Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A CDC (captura de dados de alteração) é um padrão de integração de dados que captura alterações feitas em dados em um sistema de origem, como inserções, atualizações e exclusões. Essas alterações, representadas como uma lista, são comumente conhecidas como um feed CDC. Você pode processar seus dados muito mais rapidamente se operar em um feed CDC, em vez de ler todo o conjunto de dados de origem. Bancos de dados transacionais como SQL Server, MySQL e Oracle geram feeds CDC. As tabelas delta geram seu próprio feed CDC, conhecido como CDF (feed de dados de alteração).
O diagrama a seguir mostra que, quando uma linha em uma tabela de origem que contém dados de funcionário é atualizada, ela gera um novo conjunto de linhas em um feed CDC que contém apenas as alterações. Cada linha do feed CDC normalmente contém metadados adicionais, incluindo a operação, como UPDATE e uma coluna que pode ser usada para ordenar deterministicamente cada linha no feed CDC para que você possa lidar com atualizações fora de ordem. Por exemplo, a sequenceNum coluna no diagrama a seguir determina a ordem de linha no feed CDC:
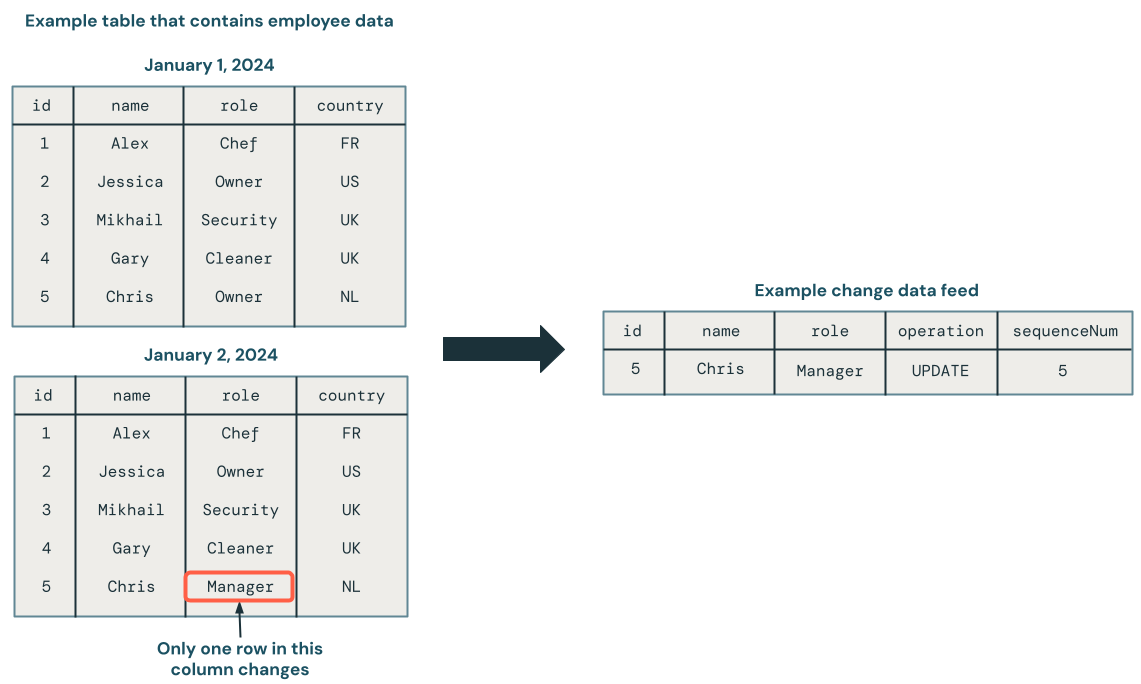
Processando um feed de dados de alterações: mantenha apenas os dados mais recentes versus mantenha versões históricas dos dados
O processamento de um feed de dados alterado é conhecido como SCD (dimensões de alteração lenta). Quando você processa um feed CDC, você tem uma escolha a fazer:
- Você mantém apenas os dados mais recentes (ou seja, substituir dados existentes)? Isso é conhecido como SCD Tipo 1.
- Ou você mantém um histórico de alterações nos dados? Isso é conhecido como SCD Tipo 2.
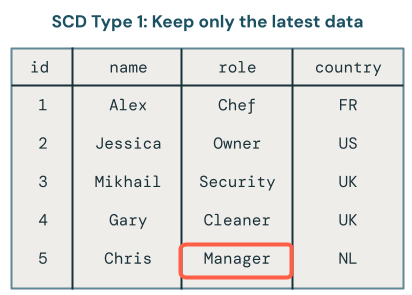
O processamento scd tipo 1 envolve a substituição de dados antigos com novos dados sempre que ocorre uma alteração. Isso significa que nenhum histórico das alterações é mantido. Somente a versão mais recente dos dados está disponível. É uma abordagem simples e geralmente é usada quando o histórico de alterações não é importante, como corrigir erros ou atualizar campos não críticos, como endereços de email do cliente.
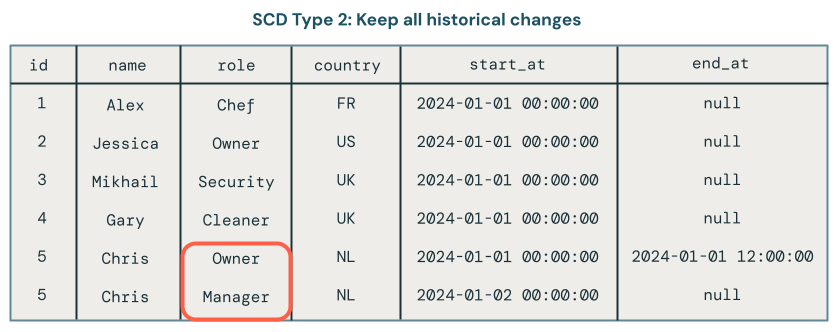
O processamento scd tipo 2 mantém um registro histórico de alterações de dados criando registros adicionais para capturar diferentes versões dos dados ao longo do tempo. Cada versão dos dados é carimbada com data/hora ou marcada com metadados que permitem aos usuários rastrear quando ocorreu uma alteração. Isso é útil quando é importante acompanhar a evolução dos dados, como acompanhar as alterações de endereço do cliente ao longo do tempo para fins de análise.
Exemplos de processamento SCD Tipo 1 e Tipo 2 com Pipelines Declarativas do Lakeflow
Os exemplos nesta seção mostram como usar o SCD Tipo 1 e o Tipo 2.
Etapa 1: Preparar dados de exemplo
Neste exemplo, você criará um feed CDC de amostra. Primeiro, crie um notebook e cole o código a seguir nele. Atualize as variáveis no início do bloco de código para um catálogo e um esquema em que você tem permissão para criar tabelas e exibições.
Esse código cria uma nova tabela Delta que contém vários registros de alteração. O esquema é o seguinte:
-
id- Inteiro, identificador exclusivo deste funcionário -
name- Cadeia de caracteres, nome do funcionário -
age- Inteiro, idade do funcionário -
operation- Alterar tipo(por exemplo,INSERT,UPDATEouDELETE) -
sequenceNum– Inteiro, identifica a ordem lógica dos eventos CDC nos dados de origem. O Lakeflow Declarative Pipelines usa esse sequenciamento para lidar com eventos de alteração que chegam fora de ordem.
# update these to the catalog and schema where you have permissions
# to create tables and views.
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
def write_employees_cdf_to_delta():
data = [
(1, "Alex", "chef", "FR", "INSERT", 1),
(2, "Jessica", "owner", "US", "INSERT", 2),
(3, "Mikhail", "security", "UK", "INSERT", 3),
(4, "Gary", "cleaner", "UK", "INSERT", 4),
(5, "Chris", "owner", "NL", "INSERT", 6),
# out of order update, this should be dropped from SCD Type 1
(5, "Chris", "manager", "NL", "UPDATE", 5)
(6, "Pat", "mechanic", "NL", "DELETE", 8),
(6, "Pat", "mechanic", "NL", "INSERT", 7)
]
columns = ["id", "name", "role", "country", "operation", "sequenceNum"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.{employees_cdf_table}")
write_employees_cdf_to_delta()
Você pode visualizar esses dados usando o seguinte comando SQL:
SELECT *
FROM mycatalog.myschema.employees_cdf
Etapa 2: Usar o SCD Tipo 1 para manter apenas os dados mais recentes
É recomendável usar a AUTO CDC API em Pipelines Declarativas do Lakeflow para processar uma fonte de dados de alteração em uma tabela SCD Tipo 1.
- Crie um novo bloco de anotações.
- Cole o código a seguir nele.
- Configure e conecte-se a um pipeline.
A employees_cdf função lê a tabela que acabamos de criar acima como um fluxo porque a create_auto_cdc_flow API, que você usará para processamento de captura de dados de alterações, espera um fluxo de alterações como entrada. Você o encapsula com um decorator @dlt.view porque não deseja materializar esse fluxo em uma tabela.
Em seguida, você usa dlt.create_target_table para criar uma tabela de streaming que contém o resultado do processamento desse feed de dados de alterações.
Por fim, você usa dlt.create_auto_cdc_flow para processar o fluxo de dados de alteração. Vamos dar uma olhada em cada argumento:
-
target- A tabela de streaming de destino, que você definiu anteriormente. -
source- A visão sobre o fluxo contínuo de registros de alteração que você definiu anteriormente. -
keys- Identifica linhas exclusivas no feed de alterações. Como você está usandoidcomo um identificador exclusivo, basta forneceridcomo a única coluna de identificação. -
sequence_by- O nome da coluna que especifica a ordem lógica dos eventos CDC nos dados de origem. Você precisa desse sequenciamento para lidar com eventos de alteração que chegam fora de ordem. ForneçasequenceNumcomo a coluna de sequenciamento. -
apply_as_deletes- Como os dados de exemplo contêm operações de exclusão, você usaapply_as_deletespara indicar quando um evento CDC deve ser tratado como umDELETEem vez de um upsert. -
except_column_list- Contém uma lista de colunas que você não deseja incluir na tabela de destino. Neste exemplo, você usará esse argumento para excluirsequenceNumeoperation. -
stored_as_scd_type- Indica o tipo SCD que você deseja usar.
import dlt
from pyspark.sql.functions import col, expr, lit, when
from pyspark.sql.types import StringType, ArrayType
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table_current = "employees_current"
employees_table_historical = "employees_historical"
@dlt.view
def employees_cdf():
return spark.readStream.format("delta").table(f"{catalog}.{schema}.{employees_cdf_table}")
dlt.create_target_table(f"{catalog}.{schema}.{employees_table_current}")
dlt.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_current}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
Execute este pipeline clicando em Iniciar.
Em seguida, execute a seguinte consulta no editor do SQL para verificar se os registros de alteração foram processados corretamente:
SELECT *
FROM mycatalog.myschema.employees_current
Observação
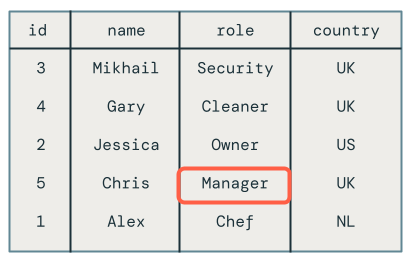
A atualização fora de ordem para o funcionário Chris foi descartada corretamente, pois sua função ainda está definida como Proprietário em vez de Gerente.
Etapa 3: Usar o SCD Tipo 2 para manter dados históricos
Neste exemplo, você cria uma segunda tabela de destino, chamada employees_historical, que contém um histórico completo de alterações nos registros de funcionários.
Adicione este código ao fluxo de trabalho. A única diferença aqui é que stored_as_scd_type é definido como 2 em vez de 1.
dlt.create_target_table(f"{catalog}.{schema}.{employees_table_historical}")
dlt.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_historical}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 2
)
Execute este pipeline clicando em Iniciar.
Em seguida, execute a seguinte consulta no editor do SQL para verificar se os registros de alteração foram processados corretamente:
SELECT *
FROM mycatalog.myschema.employees_historical
Você verá todas as alterações nos funcionários, incluindo os funcionários que foram excluídos, como Pat.
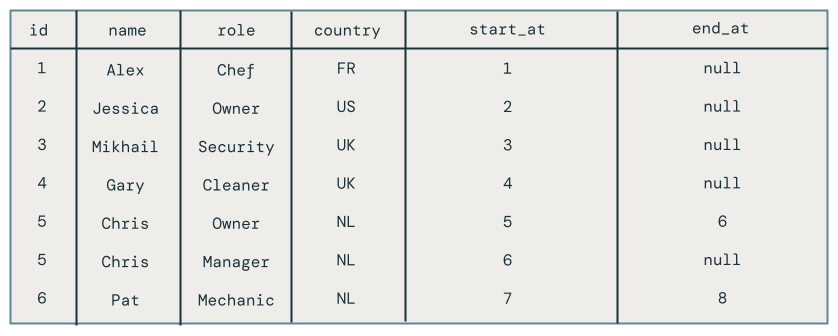
Passo 4: Limpar recursos
Quando terminar, limpe os recursos seguindo estas etapas:
Exclua o pipeline:
Observação
Quando você exclui o pipeline, ele exclui automaticamente as tabelas
employeeseemployees_historical.- Clique em Trabalhos &Pipelines e, em seguida, localize o nome do pipeline a ser excluído.
- Clique no
 Na mesma linha, nome do pipeline e clique em Excluir.
Na mesma linha, nome do pipeline e clique em Excluir.
Exclua o bloco de anotações.
Exclua a tabela que contém o fluxo de dados de alteração.
- Clique em Nova > Consulta.
- Cole e execute o seguinte código SQL, ajustando o catálogo e o esquema conforme apropriado:
DROP TABLE mycatalog.myschema.employees_cdf
Desvantagens de usar MERGE INTO e foreachBatch para a captura de dados de alteração
Databricks fornece um MERGE INTO comando SQL que você pode usar com a foreachBatch API para atualizar ou inserir linhas em uma tabela Delta. Esta seção explora como essa técnica pode ser usada para casos de uso simples, mas esse método se torna cada vez mais complexo e frágil quando aplicado a cenários do mundo real.
Neste exemplo, você usará o mesmo feed de dados de alterações usado como exemplo nos exemplos anteriores.
Implementação naive com MERGE INTO e foreachBatch
Crie um bloco de anotações e copie o código a seguir nele. Altere as variáveis catalog, schema e employees_table conforme apropriado. As variáveis catalog e schema devem ser definidas em localizações no Catálogo do Unity onde você pode criar tabelas.
Quando você executa o notebook, ele faz o seguinte:
- Cria a tabela de destino na
create_table. Ao contrário decreate_auto_cdc_flow, que trata dessa etapa automaticamente, você precisa especificar o esquema. - Lê o feed de dados de alteração como um fluxo. Cada microbatch é processado usando o
upsertToDeltamétodo, que executa umMERGE INTOcomando.
catalog = "jobs"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table = "employees_merge"
def upsertToDelta(microBatchDF, batchId):
microBatchDF.createOrReplaceTempView("updates")
microBatchDF.sparkSession.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING)
""")
create_table()
cdcData = spark.readStream.table(f"{catalog}.{schema}.{employees_cdf_table}")
cdcData.writeStream \
.foreachBatch(upsertToDelta) \
.outputMode("append") \
.start()
Para ver os resultados, execute a seguinte consulta SQL:
SELECT *
FROM mycatalog.myschema.employees_merge
Infelizmente, os resultados estão incorretos, conforme mostrado a seguir:
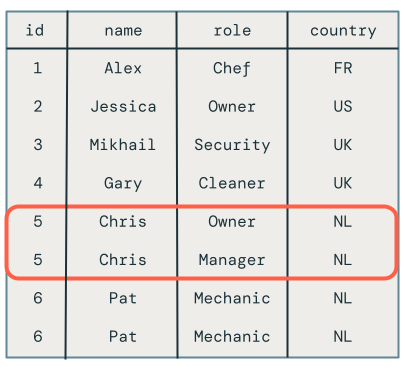
Várias atualizações para a mesma chave na mesma microbatch
O primeiro problema é que o código não manipula várias atualizações para a mesma chave na mesma microbatch. Por exemplo, você usa INSERT para inserir o funcionário Chris e então você atualiza a função dele de Proprietário para Gerente. Isso deve resultar em uma linha, mas, em vez disso, há duas linhas.
Qual alteração ganha quando há várias atualizações na mesma chave no mesmo micro-lote?
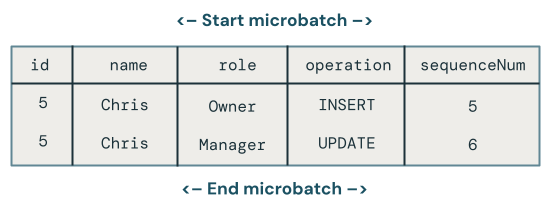
A lógica torna-se mais complexa. O exemplo de código a seguir recupera a linha sequenceNum mais recente e mescla apenas os dados na tabela de destino da seguinte maneira:
- Agrupa pela chave primária,
id. - Seleciona todas as colunas para a linha que possui o valor máximo de
sequenceNumno lote para essa chave. - Estoura a linha para fora de novo.
Atualize o upsertToDelta método conforme mostrado a seguir e execute o código:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
Ao consultar a tabela de destino, você verá que o funcionário chamado Chris tem a função correta, mas ainda há outros problemas a serem resolvidos porque você ainda excluiu registros que aparecem na tabela de destino.
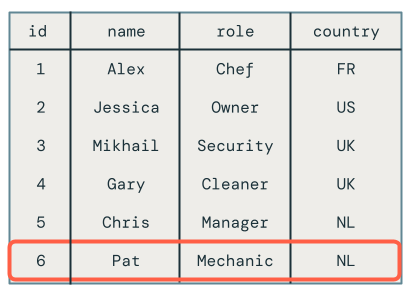
Atualizações fora de ordem entre micro-lotes
Esta seção explora o problema das atualizações fora de ordem em microbatches. O diagrama a seguir ilustra o problema: e se a linha de Chris tiver uma UPDATE operação no primeiro microbatch, seguida por uma INSERT em um microbatch subsequente? O código não lida com isso corretamente.
Qual alteração prevalece quando há atualizações fora de ordem para a mesma chave em vários microbatches?
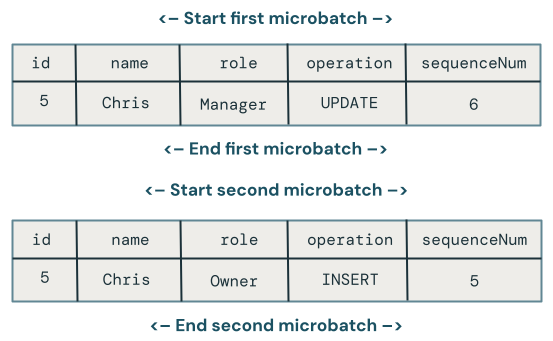
Para corrigir isso, expanda o código para armazenar uma versão em cada linha da seguinte maneira:
- Armazene quando uma linha foi atualizada pela última vez
sequenceNum. - Para cada nova linha, verifique se o timestamp é superior ao armazenado e então aplique a lógica a seguir:
- Se for maior, use os novos dados do alvo.
- Caso contrário, mantenha os dados na origem.
Primeiro, atualize o createTable método para armazenar o sequenceNum pois você o usará para versionar cada linha.
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING, sequenceNum INT)
""")
Em seguida, atualize upsertToDelta para lidar com versões de linha. A cláusula UPDATE SET de MERGE INTO precisa lidar com cada coluna separadamente.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Gerenciamento de exclusões
Infelizmente, o código ainda tem um problema. Ele não processa DELETE operações, conforme demonstrado pelo fato de que o funcionário Pat ainda está na tabela de destino.
Vamos supor que as exclusões cheguem no mesmo lote micro. Para lidar com eles, atualize o método upsertToDelta novamente para excluir a linha quando o registro de dados modificados indicar uma exclusão, conforme mostrado a seguir.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN DELETE
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Lidando com atualizações que chegam fora de ordem após exclusões
Infelizmente, o código acima ainda não está muito correto porque não lida com casos em que um DELETE é seguido por um fora de ordem UPDATE entre microbatches.
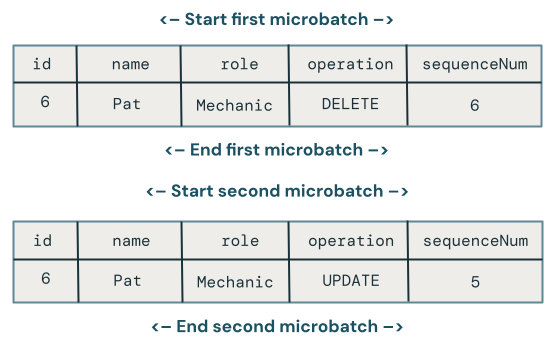
O algoritmo para lidar com esse caso precisa se lembrar de exclusões para que ele possa lidar com as atualizações fora de ordem subsequentes. Para fazer isso:
- Em vez de excluir linhas imediatamente, exclua-as com um carimbo de data/hora ou
sequenceNum. Linhas excluídas suavemente são tombadas. - Redirecione todos os usuários para uma exibição que filtra as pedras de tombamento.
- Crie um trabalho de limpeza que remova as pedras de tumba ao longo do tempo.
Use o seguinte código:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Os usuários não podem usar a tabela de destino diretamente, portanto, crie uma exibição que eles possam consultar:
CREATE VIEW employees_v AS
SELECT * FROM employees_merge
WHERE DELETED_AT = NULL
Por fim, crie um trabalho de limpeza que remova periodicamente linhas tombadas:
DELETE FROM employees_merge
WHERE DELETED_AT < now() - INTERVAL 1 DAY