Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis em os pipelines do Azure Data Factory e os pipelines do Azure Synapse Analytics. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Dica
Para a transformação equivalente (Escolher colunas) no Dataflow Gen2, consulte um guia para o Dataflow Gen2 para mapear usuários de fluxo de dados.
Use a transformação Select para renomear, descartar ou reordenar colunas. Essa transformação não altera os dados de linha, mas escolhe quais colunas serão propagadas downstream.
Em uma transformação Select, os usuários podem especificar mapeamentos fixos, usar padrões para fazer o mapeamento baseado em regras ou ativar o mapeamento automático. Tanto os mapeamentos fixos como os baseados em regras podem ser usados na mesma transformação Select. As colunas que não corresponderem aos mapeamentos definidos serão descartadas.
Mapeamento fixo
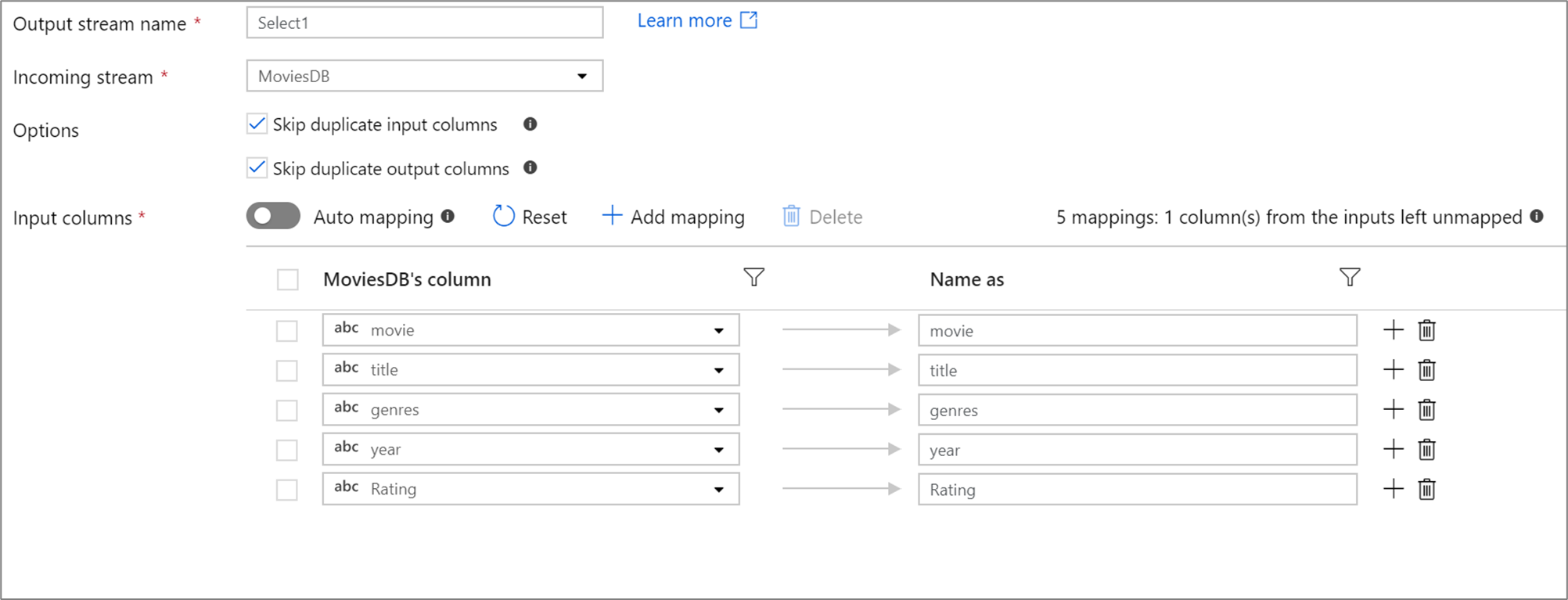
Se houver menos de 50 colunas definidas na sua projeção, todas elas terão um mapeamento fixo por padrão. O mapeamento fixo usa uma coluna de entrada definida e a mapeia com um nome exato.
Observação
Não é possível usar um mapeamento fixo para mapear ou renomear uma coluna descompassada
Mapeando colunas hierárquicas
Os mapeamentos fixos podem ser usados para mapear uma subcoluna de uma coluna hierárquica para uma coluna de nível superior. Se você tiver uma hierarquia definida, use a lista suspensa da coluna para selecionar uma subcoluna. A transformação Select criará uma nova coluna com o valor e o tipo de dados da subcoluna.
mapeamento baseado em regras
Se você quiser mapear muitas colunas de uma só vez ou mover colunas descompassadas downstream, utilize o mapeamento baseado em regras para definir os mapeamentos usando padrões de coluna. Faça a correspondência com base nas colunas name, type, stream e position. É possível fazer qualquer combinação de mapeamentos fixos e baseados em regras. Por padrão, todas as projeções com mais de 50 colunas são definidas como um mapeamento baseado em regra que corresponde a cada coluna e gera o nome inserido.
Para adicionar um mapeamento baseado em regras, clique em Adicionar mapeamento e selecione Mapeamento baseado em regras.

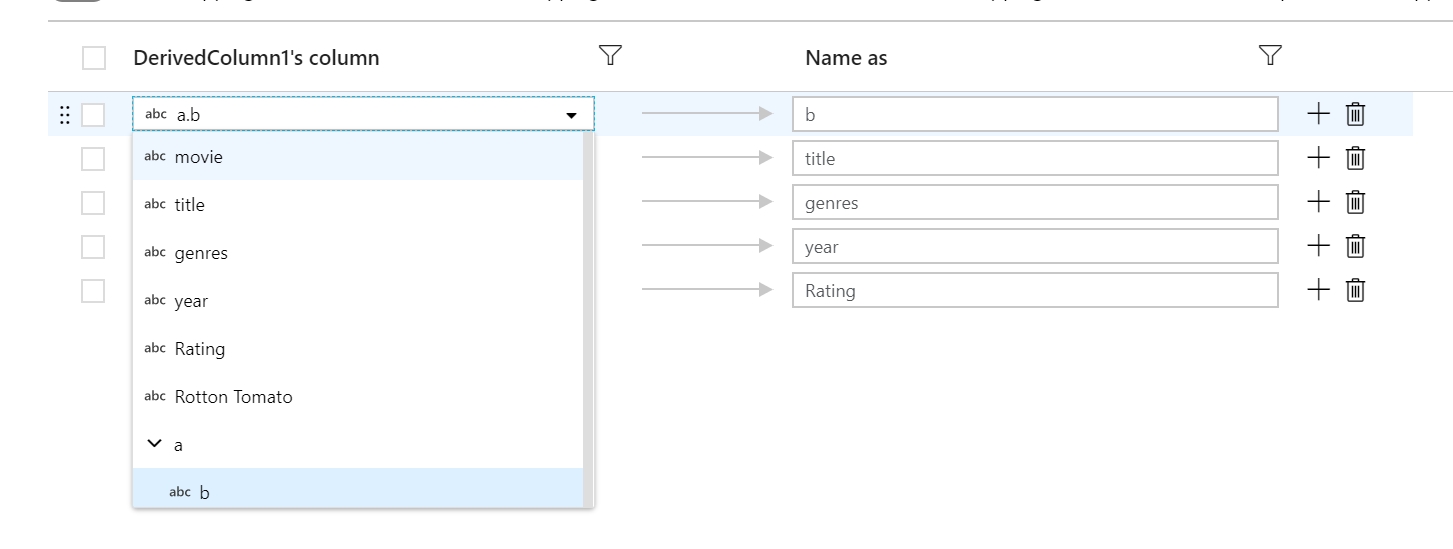
Cada mapeamento baseado em regras requer duas entradas: a condição que serve de base para a correspondência e o nome de cada coluna mapeada. Os dois valores são inseridos por meio do construtor de expressões. Insira a condição de correspondência booliana na caixa de expressões à esquerda. Na caixa de expressões à direita, especifique o destino do mapeamento da coluna de correspondência.

Use a sintaxe $$ para fazer referência ao nome de entrada de uma coluna de correspondência. Adotando a imagem acima como exemplo, digamos que um usuário queira fazer a correspondência de todas as colunas de cadeia de caracteres cujos nomes tenham menos de seis caracteres. Se uma coluna de entrada tiver sido nomeada como test, a expressão $$ + '_short' renomeará a coluna para test_short. Se esse for o único mapeamento existente, todas as colunas que não atenderem à condição serão descartadas dos dados gerados.
Os padrões correspondem a colunas tanto desviadas como definidas. Para ver quais colunas definidas são mapeadas por uma regra, clique no ícone de óculos ao lado da regra. Verifique o output usando a visualização de dados.
Mapeamento regex
Se você clicar no ícone de divisa descendente, poderá especificar uma condição de mapeamento regex. Uma condição de mapeamento usando regex corresponde a todos os nomes de coluna que atendem à condição regex especificada. Isso pode ser usado em combinação com mapeamentos padrão baseados em regras.

O exemplo acima corresponde ao padrão regex (r) ou a qualquer nome de coluna que contenha uma letra r em minúscula. Assim como no mapeamento padrão baseado em regras, todas as colunas de correspondência são alteradas pela condição à direita por meio da sintaxe $$.
Se você tiver várias correspondências regex no nome de coluna, faça referência a correspondências específicas usando $n, em que 'n' se refere a qual correspondência. Por exemplo, '$2' é relativo à segunda correspondência em um nome de coluna.
Hierarquias baseadas em regras
Se a projeção definida tiver uma hierarquia, use o mapeamento baseado em regras para mapear as subcolunas de hierarquias. Especifique uma condição de correspondência e a coluna complexa cujas subcolunas você deseja mapear. Todas as subcolunas de correspondência serão geradas com a regra 'Nome como' especificada à direita.
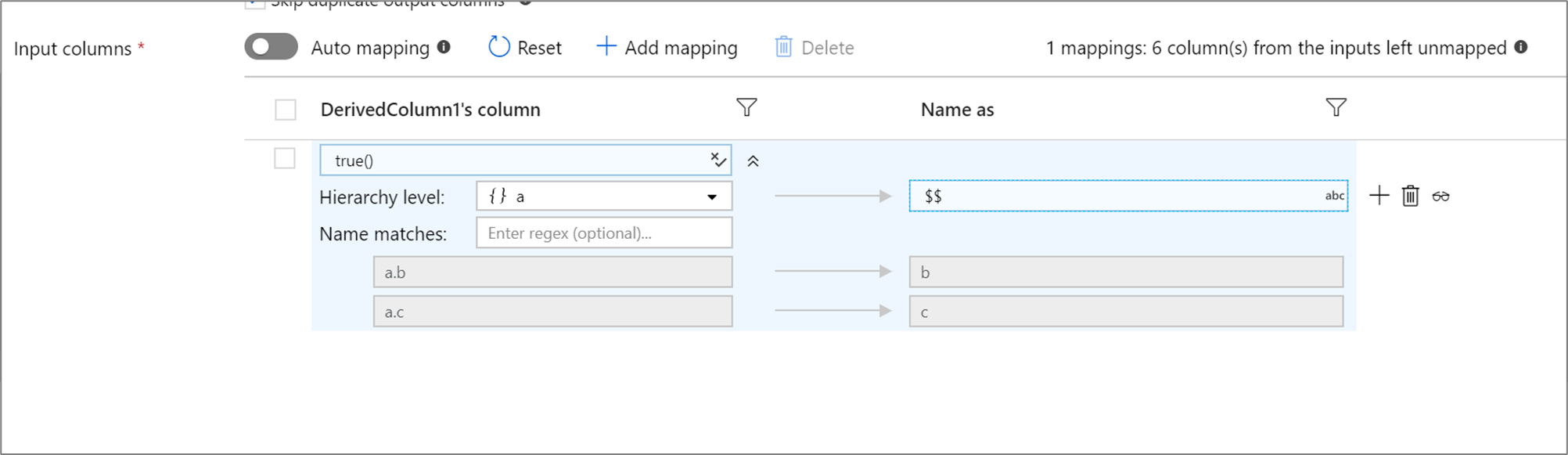
O exemplo acima corresponde a todas as subcolunas da coluna complexa a.
a contém duas subcolunas b e c. O esquema de saída incluirá duas colunas b e c, já que a condição 'Nome como' é $$.
Parametrização
É possível parametrizar nomes de coluna por meio do mapeamento baseado em regras. Use a palavra-chave name para fazer a correspondência entre nomes de coluna de entrada e um parâmetro. Por exemplo, se você tiver um parâmetro de fluxo de dados mycolumn, poderá criar uma regra que faça a correspondência de qualquer nome de coluna igual a mycolumn. Também é possível renomear a coluna de correspondência para uma cadeia de caracteres embutida em código, como 'chave de negócios', e fazer referência a ela explicitamente. Neste exemplo, a condição de correspondência é name == $mycolumn e a condição de nome é 'chave de negócios'.
Mapeamento automático
Quando uma transformação Select é adicionada, o mapeamento automático pode ser ativado com a alternância do respectivo controle deslizante. Com o mapeamento automático, a transformação Select mapeia todas as colunas de entrada, excluindo duplicatas, com o mesmo nome da entrada. Isso inclui colunas em descompasso, o que significa que os dados de saída podem conter colunas não definidas no esquema. Para obter mais informações sobre colunas em descompasso, veja descompasso de esquema.
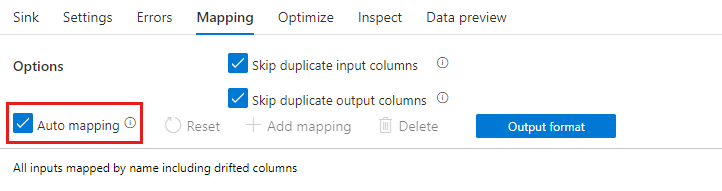
Com o mapeamento automático ativado, a transformação Select respeita as configurações para ignorar duplicadas e fornece um novo alias para as colunas existentes. A criação de alias é útil para fazer várias junções ou pesquisas no mesmo fluxo e em cenários de autojunção.
Colunas duplicadas
Por padrão, a transformação Select descarta colunas duplicadas na projeção de entrada e de saída. As colunas de entrada duplicadas geralmente são provenientes de transformações de junção e pesquisa em que há nomes de coluna duplicados em cada lado da junção. Podem ocorrer colunas de saída duplicadas quando você mapeia duas colunas de entrada diferentes com o mesmo nome. Decida se as colunas duplicadas serão descartadas ou aprovadas alternando a caixa de seleção.
Ordenação de colunas
A ordem dos mapeamentos determina a ordem das colunas de saída. Se uma coluna de entrada for mapeada várias vezes, somente o primeiro mapeamento será respeitado. A primeira correspondência será mantida para qualquer descarte de coluna duplicada.
Script de fluxo de dados
Sintaxe
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Exemplo
Veja a seguir um exemplo de mapeamento Select e o respectivo script de fluxo de dados:
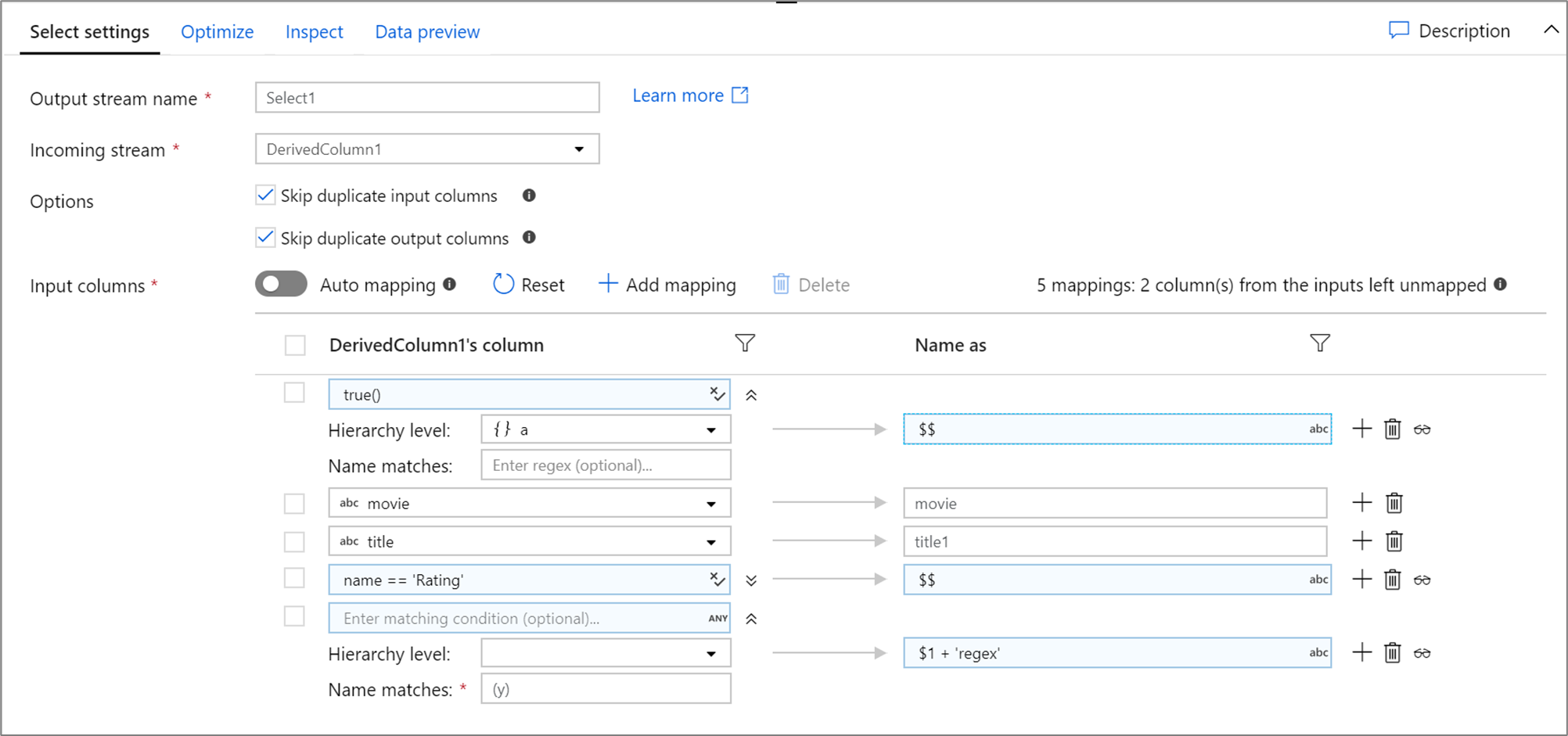
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Conteúdo relacionado
- Depois que Select for aplicado para renomear, reordenar e criar alias de colunas, use a transformação Sink para colocar os dados em um armazenamento de dados.