Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Você pode iniciar a carga de trabalho distribuída em várias GPUs, dentro de um único nó ou em vários nós, usando a API Python de GPU sem servidor. A API fornece uma interface simples e unificada que abstrai os detalhes do provisionamento de GPU, da configuração do ambiente e da distribuição da carga de trabalho. Com alterações mínimas de código, você pode mover perfeitamente do treinamento de GPU única para a execução distribuída entre GPUs remotas do mesmo notebook.
Início rápido
A API de GPU sem servidor para treinamento distribuído é pré-instalada em ambientes de computação de GPU sem servidor para notebooks do Databricks. Recomendamos o ambiente de GPU 4 e superior. Para usá-lo para treinamento distribuído, importe e use o decorador distributed para distribuir sua função de treinamento.
O snippet de código abaixo mostra o uso básico de @distributed:
# Import the distributed decorator
from serverless_gpu import distributed
# Decorate your training function with @distributed and specify the number of GPUs, the GPU type,
# and whether or not the GPUs are remote
@distributed(gpus=8, gpu_type='A10', remote=True)
def run_train():
...
Veja abaixo um exemplo completo que treina um modelo MLP (perceptron de várias camadas) em 8 nós de GPU A10 de um notebook:
Configure seu modelo e defina funções utilitárias.
# Define the model import os import torch import torch.distributed as dist import torch.nn as nn def setup(): dist.init_process_group("nccl") torch.cuda.set_device(int(os.environ["LOCAL_RANK"])) def cleanup(): dist.destroy_process_group() class SimpleMLP(nn.Module): def __init__(self, input_dim=10, hidden_dim=64, output_dim=1): super().__init__() self.net = nn.Sequential( nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, output_dim) ) def forward(self, x): return self.net(x)Importe a biblioteca serverless_gpu e o módulo distribuído .
import serverless_gpu from serverless_gpu import distributedColoque o código de treinamento do modelo em uma função e decore a função com o decorador
@distributed.@distributed(gpus=8, gpu_type='A10', remote=True) def run_train(num_epochs: int, batch_size: int) -> None: import mlflow import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data import DataLoader, DistributedSampler, TensorDataset # 1. Set up multi node environment setup() device = torch.device(f"cuda:{int(os.environ['LOCAL_RANK'])}") # 2. Apply the Torch distributed data parallel (DDP) library for data-parellel training. model = SimpleMLP().to(device) model = DDP(model, device_ids=[device]) # 3. Create and load dataset. x = torch.randn(5000, 10) y = torch.randn(5000, 1) dataset = TensorDataset(x, y) sampler = DistributedSampler(dataset) dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size) # 4. Define the training loop. optimizer = optim.Adam(model.parameters(), lr=0.001) loss_fn = nn.MSELoss() for epoch in range(num_epochs): sampler.set_epoch(epoch) model.train() total_loss = 0.0 for step, (xb, yb) in enumerate(dataloader): xb, yb = xb.to(device), yb.to(device) optimizer.zero_grad() loss = loss_fn(model(xb), yb) # Log loss to MLflow metric mlflow.log_metric("loss", loss.item(), step=step) loss.backward() optimizer.step() total_loss += loss.item() * xb.size(0) mlflow.log_metric("total_loss", total_loss) print(f"Total loss for epoch {epoch}: {total_loss}") cleanup()Execute o treinamento distribuído chamando a função distribuída com argumentos definidos pelo usuário.
run_train.distributed(num_epochs=3, batch_size=1)Quando executado, um link de execução do MLflow é gerado na saída da célula do notebook. Clique no link de execução do MLflow ou localize-o no painel Experimento para ver os resultados da execução.
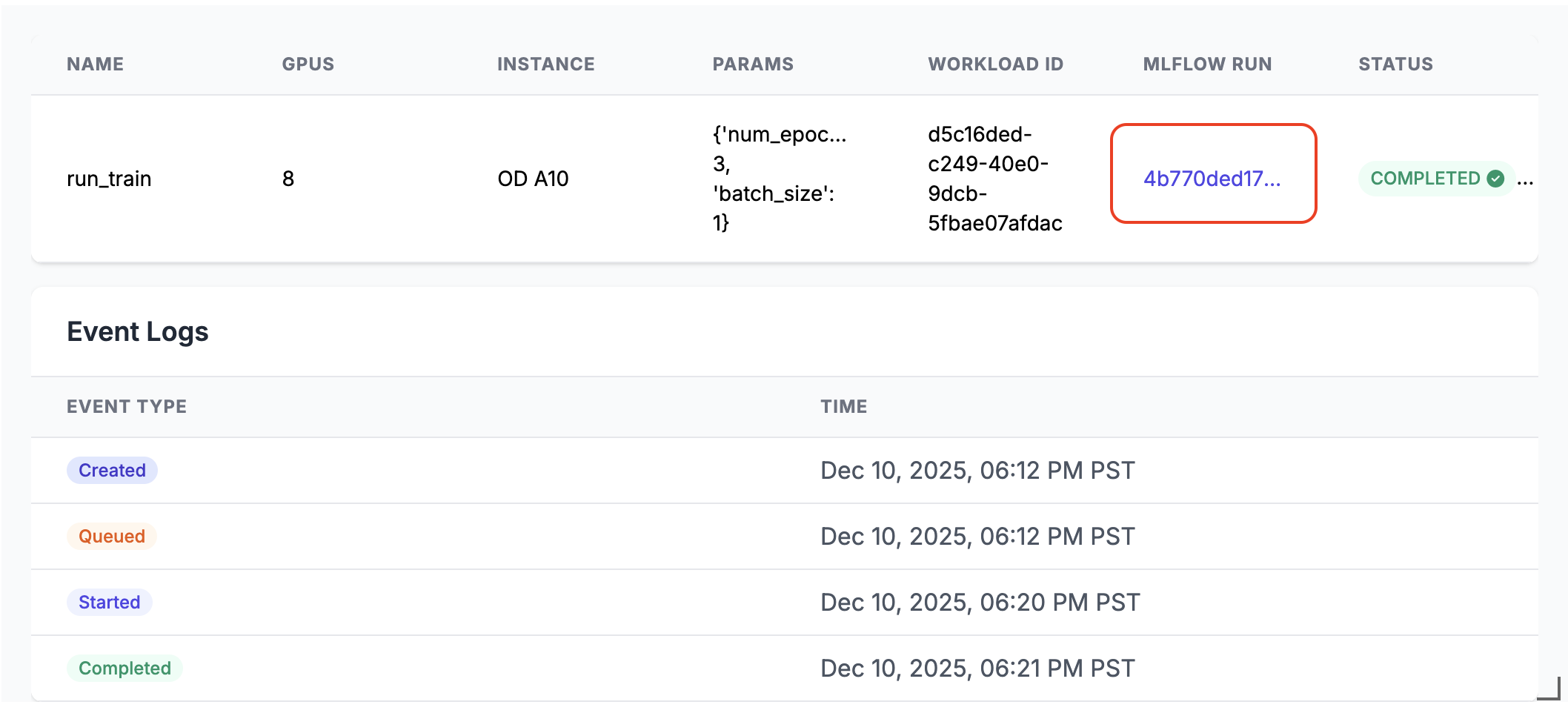
Detalhes da execução distribuída
A API de GPU sem servidor consiste em vários componentes principais:
- Gerenciador de computação: manipula a alocação e o gerenciamento de recursos
- Ambiente de runtime: gerencia ambientes e dependências do Python
- Inicializador: Orquestra a execução e o monitoramento da tarefa
Ao executar no modo distribuído:
- A função é serializada e distribuída entre o número especificado de GPUs
- Cada GPU executa uma cópia da função com os mesmos parâmetros
- O ambiente é sincronizado em todos os nós
- Os resultados são coletados e retornados de todas as GPUs
Se remote estiver definido como True, a carga de trabalho será distribuída nas GPUs remotas. Se remote estiver definido como False, a carga de trabalho será executada no único nó de GPU conectado ao notebook atual. Se o nó tiver vários chips de GPU, todos eles serão utilizados.
A API dá suporte a bibliotecas de treinamento paralelas populares, como DDP ( Distributed Data Parallel ), FSDP ( Fully Sharded Data Parallel ), DeepSpeed e Ray.
Você pode encontrar cenários de treinamento distribuídos mais reais usando as várias bibliotecas em exemplos de notebook.
Iniciar com o Ray
A API de GPU sem servidor também dá suporte ao lançamento de treinamento distribuído com o Ray através do decorador @ray_launch, que é sobreposto ao @distributed.
Cada tarefa ray_launch primeiro inicializa um encontro distribuído usando o PyTorch para determinar o trabalhador principal do Ray e coletar os IPs. O rank-zero inicia ray start --head (com a exportação de métricas, se habilitada), define RAY_ADDRESS e executa sua função decorada como o Ray driver. Outros nós conectam-se via ray start --address e esperam até que o driver grave um marcador final.
Detalhes adicionais de configuração:
- Para habilitar a coleção de métricas do sistema Ray em cada nó, use
RayMetricsMonitorcomremote=True. - Defina as opções de runtime do Ray (atores, conjuntos de dados, grupos de posicionamento e agendamento) dentro de sua função decorada usando APIs Ray padrão.
- Gerencie controles em todo o cluster (contagem e tipo de GPU, modo remoto versus local, comportamento assíncrono e variáveis de ambiente do pool do Databricks) fora da função nos argumentos do decorador ou no ambiente do notebook.
O exemplo a seguir mostra como usar @ray_launch:
from serverless_gpu.ray import ray_launch
@ray_launch(gpus=16, remote=True, gpu_type='A10')
def foo():
import os
import ray
print(ray.state.available_resources_per_node())
return 1
foo.distributed()
Para obter um exemplo completo, consulte este notebook, que usa o Ray para treinar uma rede neural Resnet18 em várias GPUs A10.
Você também pode usar essa API para chamar o Ray Data, uma biblioteca de processamento de dados escalonável para cargas de trabalho de IA, para executar a inferência em lote distribuído em LLMs. Veja exemplos de vllm e glang .
FAQs
Onde o código de carregamento de dados deve ser colocado?
Ao usar a API de GPU sem servidor para treinamento distribuído, mova o código de carregamento de dados no decorador @distributed. O tamanho do conjunto de dados pode exceder o tamanho máximo permitido pelo pickle, assim, é recomendável gerar o conjunto de dados dentro do decorador, conforme mostrado abaixo:
from serverless_gpu import distributed
# this may cause pickle error
dataset = get_dataset(file_path)
@distributed(gpus=8, remote=True)
def run_train():
# good practice
dataset = get_dataset(file_path)
....
Posso usar pools de GPU reservados?
Se houver um pool de GPU reservado disponível no seu workspace (verifique com seu administrador) e você especificar remote para True no decorador @distributed, a carga de trabalho será iniciada nesse pool de GPU reservado por padrão. Se você quiser usar o pool de GPU sob demanda, defina a variável DATABRICKS_USE_RESERVED_GPU_POOL de ambiente para False antes de chamar a função distribuída, conforme mostrado abaixo:
import os
os.environ['DATABRICKS_USE_RESERVED_GPU_POOL'] = 'False'
@distributed(gpus=8, remote=True)
def run_train():
...
Saiba Mais
Para a referência de API, consulte a documentação da API Python de GPU sem servidor .