise de sentimento, recomendações de conteúdo de acordo com as preferências de um usuário ou, até mesmo, um moderador de conteúdo automatizado que garante que todo o conteúdo publicado pela sua rede social é seguro para a família.
Agora que prendi a atenção de vocês, é provável que achem que é preciso contratar um PhD em ciência matemática para extrair esses padrões e essas informações de arquivos e bancos de dados simples, mas esse não é o caso.
O Azure Machine Learning é um serviço de nuvem totalmente gerenciado que permite criar fluxos de trabalho usando algoritmos em uma interface simples de arrastar e soltar, codificar seus próprios algoritmos em R ou usar algumas das APIs já criadas e prontas para uso, como: Análise de Texto, Content Moderator ou Recomendações.
Para obter qualquer um desses cenários de Machine Learning, você pode usar do Azure Data Lake para receber as informações de fontes diferentes. Você também pode usar o U-SQL para processar as informações e gerar uma saída que pode ser processada pelo Azure Machine Learning.
Outra opção disponível é usar os serviços de IA do Azure para analisar o conteúdo dos usuários. Você pode não apenas compreendê-los melhor (analisando o que eles escrevem com a API de Análise de Texto), mas também detectar o conteúdo indesejado ou maduro e agir de acordo com a API da Pesquisa Visual Computacional. Os serviços de IA do Azure incluem muitas soluções prontas para uso que não exigem nenhum tipo de conhecimento do Machine Learning a ser usado.
Uma experiência social em grande escala
Há um último artigo importante, mas não menos importante, que devo abordar: escalabilidade. Quando você cria uma arquitetura, cada componente deve ser dimensionado por conta própria. Eventualmente, você precisará processar mais dados ou desejará ter uma cobertura geográfica maior. Felizmente, realizar uma tarefa complexa como essa é uma experiência turnkey com o Azure Cosmos DB.
O Azure Cosmos DB dá suporte a particionamento dinâmico imediato. Ele automaticamente cria partições com base em uma determinada chave de partição, que é definida como um atributo em seus documentos. Definir a chave de partição correta deve ser feita em tempo de design. Para obter mais informações, consulte Particionamento no Azure Cosmos DB.
Para obter uma experiência social, você deve alinhar sua estratégia de particionamento com o modo de consulta e gravação. (Por exemplo, as leituras na mesma partição são desejáveis e evitam "pontos de acesso" espalhando gravações em várias partições.) Algumas opções são: partições baseadas em uma chave temporal (dia/mês/semana), por categoria de conteúdo, por região geográfica ou por usuário. Tudo depende realmente de como você consulta os dados e mostra os dados em sua experiência social.
O Azure Cosmos DB executa suas consultas (incluindo agregações) em todas as partições de forma transparente, portanto, você não precisa adicionar nenhuma lógica à medida que seus dados crescem.
Com o tempo, em última análise, você terá um aumento no tráfego e no consumo de recursos (medido em RUs ou Unidade de Solicitação), aumentará. Você lerá e escreverá com mais frequência à medida que sua base de usuários crescer. A base de usuários começa a criar e ler mais conteúdo. Portanto, a capacidade do dimensionar a produtividade é vital. É fácil aumentar seu RUs. Você pode fazer isso com algumas opções no portal do Azure ou emitindo comandos por meio da API.
O que acontece se as coisas ficarem melhores? Suponha que os usuários de um outro país/região ou continente descubram sua plataforma e comecem a utilizá-la. Será uma ótima surpresa!
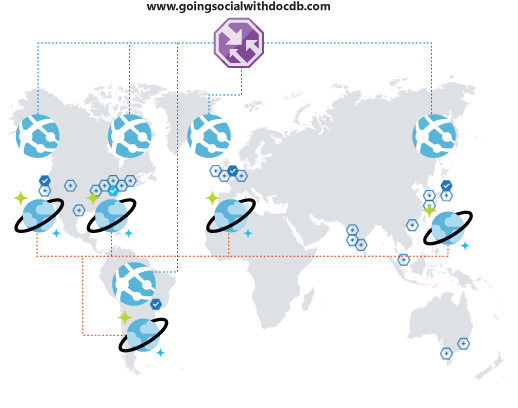
Mas espere! Você logo perceberá que sua experiência com a plataforma não é ideal. Eles estão até o momento longe de sua região operacional que a latência é terrível. É claro que não deseja perdê-los. Se houvesse uma maneira fácil de estender seu alcance global? Há!
O Azure Cosmos DB permite replicar seus dados globalmente e de forma transparente com alguns cliques, e selecionar automaticamente entre as regiões disponíveis no código do cliente. Isso também significa que é possível ter várias regiões de failover.
Ao replicar os dados globalmente, você precisa garantir que os clientes podem aproveitá-los. Se você estiver usando um front-end da Web ou acessando APIs em clientes móveis, poderá implantar o Gerenciador de Tráfego do Azure e clonar o Serviço de Aplicativo do Azure em todas as regiões desejadas, usando uma configuração de desempenho para dar suporte à cobertura global estendida. Quando seus clientes acessam seu front-end ou APIs, eles são roteados para o App Service mais próximo, que, em seguida, se conectará à réplica local do Azure Cosmos DB.
Conclusão
Este artigo esclarece as alternativas para criação de redes sociais completamente no Azure com os serviços de baixo custo. Ele fornece resultados incentivando o uso de uma solução de armazenamento de várias camadas e distribuição de dados chamada "Escada".
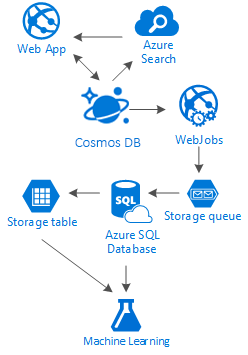
A verdade é que não há nenhuma bala de prata para esse tipo de cenários. É a sinergia criada pela combinação de serviços excepcionais que nos permite proporcionar experiências incríveis: a velocidade e a liberdade possibilitadas pelo Azure Cosmos DB para fornecer um excelente aplicativo social, a inteligência por trás de uma solução de pesquisa de primeira classe, como a Pesquisa de IA do Azure, a flexibilidade dos Serviços de Aplicativos do Azure para não hospedar sequer aplicativos independentes de idioma, e o Armazenamento do Azure e o Banco de Dados SQL do Azure expansíveis para armazenar grandes quantidades de dados, bem como o poder de análise do Azure Machine Learning para criar conhecimento e inteligência que podem fornecer comentários para os seus processos e nos ajudar a entregar o conteúdo certo para os usuários certos.
Próximas etapas
Para saber mais sobre casos de uso do Azure Cosmos DB, confira Casos de uso comuns do Azure Cosmos DB.