Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste artigo, você aprenderá a configurar o Gateway do Mosaic AI em um ponto de extremidade do Serviço de Modelo.
Requisitos
- Um workspace do Databricks em uma região em que há suporte para o serviço de modelo. Consulte Disponibilidade regional do serviço de modelo.
- Um ponto de extremidade do Serviço de Modelo. Você pode usar um dos pontos de extremidade pré-configurados de pagamento por token em seu workspace ou fazer o seguinte:
- Para criar um ponto de extremidade para modelos externos, conclua as etapas 1 e 2 de Criar um ponto de extremidade do Serviço de Modelo.
- Para criar um ponto de extremidade para a taxa de transferência provisionada, consulte APIs de Modelos de Base com taxa de transferência provisionada.
- Para criar um ponto de extremidade para um modelo personalizado, consulte Criar um ponto de extremidade.
Configurar o Gateway de IA usando a interface do usuário
Na seção IA Gateway da página de criação do endpoint, você pode configurar individualmente os recursos do IA Gateway. Consulte Recursos com suporte para saber quais recursos estão disponíveis em pontos de extremidade externos do serviço de modelo e pontos de extremidade com taxa de transferência provisionada.
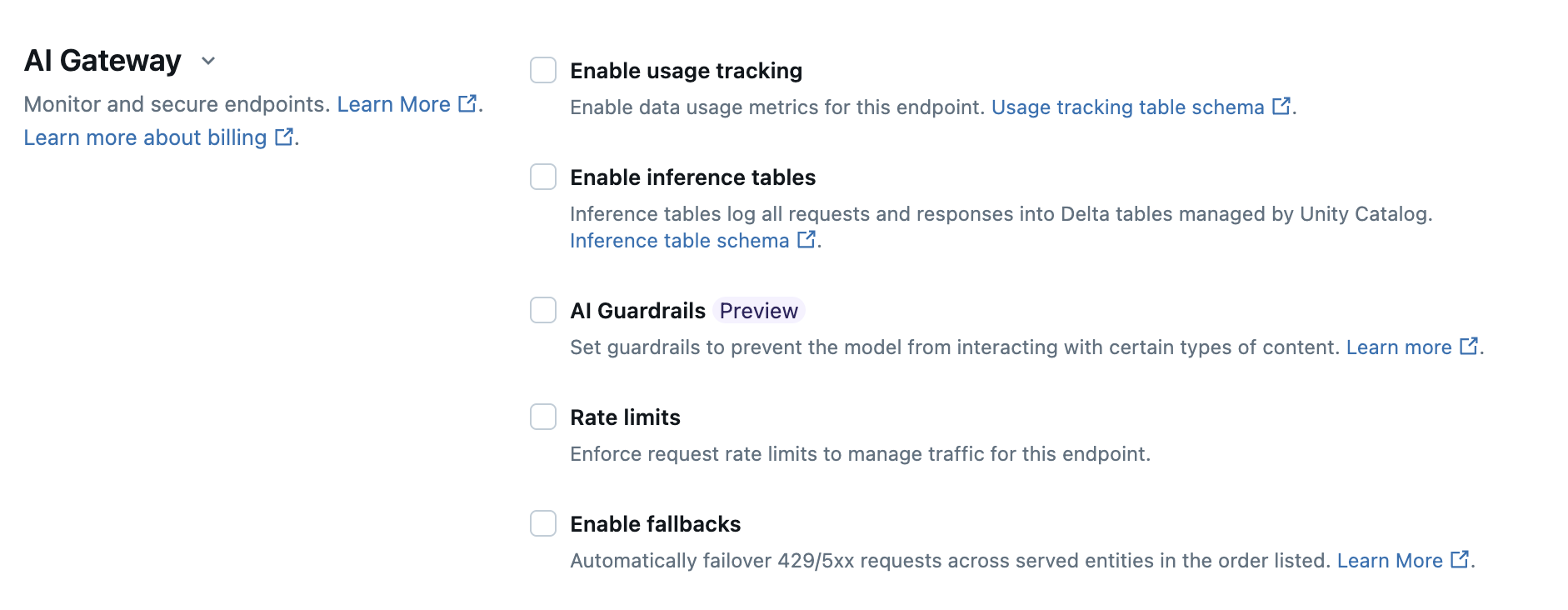
A tabela a seguir resume como configurar o Gateway de IA durante a criação do ponto de extremidade usando a interface do usuário do Serviço. Se você preferir fazer isso programaticamente, consulte o exemplo do Notebook.
| Recurso | Como habilitar | Detalhes |
|---|---|---|
| Acompanhamento de uso | Selecione Habilitar acompanhamento de uso para habilitar o acompanhamento e o monitoramento de métricas de uso de dados. Esse recurso é habilitado por padrão para pontos de extremidade de pagamento por token. |
|
| Registro em log do conteúdo | Selecione Habilitar tabelas de inferência para registrar automaticamente solicitações e respostas do seu endpoint em tabelas Delta gerenciadas pelo Catálogo da Unity. |
|
| Guardas de IA | Consulte Configurar AI Guardrails na interface do usuário. |
|
| Limites de taxa | Selecione Limites de taxa para gerenciar o tráfego do ponto de extremidade e especifique o número de solicitações por minuto que seu ponto de extremidade pode receber.
|
Por exemplo
|
| Separação de tráfego | Na seção Entidades atendidas, especifique o percentual de tráfego que você deseja rotear para modelos específicos. Para configurar a divisão de tráfego em seu ponto de extremidade programaticamente, consulte Servir vários modelos externos para um ponto de extremidade. |
|
| Soluções Alternativas | Selecione Habilitar alternativas na seção do Gateway de IA para enviar sua solicitação para outros modelos atendidos no endpoint como um recurso de reserva. |
|
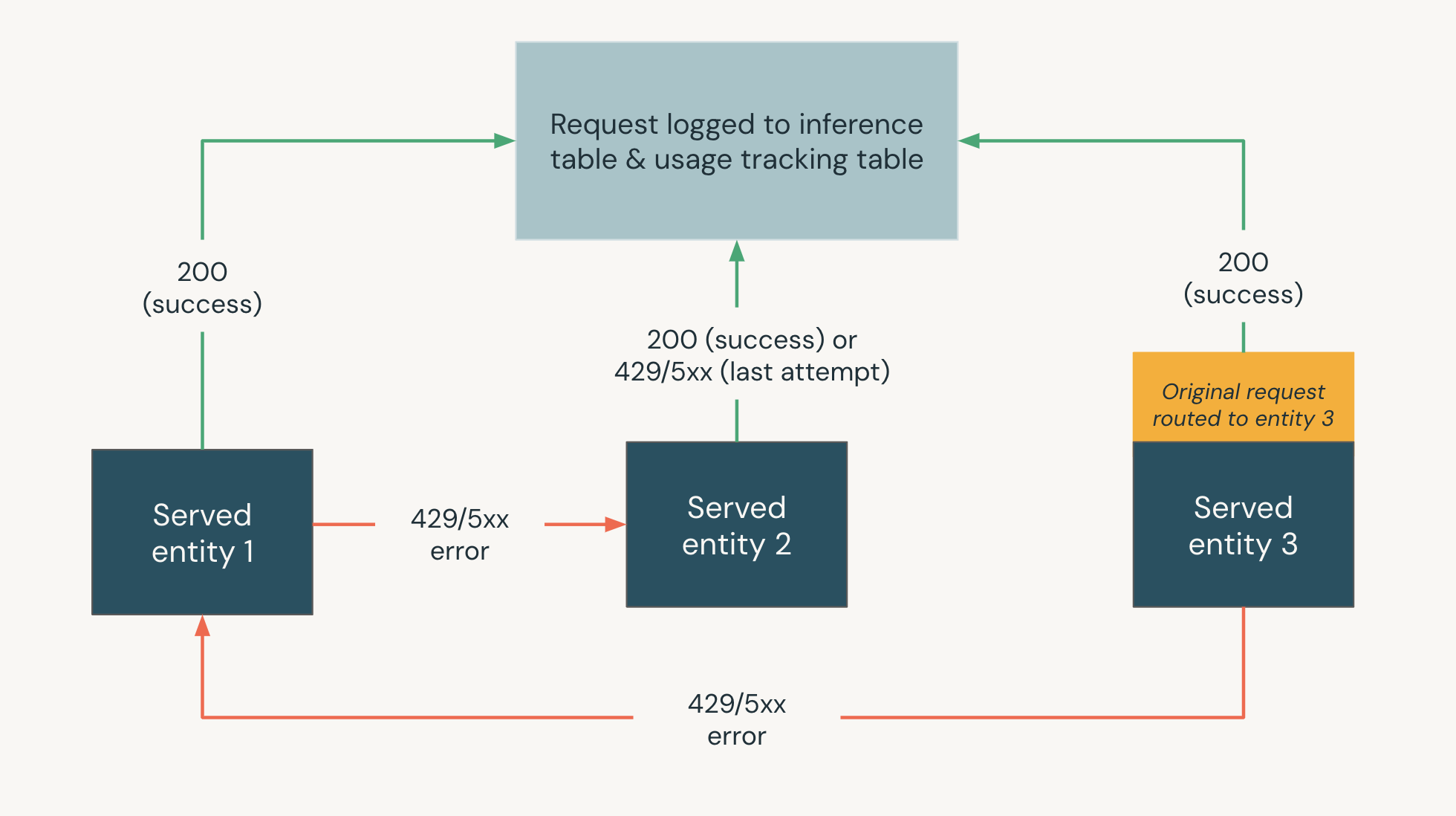
O diagrama a seguir mostra um exemplo de soluções alternativas em que,
- Três entidades são atendidas em um ponto de extremidade do Serviço de Modelo.
- A solicitação é roteada originalmente para a entidade 3 atendida.
- Se a solicitação retornar uma resposta 200, a solicitação foi bem-sucedida na Entidade atendida 3 e a solicitação e sua resposta serão registradas nas tabelas de acompanhamento de uso e registro em log do conteúdo do ponto de extremidade.
- Se a solicitação retornar um erro 429 ou 5xx na entidade Served 3, a solicitação retornará à próxima entidade atendida no ponto de extremidade, entidade atendida 1.
- Se a solicitação retornar um erro 429 ou 5xx na entidade Served 1, a solicitação retornará à próxima entidade atendida no ponto de extremidade, entidade atendida 2.
- Se a solicitação retornar um erro de 429 ou 5xx na entidade 2 atendida, a solicitação falhará, pois esse é o número máximo de entidades de fall back. A solicitação com falha e o erro de resposta são registrados nas tabelas de registro em log do conteúdo e acompanhamento de uso.
Configurar AI Guardrails na interface do usuário
Importante
Esse recurso está em Visualização Pública.
A tabela a seguir mostra como configurar limites de segurança com suporte.
Observação
Após 30 de maio de 2025, deixará de haver suporte para os guardrails de IA que moderam tópicos e filtram palavras-chave. Se esses recursos forem necessários para seus fluxos de trabalho, entre em contato com sua equipe de conta do Databricks para participar da versão prévia privada de guardrails personalizados.
| Barreira de proteção | Como habilitar |
|---|---|
| Segurança | Selecione Segurança para habilitar proteções para impedir que seu modelo interaja com conteúdo inseguro e prejudicial. |
| Detecção de PIIs (informações de identificação pessoal) | Selecione Bloquear ou Mascarar dados PII, como nomes, endereços, e números de cartão de crédito, se essas informações forem detectadas em solicitações e respostas de comunicação de terminal. Caso contrário, selecione Nenhum para que nenhuma detecção de PII ocorra. |

Esquemas de tabelas de acompanhamento de uso
As seções a seguir resumem os esquemas de tabela de acompanhamento de uso para as tabelas de sistema system.serving.served_entities e system.serving.endpoint_usage.
system.serving.served_entities esquema de tabela de acompanhamento de uso
Observação
Atualmente, não há suporte para a tabela do sistema de acompanhamento de uso system.serving.served_entities para pontos de extremidade de pagamento por token.
A tabela do sistema de acompanhamento de uso system.serving.served_entities tem o seguinte esquema:
| Nome da coluna | Descrição | Tipo |
|---|---|---|
served_entity_id |
A ID exclusiva da entidade atendida. | CADEIA DE CARACTERES |
account_id |
O ID da conta do cliente do Delta Sharing. | CADEIA DE CARACTERES |
workspace_id |
O ID do espaço de trabalho do cliente do ponto de extremidade do serviço. | CADEIA DE CARACTERES |
created_by |
A ID do criador. | CADEIA DE CARACTERES |
endpoint_name |
O nome do ponto de extremidade do serviço. | CADEIA DE CARACTERES |
endpoint_id |
O ID exclusivo do ponto de extremidade do serviço. | CADEIA DE CARACTERES |
served_entity_name |
O nome da entidade atendida. | CADEIA DE CARACTERES |
entity_type |
Tipo da entidade que é atendida. Pode ser FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL ou CUSTOM_MODEL |
CADEIA DE CARACTERES |
entity_name |
O nome subjacente da entidade. Diferente do served_entity_name, que é um nome fornecido pelo usuário. Por exemplo, entity_name é o nome do modelo do Catálogo do Unity. |
CADEIA DE CARACTERES |
entity_version |
A versão da entidade atendida. | CADEIA DE CARACTERES |
endpoint_config_version |
A versão da configuração do ponto de extremidade. | INT |
task |
O tipo da tarefa. Pode ser llm/v1/chat, llm/v1/completions ou llm/v1/embeddings. |
CADEIA DE CARACTERES |
external_model_config |
Configurações para modelos externos. Por exemplo, {Provider: OpenAI} |
ESTRUTURA |
foundation_model_config |
Configurações para modelos base. Por exemplo, {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
ESTRUTURA |
custom_model_config |
Configurações para modelos personalizados. Por exemplo, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
ESTRUTURA |
feature_spec_config |
Configurações para especificações de funcionalidades. Por exemplo, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
ESTRUTURA |
change_time |
Carimbo de data/hora da alteração da entidade atendida. | TIMESTAMP |
endpoint_delete_time |
Carimbo de data/hora da exclusão da entidade. O endpoint é o contêiner da entidade atendida. Depois que o ponto de extremidade é excluído, a entidade atendida também é excluída. | TIMESTAMP |
system.serving.endpoint_usage esquema de tabela de acompanhamento de uso
A tabela do sistema de acompanhamento de uso system.serving.endpoint_usage tem o seguinte esquema:
| Nome da coluna | Descrição | Tipo |
|---|---|---|
account_id |
A ID da conta do cliente. | CADEIA DE CARACTERES |
workspace_id |
O ID do espaço de trabalho do cliente do ponto de extremidade do serviço. | CADEIA DE CARACTERES |
client_request_id |
O identificador de solicitação fornecido pelo usuário que pode ser especificado no corpo da solicitação de serviço de modelo. Não há suporte para solicitações maiores que 4MiB. | CADEIA DE CARACTERES |
databricks_request_id |
Um identificador de solicitação gerado pelo Azure Databricks anexado a todas as solicitações de serviço de modelo. | CADEIA DE CARACTERES |
requester |
O ID do usuário ou entidade de serviço cujas permissões são usadas para a solicitação de invocação do ponto de extremidade do serviço. | CADEIA DE CARACTERES |
status_code |
O código de status HTTP que foi retornado do modelo. | INTEGER |
request_time |
O carimbo de data/hora no qual a solicitação é recebida. | TIMESTAMP |
input_token_count |
A contagem de tokens da entrada. | LONG |
output_token_count |
A contagem de tokens da saída. | LONG |
input_character_count |
A contagem de caracteres da cadeia de entrada ou prompt. | LONG |
output_character_count |
A quantidade de caracteres da sequência de saída da resposta. | LONG |
usage_context |
O mapa fornecido pelo usuário que contém identificadores do usuário final ou do aplicativo cliente que faz a chamada para o ponto de extremidade. Consulte Mais informações sobre como definir o uso com usage_context. Não há suporte para solicitações maiores que 4MiB. |
Mapa |
request_streaming |
Se a solicitação está no modo de fluxo. | BOOLEANO |
served_entity_id |
A ID exclusiva usada para ingressar na tabela de dimensões system.serving.served_entities para pesquisar informações sobre o ponto de extremidade e a entidade atendida. |
CADEIA DE CARACTERES |
Definir melhor o uso com usage_context
Ao consultar um modelo externo com o rastreamento de uso habilitado, você pode fornecer o parâmetro usage_context com o tipo Map[String, String]. O mapeamento de contexto de uso aparece na tabela de acompanhamento de uso na coluna usage_context. O tamanho do usage_context mapa não pode exceder 10 KiB.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Se você estiver usando o cliente OpenAI Python, pode especificar usage_context incluindo-o no parâmetro extra_body.
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet",
messages=[{"role": "user", "content": "What is Databricks?"}],
temperature=0,
extra_body={"usage_context": {"project": "project1"}},
)
answer = response.choices[0].message.content
print("Answer:", answer)
Os administradores de conta podem agregar diferentes linhas com base no contexto de uso para obter insights e podem unir essas informações com as da tabela de registro de carga. Por exemplo, você pode adicionar end_user_to_charge ao usage_context para acompanhar a atribuição de custos para usuários finais.
Monitorar o uso do ponto de extremidade
Para monitorar o uso do ponto de extremidade, você pode unir as tabelas do sistema e as tabelas de inferência para o ponto de extremidade.
Unir tabelas do sistema
Este exemplo só se aplica a pontos de extremidade de taxa de transferência provisionados e modelo externos. A tabela do sistema served_entities não tem suporte para os pontos de extremidade de pagamento por token, mas você pode unir as tabelas de inferência e uso para obter detalhes semelhantes.
Para unir as tabelas do sistema endpoint_usage e served_entities, use o seguinte comando SQL:
SELECT * FROM system.serving.endpoint_usage as eu
JOIN system.serving.served_entities as se
ON eu.served_entity_id = se.served_entity_id
WHERE created_by = "\<user_email\>";
Unir tabelas de inferência e uso
O seguinte une a tabela do sistema endpoint_usage e a tabela de inferência de um ponto de extremidade de pagamento por token. As tabelas de inferência e o acompanhamento de uso devem ser habilitados no endpoint para que essas tabelas sejam unidas.
SELECT * FROM system.serving.endpoint_usage AS endpoint_usage
JOIN
(SELECT DISTINCT(served_entity_id) AS fmapi_served_entity_id
FROM <inference table name>) fmapi_id
ON fmapi_id.fmapi_served_entity_id = endpoint_usage.served_entity_id;
Atualizar recursos do Gateway de IA em pontos de extremidade
Você pode atualizar os recursos do Gateway de IA em pontos de extremidade do serviço de modelo que já estavam habilitados anteriormente e em pontos de extremidade que não estavam. As atualizações nas configurações do AI Gateway levam cerca de 20 a 40 segundos para serem aplicadas, mas as atualizações de limitação de taxa podem levar até 60 segundos.
Veja a seguir como atualizar os recursos do Gateway de IA em um ponto de extremidade do Serviço de Modelo usando a interface do usuário de serviço.
Na seção Gateway da página do ponto de extremidade, você pode ver quais recursos estão habilitados. Para atualizar esses recursos, clique em Editar AI Gateway.

Exemplo de notebook
O notebook a seguir mostra como habilitar e usar programaticamente os recursos do Databricks Mosaic AI Gateway para gerenciar e governar modelos dos provedores. Consulte put /api/2.0/serving-endpoints/{name}/ai-gateway para obter detalhes da API REST.