Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Azure Data Factory é o serviço de ETL e integração de dados do Microsoft na nuvem. Este artigo fornece diretrizes de DataOps para Data Factory. Não pretende ser um tutorial completo sobre CI/CD, Git ou DevOps. Na verdade, você poderá conferir as diretrizes da equipe de data factory para realizar o DataOps no serviço, com referências de links de implementação detalhados para boas práticas de implantação de alocadores de dados, gerenciamento de alocadores e governança. O final do artigo inclui uma seção de recursos com links para tutoriais.
O que é DataOps?
DataOps é um processo de gerenciamento colaborativo de dados que as organizações de dados praticam com o objetivo de fornecer valor aos tomadores de decisão com maior rapidez.
A Gartner oferece essa clara definição de DevOps:
DataOps é uma prática colaborativa de gerenciamento de dados focada em aprimorar a comunicação, a integração e a automação de fluxos de dados entre gerentes de dados e consumidores de dados em uma organização. O objetivo do DataOps é fornecer valor com maior rapidez ao criar uma entrega e um gerenciamento de alterações de dados, modelos de dados e artefatos relacionados mais previsíveis. O DataOps usa tecnologia para automatizar o design, a implantação e o gerenciamento da entrega de dados com níveis apropriados de governança e usa metadados para aumentar a usabilidade e o valor dos dados em um ambiente dinâmico.
Como você obtém o DataOps no Azure Data Factory?
Azure Data Factory fornece aos engenheiros de dados um paradigma de pipeline de dados baseado visualmente para criar facilmente projetos de ETL e integração de dados em escala de nuvem. O Data Factory depende de integrações nativas com ferramentas de controle de versão maduras, como GitHub e Azure DevOps, bem como o ecossistema de Azure mais amplo, para fornecer muitos recursos internos para facilitar o DataOps que incluem colaboração avançada, governança e relações de artefatos.
Especificamente, após trazer seu próprio repositório do GitHub ou do Azure DevOps para o data factory, o serviço oferece opções intuitivas de interface do usuário integradas para comandos comuns como commits, salvamento de artefatos e controle de versão. O serviço também oferece a opção de fornecer boas práticas de CI/CD e check-in de código para proteger a sanidade e a integridade do seu ambiente de produção.
"Código" no Azure Data Factory
Todos os artefatos em Azure Data Factory, sejam pipelines, serviços vinculados, gatilhos etc. têm representações de "código" correspondentes no JSON por trás da integração da interface do usuário visual. Esses artefatos atuam em conformidade com os padrões de Azure Resource Manager templates. Você pode encontrar o código clicando no ícone de colchete no canto superior direito da tela. Um exemplo de “código” da função JSON seria mais ou menos assim:

Modo ao vivo e controle de versão do Git
Cada data factory tem uma fonte única de verdade: pipelines, serviços vinculados e definições de gatilho armazenadas dentro do serviço. Essa fonte de veracidade é aquilo que o pipeline executa e que determina os comportamentos dos gatilhos. Se estiver no modo ao vivo, sempre que publicar você irá modificar diretamente a fonte única de verdade. A imagem a seguir mostra a aparência do botão Publicar Tudo no modo ao vivo.

O modo ao vivo pode ser conveniente para uma única pessoa trabalhando em projetos paralelos, já que permite que os desenvolvedores vejam os efeitos imediatos de suas alterações de código. No entanto, não incentivamos seu uso para uma equipe de desenvolvedores trabalhando em projetos de trabalho no nível de produção. Os perigos incluem dedos avantajados, exclusões acidentais de recursos críticos, publicação de códigos não testados etc., para citar apenas alguns. Ao trabalhar em plataformas e projetos críticos, pense em trazer um repositório Git e usar o modo Git no data factory para simplificar o processo de desenvolvimento. O controle de versão e os recursos de check-in restrito do modo Git ajudam a evitar a maioria, se não todos, os acidentes associados ao uso direto do modo ativo.
Observação
No modo Git, o botão Publicar ou Publicar Tudo será substituído por Salvar ou Salvar Tudo, e suas alterações serão confirmadas em seus próprios branches (sem alterar diretamente as bases de código ao vivo).
Configurando a integração GitHub e Azure DevOps
Em Azure Data Factory, é altamente recomendável armazenar seu repositório em GitHub ou Azure DevOps. O serviço é totalmente compatível com ambos os métodos e a escolha de qual repositório usar depende dos padrões individuais da sua organização. Há dois métodos para configurar um novo repositório ou conectar-se a um repositório existente: usando o portal Azure ou criando da interface do usuário do Azure Data Factory Studio
Criação de uma fábrica no portal do Azure
Quando você cria um novo data factory no portal do Azure, o repositório Git padrão é Azure DevOps. Você também pode selecionar GitHub como seu repositório e definir suas configurações de repositório.
No portal Azure, selecione o tipo de repositório e insira os nomes de repositório e branch para criar uma nova fábrica integrada nativamente ao Git.
Impor o uso do Git com Azure Policy em sua organização
O uso do Git em seus projetos de Azure Data Factory é uma prática recomendada. Mesmo que você não esteja implementando um processo de CI/CD completo, a integração entre o Git e o ADF (Azure Data Factory) permite salvar os artefatos do seu recurso no seu próprio ambiente de área restrita (GIT branch), onde você pode testar suas alterações independentemente dos demais branches de alocadores. Você pode usar o Azure Policy para impor ao uso do Git na fábrica da sua organização.
Azure Data Factory Studio
Depois de criar o data factory, você também pode se conectar ao repositório por meio do Azure Data Factory Studio. Na guia Gerenciar, você verá a opção para configurar seu repositório e definir as configurações do repositório.

Por meio de um processo guiado, você é direcionado ao longo de uma série de etapas que o ajudam a configurar e se conectar facilmente ao repositório de sua escolha. Após seu repositório ter sido totalmente configurado, você pode começar a trabalhar de forma colaborativa e a salvar seus recursos.
Integração contínua e entrega contínua (CI/CD)
CI/CD é um paradigma de desenvolvimento de código no qual as alterações são inspecionadas e testadas à medida que passam por vários estágios: desenvolvimento, teste, preparo etc. Após ser revisado e testado em cada estágio, o código é finalmente publicado em bases de código ao vivo em um ambiente de produção.
CI (Integração Contínua) é a prática de testar e validar automaticamente sempre que um desenvolvedor faz uma alteração na sua base de código. CD (Entrega Contínua) significa que, após os testes da Integração Contínua terem sido bem-sucedidos, as alterações são levadas para o próximo estágio em caráter contínuo.
Conforme discutido brevemente anteriormente, o "código" em Azure Data Factory assume a forma de Azure Resource Manager modelo JSON. Consequentemente, as alterações que passam pelo processo de CI/CD (integração e entrega contínuas) incluem acréscimos, exclusões e edições em blobs JSON.
O pipeline é executado no Azure Data Factory
Antes de falar sobre CI/CD em Azure Data Factory, primeiro precisamos falar sobre como o serviço executa um pipeline. Antes de executar um pipeline, o Data Factory faz o seguinte:
- Extrai a definição publicada mais recente do pipeline e seus respectivos ativos como conjuntos de dados, serviços vinculados etc.
- Compila-o até o nível de ações; se a fábrica de dados tiver executado-o recentemente, ela recupera as ações das compilações armazenadas em cache.
- Executa o pipeline.
A execução do pipeline envolve as seguintes etapas:
- O serviço tira um instantâneo de um ponto no tempo da definição do pipeline.
- As definições não mudam ao longo da duração do pipeline.
- Mesmo que sejam executados por um longo tempo, seus pipelines não serão afetados pelas alterações subsequentes feitas após terem sido iniciados. Se você publicar alterações no serviço vinculado, pipelines etc. durante a execução, as execuções em andamento não serão afetadas.
- Quando você publica alterações, as execuções subsequentes iniciadas após a publicação usarão as definições atualizadas.
Publicando no Azure Data Factory
Independentemente de você estar implantando pipelines com o Pipeline de Lançamento do Azure para automatizar a publicação ou com a implantação manual de modelos do Resource Manager, no back-end a publicação é uma série de operações de criação/atualização em conjuntos de dados, serviços vinculados, pipelines e gatilhos para cada um dos artefatos. O efeito é o mesmo que fazer diretamente as chamadas à API REST subjacentes.
Algumas conclusões resultam das ações nesse ponto:
- Todas essas chamadas à API são síncronas, o que significa que a chamada só retorna quando a publicação é bem-sucedida ou falha. Não haverá um estado de implantação parcial para o artefato.
- As chamadas à API são sequenciais em sua maior parte. Tentamos paralelizar as chamadas, mantendo as dependências referenciais dos artefatos. A ordem das implantações é: serviço vinculado -> runtime do conjunto de dados/integração -> pipeline -> gatilho. Essa ordem garante que os artefatos dependentes possam fazer referência às suas dependências corretamente. Por exemplo, os pipelines dependem de conjuntos de dados e, portanto, o Data Factory os implanta após os conjuntos de dados.
- A implantação de serviços vinculados, conjuntos de dados etc. é independente dos pipelines. Existem situações em que o Data Factory atualiza os serviços vinculados antes de um pipeline ser atualizado. Falaremos sobre essa situação na seção Quando Deter um Gatilho.
- A implantação não irá excluir artefatos das fábricas. Você precisa chamar explicitamente as APIs de exclusão para cada tipo de artefato (pipeline, conjunto de dados, serviço vinculado etc.) para limpar uma fábrica. Consulte o script pós-implantação de exemplo de Azure Data Factory por exemplo.
- Mesmo que você não tenha usado um pipeline, conjunto de dados ou serviço vinculado, o script continuará invocando uma chamada à API de atualização rápida para o data factory.
Gatilhos de publicação
- Os gatilhos apresentam os seguintes estados: iniciados ou detidos.
- Você não pode fazer alterações em um gatilho no modo iniciado. É preciso deter um gatilho antes de publicar quaisquer alterações.
- Você pode invocar a API Criar ou Atualizar Gatilho em um gatilho no modo iniciado.
- Se o conteúdo for alterado, a API irá falhar.
- Se o conteúdo permanecer inalterado, a API terá sucesso.
- Esse comportamento exerce um impacto profundo sobre em que momento deter um gatilho.
Quando deter um gatilho
Quando se trata da implantação em um data factory de produção, com gatilhos ao vivo dando início a execuções de pipeline o tempo todo, a pergunta passa a ser: "Devemos interrompê-los?"
A resposta resumida é que você deve pensar em deter um gatilho somente nas seguintes situações:
- Você precisa deter o gatilho se estiver atualizando definições do gatilho, incluindo campos como data de término, frequência e associação de pipeline.
- É recomendável pausar o gatilho quando você estiver atualizando os datasets ou serviços vinculados referenciados em um pipeline em execução. Por exemplo, se você estiver alternando as credenciais para o SQL Server.
- Você poderá optar por interromper o gatilho se o pipeline associado estiver gerando erros, falhando e sobrecarregando seus servidores.
Confira alguns pontos a serem levados em conta no que diz respeito à interrupção de gatilhos:
- Conforme explicado na seção Pipeline Runs no Azure Data Factory, quando um disparador inicia uma execução de pipeline, ele tira um instantâneo do pipeline, do conjunto de dados, do tempo de execução de integração e das definições de serviço vinculado. Se o pipeline for executado antes de as alterações serem preenchidas no back-end, o gatilho dará início a uma execução com a versão antiga. Na maioria dos casos, isso deve funcionar.
- Conforme explicado na seção Publicação de gatilhos. Um gatilho não pode ser atualizado se estiver em um estado iniciado. Portanto, se você precisar alterar informações sobre a definição do gatilho, detenha o gatilho antes de publicar as alterações.
- Conforme explicado na seção Publicação no Azure Data Factory, modificações nos datasets ou serviços vinculados publicam-se antes das alterações no pipeline. Para garantir que as execuções de pipeline usem as credenciais corretas e se comuniquem com os servidores certos, recomendamos que você interrompa também o respectivo gatilho.
Como preparar alterações de “código”
Recomendamos que você siga essas boas práticas de pull requests.
- Cada desenvolvedor deve trabalhar em seus próprios branches individuais e, no final do dia, criar solicitações de pull para a ramificação principal do repositório. Confira os tutoriais sobre solicitações de pull em GitHub e DevOps.
- Quando os gatekeepers aprovam as solicitações de pull e mesclam as alterações na ramificação principal, o processo de CI/CD pode ser iniciado. Existem dois métodos sugeridos para promover alterações em todos os ambientes: automatizado e manual.
- Quando estiver pronto para iniciar pipelines de CI/CD, você poderá geralmente fazer isso utilizando o Azure Pipeline Release ou implantar pipelines específicos usando este utilitário de código aberto do Azure Player.
Implantação de alterações automatizada
Para ajudar com implantações automatizadas, recomendamos usar o pacote npm de utilitários Azure Data Factory. O uso do pacote npm ajuda a validar todos os recursos em um pipeline e a gerar os modelos do ARM para o usuário.
Para começar a usar o pacote npm de utilitários Azure Data Factory, consulte Automatização da publicação para integração e entrega contínuas.
Implantação manual de alterações
Após ter mesclado seu branch novamente no branch de colaboração principal do seu repositório Git, você poderá publicar suas alterações manualmente no serviço ao vivo do Azure Data Factory. O serviço oferece um controle da interface do usuário sobre a publicação de factories que não sejam de desenvolvimento com a opção Desabilitar publicação (do estúdio do ADF ).
Implantação seletiva
A implantação seletiva depende de um recurso de GitHub e Azure DevOps, conhecido como cherry picking. Esse recurso permite que você implante apenas determinadas alterações, mas não outras. Por exemplo, um desenvolvedor fez alterações em vários pipelines, mas para a implantação de hoje, pode ser que queiramos implantar alterações em apenas um.
Siga os tutoriais de Azure DevOps e GitHub para selecionar as confirmações relevantes para o pipeline de que você precisa. Verifique se todas as alterações, incluindo as alterações relevantes feitas nos gatilhos, dependências e serviços vinculados associados ao pipeline, foram selecionadas por meio do cherry-picking.
Após ter selecionado e mesclado as alterações selecionadas por meio do cherry-picking no pipeline de colaboração principal, você poderá iniciar o processo de CI/CD para as alterações propostas. Informações adicionais sobre como usar o hotfix, o cherry-picking ou estruturas externas para uma implantação seletiva, conforme descrito na seção Testes automatizados deste artigo.
Teste de unidade
Os testes de unidade são uma parte importante do processo de desenvolvimento de novos pipelines ou de edição de artefatos de fábricas de dados existentes, com foco no teste de componentes do código. O Data Factory permite testes de unidade individuais, tanto no nível de pipeline quanto do artefato de fluxo de dados, usando o recurso de depuração de pipelines.

Ao desenvolver fluxos de dados, você será capaz de obter insights sobre cada transformação e alteração de código individuais usando o recurso de pré-visualização de dados para realizar testes de unidade antes de implantar suas alterações na produção.

O serviço fornece um feedback ao vivo e interativo de suas atividades de pipeline na interface do usuário ao fazer a depuração e testes de unidade no Azure Data Factory.
Teste automatizado
Há várias ferramentas disponíveis para testes automatizados que você pode usar com Azure Data Factory. Como o serviço armazena objetos como entidades JSON, pode ser conveniente usar a estrutura de teste de unidade NUnit de .NET de código aberto com o Visual Studio. Consulte esta postagem Configurar testes automatizados para o Azure Data Factory que fornece uma explicação detalhada de como configurar um ambiente de teste unitário automatizado para o seu Azure Data Factory. (Nosso especial obrigado a Richard Swinbank, por nos dar permissão para usar essa postagem de blog.)
Os clientes também podem executar pipelines de TESTE com o PowerShell ou a CLI do AZ como parte do processo de CI/CD para etapas de pré e pós-implantação.
Um ponto forte crucial do Data Factory é sua parametrização de conjuntos de dados. Esse recurso permite que os clientes executem os mesmos pipelines com diferentes conjuntos de dados para se certificar de que o novo desenvolvimento cumpra todos os requisitos de origem e destino.
Outras estruturas de CI/CD para Azure Data Factory
Conforme descrito anteriormente, a integração interna do Git está disponível nativamente por meio da interface do usuário Azure Data Factory, incluindo mesclagem, ramificação, comparação e publicação. No entanto, há outras estruturas de CI/CD úteis que são populares na comunidade Azure, que fornecem mecanismos alternativos para fornecer recursos semelhantes. A metodologia de Git do Azure Data Factory se baseia em modelos do ARM, enquanto estruturas como o ADFTools de Kamil Nowinski adotam uma abordagem diferente ao confiar, em vez disso, em artefatos JSON individuais do seu data factory. Os engenheiros de dados que são experientes em Azure DevOps e preferem trabalhar nesse ambiente (em oposição à abordagem de interface do usuário baseada em ARM que o serviço oferece prontamente) podem achar que essa estrutura funciona bem para eles e para cenários comuns, como implantações parciais. Essa estrutura também pode simplificar a forma de lidar com gatilhos ao implantar em ambientes com estados de gatilhos em execução.
Governança de dados no Azure Data Factory
Um aspecto importante de um DataOps eficaz é a governança de dados. Para ferramentas de ETL de integração de dados, o fornecimento de linhagem de dados e relações entre artefatos pode fornecer informações importantes para um engenheiro de dados entender o impacto das alterações downstream. O Data Factory fornece exibições integradas de artefatos relacionados que constituem a implementação da sua fábrica.
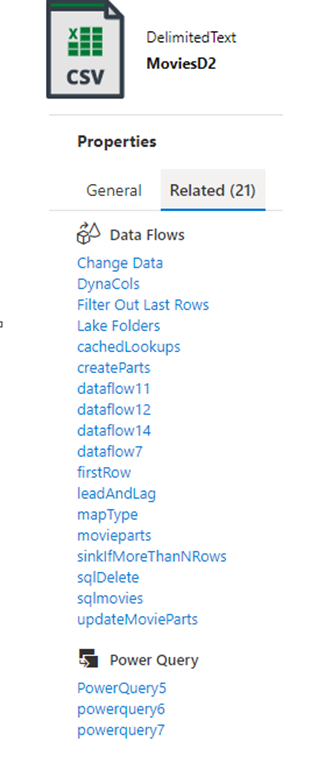
A integração nativa com Microsoft Purview fornece linhagem, análise de impacto e catalogação de dados.
Microsoft Purview fornece uma solução unificada de governança de dados para ajudar a gerenciar e governar seus dados locais, multinuvem e saaS (software como serviço). Isso permite que você crie com facilidade um mapa holístico e atualizado do seu panorama de dados com descoberta automatizada de dados, classificação de dados confidenciais e linhagem de dados de ponta a ponta. Esses recursos permitem que os consumidores de dados acessem um gerenciamento de dados valioso e confiável.

Com a integração nativa ao seu Data Catalog do Purview, o Data Factory permite a fácil pesquisa e descoberta de ativos de dados para serem usados em pipelines de integração de dados em todo o patrimônio de dados da sua organização.

Você pode usar a barra de pesquisa principal do Azure Data Factory Studio para encontrar ativos de dados em seu catálogo do Purview.
